通俗易懂,JDK 並發容器總結
- 2019 年 10 月 7 日
- 筆記
目錄: 一 JDK 提供的並發容器總結二 ConcurrentHashMap三 CopyOnWriteArrayList3.1 CopyOnWriteArrayList 簡介3.2 CopyOnWriteArrayList 是如何做到的?3.3 CopyOnWriteArrayList 讀取和寫入源碼簡單分析3.3.1 CopyOnWriteArrayList 讀取操作的實現3.3.2 CopyOnWriteArrayList 寫入操作的實現四 ConcurrentLinkedQueue五 BlockingQueue5.1 BlockingQueue 簡單介紹5.2 ArrayBlockingQueue5.3 LinkedBlockingQueue5.4 PriorityBlockingQueue六 ConcurrentSkipListMap七 參考
一 JDK 提供的並發容器總結
《實戰Java高並發程式設計》為我們總結了下面幾種大家可能會在高並發程式設計中經常遇到和使用的 JDK 為我們提供的並發容器。先帶大家概覽一下,下面會一一介紹到。
JDK提供的這些容器大部分在 java.util.concurrent 包中。
- ConcurrentHashMap: 執行緒安全的HashMap
- CopyOnWriteArrayList: 執行緒安全的List,在讀多寫少的場合性能非常好,遠遠好於Vector.
- ConcurrentLinkedQueue:高效的並發隊列,使用鏈表實現。可以看做一個執行緒安全的 LinkedList,這是一個非阻塞隊列。
- BlockingQueue: 這是一個介面,JDK內部通過鏈表、數組等方式實現了這個介面。表示阻塞隊列,非常適合用於作為數據共享的通道。
- ConcurrentSkipListMap: 跳錶的實現。這是一個Map,使用跳錶的數據結構進行快速查找。
二 ConcurrentHashMap
我們知道 HashMap 不是執行緒安全的,在並發場景下如果要保證一種可行的方式是使用 Collections.synchronizedMap() 方法來包裝我們的 HashMap。但這是通過使用一個全局的鎖來同步不同執行緒間的並發訪問,因此會帶來不可忽視的性能問題。
所以就有了 HashMap 的執行緒安全版本—— ConcurrentHashMap 的誕生。在ConcurrentHashMap中,無論是讀操作還是寫操作都能保證很高的性能:在進行讀操作時(幾乎)不需要加鎖,而在寫操作時通過鎖分段技術只對所操作的段加鎖而不影響客戶端對其它段的訪問。
關於 ConcurrentHashMap 相關問題,我在 《這幾道Java集合框架面試題幾乎必問》這篇文章中已經提到過。下面梳理一下關於 ConcurrentHashMap 比較重要的問題:
- ConcurrentHashMap 和 Hashtable 的區別
- ConcurrentHashMap執行緒安全的具體實現方式/底層具體實現
三 CopyOnWriteArrayList
3.1 CopyOnWriteArrayList 簡介
public class CopyOnWriteArrayList<E> extends Object implements List<E>, RandomAccess, Cloneable, Serializable
在很多應用場景中,讀操作可能會遠遠大於寫操作。由於讀操作根本不會修改原有的數據,因此對於每次讀取都進行加鎖其實是一種資源浪費。我們應該允許多個執行緒同時訪問List的內部數據,畢竟讀取操作是安全的。
這和我們之前在多執行緒章節講過 ReentrantReadWriteLock 讀寫鎖的思想非常類似,也就是讀讀共享、寫寫互斥、讀寫互斥、寫讀互斥。JDK中提供了 CopyOnWriteArravList 類比相比於在讀寫鎖的思想又更進一步。為了將讀取的性能發揮到極致,CopyOnWriteArravList 讀取是完全不用加鎖的,並且更厲害的是:寫入也不會阻塞讀取操作。只有寫入和寫入之間需要進行同步等待。這樣一來,讀操作的性能就會大幅度提升。那它是怎麼做的呢?
3.2 CopyOnWriteArravList 是如何做到的?
CopyOnWriteArravList 類的所有可變操作(add,set等等)都是通過創建底層數組的新副本來實現的。當 List 需要被修改的時候,我並不修改原有內容,而是對原有數據進行一次複製,將修改的內容寫入副本。寫完之後,再將修改完的副本替換原來的數據,這樣就可以保證寫操作不會影響讀操作了。
從 CopyOnWriteArravList 的名字就能看出CopyOnWriteArravList 是滿足CopyOnWrite 的ArrayList,所謂CopyOnWrite 也就是說:在電腦,如果你想要對一塊記憶體進行修改時,我們不在原有記憶體塊中進行寫操作,而是將記憶體拷貝一份,在新的記憶體中進行寫操作,寫完之後呢,就將指向原來記憶體指針指向新的記憶體,原來的記憶體就可以被回收掉了。
3.3 CopyOnWriteArrayList 讀取和寫入源碼簡單分析
3.3.1 CopyOnWriteArravList 讀取操作的實現
讀取操作沒有任何同步控制和鎖操作,理由就是內部數組 array 不會發生修改,只會被另外一個 array 替換,因此可以保證數據安全。
/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; public E get(int index) { return get(getArray(), index); } @SuppressWarnings("unchecked") private E get(Object[] a, int index) { return (E) a[index]; } final Object[] getArray() { return array; }
3.3.2 CopyOnWriteArravList 寫入操作的實現
CopyOnWriteArravList 寫入操作 add() 方法在添加元素的時候加了鎖,保證了同步,避免了多執行緒寫的時候會 copy 出多個副本出來。
/** * Appends the specified element to the end of this list. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock();//加鎖 try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1);//拷貝新數組 newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock();//釋放鎖 } }
四 ConcurrentLinkedQueue
Java提供的執行緒安全的 Queue 可以分為阻塞隊列和非阻塞隊列,其中阻塞隊列的典型例子是 BlockingQueue,非阻塞隊列的典型例子是ConcurrentLinkedQueue,在實際應用中要根據實際需要選用阻塞隊列或者非阻塞隊列。 阻塞隊列可以通過加鎖來實現,非阻塞隊列可以通過 CAS 操作實現。
從名字可以看出,ConcurrentLinkedQueue這個隊列使用鏈表作為其數據結構.ConcurrentLinkedQueue 應該算是在高並發環境中性能最好的隊列了。它之所有能有很好的性能,是因為其內部複雜的實現。
ConcurrentLinkedQueue 內部程式碼我們就不分析了,大家知道ConcurrentLinkedQueue 主要使用 CAS 非阻塞演算法來實現執行緒安全就好了。
ConcurrentLinkedQueue 適合在對性能要求相對較高,同時對隊列的讀寫存在多個執行緒同時進行的場景。
五 BlockingQueue
5.1 BlockingQueue 簡單介紹
上面我們己經提到了 ConcurrentLinkedQueue 作為高性能的非阻塞隊列。下面我們要講到的是阻塞隊列——BlockingQueue。阻塞隊列(BlockingQueue)被廣泛使用在「生產者-消費者」問題中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。當隊列容器已滿,生產者執行緒會被阻塞,直到隊列未滿;當隊列容器為空時,消費者執行緒會被阻塞,直至隊列非空時為止。
BlockingQueue 是一個介面,繼承自 Queue,所以其實現類也可以作為 Queue 的實現來使用,而 Queue 又繼承自 Collection 介面。下面是 BlockingQueue 的相關實現類:

BlockingQueue 的實現類
下面主要介紹一下:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,這三個 BlockingQueue 的實現類。
5.2 ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 介面的有界隊列實現類,底層採用數組來實現。ArrayBlockingQueue一旦創建,容量不能改變。其並發控制採用可重入鎖來控制,不管是插入操作還是讀取操作,都需要獲取到鎖才能進行操作。當隊列容量滿時,嘗試將元素放入隊列將導致操作阻塞;嘗試從一個空隊列中取一個元素也會同樣阻塞。
ArrayBlockingQueue 默認情況下不能保證執行緒訪問隊列的公平性,所謂公平性是指嚴格按照執行緒等待的絕對時間順序,即最先等待的執行緒能夠最先訪問到 ArrayBlockingQueue。而非公平性則是指訪問 ArrayBlockingQueue 的順序不是遵守嚴格的時間順序,有可能存在,當 ArrayBlockingQueue 可以被訪問時,長時間阻塞的執行緒依然無法訪問到 ArrayBlockingQueue。如果保證公平性,通常會降低吞吐量。如果需要獲得公平性的 ArrayBlockingQueue,可採用如下程式碼:
private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);
5.3 LinkedBlockingQueue
LinkedBlockingQueue 底層基於單向鏈表實現的阻塞隊列,可以當做無界隊列也可以當做有界隊列來使用,同樣滿足FIFO的特性,與ArrayBlockingQueue 相比起來具有更高的吞吐量,為了防止 LinkedBlockingQueue 容量迅速增,損耗大量記憶體。通常在創建LinkedBlockingQueue 對象時,會指定其大小,如果未指定,容量等於Integer.MAX_VALUE。
相關構造方法:
/** *某種意義上的無界隊列 * Creates a {@code LinkedBlockingQueue} with a capacity of * {@link Integer#MAX_VALUE}. */ public LinkedBlockingQueue() { this(Integer.MAX_VALUE); } /** *有界隊列 * Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity. * * @param capacity the capacity of this queue * @throws IllegalArgumentException if {@code capacity} is not greater * than zero */ public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node<E>(null); }
5.4 PriorityBlockingQueue
PriorityBlockingQueue 是一個支援優先順序的無界阻塞隊列。默認情況下元素採用自然順序進行排序,也可以通過自定義類實現 compareTo() 方法來指定元素排序規則,或者初始化時通過構造器參數 Comparator 來指定排序規則。
PriorityBlockingQueue 並發控制採用的是 ReentrantLock,隊列為無界隊列(ArrayBlockingQueue 是有界隊列,LinkedBlockingQueue 也可以通過在構造函數中傳入 capacity 指定隊列最大的容量,但是 PriorityBlockingQueue 只能指定初始的隊列大小,後面插入元素的時候,如果空間不夠的話會自動擴容)。
簡單地說,它就是 PriorityQueue 的執行緒安全版本。不可以插入 null 值,同時,插入隊列的對象必須是可比較大小的(comparable),否則報 ClassCastException 異常。它的插入操作 put 方法不會 block,因為它是無界隊列(take 方法在隊列為空的時候會阻塞)。
推薦文章:
《解讀 Java 並發隊列 BlockingQueue》
https://javadoop.com/post/java-concurrent-queue
六 ConcurrentSkipListMap
下面這部分內容參考了極客時間專欄《數據結構與演算法之美》以及《實戰Java高並發程式設計》。
為了引出ConcurrentSkipListMap,先帶著大家簡單理解一下跳錶。
對於一個單鏈表,即使鏈表是有序的,如果我們想要在其中查找某個數據,也只能從頭到尾遍歷鏈表,這樣效率自然就會很低,跳錶就不一樣了。跳錶是一種可以用來快速查找的數據結構,有點類似於平衡樹。它們都可以對元素進行快速的查找。但一個重要的區別是:對平衡樹的插入和刪除往往很可能導致平衡樹進行一次全局的調整。而對跳錶的插入和刪除只需要對整個數據結構的局部進行操作即可。這樣帶來的好處是:在高並發的情況下,你會需要一個全局鎖來保證整個平衡樹的執行緒安全。而對於跳錶,你只需要部分鎖即可。這樣,在高並發環境下,你就可以擁有更好的性能。而就查詢的性能而言,跳錶的時間複雜度也是 O(logn) 所以在並發數據結構中,JDK 使用跳錶來實現一個 Map。
跳錶的本質是同時維護了多個鏈表,並且鏈表是分層的,

2級索引跳錶
最低層的鏈表維護了跳錶內所有的元素,每上面一層鏈表都是下面一層的了集。
跳錶內的所有鏈表的元素都是排序的。查找時,可以從頂級鏈表開始找。一旦發現被查找的元素大於當前鏈表中的取值,就會轉入下一層鏈表繼續找。這也就是說在查找過程中,搜索是跳躍式的。如上圖所示,在跳錶中查找元素18。
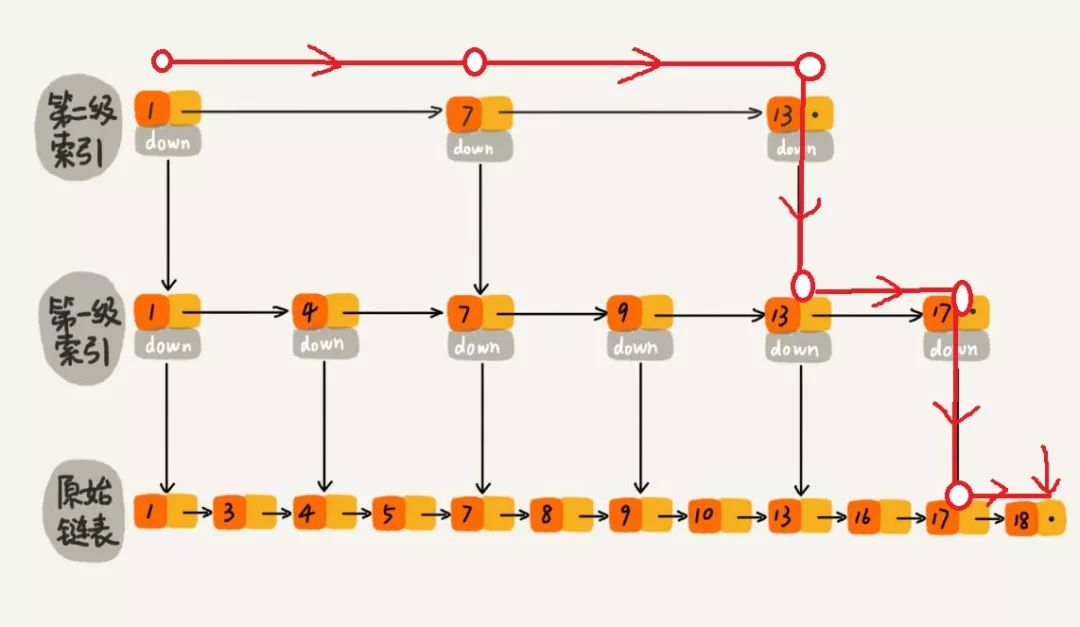
在跳錶中查找元素18
查找18 的時候原來需要遍歷 18 次,現在只需要 7 次即可。針對鏈表長度比較大的時候,構建索引查找效率的提升就會非常明顯。
從上面很容易看出,跳錶是一種利用空間換時間的演算法。
使用跳錶實現Map 和使用哈希演算法實現Map的另外一個不同之處是:哈希並不會保存元素的順序,而跳錶內所有的元素都是排序的。因此在對跳錶進行遍歷時,你會得到一個有序的結果。所以,如果你的應用需要有序性,那麼跳錶就是你不二的選擇。JDK 中實現這一數據結構的類是ConcurrentSkipListMap。
七 參考
- 《實戰Java高並發程式設計》
- https://javadoop.com/post/java-concurrent-queue
- https://juejin.im/post/5aeebd02518825672f19c546
