重學數據結構之隊列
一、隊列的概念
1.基本概念
隊列(queue)又被稱為隊,也是一種保存數據元素的容器。隊列時一種特殊的線性表,只允許在表的前端(front)進行刪除操作,只允許在表的後端(rear)進行插入操作,進行刪除操作的一端叫做對頭,進行插入操作的一端稱為隊尾。
隊列按照先進先出的原則(FIFO,First In First Out)存儲數據,先存入的元素會先被取出來使用。在隊列中插入一個隊列元素稱為入隊,從隊列中刪除一個隊列元素稱為出隊。
2.抽象數據描述
隊列的基本操作和棧是類似的,只不過操作名稱有些許不一樣,下面是一個基本隊列的抽象數據描述:
ADT Queue:
Queue(self) # 創建一個空隊列
is_empty(self) # 判斷隊列是否為空
enqueue(self, elem) # 入隊,向隊列中插入一個元素
dequeue(self) # 出隊,從隊列中刪除一個元素
peek(self) # 查看對頭位置的元素
3.用 Python 實現
1 # 自定義隊列
2 class MyQueue:
3 def __init__(self):
4 self.data = []
5
6 def is_empty(self):
7 return len(self.data) == 0
8
9 def enqueue(self, elem):
10 self.data.append(elem)
11
12 def dequeue(self):
13 if self.data:
14 ret, self.data = self.data[0], self.data[1:]
15 return ret
16 return None
17
18 def peek(self):
19 return self.data[0] if self.data else None
二、隊列
1.順序隊列
順序隊列是隊列的順序存儲結構,順序隊列實際上是運算受限的順序表。和順序表一樣,順序隊列使用一個向量空間來存放當前隊列中的元素。由於隊列的隊頭和隊尾的位置是變化的,設置兩個指針front和rear分別指示隊頭元素和隊尾元素的位置,它們的初值在初始化時都置為0。
2.循環隊列
循環隊列將向量空間想像為一個首尾相接的迴環,在循環隊列中,由於入隊時隊尾指針向前追趕隊頭指針,出隊時隊頭指針追趕隊尾指針,因而隊空和隊滿時頭尾指針均相等。
3.雙端隊列
雙端隊列是一種具有隊列和棧的性質的數據結構。雙端隊列中的元素可以從兩端彈出,其限定插入和刪除操作在表的兩端進行。雙端隊列是限定插入和刪除操作在表的兩端進行的線性表。
4.優先順序隊列
在優先順序隊列中,會給每一個元素都分配一個數字用來標記其優先順序,例如給其中最小的數字以最高的優先順序,這樣就可以在一個集合中訪問優先順序最高的元素並對其進行查找和刪除操作了。
使用 Python 實現一個優先順序隊列,可以藉助 Python 中的 heapq 模組來實現,heapq 是一個二叉堆的實現,其內部使用內置的 list 對象,對於列表中的每一個元素都滿足 a[k] <= a[2 * k + 1] and a[k] <= a[2 * k + 2],因此其默認是一個最小堆,a[0] 是隊列中最小的元素。下面是利用 heapq 模組實現的一個優先順序隊列程式碼示例:
1 # 自定義優先順序隊列
2 class PriorityQueue:
3 def __init__(self):
4 self.data = []
5 self.index = 0
6
7 def push(self, elem, priority):
8 """
9 入隊,將元素插入到隊列中
10 :param elem: 待插入元素
11 :param priority: 該元素的優先順序
12 :return:
13 """
14 # priority 加上負號是因為 heapq 默認是最小堆
15 heapq.heappush(self.data, (-priority, self.index, elem))
16 self.index += 1
17
18 def pop(self):
19 """
20 出隊,從隊列中取出優先順序最高的元素
21 :return:
22 """
23 return heapq.heappop(self.data)[-1]
24
25 def size(self):
26 """
27 獲取隊列中元素數量
28 :return:
29 """
30 return len(self.data)
31
32 def is_empty(self):
33 """
34 判斷隊列是否為空
35 :return:
36 """
37 return len(self.data) == 0
三、隊列的應用
1.迷宮問題
1)問題描述
將一個迷宮映射成一個由0和1組成的二維矩陣,迷宮裡的空位置用0來表示,障礙和邊界用1來表示,最左上角為入口,最右下角為出口,求是否能從迷宮中走出來?
2)問題分析
首先在演算法初始時,可行的位置用0標識,不可行的位置用1標識,但在搜索路徑的過程中需要將已經走過的位置給標記上,這裡可以用數字2來標記,在後面的搜索過程中碰到2也就不會重複搜索了。
當到達一個位置時,需要確定該位置的可行方向,而除了邊界點,每個位置都有四個可行的方向需要探索,例如對於坐標點(i,j),其四個相鄰位置如下圖:
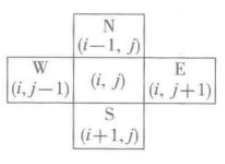
為了能夠方便的計算相鄰位置,可以用一個列表來記錄:
DIR = [(0, 1), (1, 0), (0, -1), (-1, 0)]
對於任何一個位置(i,j),都可以分別加上 DIR[0]、DIR[1]、DIR[2]、DIR[3],就能得到相鄰位置了。
為了使演算法變得簡單,這裡可以先定義兩個輔助用的函數,一個用於標記走過的點,一個用於判斷輸入的位置是否可以通行,具體程式碼如下:
1 def mark(maze, pos): 2 """ 3 將迷宮中已經走過的位置進行標記,設置為2 4 :param maze: 迷宮 5 :param pos: 位置 6 :return: 7 """ 8 maze[pos[0]][pos[1]] = 2 9 10 11 def passable(maze, pos): 12 """ 13 檢車迷宮中指定位置是否能走 14 :param maze: 迷宮 15 :param pos: 位置 16 :return: 17 """ 18 if pos[0] < len(maze) and pos[1] < len(maze[0]): 19 return maze[pos[0]][pos[1]] == 0 20 return False
3)遞歸演算法求解
在使用遞歸演算法求解的過程中,對於每一個位置,都有如下的演算法過程:
- 標記當前位置;
- 檢查當前位置是否為出口,如果則表明找到路徑,演算法結束,不是則進行下一步;
- 遍歷該位置的相鄰位置,使用遞歸調用自身;
- 如果相鄰位置都不可行,表明無法從迷宮中走出來,演算法結束。
遞歸演算法的核心函數程式碼如下:
1 def solution(maze, pos, end): 2 """ 3 遞歸演算法的核心函數 4 :param maze: 迷宮,二維矩陣 5 :param pos: 當前位置 6 :param end: 出口 7 :return: 8 """ 9 mark(maze, pos) 10 if pos == end: 11 print(pos) 12 return True 13 for i in range(4): 14 next_pos = pos[0] + DIR[i][0], pos[1] + DIR[i][1] 15 if passable(maze, next_pos): 16 if solution(maze, next_pos, end): 17 print(pos) 18 return True 19 return False
4)使用隊列求解
基於隊列的求解演算法還是使用之前的表示方法和輔助函數,但演算法過程有變化。
首先將入口標記為已經到過併入隊,然後當隊列里還有未探索的位置時,取出一個位置並檢查該位置的相鄰位置,當相鄰位置可行時,如果這個位置就是出口則結束演算法,否則加入到隊列中,當整個隊列中的元素都被取出來後,隊列為空,表示未找到從迷宮中走出來的路徑,結束演算法。使用隊列求解迷宮問題的演算法程式碼如下:
1 def queue_solution(maze): 2 """ 3 使用隊列求解迷宮問題 4 :param maze: 迷宮,二維矩陣 5 :return: 6 """ 7 start, end = (0, 0), (len(maze) - 1, len(maze[0]) - 1) 8 q = MyQueue() 9 mark(maze, start) 10 q.enqueue(start) 11 while not q.is_empty(): 12 pos = q.dequeue() 13 for i in range(4): 14 next_pos = pos[0] + DIR[i][0], pos[1] + DIR[i][1] 15 if passable(maze, next_pos): 16 if next_pos == end: 17 print("Find Path!") 18 return True 19 mark(maze, next_pos) 20 q.enqueue(next_pos) 21 print("No Path!") 22 return False
2.生產者消費者模式
所謂生產者消費者模式,簡而言之就是兩個執行緒,一個扮演生產者,負責產生數據,另一個扮演消費者,不斷獲取這些數據並進行處理。而只有生產者和消費者,還算不上生產者消費者模式,還需要有一個緩衝區位於兩者之間,生產者把數據放入緩衝區,消費者從緩衝區中取出數據。使用生產者消費者模式有幾個好處:解耦,支援並發等。
在編寫爬蟲爬取數據時,就可以使用該模式,一個模組不斷獲取 URL,另一個模組就負責發送請求和解析數據,而在其中就可以使用隊列作為緩衝區,將待爬取的 URL 都存放在這個隊列中,然後爬取模組再從中取出 URL 進行爬取,直至隊列為空。這裡可以參考我以前寫過的一篇部落格://www.cnblogs.com/TM0831/p/10510319.html。

