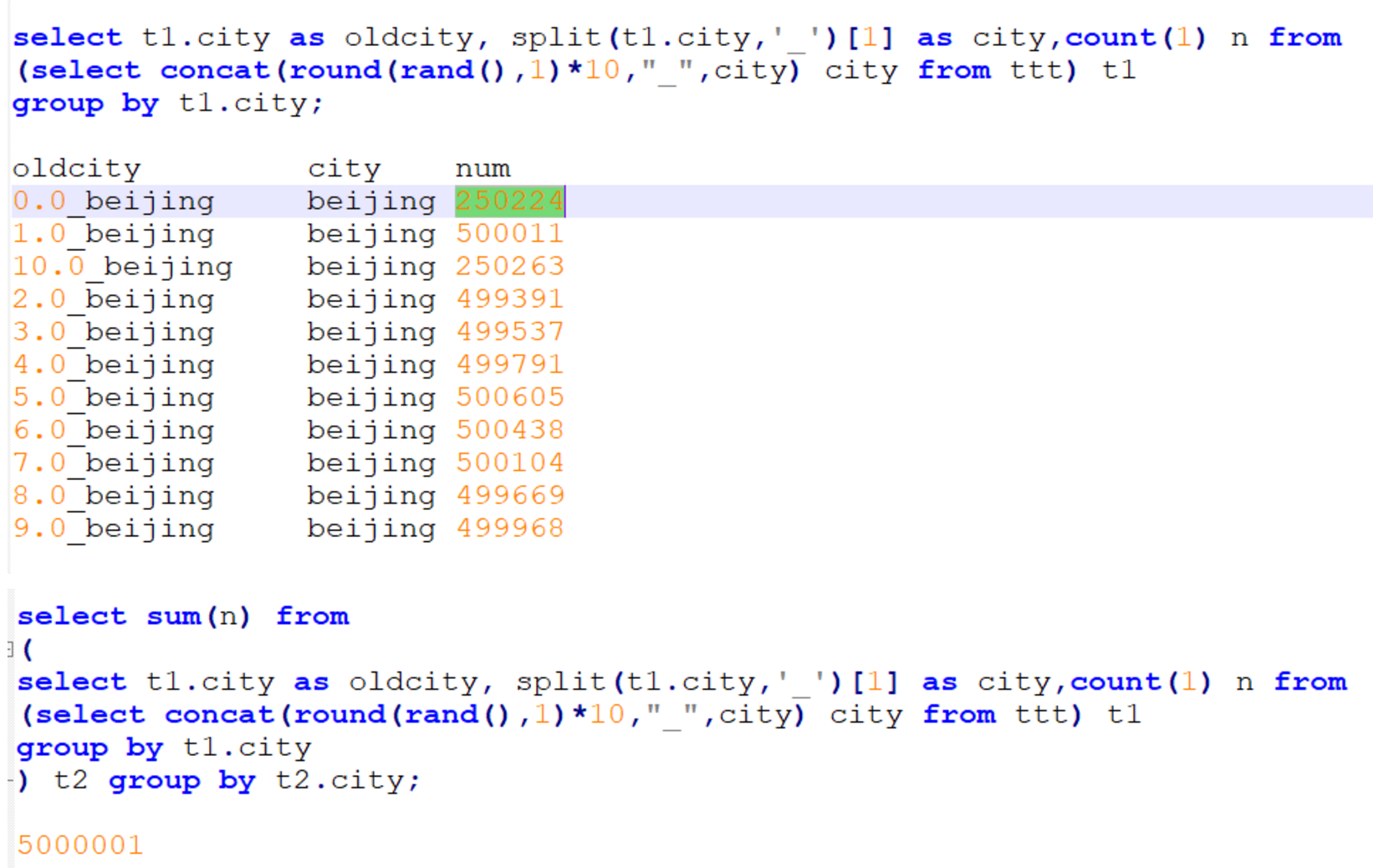
3、Hive-sql優化,數據傾斜處理
一、Hive-sql優化
#增加reducer任務數量(拉取數量分流) set mapred.reduce.tasks=20; #在同一個sql中的不同的job是否可以同時運行,默認為false set hive.exec.parallel=true; #增加同一個sql允許並行任務的最大執行緒數 set hive.exec.parallel.thread.number=8; #設置reducer記憶體大小 set mapreduce.reduce.memory.mb=4096; set mapreduce.reduce.java.opts=-Xmx3584m; -- -Xmx 設置堆的最大空間大小。
#mapjoin相關設置,小表載入到記憶體,無reduce
set hive.mapjoin.smalltable.filesize=25000000; -- 刷入記憶體表的大小(位元組)。注意:設置太大也不會校驗,所以要根據自己的數據集調整
set hive.auto.convert.join = true; -- 開啟mapjoin,默認false
set hive.mapjoin.followby.gby.localtask.max.memory.usage=0.6 ;--map join做group by操作時,可使用多大的記憶體來存儲數據。若數據太大則不會保存在記憶體里,默認0.55
set hive.mapjoin.localtask.max.memory.usage=0.90; -- 本地任務可以使用記憶體的百分比,默認值:0.90
-- 在設置成false時,可以手動的指定mapjoin /*+ MAPJOIN(c) */ 。-->c:放到記憶體中的表
select /*+ MAPJOIN(c) */ * from user_install_status u
inner join country_dict c
on u.country=c.code
-- 如果不是做innerjoin, 做left join 、right join
-- A left join B, 把B放到記憶體
-- A right join B, 把A放到記憶體
#設置執行引擎
set hive.execution.engine=mr; -- 執行MapReduce任務,也可以設置為spark
-- 設置記憶體大小
set mapreduce.reduce.memory.mb=8192; -- reduce 設置的是 Container 的記憶體上限,這個參數由 NodeManager 讀取並進行控制,當 Container 的記憶體大小超過了這個參數值,NodeManager 會負責 kill 掉 Container
set mapreduce.reduce.java.opts=-Xmx6144m; -- reduce Java 程式可以使用的最大堆記憶體數,要小於 mapreduce.reduce.memory.mb
set mapreduce.map.memory.mb=8192; -- map申請記憶體大小
set mapreduce.map.java.opts=-Xmx6144m;
#動態分區設置,參考://www.cnblogs.com/cssdongl/p/6831884.html
set hive.exec.dynamic.partition=true; 是開啟動態分區
set hive.exec.dynamic.partition.mode=nonstrict; 這個屬性默認值是strict,就是要求分區欄位必須有一個是靜態的分區值,當前設置為nonstrict,那麼可以全部動態分區
#其他
-- 開始負載均衡
set hive.groupby.skewindata=true
-- 開啟map端combiner
set hive.map.aggr=true
二、數據傾斜
2.1、數據傾斜的表現
- 任務進度長時間維持在99%(或100%),查看任務監控頁面,發現只有少量(1個或幾個)reduce子任務未完成。因為其處理的數據量和其他reduce差異過大。
- 單一reduce的記錄數與平均記錄數差異過大,通常可能達到3倍甚至更多。 最長時長遠大於平均時長。
2.2、數據傾斜的解決方案
參數調節:
- 對於group by 產生傾斜的問題
- 開啟map端combiner:【set hive.map.aggr=true;】
- 開啟負載均衡:【set hive.groupby.skewindata=true;】
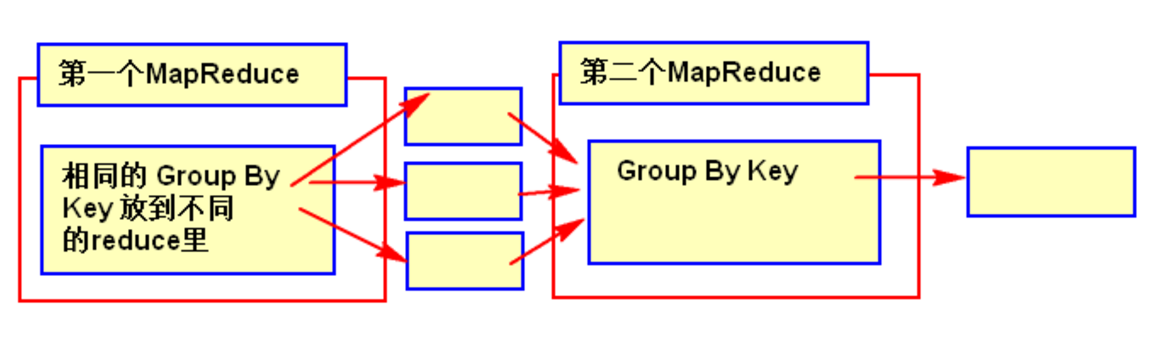
- 有數據傾斜的時候進行負載均衡,當選項設定為 true,生成的查詢計劃會有兩個 MR Job。
- 第一個 MR Job 中,Map 的輸出結果集合會隨機分布到 Reduce 中,每個 Reduce 做部分聚合操作,並輸出結果,這樣處理的結果是相同的 Group By Key 有可能被分發到不同的 Reduce 中,從而達到負載均衡的目的;
- 第二個 MR Job 再根據預處理的數據結果按照 Group By Key 分布到 Reduce 中(這個過程可以保證相同的 Group By Key 被分布到同一個 Reduce 中),最後完成最終的聚合操作。

SQL 語句調節:
- 大小表Join:
- 使用map join讓小的維度表先進記憶體。在map端完成join,不經過reduce。
- 大表Join大表:
- 非法數據太多,比如null,可以把空值的key變成一個字元串加上隨機數,把傾斜的數據分到不同的reduce上,由於null值關聯不上,處理後並不影響最終結果。
- 如果null值不要,可以通過where條件篩選掉;
- 將大量的非法數據轉化成隨機數+字元串,這樣兩個表的數據不會join在一起。
- count distinct大量相同特殊值:
- count distinct時,將值為空的情況單獨處理
- 如果是計算count distinct,可以不用處理,直接過濾,在最後結果中加1。
- 如果還有其他計算,需要進行group by,可以先將值為空的記錄單獨處理,再和其他計算結果進行union。
- 採用sum group by的方式來替換 count(distinct) 完成計算。
- 特殊情況特殊處理:
- 在業務邏輯優化效果的不大情況下,有些時候是可以將傾斜的數據單獨拿出來處理。最後union回去
- 比如:group by時維度過小,數據過於集中,數據自身傾斜,比如 北京的用戶比其它地方的用戶多很多
- 此時可以把北京的數據單獨處理:先把北京的數據分成N塊,每塊的數據進行局部統計,再將每塊的局部統計結果進行匯總,最終統計出結果