HashMap面試知識點總結
主要參考 JavaGuide 和 敖丙 的文章, 其中也有參考其他的文章, 但忘記保存鏈接了, 文中圖片也是引用別的大佬的, 請見諒.
新手上路, 若有問題, 歡迎指正.
背景
HashMap 的相關問題在校招面試中十分常見, 作為新人, HashMap 的各個問題應該要理解的十分透徹才行. 此外, ConcurrentHashMap, Hashtable 也是經常與 HashMap 一同被問, 下文中都有介紹.
HashMap 原理
1. 底層數據結構
HashMap 在 JDK1.8 之前底層使用的是數組+鏈表的拉鏈式結構; 在 JDK1.8 之後引入了紅黑樹, 當鏈表長度大於閾值的時候就會將這個鏈錶轉化為紅黑樹.
2. JDK1.8 中 HashMap 的改動
如上面所說, JDK1.8 中對 HashMap 做了一些改動, 在 JDK1.8 之前鏈表的插入使用的是頭插法, 作者認為剛剛插入的數據被查詢的可能性比較大, 頭插法在多執行緒 resize 的時候可能會產生循環鏈表. JDK1.8 之後改為了尾插法, 在擴容的時候會保持鏈表元素原本的順序, 避免了鏈表成環的問題, 但是改完以後 HashMap 依然不能支援並發場景. (不過 HashMap 本來也不是為多執行緒而生的呀)
3. 鏈表和紅黑樹的轉化
當鏈表長度大於閾值的時候就會將這個鏈錶轉化為紅黑樹, 鏈錶轉化為紅黑樹的默認閾值為 8, 如果紅黑樹的節點個數減少到一定程度也會轉化為鏈表, 這是出於時間和空間的折中方案, 默認會在節點個數減少到 6 的時候進行轉化.
4. 默認紅黑樹轉化閾值的選擇
上面所講的閾值為什麼選擇 8 和 6 呢? 根據泊松分布, 在負載因子為 0.75 (HashMap 的默認值) 的時候, 單個 hash 槽內元素個數為 8 的概率小於百萬分之一, 所以將 7 作為一個分水嶺, 等於 7 的時候不進行轉化, 大於等於 8 時轉化為紅黑樹, 小於等於 6 的時候再轉化為鏈表.
5. hash值的計算
通過閱讀源碼, 我們可以發現它是通過 (h = key.hashCode()) ^ (h >>> 16) 來計算 hash 值, 混合了 key 哈希值的高 16 位和低 16 位.
6. 擴容機制
HashMap 的默認容量 (其實就是拉鏈式中數組的長度) 為 16, 每次擴容都會變為原來的 2 倍, 並保證容量為 2 的冪次, 如果在構造函數或者擴容的時候給定一個不是 2 的冪次的數, 它會自動向上擴展到一個 2 的冪次.
7. 為什麼 HashMap 的容量要保證是 2 的冪次?
- 由於使用拉鏈式的存儲方式, 當 put 一個數據的時候, 需要對數組的長度取模確定數據在數組中的位置, 取模過程相對耗時, 因此需要優化取模運算. 當數組長度為 2 的冪次的時候,
hash % len等價於hash & (len - 1), 與運算相對取模運算更快. - 在滿足容量為 2 的冪次的時候,
(len - 1)的所有二進位位都為 1, 這種情況下, 只需要保證 hash 演算法的結果是均勻分布的, 那麼 HashMap 中各元素一定是均勻分布的. - HashMap 中有個欄位
threshold, 源碼註解中寫著The next size value at which to resize (capacity * load factor), 表示它用來判斷下次什麼時候擴容的欄位. 當數組發生擴容時, 只需要再比較 1 bit 即可確定這個節點是否需要移動, 要麼不動, 要麼移動原來的數組長度.
8. 為什麼 HashMap 的默認容量是 16 呢?
這應該是一個經驗值, 要保證容量為 2 的冪次, 並且需要在效率和空間上做一個權衡, 太大浪費空間, 太小需要頻繁擴容.
HashMap 與 Hashtable 的區別
| 集合 | 執行緒安全性 | 效率 | 默認容量 | 擴容方式 | 底層結構 | 實現方式 | 是否支援null值 | 迭代器 |
|---|---|---|---|---|---|---|---|---|
| HashMap | 不安全 | 高 | 16 | 2n (保證是2的冪次) | 數組+鏈表+紅黑樹 | 繼承AbstractMap類 | Key允許存在一個null, Value可以為null | Fail-fast 機制 |
| Hashtable | 安全 | 低 | 11 | 2n+1 | 數組+鏈表 | 繼承Dictionary類 | Key和Value都不能為null | Enumerator |
1. 執行緒安全性和效率
首先 HashMap 本來就不是針對多執行緒情況而設計的, Hashtable 是遺留類, 它內部使用 synchronzied 來修飾方式, 使得它能夠成為一個同步集合, 但這種方式效率比較低.
我們可以通過兩種方式來獲得同步的 HashMap.
- 第一種是使用
Collentions.synchronizedMap(Map<K,V> m)來將一個非同步 Map 變為同步 Map. 這種方式的原理比較簡單, 與 Hashtable 類似, 它會把傳入的 map 對象作為 mutex 互斥鎖對象, 然後在方法里都加上synchronized(mutex)的同步. - 第二種是使用
java.util.concurrent包下的同步集合ConcurrentHashMap, 這個集合將在下面詳細介紹.
2. 對於 null 的支援和迭代器的差異
/* HashMap 中計算 hash 值的過程 */
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/* Hashtable 中 put 的部分源碼 */
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
...
}
首先從源碼上看, Hashtable 在 put 值為 null 的 key 或者 value 時候會拋出 NullPointerException, 但是 HashMap 對值為 null 的 key 做了特殊處理. 看似很簡單的處理, 那這麼處理的內在原因是什麼呢?
Hashtable 的迭代器使用了安全失敗機制 (fail-safe), 這種機制在遍曆元素的時候, 先複製原有集合內容, 在拷貝的集合上進行遍歷, 這會使得每次讀取到的數據並不一定是最新數據. 如果可以使用 null 值, 將會無法判斷對應的 key 是不存在還是為空. ConrrentHashMap 也是同樣的道理.
HashMap 則是使用安全失敗機制 (fail-fast), 這種機制是指在用迭代器遍歷一個集合對象的時候, 如果遍歷過程中對集合對象的內容進行了修改, 則會拋出 Concurrent Modification Exception. 通過閱讀源碼, 我們可以發現這種機制使用了 modCount 變數, 每次遍歷下個元素的時候, 都會檢查 modCount 變數的值是否發生改變, 如果發生改變就會拋出異常. 我們不能依賴這個異常是否拋出來進行並發控制, 這個異常只建議用於檢測並發修改的 bug.
java.util 包下的集合 (除了同步容器: Hashtable, Vector 等) 都是 fail-fast, 而 java.util.concurrent 包下的集合和 java.util 包下的同步集合都是 fail-safe.
ConcurrentHashMap 與 Hashtable 的區別
-
它們的底層結構不一樣: ConcurrentHashMap 的底層結構與 HashMap 類似, 使用了數組+鏈表+紅黑樹, 而 Hashtable 使用了數組+鏈表.
-
它們都是執行緒安全的, 但它們實現執行緒安全的方式不一樣.
-
Hashtable 使用同一個對象鎖, 用 synchronized 來保證執行緒安全.

-
ConcurrentHashMap 在 JDK1.7 中使用分段鎖, 對整個數組進行分割來分段, 每把鎖只鎖定一部分數據, 多執行緒可以訪問不同的數據段. Segment 鎖繼承了 ReentrantLock, 是一種可重入鎖, 獲取鎖時先嘗試自旋獲取鎖, 達到最大自旋次數後改為阻塞方式獲取鎖, 保證能夠獲取成功.

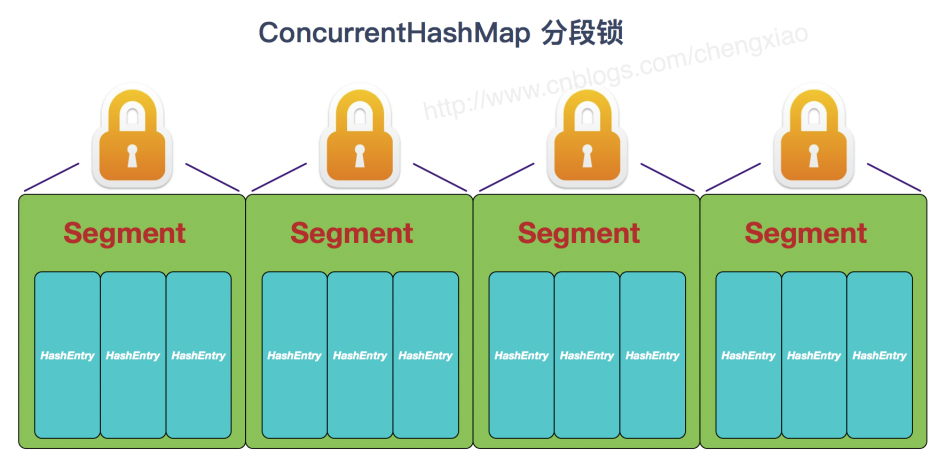
-
ConcurrentHashMap 在 JDK1.8 中不再使用分段 (Segment) 的概念, 直接用 Node 數組+鏈表+紅黑樹來實現, 使用 CAS + synchronized 來進行並發控制. sychronized 只鎖定當前鏈表或紅黑樹的頭節點, 只要 hash 不衝突就不會有並發問題.
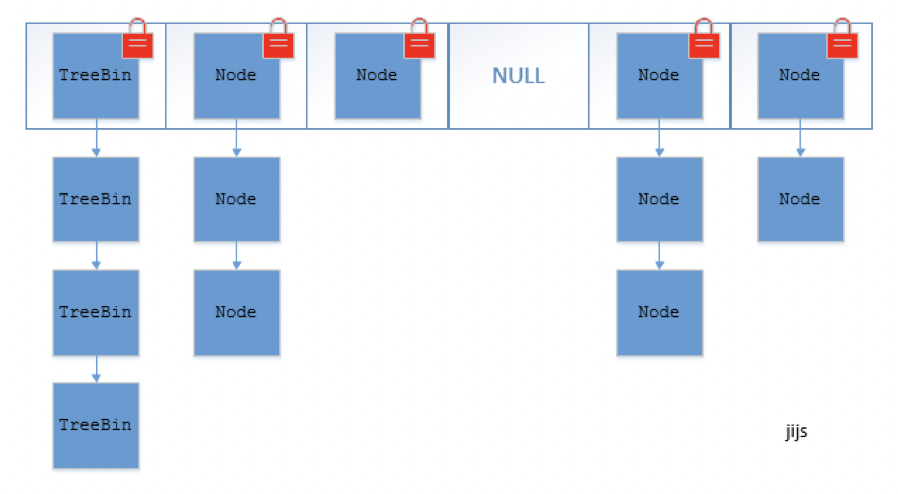
-




其他知識點
1. HashMap 與 LinkedHashMap 的區別
LinkedHashMap 繼承自 HashMap, 底層結構與 HashMap 一致, 主要區別是 LinkedHashMap 維護了一個雙向鏈表, 記錄了插入數據的順序. LinkedHashMap 十分適合用來實現 LRU 演算法, LRU 演算法主要利用了雙向鏈表和 HashMap, 這簡直就是量身打造, 要是手撕程式碼題用 LinkedHashMap 簡直是作弊, 一般面試官不會讓你這麼乾的 😛. LeetCode 146 – LRU Cache
public class LRU_Cache {
private Map<Integer, Integer> map;
public LRU_Cache(int capacity) {
// 設置 accessOrder = true 之後每次訪問元素之後都會把這個元素移動到鏈表最後
map = new LinkedHashMap<>(capacity, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
};
}
public int get(int key) { return map.getOrDefault(key, -1); }
public void put(int key, int value) { map.put(key, value); }
}
2. HashMap 與 HashSet 的區別
閱讀一下 HashSet 的源碼, 我們會發現 HashSet 是基於 HashMap 來實現的, 只不過 HashMap 的使用 key 來計算 hash 值, 而 HashSet 使用的是成員對象.
3. 同步集合執行緒安全問題
同步集合一定是執行緒安全的嗎? 其實同步集合只能保證單個方法操作是執行緒安全的, 而對這些集合的複合操作是無法保證其執行緒安全性, 需要主動加鎖來保證執行緒安全. 例子如下:
public void deleteLastElement(Vector v) {
int lastIdx = v.size() - 1;
v.remove(lastIdx);
}
4. N 個元素要加入 HashMap, 初始化為多大合適?
為了避免頻繁的擴容操作, 我們應該盡量一次性初始化所需要的空間.
如果負載因子為 0.75, 假設 N = 16, 由於 threshold = capacity * load factor = 16 * 0.75 = 12, 當加入第 12 個元素的時候, HashMap 就需要擴容了, 因此直接初始化為 32 最為合適.
從上面這個例子中可以看出規律, 我們應該直接初始化 HashMap 的容量為 capacity = N / load factor, 並且將 capacity 向上取至 2 的冪次.


