Java:手寫幼兒園級執行緒安全LRU快取X探究影響命中率的因素
- 2020 年 5 月 7 日
- 筆記
最近遇到一個需求,需要頻繁訪問資料庫,但是訪問的內容只是 id + 名稱 這樣的簡單鍵值對。
頻繁的訪問資料庫,網路上和記憶體上都會給資料庫伺服器帶來不小負擔。
於是打算寫一個簡單的LRU快取來快取這樣的鍵值對。考慮到tomcat的用戶辦法訪問是多執行緒進行的。
所以還要保證cache是執行緒安全的。避免在用戶操作的時候修改了cache導致其他用戶讀到不合法的資訊。
構思
一, 數據結構選取
思路:
1.最簡單的是用鏈表,最新訪問的元素所在節點插入到頭節點的後面,當要回收的時候就去釋放鏈表尾部節點。
問題 : 如果數據量巨大,那麼這條鏈表就會十分長,即使是線性時間複雜度的查找,也會耗掉不少時間。
2.打散鏈表,採用散列法,將節點散列到散列表中,這樣,我們一長條的鏈表就會被打散成若干長度更小的鏈表。
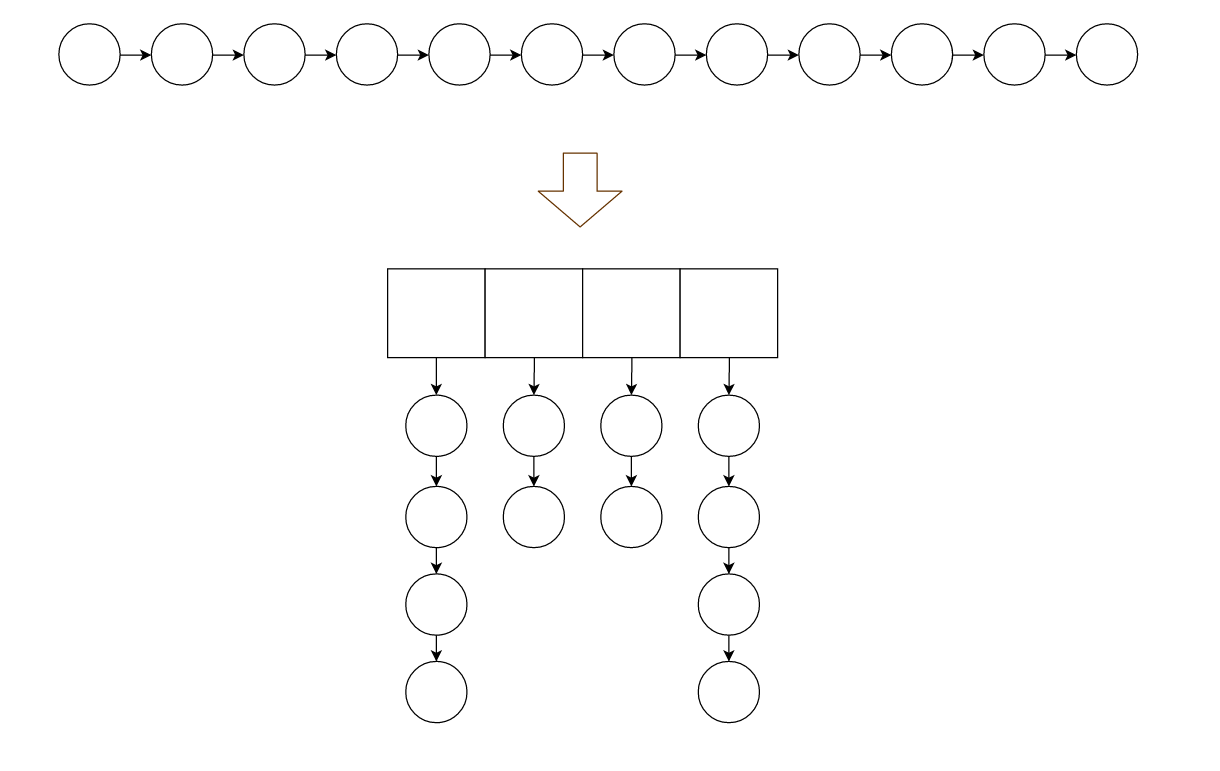
假如我們的散列演算法設計得當,讓整個鏈表均勻的灑在散列表上,那麼所用時間最壞情況可以 變成原本的 1/m , m是散列表的大小。
3.在2中,雖然我們使用了散列表來打散,但是如果散列演算法不當,或者正好碰到最壞情況,還是有可能節點集中在一條鏈上。
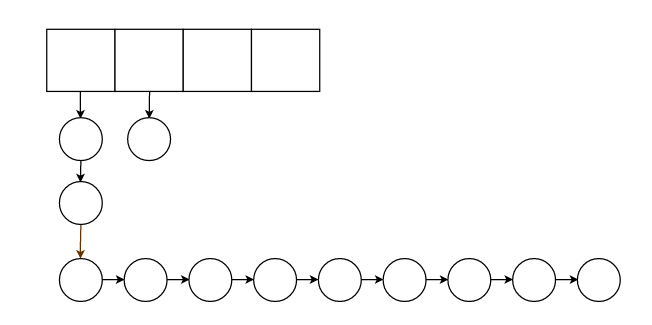
所以我們可以把鏈表設計成樹,這樣我們就保證了最壞時的logN級的查找複雜度。
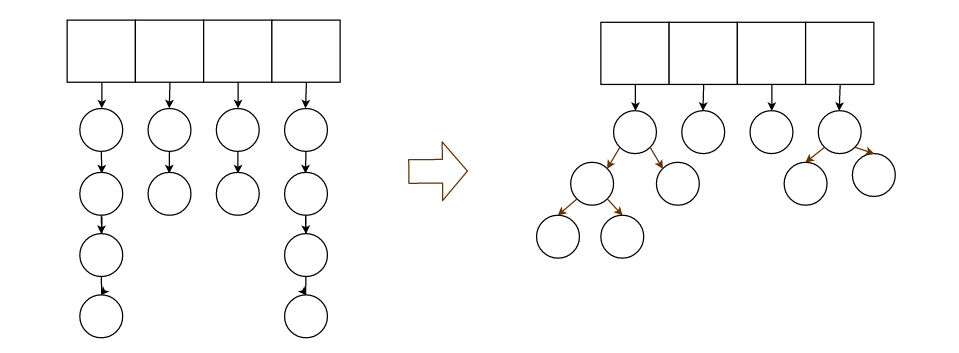
總體上方法3會比2高效,但是實現起來複雜得多,所以我們採用方法2。
二, 回收策略
回收的時候需要考慮到
1.怎麼樣讓回收的內容在最近儘可能不被訪問到,這可能需要結合自己的程式業務來決定,一般的做法是回收最近最少使用的內容,不可能準確預測某內容在不久
的將來不被訪問。
2.回收內容之後需要讓整個存儲結構儘可能均勻,儘可能不出現
這種情況。
於是採取策略,回收最長的那個鏈表的末尾節點,這種做法不能說百分百可靠,
可能因為散列演算法設計不合理,導致節點都聚集在某個槽中,這樣的話那個槽的鏈表就會特別長。
這時這個鏈表上的節點總是要訪問的,但是我們回收的是最長的鏈表,那麼我們總是在回收最近要訪問的內容
就很不合理,但是如果我們的散列演算法得當,那麼我們就能回收的同時保持整個散列表結構邏輯上均勻。
絕對均勻也不好,因為如果絕對均勻,那麼就沒有一個較長的鏈表,可以快取儘可能多,最近被頻繁訪問的內容。
所以,散列演算法的設計十分重要。
三, 執行緒安全
執行緒安全,這裡是簡單地採用 ReentrantReadWriteLock,分為讀寫兩把鎖,在讀取快取但不寫的時候,佔用讀鎖。
如果沒命中,需要向散列表中寫新內容,或修改,則佔用寫鎖。
注意點:
並發編程使用 ReentrantReadWriteLock 無法做到鎖升級,需要釋放讀鎖之後再獲取寫鎖。
在釋放讀鎖到獲取寫鎖之間,需要考慮到所有其他執行緒獲取寫鎖修改某些我們需要的量的情況。
比如我們對A訪問用讀寫鎖R
R.readLock().lock();
M = null;
//0
if(A != null){
M = A;
}
R.readLock().unlock();
//1
R.writeLock().lock();
//2
function(M);
A = new XX();
在1處,可能有其他執行緒先佔有了寫鎖,並且執行完了2之後的程式碼,所以我們在0處的判斷就失效了。
所以在2之後還需要判斷
//2
if(A != null){
M = A;
}
也就是要考慮釋放讀鎖與獲取寫鎖之間,其他執行緒可能獲取寫鎖修改某些共享量。
在下面的程式碼注釋中有詳細說明
開始編寫
首先,我們要實現我們選取的數據結構,這裡選的是2中的數據結構。
3中的數據結構讀者可以自行實現,需要注意的是,樹如果旋轉,則需要把旋轉後的根節點掛到散列表上
1.鏈表設計
我們知道,鏈表的脫鏈和掛入有時候需要檢查前驅後繼節點是否非空。這使得我們的程式碼實現起來很複雜,而且維護的時候閱讀也不方便。
於是我們打算讓一根鏈表生來就有頭和尾節點,這兩個節點存放的值是無用的,這兩個節點是閑置的,這樣我們刪除鏈表中的某個節點時
就不用檢查他的前驅後繼是否非空,因為有一開始的兩個頭尾節點,前驅後繼肯定非空。
我們回收的時候回收的是尾節點的前一個節點。有一種特殊情況,如果頭節點和尾節點之間沒有其他節點呢?回收的不就是頭節點?
我們的回收策略是回收長度最長的鏈表中的節點,並且當整個散列表的大小到達了特定值才會回收,所以一般不會回收頭節點。
雖然多了頭和尾兩個節點,但是相比於我們成千上萬的數據,微不足道。
private class Node{ /** * 當前節點的id */ long now; /** * id - 名稱鍵值對中的名稱 */ String name; /** * 前驅 */ Node pre; /** * 後繼 */ Node next; }
2.每條鏈表的管理結構
為了管理每個鏈表,比如記錄鏈表的長度資訊,保存鏈表的頭尾指針(引用)。我們需要用一個數據結構管理鏈表
private class HeadManager{ /** * 鏈接前一個管理結構(鏈表長度小於等於當前鏈表)和後一個管理結構(鏈表長度大於等於當前鏈表) */ HeadManager pre, next; /** * 當前鏈表的長度 */ int size = 0; /** * 鏈表中閑置的頭節點 * */ Node head = new Node(); /** * 鏈表中閑置的尾節點 */ Node tail = new Node(); { /* * 一開始讓首尾相連 */ head.next = tail; tail.pre = head; } }
這些管理結構是按照各自的鏈表長度大小組織成一條鏈表的,我們暫且稱之為管理鏈表。當我們要回收節點的時候,就去找管理鏈表末尾的管理結構,把他的倒數第二個節點釋放(尾節點閑置)。同樣我們也需要閑置的管理結構頭節點和尾節點來簡化我們的程式碼。
總體框架:
public class PlatformCache { /** * 當整個散列表中的值超過這個大小,就會開始回收 */ private static final int MAX_SIZE = 1024; /** * 散列表所在數組的初始大小 */ private static final int INIT_SIZE = 64; private static Double rate = 0.0; private static Double time = 0.0; /** * 讀寫鎖 */ private ReentrantReadWriteLock reentrantReadWriteLock; /** * 整個散列表中的節點數 */ private int size; /** * 散列表 */ private HeadManager[] tables; /** * 管理結構鏈表中的閑置頭 */ private HeadManager inOrderHead; /** * 管理結構鏈表中的閑置尾 */ private HeadManager inOrderTail; /** * 單例 */ private static PlatformCache instance;
}
/**
* 獲取單例
*/
public static PlatformCache getInstance(){ if(instance == null){ synchronized (PlatformCache.class){ if(instance == null){ instance = new PlatformCache(); } } } return instance; }
public String getName(long id){ try {//鎖讀鎖 防止讀入時修改 reentrantReadWriteLock.readLock().lock(); //簡單散列 int index = hash(id); HeadManager manager = tables[index]; //如果管理結構不在散列表中 就讓fresh = true boolean fresh = false; if(manager != null){ Node head = manager.head.next; while(head != null && head != manager.tail){ //命中 if(id == head.now){ reentrantReadWriteLock.readLock().unlock(); reentrantReadWriteLock.writeLock().lock(); //到這裡的時候,可能有其他執行緒操作過我們命中了的節點 //所以需要看一下我們的節點有沒有被刪除(前驅後繼為空) if(head.pre == null || head.next == null){ //如果刪除了,就跳出循環,和沒命中合併成同一種情況 reentrantReadWriteLock.readLock().lock(); reentrantReadWriteLock.writeLock().unlock(); break; } //移到前面 表示最近訪問過 moveForward(manager, head);return head.name; } head = head.next; } }else{ fresh = true; } //訪問資料庫 Platform platform = mapper.selectByPrimaryKey(id); if(platform != null){ reentrantReadWriteLock.readLock().unlock(); //1 reentrantReadWriteLock.writeLock().lock(); //這裡的檢查很重要 因為在1處可能別的執行緒獲得了鎖 //修改了我們要訪問的index下標處的內容 if(tables[index] == null){ //創建新的 管理結構 並掛到散列表上 manager = new HeadManager(); tables[index] = manager; }else{ //如果其他執行緒創建了管理結構 //那麼他們可能把我們想要的節點放到鏈表中了 //所以再次遍歷節點,看看能否找到 manager = tables[index]; fresh = false; Node head = manager.head.next; while(head != null && head != manager.tail){ //命中 if(id == head.now){ //下面不用加寫鎖因為當前已經獲得寫鎖 //移到前面 表示最近訪問過 moveForward(manager, head); return head.name; } head = head.next; } } //新建一個Node Node more = new Node(); more.name = platform.getPlatformName(); more.now = platform.getPlatformId(); //插入到鏈表中閑置頭節點的下一位 Node now = manager.head.next; manager.head.next = more; more.next = now; now.pre = more; more.pre = manager.head; //更改管理結構管理的鏈表大小和總大小 manager.size ++; size ++; if(fresh){ //如果新建了管理結構 就把管理結構掛入到大小隊列 insertBeforeHead(manager); } //管理結構的鏈表大小增加時排序管理結構隊列 whenInc(manager); //超出了我們的預算,則進行回收 if(size > MAX_SIZE){ if(inOrderTail.pre == inOrderHead){ logger.error("快取中頭和尾之間沒有快取節點!"); throw new ServiceException("快取錯誤已經記錄日誌"); } //刪除鏈表長度最大的管理結構的鏈表尾節點的前一個節點 //inOrderTail是閑置的管理結構尾節點 //inOrderTail.pre是鏈表長度最大的管理結構 //inOrderTail.pre.tail是鏈表閑置的尾節點 //inOrderTail.pre.tail.pre真正需要回收的節點 deleteNode(inOrderTail.pre.tail.pre); //管理結構的鏈表長度和散列表總大小均-1 inOrderTail.pre.size --; size --; whenDec(inOrderTail.pre); } return platform.getPlatformName(); } return null; }finally { //釋放所有鎖 try { //保險起見 固定釋放讀寫鎖 try { if(reentrantReadWriteLock.writeLock().isHeldByCurrentThread()){ reentrantReadWriteLock.writeLock().unlock(); } }catch (Exception e){ } try { reentrantReadWriteLock.readLock().unlock(); }catch (Exception e){ } }catch (Exception e){ //可以寫入日誌 } } }
輔助性方法外提:
private void deleteNode(Node node){ Node next = node.next; node.pre.next = next; next.pre = node.pre; node.pre = node.next = null; } /** * 往後找,找到鏈表長度比自己小的管理結構,並且插到他後面 */ private void whenInc(HeadManager manager){ HeadManager back = manager.next; while(back.size < manager.size && back != inOrderTail){ back = back.next; } manager.pre.next = manager.next; manager.next.pre = manager.pre; HeadManager pre = back.pre; pre.next = manager; manager.pre = pre; back.pre = manager; manager.next = back; } private void insertBeforeHead(HeadManager manager) { HeadManager now = inOrderHead.next; inOrderHead.next = manager; manager.next = now; now.pre = manager; manager.pre = inOrderHead; } private int hash(Long id){ Long tmp = id; id ^= tmp >>> 32; id ^= tmp >>> 16; id ^= tmp >>> 8; id ^= tmp >>> 4; return Math.toIntExact(id & (tables.length - 1)); } /** * 往前找,找到鏈表長度比自己大的管理結構,並且插到他前面 */ private void whenDec(HeadManager manager){ HeadManager front = manager.pre; while(front.size > manager.size && front != inOrderHead){ front = front.pre; } manager.pre.next = manager.next; manager.next.pre = manager.pre; HeadManager next = front.next; front.next = manager; next.pre = manager; manager.pre = front; manager.next = next; }
//被訪問的節點放在鏈表頭部 private void moveForward(HeadManager manager, Node head){ Node now = manager.head; Node next = head.next; head.pre.next = next; next.pre = head.pre; head.pre = now; head.next = now.next; now.next.pre = head; now.next = head; }
測試
測試了一下,不是很OK。
測試環境:
硬體: i5 4核CPU 記憶體8G
軟體: Jmeter 300執行緒,每次請求使用limit 隨機數,50 請求50條數據,資料庫表中總共有3300條數據
tomcat7.0
JDK8.0
散列表的大小是64
最大容納Node個數是1024
系統跑到穩定的時候,命中率平均大概只有40%
其中穩定後的一組:
命中率: 0.3817002017558209
各個鏈表長度:
0 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 0
Manager總數: 64
Node總數: 1024.0
方差: 8.0
散列表大小:64
可以看出我們每個管理結構的鏈表長度都相等,整個散列表均勻,但是命中率實在太低。
我們改變一些量來嘗試提高命中率。
嘗試1.改變散列演算法
原本的散列法:
散列演算法1:
int index = Math.toIntExact((id & (tables.length - 1)));
直接用以散列表長度-1 做為掩碼取後幾位做為下標。
我們採用新的散列演算法:
將id每一位的特徵都用上。
散列演算法2:
private int hash(Long id){ id |= id >> 8; id |= id >> 8; id |= id >> 8; id |= id >> 8; return Math.toIntExact(id & (tables.length - 1)); }
看看命中率會不會提高。
運行穩定後,命中率上升到50%左右。
運行穩定後的一組數據:
命中率: 0.5101351858242434
各個鏈表長度:
0 1 2 3 6 7 7 7 8 8 9 9 9 9 9 10 10 11 11 12 14 16 16 16 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 21 21 21 21 21 21 21 21 21 21 21 21 21 21 0
Manager總數: 63
Node總數: 1024.0
方差: 43.465388506960714
散列表大小 : 64
我們發現,雖然均勻程度下降,但是命中率有所上升,因為充分利用了元素標識id的特徵。元素散列到散列表中的位置更有獨特性。
當然,因為我們用的是按位或,所以元素會往數組下標大的方向聚集。
所以進一步改進我們的hash演算法
散列演算法3:
private int hash(Long id){ Long tmp = id; id ^= tmp >>> 32; id ^= tmp >>> 16; id ^= tmp >>> 8; id ^= tmp >>> 4; return Math.toIntExact(id & (tables.length - 1)); }
我們讓每一位都參與到特徵值的生成中,但是減少了往下標大的地方聚集的趨勢
穩定後結果:
命中率: 0.561265216523648
各個鏈表長度:
0 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 0
Manager總數: 64
Node總數: 1024.0
方差: 8.0
散列表大小 : 64
我們發現散列表變得均勻,命中率相應也上升了不少。
與散列演算法1比起來,散列表都是均勻的,為什麼命中率高了接近20%呢?
原因可能是因為:演算法1的散列表均勻是回收演算法造成的,演算法1散列的結果仍然很不均勻,導致散列出的下標集中在某些地方。
頻繁地對這些地方進行訪問,可能頻繁的在這些地方插入節點,所以這些活躍區域,也是長度增長最快的區域,而回收的時候又
總是回收這些活躍區域,導致我們不久之前剛剛創建的節點總是被回收,導致命中率下降。
演算法2雖然也是保持散列表均勻,但是對散列表的訪問因為散列演算法散列得得當,所以分散得比較開,所以是
「在均勻情況下,增加一個,回收一個,而且大大減少了回收的是最近訪問過的節點的概率」
嘗試2.改變散列表的大小,但不改變最大Node數量
最大節點數還是1024,而散列表的槽數增加成128。
運行穩定後,命中率沒有明顯的上升。
原因可能是因為就算增加了槽數,但總的節點數不變,該回收還是回收,導致命中率沒有明顯上升。
但是鏈表的平均長度減小,在鏈表中遍歷查詢元素的時間減少。
使用散列演算法2.
命中率: 0.5074192929043583
各個鏈表長度:
0 1 1 1 1 1 2 2 2 3 3 3 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 7 7 8 8 8 8 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 11 11 11 11 11 11 11 11 11 11 11 11 11 0
Manager總數: 125
Node總數: 1024.0
方差: 9.836877824000004
使用散列演算法3.
命中率: 0.5587484035759898
各個鏈表長度:
0 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 0
Manager總數: 128
Node總數: 1024.0
方差: 1.0
嘗試3.散列表大小不變,增加節點個數
這個方法大概率是會增加命中率的,因為減少了回收次數,而且節點數接近我們記錄總數的時候,命中率甚至可能接近100%。
最大節點數增加成是2048,散列表的槽數為128。
運行穩定後: 命中率接近100%
使用散列演算法2.
命中率: 0.9811895632415405
各個鏈表長度:
0 1 1 1 1 1 2 2 2 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 6 7 8 8 8 8 8 9 9 9 10 10 10 11 11 11 11 11 11 11 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 13 14 14 14 15 15 15 15 15 16 16 16 17 18 18 18 18 18 20 20 20 20 20 21 21 22 22 23 25 34 35 37 37 37 37 38 38 39 40 40 40 41 41 42 45 46 49 49 49 49 50 50 50 0
Manager總數: 125
Node總數: 2048.0
方差: 198.067511296
嘗試4.改變回收策略
簡單的採取回收當前位置的末尾節點。
比如我們在0號位置插入一個新增的Node,導致整個散列表節點數超過了最大值,那麼就直接回收0號位置的末尾節點(不是真正的末尾節點,真正的末尾節點被閑置)
使用散列演算法2
命中率: 0.5508982035928144
0 0 0 0 0 0 0 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 8 8 8 8 9 9 10 10 10 10 10 10 11 11 11 11 12 12 12 13 13 14 15 16 16 17 18 19 20 20 20 20 21 21 22 23 23 24 25 28 29 29 31 34 0
Manager總數: 125
Node總數: 1024.0
方差: 57.676877824
散列表大小 : 128
使用散列演算法3
命中率: 0.561866802451144
0 1 4 4 4 4 4 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 11 11 11 11 11 11 11 11 11 11 12 12 12 12 13 14 0
Manager總數: 128
Node總數: 1024.0
方差: 5.578125
散列表大小 : 128
命中率並沒有多大的變化,但是散列表均勻程度下降。
擴容與重散列:
明天考試,以後再更
最終採用了:
1.散列演算法3,保證散列的均勻性
2.回收最長鏈表
3.最大節點數 : 採用總數據量的45%。比如總共有1000條數據,則最多有450個節點。選取的理由是命中率可以達到80%,滿足我的業務需求

1500 / 3300 約等於 45%
當然,這是我的雞肋業務,如果真的要用到海量數據的業務中去,則僅供參考。
有不妥之處,多謝指出。


