大batch任務對structured streaming任務影響
- 2020 年 5 月 7 日
- 筆記
- spark, spark streaming
信念,你拿它沒辦法,但是沒有它你什麼也做不成。—— 撒姆爾巴特勒
前言
對於spark streaming而言,大的batch任務會導致後續batch任務積壓,對於structured streaming任務影響如何,本篇文章主要來做一下簡單的說明。
本篇文章的全稱為設置trigger後,運行時間長的 query 對後續 query 的submit time的影響
Trigger類型
首先trigger有三種類型,分別為 OneTimeTrigger ,ProcessingTime 以及 ContinuousTrigger 三種。這三種解釋可以參照 spark 集群優化 中對 trigger的解釋說明。
設置OneTimeTrigger後,運行時間長的 query 對後續 query 的submit time的影響
OneTimeTrigger只執行一次query就結束了,不存在對後續batch影響。
設置ProcessingTimeTrigger後,運行時間長的 query 對後續 query 的submit time的影響
設置超過 trigger inverval的sleep時間
程式碼截圖如下,即在每一個partition上的task中添加一個sleep邏輯:

運行效果
運行效果截圖如下:
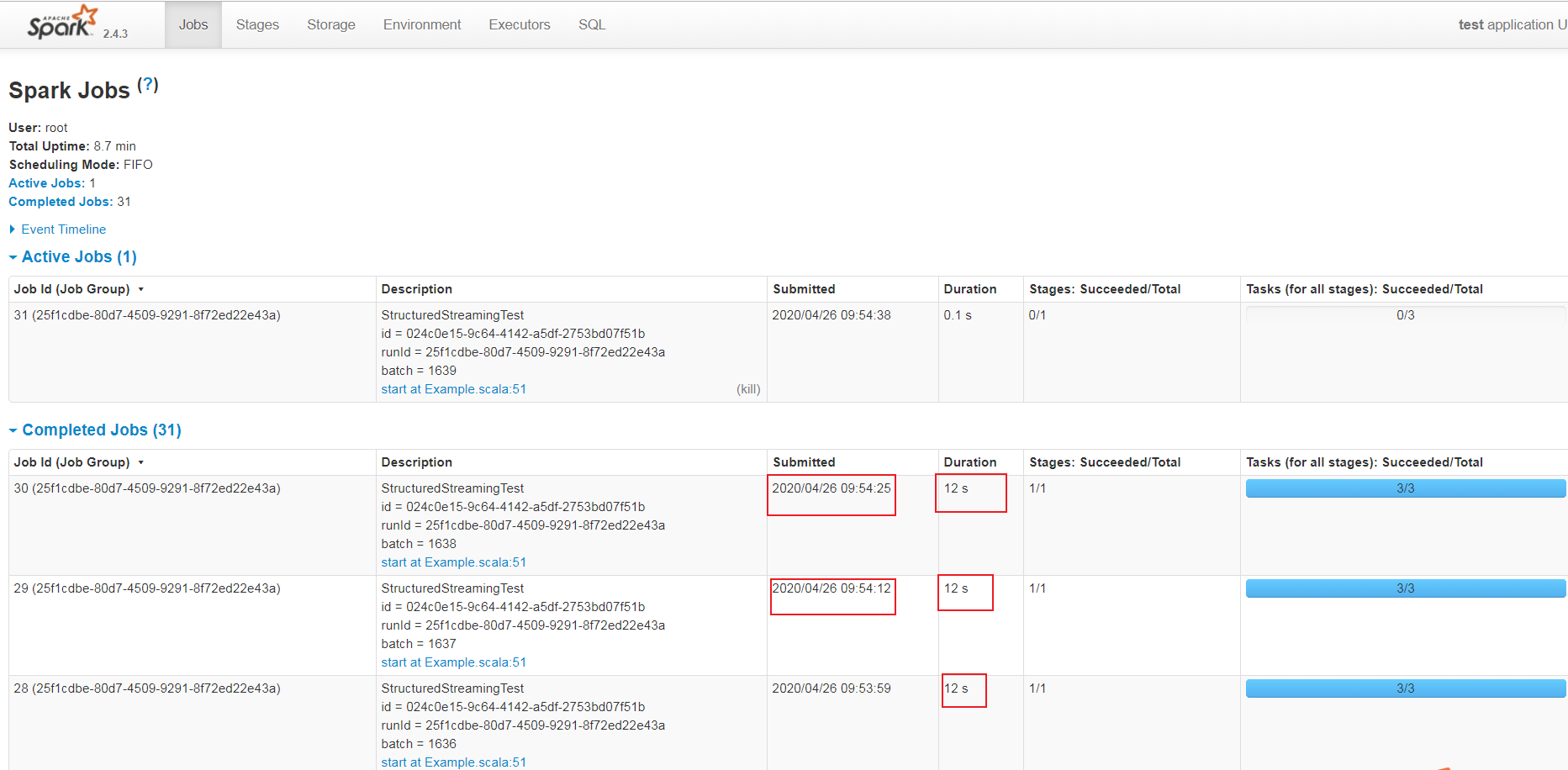
UI的Jobs面板截圖如下:
UI的SQL面板截圖如下:
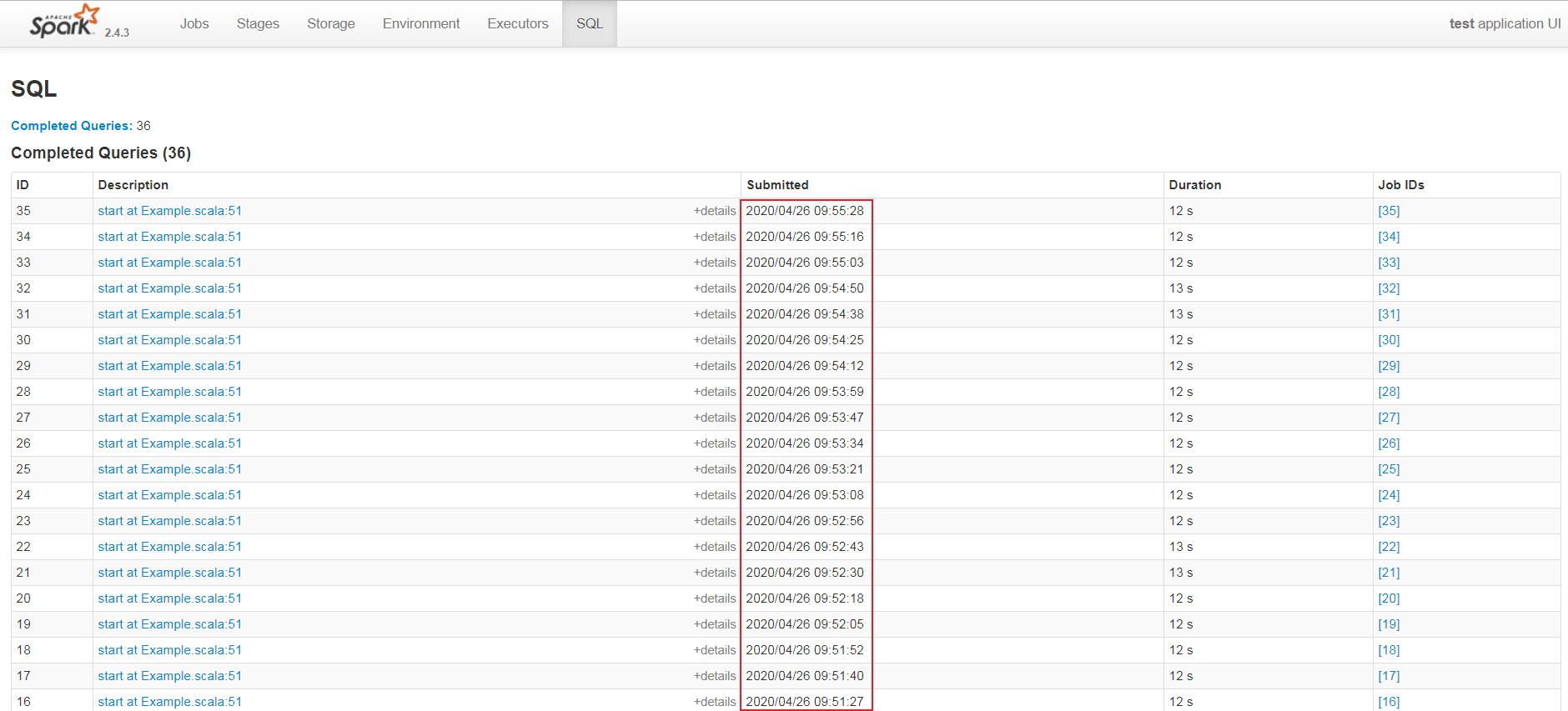
通過上面兩個面板截圖中的submitted列可以看出,此時每一個batch的query 提交時間是根據前驅query的結束時間來確定的。
設置 ContinuousTrigger 後,運行時間長的 query 對後續 query 的submit time的影響
源碼分析
下面從源碼角度來分析一下。
StreamExecution的職責
它是當新數據到達時在後台連續執行的查詢的句柄。管理在單獨執行緒中發生的流式Spark SQL查詢的執行。 與標準查詢不同,每次新數據到達查詢計劃中存在的任何 Source 時,流式查詢都會重複執行。每當新數據到達時,都會創建一個 QueryExecution,並將結果以事務方式提交給給定的 Sink 。
它有兩個子類,截圖如下:

Tigger和StreamExecution的對應關係
在org.apache.spark.sql.streaming.StreamingQueryManager#createQuery方法中有如下程式碼片段:
1 (sink, trigger) match { 2 case (v2Sink: StreamWriteSupport, trigger: ContinuousTrigger) => 3 if (sparkSession.sessionState.conf.isUnsupportedOperationCheckEnabled) { 4 UnsupportedOperationChecker.checkForContinuous(analyzedPlan, outputMode) 5 } 6 // 使用 ContinuousTrigger 則為 ContinuousExecution 7 new StreamingQueryWrapper(new ContinuousExecution( 8 sparkSession, 9 userSpecifiedName.orNull, 10 checkpointLocation, 11 analyzedPlan, 12 v2Sink, 13 trigger, 14 triggerClock, 15 outputMode, 16 extraOptions, 17 deleteCheckpointOnStop)) 18 case _ => 19 // 使用 ProcessingTrigger 則為 MicroBatchExecution 20 new StreamingQueryWrapper(new MicroBatchExecution( 21 sparkSession, 22 userSpecifiedName.orNull, 23 checkpointLocation, 24 analyzedPlan, 25 sink, 26 trigger, 27 triggerClock, 28 outputMode, 29 extraOptions, 30 deleteCheckpointOnStop)) 31 }
可以看出,Tigger和對應的StreamExecution的關係如下:
|
Trigger
|
StreamExecution
|
|---|---|
| OneTimeTrigger | MicroBatchExecution |
| ProcessingTrigger | MicroBatchExecution |
| ContinuousTrigger | ContinuousExecution |
另外,StreamExecution構造參數中的analyzedPlan是指LogicalPlan,也就是說在第一個query啟動之前,LogicalPlan已經生成,此時的LogicalPlan是 UnResolved LogicalPlan,因為此時每一個AST依賴的數據節點的source資訊還未知,還無法優化LogicalPlan。
注意
ContinuousExecution支援的source類型目前有限,主要為StreamWriteSupport子類,即:
|
source
|
class full name
|
|---|---|
| console | org.apache.spark.sql.execution.streaming.ConsoleSinkProvider |
| kafka | org.apache.spark.sql.kafka010.KafkaSourceProvider |
| ForeachSink | org.apache.spark.sql.execution.streaming.sources.ForeachWriterProvider |
| MemorySinkV2 | org.apache.spark.sql.execution.streaming.sources.MemorySinkV2 |
否則會匹配到 MicroBatchExecution, 但是在初始化 triggerExecution成員變數時,只支援ProcessingTrigger,不支援 ContinuousTrigger,會拋出如下異常:

StreamExecution的執行
org.apache.spark.sql.streaming.StreamingQueryManager#startQuery有如下程式碼片段:
1 try { 2 // When starting a query, it will call `StreamingQueryListener.onQueryStarted` synchronously. 3 // As it's provided by the user and can run arbitrary codes, we must not hold any lock here. 4 // Otherwise, it's easy to cause dead-lock, or block too long if the user codes take a long 5 // time to finish. 6 query.streamingQuery.start() 7 } catch { 8 case e: Throwable => 9 activeQueriesLock.synchronized { 10 activeQueries -= query.id 11 } 12 throw e 13 }
這裡的query.streamingQuery就是StreamExecution,即為MicroBatchExecution 或 ContinuousExecution。
StreamExecution的start 方法如下:
1 /** 2 * Starts the execution. This returns only after the thread has started and [[QueryStartedEvent]] 3 * has been posted to all the listeners. 4 */ 5 def start(): Unit = { 6 logInfo(s"Starting $prettyIdString. Use $resolvedCheckpointRoot to store the query checkpoint.") 7 queryExecutionThread.setDaemon(true) 8 queryExecutionThread.start() 9 startLatch.await() // Wait until thread started and QueryStart event has been posted 10 }
queryExecutionThread成員變數聲明如下:
1 /** 2 * The thread that runs the micro-batches of this stream. Note that this thread must be 3 * [[org.apache.spark.util.UninterruptibleThread]] to workaround KAFKA-1894: interrupting a 4 * running `KafkaConsumer` may cause endless loop. 5 */ 6 val queryExecutionThread: QueryExecutionThread = 7 new QueryExecutionThread(s"stream execution thread for $prettyIdString") { 8 override def run(): Unit = { 9 // To fix call site like "run at <unknown>:0", we bridge the call site from the caller 10 // thread to this micro batch thread 11 sparkSession.sparkContext.setCallSite(callSite) 12 runStream() 13 } 14 }
其中,QueryExecutionThread 是 UninterruptibleThread 的子類,UninterruptibleThread 是 Thread的子類,即QueryExecutionThread 是一個執行緒類。他會運行runStream方法,runStream關鍵程式碼如下:
try { // 運行Stream query的準備工作,send QueryStartedEvent event, countDown latch,streaming configure等操作 runActivatedStream(sparkSessionForStream) // 運行 stream } catch { // 異常處理 } finally { // 運行完Stream query的收尾工作,stop source,send stream stop event,刪除checkpoint(如果啟用deleteCheckpointOnStop)等等操作 }
runActivatedStream 說明:Run the activated stream until stopped. :它是抽象方法,由子類實現。
MicroBatchExecution的runActivatedStream的實現
MicroBatchExecution 的 runActivatedStream的方法邏輯描述如下:
1 triggerExecutor.execute(() =>{ 2 提交執行每一個query的操作 3 })
triggerExecution 的定義如下:
private val triggerExecutor = trigger match { case t: ProcessingTime => ProcessingTimeExecutor(t, triggerClock) case OneTimeTrigger => OneTimeExecutor() case _ => throw new IllegalStateException(s"Unknown type of trigger: $trigger") }
即使用 ProcessingTime 會使用 ProcessingTimeExecutor 來周期性生成 batch query,其 execution 方法程式碼如下:
1 override def execute(triggerHandler: () => Boolean): Unit = { 2 while (true) { 3 val triggerTimeMs = clock.getTimeMillis 4 val nextTriggerTimeMs = nextBatchTime(triggerTimeMs) 5 val terminated = !triggerHandler() 6 if (intervalMs > 0) { 7 val batchElapsedTimeMs = clock.getTimeMillis - triggerTimeMs 8 if (batchElapsedTimeMs > intervalMs) { 9 notifyBatchFallingBehind(batchElapsedTimeMs) 10 } 11 if (terminated) { 12 return 13 } 14 clock.waitTillTime(nextTriggerTimeMs) 15 } else { 16 if (terminated) { 17 return 18 } 19 } 20 } 21 }
偽程式碼如下:
def execute(triggerHandler: () => Boolean): Unit = { while(true) { 獲取current_time 根據current_time和interval獲取下一個批次start_time 執行query任務獲取並獲取是否結束stream的標誌位 if(interval > 0) { query使用時間 = 新獲取的current_time - 舊的current_time if(query使用時間 > interval) { notifyBatchFallingBehind // 目前只是列印warn日誌 } if(stream終止標誌位為true){ return // 結束這個while循環退出方法 } // Clock.waitTillTime SystemClock子類通過while + sleep(ms)實現,其餘子類通過while + wait(ms) 來實現,使用while是為了防止外部中斷導致wait時間不夠 } else { if(stream終止標誌位為true){ return // 結束這個while循環退出方法 } } } }
即stream沒有停止情況下,下一個batch的提交時間為 = 當前batch使用時間 > interval ? 當前batch結束時間:本批次開始時間 / interval * interval + interval
ContinuousExecution的runActivatedStream的實現
源碼如下:
1 override protected def runActivatedStream(sparkSessionForStream: SparkSession): Unit = { 2 val stateUpdate = new UnaryOperator[State] { 3 override def apply(s: State) = s match { 4 // If we ended the query to reconfigure, reset the state to active. 5 case RECONFIGURING => ACTIVE 6 case _ => s 7 } 8 } 9 10 do { 11 runContinuous(sparkSessionForStream) 12 } while (state.updateAndGet(stateUpdate) == ACTIVE) 13 }
其中,runContinuous 源碼如下:
/** * Do a continuous run. * @param sparkSessionForQuery Isolated [[SparkSession]] to run the continuous query with. */ private def runContinuous(sparkSessionForQuery: SparkSession): Unit = { // A list of attributes that will need to be updated. val replacements = new ArrayBuffer[(Attribute, Attribute)] // Translate from continuous relation to the underlying data source. var nextSourceId = 0 continuousSources = logicalPlan.collect { case ContinuousExecutionRelation(dataSource, extraReaderOptions, output) => val metadataPath = s"$resolvedCheckpointRoot/sources/$nextSourceId" nextSourceId += 1 dataSource.createContinuousReader( java.util.Optional.empty[StructType](), metadataPath, new DataSourceOptions(extraReaderOptions.asJava)) } uniqueSources = continuousSources.distinct val offsets = getStartOffsets(sparkSessionForQuery) var insertedSourceId = 0 val withNewSources = logicalPlan transform { case ContinuousExecutionRelation(source, options, output) => val reader = continuousSources(insertedSourceId) insertedSourceId += 1 val newOutput = reader.readSchema().toAttributes assert(output.size == newOutput.size, s"Invalid reader: ${Utils.truncatedString(output, ",")} != " + s"${Utils.truncatedString(newOutput, ",")}") replacements ++= output.zip(newOutput) val loggedOffset = offsets.offsets(0) val realOffset = loggedOffset.map(off => reader.deserializeOffset(off.json)) reader.setStartOffset(java.util.Optional.ofNullable(realOffset.orNull)) StreamingDataSourceV2Relation(newOutput, source, options, reader) } // Rewire the plan to use the new attributes that were returned by the source. val replacementMap = AttributeMap(replacements) val triggerLogicalPlan = withNewSources transformAllExpressions { case a: Attribute if replacementMap.contains(a) => replacementMap(a).withMetadata(a.metadata) case (_: CurrentTimestamp | _: CurrentDate) => throw new IllegalStateException( "CurrentTimestamp and CurrentDate not yet supported for continuous processing") } val writer = sink.createStreamWriter( s"$runId", triggerLogicalPlan.schema, outputMode, new DataSourceOptions(extraOptions.asJava)) val withSink = WriteToContinuousDataSource(writer, triggerLogicalPlan) val reader = withSink.collect { case StreamingDataSourceV2Relation(_, _, _, r: ContinuousReader) => r }.head reportTimeTaken("queryPlanning") { lastExecution = new IncrementalExecution( sparkSessionForQuery, withSink, outputMode, checkpointFile("state"), runId, currentBatchId, offsetSeqMetadata) lastExecution.executedPlan // Force the lazy generation of execution plan } sparkSessionForQuery.sparkContext.setLocalProperty( StreamExecution.IS_CONTINUOUS_PROCESSING, true.toString) sparkSessionForQuery.sparkContext.setLocalProperty( ContinuousExecution.START_EPOCH_KEY, currentBatchId.toString) // Add another random ID on top of the run ID, to distinguish epoch coordinators across // reconfigurations. val epochCoordinatorId = s"$runId--${UUID.randomUUID}" currentEpochCoordinatorId = epochCoordinatorId sparkSessionForQuery.sparkContext.setLocalProperty( ContinuousExecution.EPOCH_COORDINATOR_ID_KEY, epochCoordinatorId) sparkSessionForQuery.sparkContext.setLocalProperty( ContinuousExecution.EPOCH_INTERVAL_KEY, trigger.asInstanceOf[ContinuousTrigger].intervalMs.toString) // Use the parent Spark session for the endpoint since it's where this query ID is registered. val epochEndpoint = EpochCoordinatorRef.create( writer, reader, this, epochCoordinatorId, currentBatchId, sparkSession, SparkEnv.get) val epochUpdateThread = new Thread(new Runnable { override def run: Unit = { try { triggerExecutor.execute(() => { startTrigger() if (reader.needsReconfiguration() && state.compareAndSet(ACTIVE, RECONFIGURING)) { if (queryExecutionThread.isAlive) { queryExecutionThread.interrupt() } false } else if (isActive) { currentBatchId = epochEndpoint.askSync[Long](IncrementAndGetEpoch) logInfo(s"New epoch $currentBatchId is starting.") true } else { false } }) } catch { case _: InterruptedException => // Cleanly stop the query. return } } }, s"epoch update thread for $prettyIdString") try { epochUpdateThread.setDaemon(true) epochUpdateThread.start() reportTimeTaken("runContinuous") { SQLExecution.withNewExecutionId(sparkSessionForQuery, lastExecution) { lastExecution.executedPlan.execute() } } } catch { case t: Throwable if StreamExecution.isInterruptionException(t) && state.get() == RECONFIGURING => logInfo(s"Query $id ignoring exception from reconfiguring: $t") // interrupted by reconfiguration - swallow exception so we can restart the query } finally { // The above execution may finish before getting interrupted, for example, a Spark job having // 0 partitions will complete immediately. Then the interrupted status will sneak here. // // To handle this case, we do the two things here: // // 1. Clean up the resources in `queryExecutionThread.runUninterruptibly`. This may increase // the waiting time of `stop` but should be minor because the operations here are very fast // (just sending an RPC message in the same process and stopping a very simple thread). // 2. Clear the interrupted status at the end so that it won't impact the `runContinuous` // call. We may clear the interrupted status set by `stop`, but it doesn't affect the query // termination because `runActivatedStream` will check `state` and exit accordingly. queryExecutionThread.runUninterruptibly { try { epochEndpoint.askSync[Unit](StopContinuousExecutionWrites) } finally { SparkEnv.get.rpcEnv.stop(epochEndpoint) epochUpdateThread.interrupt() epochUpdateThread.join() stopSources() // The following line must be the last line because it may fail if SparkContext is stopped sparkSession.sparkContext.cancelJobGroup(runId.toString) } } Thread.interrupted() } }
// TODO 偽程式碼,後續整理


