不可錯過的java面試部落格之java集合篇
1. List
List 是有序的 Collection。Java List 一共三個實現類:
分別是 ArrayList、Vector 和 LinkedList
ArrayList
ArrayList 是最常用的 List 實現類,內部是通過數組實現的,它允許對元素進行快速隨機訪問。數組的缺點是每個元素之間不能有間隔,當數組大小不滿足時需要增加存儲能力,就要將已經有數組的數據複製到新的存儲空間中。當從 ArrayList 的中間位置插入或者刪除元素時,需要對數組進行複製、移動、代價比較高。因此,它適合隨機查找和遍歷,不適合插入和刪除。排列有序,可重複,容量不夠的時候,當前容量*1.5+1。
Vector(數組實現、執行緒同步)
Vector 與 ArrayList 一樣,也是通過數組實現的,不同的是它支援執行緒的同步,即某一時刻只有一個執行緒能夠寫 Vector,避免多執行緒同時寫而引起的不一致性,但實現同步需要很高的花費,因此,訪問它比訪問 ArrayList 慢。默認擴展一倍容量。
LinkList(鏈表)
LinkedList 是用鏈表結構存儲數據的,很適合數據的動態插入和刪除,隨機訪問和遍歷速度比較慢。另外,他還提供了 List 介面中沒有定義的方法,專門用於操作表頭和表尾元素,可以當作堆棧、隊列和雙向隊列使用。底層使用雙向循環鏈表數據結構。執行緒不安全。
2. ArrayList和linkedList的執行緒安全處理
ArrayList是執行緒不安全的,因此在並發編程時,經常會使用Collections.synchronizedList與CopyOnWriteArrayList來替代ArrayList,接下來對這兩種list進行性能的比較。其中Collections.synchronizedLis在更新操作中使用了同步鎖,而CopyOnWriteArrayList在更新操作中不僅使用了可重入鎖,而且還需要進行數組的複製。
方法一:List<String> list = Collections.synchronizedList(new LinkedList<String>());
方法二:將LinkedList全部換成ConcurrentLinkedQueue;
3. Set
Set 注重獨一無二的性質,該體系集合用於存儲無序(存入和取出的順序不一定相同)元素,值不能重複。對象的相等性本質是對象 hashCode 值(java 是依據對象的記憶體地址計算出的此序號)判斷的,如果想要讓兩個不同的對象視為相等的,就必須覆蓋 Object 的 hashCode 方法和 equals 方法。
HashSet(Hash 表)
哈希表邊存放的是哈希值。HashSet 存儲元素的順序並不是按照存入時的順序(和 List 顯然不同) 而是按照哈希值來存的所以取數據也是按照哈希值取得。元素的哈希值是通過元素的hashcode 方法來獲取的, HashSet 首先判斷兩個元素的哈希值,如果哈希值一樣,接著會比較equals 方法 如果 equls 結果為 true ,HashSet 就視為同一個元素。如果 equals 為 false 就不是同一個元素。
哈希值相同 equals 為 false 的元素是怎麼存儲呢,就是在同樣的哈希值下順延(可以認為哈希值相同的元素放在一個哈希桶中)。也就是哈希一樣的存一列。如圖 1 表示 hashCode 值不相同的情況;圖 2 表示 hashCode 值相同,但 equals 不相同的情況。
HashSet 通過 hashCode 值來確定元素在記憶體中的位置。一個 hashCode 位置上可以存放多個元素。
TreeSet(二叉樹)
1. TreeSet()是使用二叉樹的原理對新 add()的對象按照指定的順序排序(升序、降序),每增
加一個對象都會進行排序,將對象插入的二叉樹指定的位置。
2. Integer 和 String 對象都可以進行默認的 TreeSet 排序,而自定義類的對象是不可以的,自己定義的類必須實現 Comparable 介面,並且覆寫相應的 compareTo()函數,才可以正常使用。
3. 在覆寫 compare()函數時,要返回相應的值才能使 TreeSet 按照一定的規則來排序
4. 比較此對象與指定對象的順序。如果該對象小於、等於或大於指定對象,則分別返回負整數、零或正整數。
LinkHashSet(HashSet+LinkedHashMap)
對於 LinkedHashSet 而言,它繼承與 HashSet、又基於 LinkedHashMap 來實現的。
LinkedHashSet 底層使用 LinkedHashMap 來保存所有元素,它繼承與 HashSet,其所有的方法操作上又與 HashSet 相同,因此 LinkedHashSet 的實現上非常簡單,只提供了四個構造方法,並通過傳遞一個標識參數,調用父類的構造器,底層構造一個 LinkedHashMap 來實現,在相關操作上與父類 HashSet 的操作相同,直接調用父類 HashSet 的方法即可。
4. Map
HashMap(數組+鏈表+紅黑樹)
HashMap 根據鍵的 hashCode 值存儲數據,大多數情況下可以直接定位到它的值,因而具有很快的訪問速度,但遍歷順序卻是不確定的。 HashMap 最多只允許一條記錄的鍵為 null,允許多條記錄的值為 null。HashMap 非執行緒安全,即任一時刻可以有多個執行緒同時寫 HashMap,可能會導致數據的不一致。如果需要滿足執行緒安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有執行緒安全的能力,或者使用 ConcurrentHashMap。
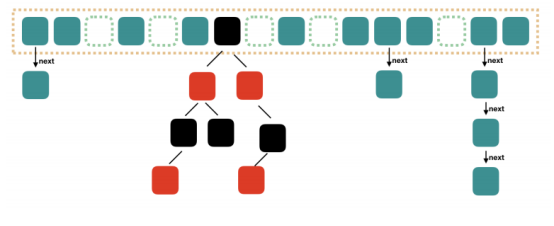
java7的hashmap實現

大方向上,HashMap 裡面是一個數組,然後數組中每個元素是一個單向鏈表。上圖中,每個綠色的實體是嵌套類 Entry 的實例,Entry 包含四個屬性:key, value, hash 值和用於單向鏈表的 next。
1. capacity:當前數組容量,始終保持 2^n,可以擴容,擴容後數組大小為當前的 2 倍。
2. loadFactor:負載因子,默認為 0.75。
3. threshold:擴容的閾值,等於 capacity * loadFactor
java8的hashmap實現
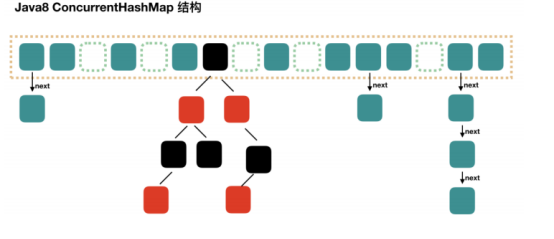
Java8 對 HashMap 進行了一些修改,最大的不同就是利用了紅黑樹,所以其由 數組+鏈表+紅黑樹 組成。
根據 Java7 HashMap 的介紹,我們知道,查找的時候,根據 hash 值我們能夠快速定位到數組的具體下標,但是之後的話,需要順著鏈表一個個比較下去才能找到我們需要的,時間複雜度取決於鏈表的長度,為 O(n)。為了降低這部分的開銷,在 Java8 中,當鏈表中的元素超過了 8 個以後,會將鏈錶轉換為紅黑樹,在這些位置進行查找的時候可以降低時間複雜度為 O(logN)。
ConcurrentHashMap
Segment 段
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因為它支援並發操作,所以要複雜一些。整個 ConcurrentHashMap 由一個個 Segment 組成,Segment 代表」部分「或」一段「的
意思,所以很多地方都會將其描述為分段鎖。注意,行文中,我很多地方用了「槽」來代表一個segment。
執行緒安全(Segment 繼承 ReentrantLock 加鎖)
簡單理解就是,ConcurrentHashMap 是一個 Segment 數組,Segment 通過繼承ReentrantLock 來進行加鎖,所以每次需要加鎖的操作鎖住的是一個 segment,這樣只要保證每個 Segment 是執行緒安全的,也就實現了全局的執行緒安全。

並行度(默認 16)
concurrencyLevel:並行級別、並發數、Segment 數,怎麼翻譯不重要,理解它。默認是 16,
也就是說 ConcurrentHashMap 有 16 個 Segments,所以理論上,這個時候,最多可以同時支援 16 個執行緒並發寫,只要它們的操作分別分布在不同的 Segment 上。這個值可以在初始化的時候設置為其他值,但是一旦初始化以後,它是不可以擴容的。再具體到每個 Segment 內部,其實每個 Segment 很像之前介紹的 HashMap,不過它要保證執行緒安全,所以處理起來要麻煩些。
java8實現
Java8 對 ConcurrentHashMap 進行了比較大的改動,Java8 也引入了紅黑樹。通過對鏈表的頭加鎖實現。
HashTable(執行緒安全)
Hashtable 是遺留類,很多映射的常用功能與 HashMap 類似,不同的是它承自 Dictionary 類,並且是執行緒安全的,任一時間只有一個執行緒能寫 Hashtable,並發性不如 ConcurrentHashMap,因為 ConcurrentHashMap 引入了分段鎖。Hashtable 不建議在新程式碼中使用,不需要執行緒安全的場合可以用 HashMap 替換,需要執行緒安全的場合可以用 ConcurrentHashMap 替換。
TreeMap(可排序)
TreeMap 實現 SortedMap 介面,能夠把它保存的記錄根據鍵排序,默認是按鍵值的升序排序,也可以指定排序的比較器,當用 Iterator 遍歷 TreeMap 時,得到的記錄是排過序的。
如果使用排序的映射,建議使用 TreeMap。
在使用 TreeMap 時,key 必須實現 Comparable 介面或者在構造 TreeMap 傳入自定義的
Comparator,否則會在運行時拋出 java.lang.ClassCastException 類型的異常。
LinkHashMap(記錄插入順序)
LinkedHashMap 是 HashMap 的一個子類,保存了記錄的插入順序,在用 Iterator 遍歷
LinkedHashMap 時,先得到的記錄肯定是先插入的,也可以在構造時帶參數,按照訪問次序排序。
5. HashMap中,初始化設置長度時,容量自動轉成2的冪次長度的演算法剖析
默認情況下HashMap的容量是16,但是,如果用戶通過構造函數指定了一個數字作為容量,那麼Hash會選擇大於該數字的第一個2的冪作為容量。(3->4、7->8、9->16)
我們可以知道,在已知HashMap中將要存放的KV個數的時候,設置一個合理的初始化容量可以有效的提高性能。因為減少擴容,提高效率。
HashMap有擴容機制,就是當達到擴容條件時會進行擴容。HashMap的擴容條件就是當HashMap中的元素個數(size)超過臨界值(threshold)時就會自動擴容。在HashMap中,threshold = loadFactor * capacity。
所以,如果我們沒有設置初始容量大小,隨著元素的不斷增加,HashMap會發生多次擴容,而HashMap中的擴容機制決定了每次擴容都需要重建hash表,是非常影響性能的。
默認情況下,當我們設置HashMap的初始化容量時,實際上HashMap會採用第一個大於該數值的2的冪作為初始化容量。
在Jdk 1.7和Jdk 1.8中,HashMap初始化這個容量的時機不同。jdk1.8中,在調用HashMap的構造函數定義HashMap的時候,就會進行容量的設定。而在Jdk 1.7中,要等到第一次put操作時才進行這一操作。
不管是Jdk 1.7還是Jdk 1.8,計算初始化容量的演算法其實是如出一轍的,主要程式碼如下:
int n = cap – 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n <>0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
根據用戶傳入的容量值(程式碼中的cap),通過計算,得到第一個比他大的2的冪並返回。
通過幾次無符號右移和按位或運算,我們把1100 1100 1100轉換成了1111 1111 1111 ,再把1111 1111 1111加1,就得到了1 0000 0000 0000,這就是大於1100 1100 1100的第一個2的冪。
但是還有一種特殊情況套用以上公式不行,這些數字就是2的冪自身。如果數字4 套用公式的話。得到的會是 8 。為了解決這個問題,JDK的工程師把所有用戶傳進來的數在進行計算之前先-1。
最好的初始化容量機制:expectedSize / 0.75F + 1.0F
6. 如果HashMap的大小超過了負載因子(load factor)定義的容量,怎麼辦?
默認的負載因子大小為0.75,也就是說,當一個map填滿了75%的bucket時候,和其它集合類(如ArrayList等)一樣,將會創建原來HashMap大小的兩倍的bucket數組,來重新調整map的大小,並將原來的對象放入新的bucket數組中。這個過程叫作rehashing,因為它調用hash方法找到新的bucket位置。這個值只可能在兩個地方,一個是原下標的位置,另一種是在下標為<原下標+原容量>的位置。
7. 重新調整HashMap大小存在什麼問題嗎?
當重新調整HashMap大小的時候,確實存在條件競爭,因為如果兩個執行緒都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,存儲在鏈表中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap並不會將元素放在鏈表的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生了,那麼就死循環了。(多執行緒的環境下不使用HashMap)
8. 為什麼hashmap多執行緒會進入死循環?
HashMap的容量是有限的。當經過多次元素插入,使得HashMap達到一定飽和度時,Key映射位置發生衝突的幾率會逐漸提高。這時候,HashMap需要擴展它的長度,也就是進行Resize。
由於擴容採用的是尾插法。會造成環形的情況,第一個執行緒 是 2指向3。然後cpu執行另一個執行緒,尾插法 變成了3指向2。此時回到執行緒1。2指向3 3又指向2。就找不到尾部數據,產生死循環。
9. hashmap的工作原理是什麼?
HashMap是基於hashing的原理,我們使用put(key, value)存儲對象到HashMap中,使用get(key)從HashMap中獲取對象。當我們給put()方法傳遞鍵和值時,我們先對鍵調用hashCode()方法,計算並返回的hashCode是用於找到Map數組的bucket位置來儲存Node 對象。這裡關鍵點在於指出,HashMap是在bucket中儲存鍵對象和值對象,作為Map.Node 。
以下是具體的put過程(JDK1.8版)
1.對Key求Hash值,然後再計算下標
2.如果沒有碰撞,直接放入桶中(碰撞的意思是計算得到的Hash值相同,需要放到同一個bucket中)
3.如果碰撞了,則調用equals() 比較value,相同則替換舊值,不同則以鏈表的方式鏈接到後面
4.如果鏈表長度超過閥值( TREEIFY THRESHOLD==8),就把鏈錶轉成紅黑樹,鏈表長度低於6,就把紅黑樹轉回鏈表
5.如果桶滿了(容量16*載入因子0.75),就需要 resize(擴容2倍後重排)
以下是具體get過程(考慮特殊情況如果兩個鍵的hashcode相同,你如何獲取值對象?)
當我們調用get()方法,HashMap會使用鍵對象的hashcode找到bucket位置,找到bucket位置之後,會調用keys.equals()方法去找到鏈表中正確的節點,最終找到要找的值對象。
10. HashMap中hash函數怎麼是是實現的?
我們可以看到在hashmap中要找到某個元素,需要根據key的hash值來求得對應數組中的位置。 所以我們首先想到的就是把hashcode對數組長度取模運算,這樣一來,元素的分布相對來說是比較均勻的。但是,「模」運算的消耗還是比較大的,能不能找一種更快速,消耗更小的方式,我們來看看JDK1.8的源碼是怎麼做的。

11. 拉鏈法導致的鏈表過深問題為什麼不用二叉查找樹代替,而選擇紅黑樹?為什麼不一直使用紅黑樹?
之所以選擇紅黑樹是為了解決二叉查找樹的缺陷,二叉查找樹在特殊情況下會變成一條線性結構(這就跟原來使用鏈表結構一樣了,造成很深的問題),遍歷查找會非常慢。而紅黑樹在插入新數據後可能需要通過左旋,右旋、變色這些操作來保持平衡,引入紅黑樹就是為了查找數據快,解決鏈表查詢深度的問題,我們知道紅黑樹屬於平衡二叉樹,但是為了保持「平衡」是需要付出代價的,但是該代價所損耗的資源要比遍歷線性鏈表要少,所以當長度大於8的時候,會使用紅黑樹,如果鏈表長度很短的話,根本不需要引入紅黑樹,引入反而會慢。
12. 說說你對紅黑樹的見解?
每個節點非紅即黑
根節點總是黑色的
如果節點是紅色的,則它的子節點必須是黑色的(反之不一定)
每個葉子節點都是黑色的空節點(NIL節點)
從根節點到葉節點或空子節點的每條路徑,必須包含相同數目的黑色節點(即相同的黑色高度)
13. 解決hash 碰撞還有那些辦法?
開放定址法
當衝突發生時,使用某種探查技術在散列表中形成一個探查(測)序列。沿此序列逐個單元地查找,直到找到給定的地址。
按照形成探查序列的方法不同,可將開放定址法區分為線性探查法、二次探查法、雙重散列法等。
再哈希法
Hi = RHi(key),i=1,2,…k
RHi均是不同的哈希函數,即在同義詞產生地址衝突時計算另一個哈希函數地址,直到不發生衝突為止。這種方法不易產生聚集,但是增加了計算時間。
缺點:增加了計算時間。
建立一個公共溢出區
假設哈希函數的值域為[0,m-1],則設向量HashTable[0…m-1]為基本表,每個分量存放一個記錄,另設立向量OverTable[0….v]為溢出表。所有關鍵字和基本表中關鍵字為同義詞的記錄,不管他們由哈希函數得到的哈希地址是什麼,一旦發生衝突,都填入溢出表。
簡單地說就是搞個新表存衝突的元素。
鏈地址法(拉鏈法)
將所有關鍵字為同義詞的記錄存儲在同一線性鏈表中,也就是把衝突位置的元素構造成鏈表。
14. 為什麼要用擾動函數?

擾動函數就是解決碰撞問題。若不使用擾動函數,則直接將key.hashCode()和下面的步驟2做與運算,則會有以下情景。
以初始長度16為例,16-1=15。2進位表示是00000000 00000000 00001111。和某散列值做「與」操作如下,結果就是截取了最低的四位值。

這樣就算散列值分布再鬆散,要是只取最後幾位的話,碰撞也會很嚴重。如果散列本身做得不好,分布上成等差數列的漏洞,恰好使最後幾個低位呈現規律性重複,則碰撞會更嚴重。
15. 擾動函數如何實現?
由擾動函數源碼可知,會有以下步驟:①使用key.hashCode()計算hash值並賦值給變數h;②將h向右移動16位;③將變數h和向右移16位的h做異或運算(二進位位相同為0,不同為1)。此時得到經過擾動函數後的hansh值。

右移16位正好為32bit的一半,自己的高半區和低半區做異或,是為了混合原始哈希嗎的高位和低位,來加大低位的隨機性。而且混合後的低位摻雜了高位的部分特徵,使高位的資訊也被保留下來。

若直接使用key.hashCode()計算出hash值,則範圍為:-2147483648到2147483648,大約40億的映射空間。若映射得比較均勻,是很難出現碰撞的。但是這麼大範圍無法放入記憶體中,況且HashMap的 初始容量為16。所以必須要進行與運算取模。
16. HashMap的負載因子初始值為什麼是0.75?
比如說當前的容器容量是16,負載因子是0.75,16*0.75=12,也就是說,當容量達到了12的時候就會進行擴容操作。
當負載因子是1.0的時候,也就意味著,只有當數組的8個值(這個圖表示了8個)全部填充了,才會發生擴容。這就帶來了很大的問題,因為Hash衝突時避免不了的。當負載因子是1.0的時候,意味著會出現大量的Hash的衝突,底層的紅黑樹變得異常複雜。對於查詢效率極其不利。這種情況就是犧牲了時間來保證空間的利用率。
因此一句話總結就是負載因子過大,雖然空間利用率上去了,但是時間效率降低了。
負載因子是0.5的時候,這也就意味著,當數組中的元素達到了一半就開始擴容,既然填充的元素少了,Hash衝突也會減少,那麼底層的鏈表長度或者是紅黑樹的高度就會降低。查詢效率就會增加。
但是,兄弟們,這時候空間利用率就會大大的降低,原本存儲1M的數據,現在就意味著需要2M的空間。
一句話總結就是負載因子太小,雖然時間效率提升了,但是空間利用率降低了。
大致意思就是說負載因子是0.75的時候,空間利用率比較高,而且避免了相當多的Hash衝突,使得底層的鏈表或者是紅黑樹的高度比較低,提升了空間效率。
17. 為什麼hashMap的容量擴容時一定是2的冪次?
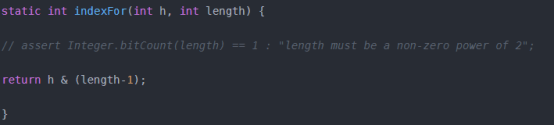
HashMap的容量為16轉化成二進位為10000,length-1得出的二進位為01111
哈希值為1111
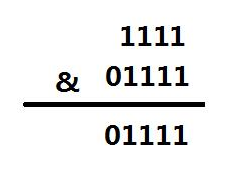
可以得出索引的位置為15
假設 HashMap的容量為15轉化成二進位為1111,length-1得出的二進位為1110
哈希值為1111和1110

那麼兩個索引的位置都是14,就會造成分布不均勻了,
增加了碰撞的幾率,減慢了查詢的效率,造成空間的浪費。
總結:
因為2的冪-1都是11111結尾的,所以碰撞幾率小。
判斷位置的時候代替取模運算,效率高。
18. linkedhashmap如何保證有序性?
繼承自hashmap,內部增加了head tail 和accessorder。
19. Comparable 和 Comparator 的區別?
如果在定義類時,就實現了Comparable介面,直接在裡面重寫compareTo()方法,如果沒實現,後面在業務開發中需要有比較排序的功能,就再單獨寫一個類實現Comparator介面,在裡面重寫compare()方法,然後這個類需要作為參數傳入到工具類Collections.sort和Arrays.sort方法中。最主要的區別就是一個一開始就實現,一個是後期實現。
20. Array 和 ArrayList 有何區別?什麼時候更適合用 Array?
Array 可以容納基本類型和對象,而 ArrayList 只能容納對象。
Array 是指定大小的,而 ArrayList 大小是固定的,可自動擴容。
Array 沒有提供 ArrayList 那麼多功能,比如 addAll、removeAll 和 iterator 等。
21. ArrayList是如何擴容的?
如果通過無參構造的話,初始數組容量為 0 ,當真正對數組進行添加時,才真正分配容量。每次按照 1.5 倍(位運算)的比率通過 copeOf 的方式擴容。
在 JKD6 中實現是,如果通過無參構造的話,初始數組容量為10,每次通過 copeOf 的方式擴容後容量為原來的 1.5 倍。


