spark系列-8、Spark Streaming
參考鏈接://spark.apache.org/docs/latest/streaming-programming-guide.html
一、Spark Streaming 介紹
Spark Streaming是核心Spark API的擴展,可實現實時數據流的可伸縮,高吞吐量,容錯流處理。數據可以從Kafka、ZeroMQ等消息隊列以及TCP sockets或者目錄文件從數據源獲取數據,並且可以使用map,reduce,join和window等高級函數進行複雜演算法的處理。最後,可以將處理後的數據推送到文件系統,資料庫和實時儀錶板。

- 在內部,它的工作方式為:Spark Streaming接收實時輸入數據流,並將數據分成批次,然後由Spark引擎進行處理,以生成批次的最終結果流。

- 對應的批數據,在Spark內核對應一個RDD實例,因此,對應流數據的DStream可以看成是一組RDDs,即RDD的一個序列。通俗點理解的話,在流數據分成一批一批後,通過一個先進先出的隊列,然後 Spark Engine從該隊列中依次取出一個個批數據,把批數據封裝成一個RDD,然後進行處理,這是一個典型的生產者消費者模型,對應的就有生產者消費者模型的問題,即如何協調生產速率和消費速率。



Spark Streaming Wordcount:
-
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Duration, Durations, StreamingContext} /** * @author xiandongxie */ object SparkStreamingWordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() .setMaster("local[2]") .setAppName("SparkStreamingWordCount") // 設置批次時間5S val duration: Duration = Durations.seconds(5) val context: StreamingContext = new StreamingContext(conf,duration) // 指定socket數據源 val sourceDStream: ReceiverInputDStream[String] = context.socketTextStream("localhost", 6666) // 計算WordCount val resultDStream: DStream[(String, Int)] = sourceDStream.flatMap(f => f.split("\t")) .map((_, 1)) .reduceByKey(_ + _) resultDStream.print() context.start() // Start the computation context.awaitTermination() // Wait for the computation to terminate } }
二、Spark Streaming 對比 Storm
- 處理模型以及延遲
- 雖然兩框架都提供了可擴展性(scalability)和可容錯性(fault tolerance),但是它們的處理模型從根本上說是不一樣的。Storm可以實現亞秒級時延的處理,而每次只處理一條event,而Spark Streaming可以在一個短暫的時間窗口裡面處理多條(batches)Event。所以說Storm可以實現亞秒級時延的處理,而Spark Streaming則有一定的時延。
- 容錯和數據保證
- 然而兩者的都有容錯時候的數據保證,Spark Streaming的容錯(通過血緣關係)為有狀態的計算提供了更好的支援。在Storm中,每條記錄在系統的移動過程中都需要被標記跟蹤,所以Storm只能保證每條記錄最少被處理一次,但是允許從錯誤狀態恢復時被處理多次。這就意味著可變更的狀態可能被更新兩次從而導致結果不正確。
- Spark Streaming的容錯:通過血緣關係,是粗粒度的,保證每個批處理記錄僅僅被處理一次,即使是node節點掛掉
- Storm:細粒度的容錯,每條記錄在系統的移動過程中都需要被標記跟蹤,缺點:允許從錯誤狀態恢復時被處理多次。這就意味著可變更的狀態可能被更新兩次從而導致結果不正確。
- 批處理框架集成
- Spark Streaming的一個很棒的特性就是它是在Spark框架上運行的。這樣你就可以使用spark的批處理程式碼一樣來寫Spark Streaming程式,或者是在Spark中交互查詢比如spark-sql。這就減少了單獨編寫流處理程式和歷史數據處理程式。
- 生產支援
- 兩者都可以在各自的集群框架中運行,但是Storm可以在Mesos上運行, 而Spark Streaming可以在YARN和Mesos上運行。

Spark Streaming優缺點:
- 優點:
- 吞吐量大、速度快。
- 容錯:SparkStreaming在沒有額外程式碼和配置的情況下可以恢復丟失的工作。checkpoint。
- 社區活躍度高。生態圈強大。因為後台是Spark
- 數據源廣泛。
- 缺點:
- 延遲。500毫秒已經被廣泛認為是最小批次大小。所以實際場景中應注意該問題,就像標題分類場景,設定的0.5s一批次,加上處理時間,分類介面會佔用1s的響應時間。實時要求高的可選擇使用其他框架。
三、架構與抽象
Spark Streaming使用「微批次」的架構,把流試計算當成一系列連接的小規模批處理來對待,Spark Streaming從各種輸入源中讀取數據,並把數據分成小組的批次,新的批次按均勻的時間間隔創建出來,在每個時間區間開始的時候,一個新的批次就創建出來,在該區間內收到的數據都會被添加到這個批次中,在時間區間結束時,批次停止增長。時間區間的大小是由批次間隔這個參數決定的,批次間隔一般設在500毫秒到幾秒之間,由應用開發者配置,每個輸出批次都會形成一個RDD,以Spark作業的方式處理並生成其他的RDD。並能將處理結果按批次的方式傳給外部系統。

接受器(receive)會佔用一個executor的一個cpu,所以在local[n]模式下,n > 要運行的接收器數
四、DStream 操作
- DStream 上的原語與 RDD 的類似,分為 Transformations(轉換,惰性的)和 Output Operations(輸出)兩種,此外轉換操作中還有一些比較特殊的原語,如:
- updateStateByKey()、transform() 以及各種 Window 相關的原語。
- UpdateStateByKey 返回一個新的「狀態」 DStream,在該DStream中,通過在鍵的先前狀態和鍵的新值上應用給定函數來更新每個鍵的狀態。這可用於維護每個鍵的任意狀態數據。
- 如輸入:hello world,結果則為:(hello,1)(world,1),然後輸入 hello spark,結果則為 (hello,2)(spark,1)。會保留上一次數據處理的結果。
-
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Durations, StreamingContext} /** * @author xiandongxie */ object SparkStreamingSocketPortUpdateState { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() .setAppName("sparkstreamingsocketportupdatestate") .setMaster("local[2]") val streamingContext = new StreamingContext(conf, Durations.seconds(5)) // 設置保存地址 streamingContext.checkpoint("/tmp/spark/sparkstreamingsocketportupdatestat") val sourceDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("localhost", 6666) val reduceDStream: DStream[(String, Int)] = sourceDStream.flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) val updateStateByKey: DStream[(String, Int)] = reduceDStream.updateStateByKey((newValues: Seq[Int], runningCount: Option[Int]) => { var total: Int = 0 for (i <- newValues) { total += i } println(newValues + "\t" + (if (runningCount.isDefined) runningCount.get else 0)) val last: Int = if (runningCount.isDefined) runningCount.get else 0 val now: Int = total + last Some(now) }) updateStateByKey.foreachRDD((r, t) => { println(s"count time:${t},${r.collect().toList}") }) streamingContext.start() streamingContext.awaitTermination() } }
- Transform() 原語允許 DStream 上執行任意的 RDD-to-RDD 函數 代替原有的DStream 轉換操作,必須返回一個RDD;通過該函數可以方便的擴展 Spark API。
普通的轉換操作如下表所示:
|
轉換 |
描述 |
|
map(func) |
源 DStream的每個元素通過函數func返回一個新的DStream。 |
|
flatMap(func) |
類似與map操作,不同的是每個輸入元素可以被映射出0或者更多的輸出元素。 |
|
filter(func) |
在源DSTREAM上選擇Func函數返回僅為true的元素,最終返回一個新的DSTREAM 。 |
|
repartition(numPartitions) |
通過輸入的參數numPartitions的值來改變DStream的分區大小。 |
|
union(otherStream) |
返回一個包含源DStream與其他 DStream的元素合併後的新DSTREAM。 |
|
count() |
對源DStream內部的所含有的RDD的元素數量進行計數,返回一個內部的RDD只包含一個元素的DStreaam。 |
|
reduce(func) |
使用函數func(有兩個參數並返回一個結果)將源DStream 中每個RDD的元素進行聚 合操作,返回一個內部所包含的RDD只有一個元素的新DStream。 |
|
countByValue() |
計算DStream中每個RDD內的元素出現的頻次並返回新的DStream[(K,Long)],其中K是RDD中元素的類型,Long是元素出現的頻次。 |
|
reduceByKey(func, [numTasks]) |
當一個類型為(K,V)鍵值對的DStream被調用的時候,返回類型為類型為(K,V)鍵值對的新 DStream,其中每個鍵的值V都是使用聚合函數func匯總。注意:默認情況下,使用 Spark的默認並行度提交任務(本地模式下並行度為2,集群模式下位8),可以通過配置numTasks設置不同的並行任務數。 |
|
join(otherStream, [numTasks]) |
當被調用類型分別為(K,V)和(K,W)鍵值對的2個DStream時,返回類型為(K,(V,W))鍵值對的一個新 DSTREAM。 |
|
cogroup(otherStream, [numTasks]) |
當被調用的兩個DStream分別含有(K, V) 和(K, W)鍵值對時,返回一個(K, Seq[V], Seq[W])類型的新的DStream。 |
|
transform(func) |
通過對源DStream的每RDD應用RDD-to-RDD函數返回一個新的DStream,這可以用來在DStream做任意RDD操作。 |
|
updateStateByKey(func) |
返回一個新狀態的DStream,其中每個鍵的狀態是根據鍵的前一個狀態和鍵的新值應用給定函數func後的更新。這個方法可以被用來維持每個鍵的任何狀態數據。 |
五、窗口轉換操作
- 在Spark Streaming中,數據處理是按批進行的,而數據採集是逐條進行的,因此在Spark Streaming中會先設置好批處理間隔(batch duration),當超過批處理間隔的時候就會把採集到的數據匯總起來成為一批數據交給系統去處理。
- 對於窗口操作而言,在其窗口內部會有N個批處理數據,批處理數據的大小由窗口間隔(window duration)決定,而窗口間隔指的就是窗口的持續時間,在窗口操作中,只有窗口的長度滿足了才會觸發批數據的處理。除了窗口的長度,窗口操作還有另一個重要的參數就是滑動間隔(slide duration),它指的是經過多長時間窗口滑動一次形成新的窗口,滑動窗口默認情況下和批次間隔的相同,而窗口間隔一般設置的要比它們兩個大。在這裡必須注意的一點是滑動間隔和窗口間隔的大小一定得設置為批處理間隔的整數倍
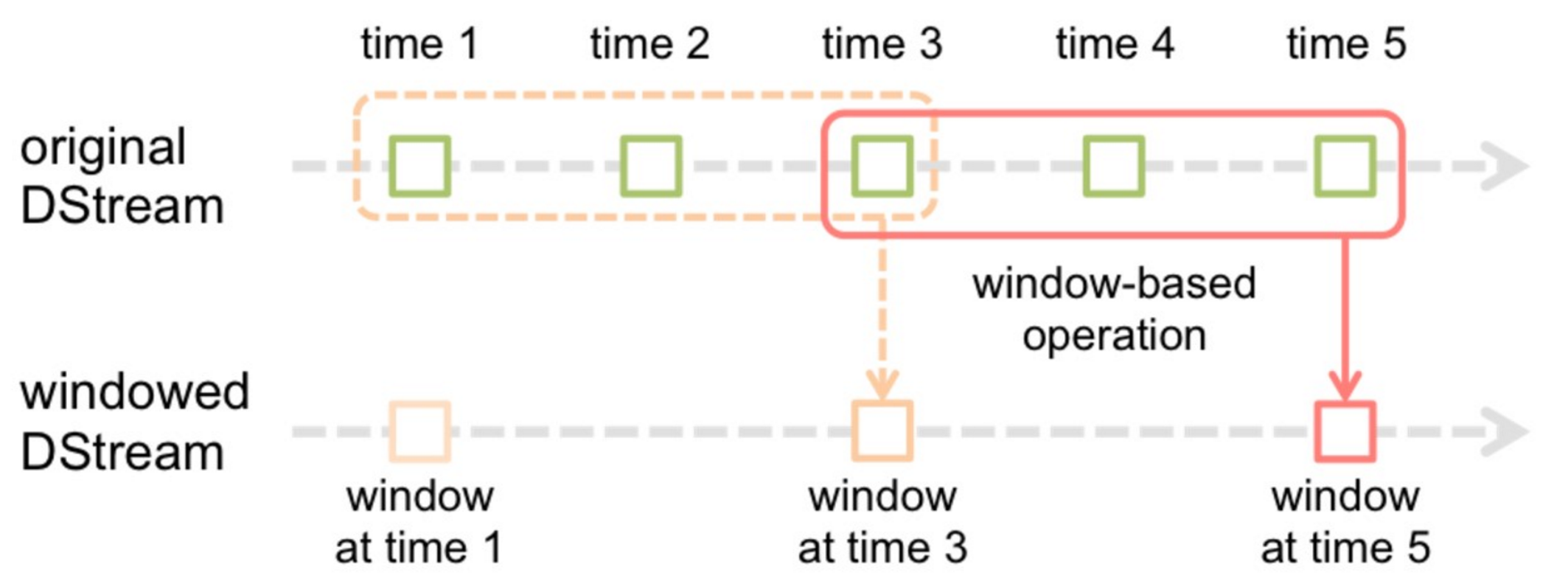

val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
窗口的計算:
Spark Streaming 還提供了窗口的計算,它允許你通過滑動窗口對數據進行轉換,窗口轉換操作如下:
|
轉換 |
描述 |
|
window(windowLength窗口大小, slideInterval滑動間隔) |
返回一個基於源DStream的窗口批次計算後得到新的DStream。 |
|
countByWindow(windowLength,slideInterval) |
返回基於滑動窗口的DStream中的元素的數量。 |
|
reduceByWindow(func, windowLength,slideInterval) |
基於滑動窗口對源DStream中的元素進行聚合操作,得到一個新的DStream。 |
|
reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]) |
基於滑動窗口對(K,V)鍵值對類型的DStream中的值按K使用聚合函數func進行聚合操作,得到一個新的DStream。 |
|
reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) |
一個更高效的reduceByKkeyAndWindow()的實現版本,先對滑動窗口中新的時間間隔內數據增量聚合併移去最早的與新增數據量的時間間隔內的數據統計量。例如,計算t+4秒這個時刻過去5秒窗口的WordCount,那麼我們可以將t+3時刻過去5秒的統計量加上[t+3,t+4]的統計量,在減去[t-2,t-1]的統計量,這種方法可以復用中間三秒的統計量,提高統計的效率。 |
|
countByValueAndWindow(windowLength,slideInterval, [numTasks]) |
基於滑動窗口計算源DStream中每個RDD內每個元素出現的頻次並返回DStream[(K,Long)],其中K是RDD中元素的類型,Long是元素頻次。與countByValue一樣,reduce任務的數量可以通過一個可選參數進行配置。 |
七、輸出操作
Spark Streaming允許DStream的數據被輸出到外部系統,如資料庫或文件系統。由於輸出操作實際上使transformation操作後的數據可以通過外部系統被使用,同時輸出操作觸發所有DStream的transformation操作的實際執行(類似於RDD操作)。以下表列出了目前主要的輸出操作:
|
轉換 |
描述 |
|
print() |
在Driver中列印出DStream中數據的前10個元素。 |
|
saveAsTextFiles(prefix, [suffix]) |
將DStream中的內容以文本的形式保存為文本文件,其中每次批處理間隔內產生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsObjectFiles(prefix, [suffix]) |
將DStream中的內容按對象序列化並且以SequenceFile的格式保存。其中每次批處理間隔內產生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsHadoopFiles(prefix, [suffix]) |
將DStream中的內容以文本的形式保存為Hadoop文件,其中每次批處理間隔內產生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
foreachRDD(func) |
最基本的輸出操作,將func函數應用於DStream中的RDD上,這個操作會輸出數據到外部系統,比如保存RDD到文件或者網路資料庫等。需要注意的是func函數是在運行該streaming應用的Driver進程里執行的。 |
dstream.foreachRDD是一個強大的原語,可以將數據發送到外部系統:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
八、checkpoint
流應用程式必須24*7全天候運行,因此必須對與應用程式邏輯無關的故障(例如,系統故障,JVM崩潰等)具有彈性。為此,Spark Streaming需要將足夠的資訊檢查點指向容錯存儲系統,以便可以從故障中恢復。檢查點有兩種類型的數據。
- 元數據檢查點 -將定義流計算的資訊保存到HDFS等容錯存儲中。這用於從運行流應用程式的驅動程式的節點的故障中恢復。元數據包括:
- 配置 -用於創建流應用程式的配置。
- DStream操作 -定義流應用程式的DStream操作集。
- 不完整的批次 -作業排隊但尚未完成的批次。
- 數據檢查點 -將生成的RDD保存到可靠的存儲中。在一些有狀態轉換中,這需要跨多個批次合併數據,這是必需的。在此類轉換中,生成的RDD依賴於先前批次的RDD,這導致依賴項鏈的長度隨時間不斷增加。為了避免恢復時間的這種無限制的增加(與依賴關係鏈成比例),有狀態轉換的中間RDD定期 檢查點到可靠的存儲(例如HDFS)以切斷依賴關係鏈。
總而言之,從驅動程式故障中恢復時,主要需要元數據檢查點,而如果使用有狀態轉換,即使是基本功能,也需要數據或RDD檢查點。
何時啟用檢查點:
必須為具有以下任一要求的應用程式啟用檢查點:
- 有狀態轉換的用法 -如果在應用程式中使用
updateStateByKey或reduceByKeyAndWindow(帶有反函數),則必須提供檢查點目錄以允許定期進行RDD檢查點。 - 從運行應用程式的驅動程式故障中恢復 -元數據檢查點用於恢復進度資訊。
注意,沒有前述狀態轉換的簡單流應用程式可以在不啟用檢查點的情況下運行。在這種情況下,從驅動程式故障中恢復也將是部分的(某些已接收但未處理的數據可能會丟失)。這通常是可以接受的,並且許多都以這種方式運行Spark Streaming應用程式。預計將來會改善對非Hadoop環境的支援。
如何配置檢查點:
可以通過在容錯,可靠的文件系統(例如,HDFS,S3等)中設置目錄來啟用檢查點,將檢查點資訊保存到該目錄中。這是通過使用完成的streamingContext.checkpoint(checkpointDirectory)。這將允許您使用前面提到的有狀態轉換。此外,如果要使應用程式從驅動程式故障中恢復,則應重寫流應用程式以具有以下行為。
- 程式首次啟動時,它將創建一個新的StreamingContext,設置所有流,然後調用start()。
- 失敗後重新啟動程式時,它將根據檢查點目錄中的檢查點數據重新創建StreamingContext。
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Durations, StreamingContext} /** * @author xiandongxie */ object SparkStreamingSocketCheckPoint { def main(args: Array[String]): Unit = { val checkpointPath = "/tmp/spark/sparkStreamingSocketCheckPoint" val strc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => { val conf: SparkConf = new SparkConf() .setAppName("SparkStreamingSocketCheckPoint") .setMaster("local[2]") val streamingContext = new StreamingContext(conf, Durations.seconds(5)) streamingContext.checkpoint(checkpointPath) val sourceDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("localhost", 6666) val reduceDStream: DStream[(String, Int)] = sourceDStream.flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) val updateStateByKey: DStream[(String, Int)] = reduceDStream.updateStateByKey((newValues: Seq[Int], runningCount: Option[Int]) => { var total: Int = 0 for (i <- newValues) { total += i } val last: Int = if (runningCount.isDefined) runningCount.get else 0 val now: Int = total + last Some(now) }) updateStateByKey.foreachRDD((r, t) => { println(s"count time:${t},${r.collect().toList}") }) streamingContext }) strc.start() strc.awaitTermination() } }
程式碼地址://gitee.com/xiexiandong/abc_bigdata


