爬取抖音短影片改良版
使用更簡單的方法
在我之前的一篇部落格中,我用了構造網址的方法來獲取抖音短影片,但是在今天我又一次的研究抖音短影片的時候發現了一個更加簡單的方法,發現我之前的分析實在是太過繁瑣了,所以有寫了一篇部落格來記錄下這個方法。(上一篇部落格就當做是就記錄下分析網頁的思路吧,就不作更改了)
與上一篇部落格不同的是,這個方法可以省略掉大量的分析步驟
隨便打開一個抖音個人主頁,我選擇的是愛奇藝體育,接著右鍵檢查網頁元素,點擊network選項卡下的xhr選項,分析抓到的包
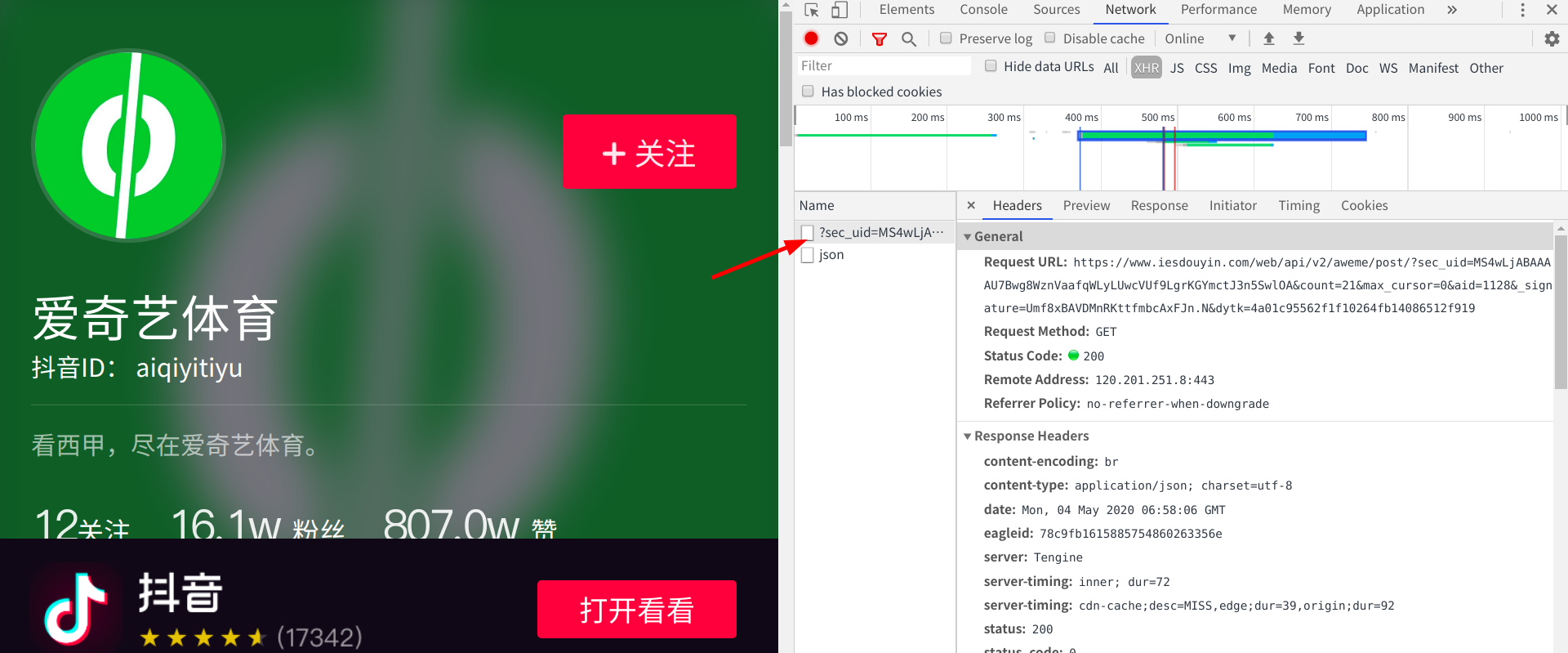
點到preview選項卡,點擊video->download_addr->url_list
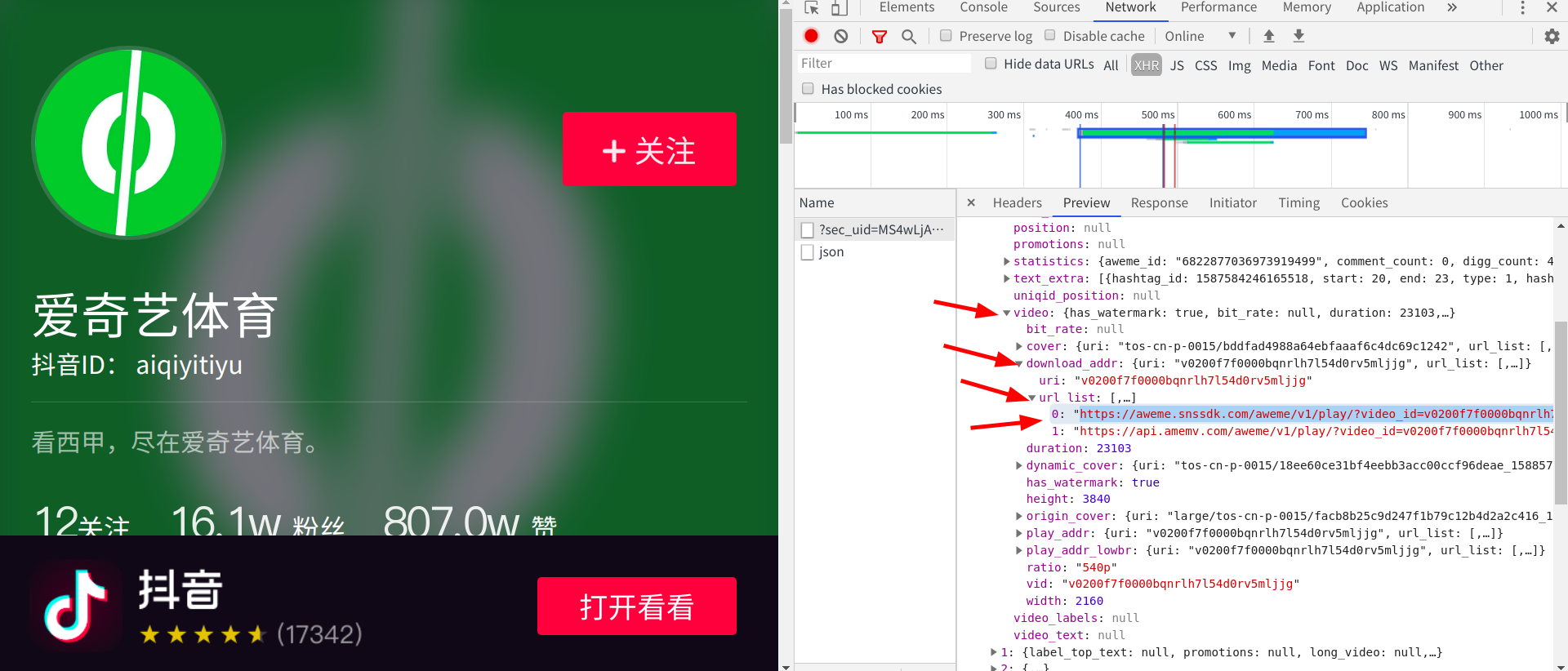
發現這下面跟著的兩個網址正好是影片的網址(根本不需要構造,只是這個網址藏的有點深,需要非常耐心的尋找),打開網址查看:

ok,現在我們只要想辦法提取到它就大功告成了
我這次使用的方法中用到了jsonpath模組,直接pip下載就可以了:
pip install jsonpath
程式碼
import requests
import json
import jsonpath
class Douyin:
def page_num(self,max_cursor):
#隨機碼
random_field = '00nvcRAUjgJQBMjqpgesfdNJ72&dytk=4a01c95562f1f10264fb14086512f919'
#網址的主體
url = '//www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAU7Bwg8WznVaafqWLyLUwcVUf9LgrKGYmctJ3n5SwlOA&count=21&max_cursor=' + str(max_cursor) + '&aid=1128&_signature=' + random_field
#請求頭
headers = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response = requests.get(url,headers=headers).text
#轉換成json數據
resp = json.loads(response)
#提取到max_cursor
max_cursor = resp['max_cursor']
#遍歷
for data in resp['aweme_list']:
# 影片簡介
video_title = data['desc']
#使用jsonpath語法提取download_addr
video_url = jsonpath.jsonpath(data,'$..download_addr')
for a in video_url:
#提取出來第一個鏈接地址
video_realurl = a['url_list'][1]
# 請求影片
video = requests.get(video_realurl, headers=headers).content
with open('t/' + video_title, 'wb') as f:
print('正在下載:', video_title)
f.write(video)
#判斷停止構造網址的條件
if max_cursor==0:
return 1
else:
douyin.page_num(max_cursor)
if __name__ == '__main__':
douyin = Douyin()
douyin.page_num(max_cursor=0)
優點
這個方法的優點是可以省去很大一部分的分析網址的步驟,而且沒有調用到webdriver(可以不限制瀏覽器),速度也會有顯著提升
不足
還是沒有解決隨機生成字元串的問題,操作比較麻煩
使用方法



