DeepWalk論文精讀:(2)核心演算法
- 2020 年 5 月 3 日
- 筆記
模組2
1. 核心思想及其形成過程
DeepWalk結合了兩個不相干領域的模型與演算法:隨機遊走(Random Walk)及語言模型(Language Modeling)。
1.1 隨機遊走
由於網路嵌入需要提取節點的局部結構,所以作者很自然地想到可以使用隨機遊走演算法。隨機遊走是相似性度量的一種方法,曾被用於內容推薦[11]、社區識別[1, 38]等。除了捕捉局部結構,隨機遊走還有以下兩個好處:
- 容易並行,使用不同的執行緒、進程、機器,可以同時在一個圖的不同部分運算;
- 關注節點的局部結構使得模型能更好地適應變化中的網路,在網路發生微小變化時,無需在整個圖上重新計算。
1.2 語言模型
語言模型(Language Modeling)有一次顛覆性創新[26, 27],體現在以下三點:
- 從原來的利用上下文預測缺失單詞,變為利用一個單詞預測上下文;
- 不僅考慮了給定單詞左側的單詞,還考慮了右側的單詞;
- 將給定單詞前後文打亂順序,不再考慮單詞的前後順序因素。
這些特性非常適合節點的表示學習問題:第一點使得較長的序列也可以在允許時間內計算完畢;第二、三點的順序無關使得學習到的特徵能更好地表徵「臨近」這一概念的對稱性。
1.3 如何結合
可以結合的原因,是作者觀察到:
- 如果不論規模大小,節點的度服從冪律分布,那麼在隨機遊走序列上節點的出現頻率也應當服從冪律分布。
- 自然語言中詞頻服從冪律分布,自然語言模型可以很好地處理這種分布。
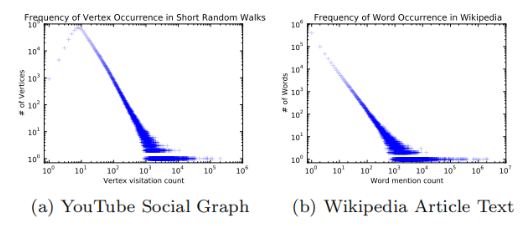
所以作者將自然語言模型中的方法遷移到了網路社群結構問題上,這也正是DeepWalk的一個核心貢獻。
2. 具體演算法
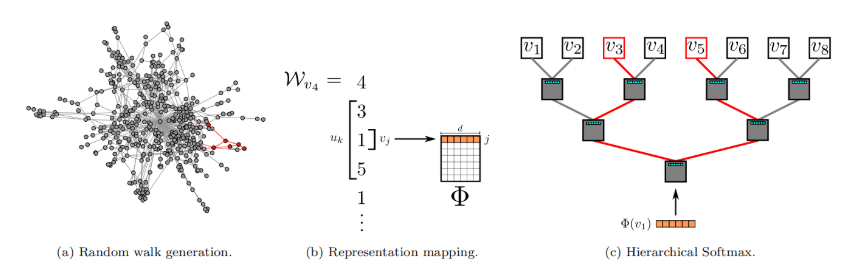
演算法由兩部分組成:第一部分是隨機遊走序列生成器,第二部分是向量更新。
2.1 隨機遊走生成器
DeepWalk用$W_{v_i}$表示以$v_i$為根節點的隨機遊走序列,它的生成方式是:從$v_i$出發,隨機訪問一個鄰居,然後再訪問鄰居的鄰居…每一步都訪問前一步所在節點的鄰居,直到序列長度達到設定的最大值$t$。在進行上述過程的時候,可能會發生「掉頭」的情況,但實驗證明這並沒有什麼影響。在實際操作中,規定每一個節點都要作為根節點遊走$\gamma$次,序列長度為$t$。

Algorithm 1中的3-9(不包括7)展示了隨機遊走的過程。外循環指定$\gamma$次循環,每次首先打亂全部節點的順序以加速隨機梯度下降(SGD)的收斂速度,內循環中在每一個節點上執行一遍隨機遊走RandomWalk,得到隨機遊走序列$W_{v_i}$。
2.2 節點表示更新
在得到了隨機遊走序列之後,就可以更新節點的表示向量了。作者使用了SkipGram演算法,並利用Hierarchichal Softmax進行加速。
2.2.1 SkipGram

Algorithm 2展示了SkipGram演算法[26]。第3行為演算法核心,其思想是「利用中心節點預測臨近節點」。對於一個隨機遊走序列,每一個節點都可作為中心節點,根據設定的窗口大小$\omega$,選取序列里中心節點前後各$\omega$,共$2\omega$個節點。SkipGram的優化目標是:
$$
minimize \space -\log \Pr(u_k|\Phi(v_j))
$$
即最大化在$v_j$附近出現$u_k$的概率。其中,$u_k$是這$2\omega$個節點中的每一個,$\Phi(v_j) \in \mathbb{R}^d$是將節點映射到它的嵌入表示的函數,也即我們最終要得到的結果。但這樣做有一個很大的不足:在學習和計算$\Pr(u_k|\Phi(v_j))$的分布時,由於節點個數非常多,標籤個數將會與$|V|$相同,需要非常多個分類器,需要大量的計算資源[3]。為了加速計算,可以使用Hierarchical Softmax近似求解,將在2.2.2中具體介紹。
第4行是利用隨機梯度SGD[4]下降更新映射函數(形式為矩陣),其中學習率初始值為2.5%(2.5e-2),在訓練中隨著見過的節點數量增多而線性地減小。
2.2.2 Hierarchical Softmax
在計算$\Pr(u_k|\Phi(v_i))$時,可以利用Hierarchical Softmax二叉樹[29, 30]加速。作者將所有節點作為二叉樹的葉子節點,就可以用從根節點到葉子節點的路徑來表示每個節點。二叉樹若有$|V|$個葉子節點,則深度至多為$\log|V|$。這樣就會有:
$$
\Pr(u_k|\Phi(v_j))=\prod_{l=1}^{\lceil\log|V|\rceil}\Pr(b_l|\Phi(v_j))
$$
其中$b_0, b_1, …, b_{\lceil\log|V|\rceil}$是一系列二叉樹中的非葉子節點。這樣就可以用較少的分類器完成這個任務,將計算複雜度由$O(|V|)$降低至$O(\log|V|)$。
更進一步,還可以結合節點出現頻率,使用霍夫曼編碼,為更頻繁出現的節點分配稍短的路徑,再次降低計算複雜度。
3. 並行化
如前文所述,隨機序列中節點出現頻率服從冪律分布,長尾中包含了大量的不經常出現的節點,所以對於$\Phi$的更新應當是十分稀疏的。因此,作者使用了非同步的隨機梯度下降(ASGD)方法,並行計算以提高收斂速度[36],使得可以用於大規模的機器學習[8]。
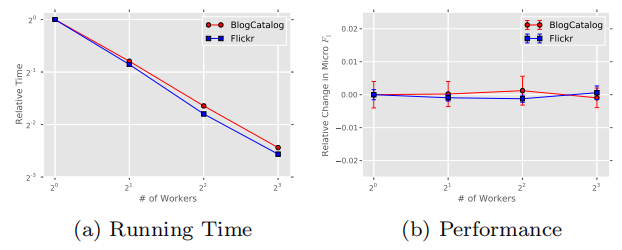
在BlogCatalog和Flickr兩個網路上的實驗結果也表明:增加並行任務的個數,可以可以線性地減少訓練時間,但不會降低準確性。
4. 演算法變體
4.1 Streaming
Streaming無需知道整個圖的結構,將隨機遊走序列直接傳遞到表示學習部分,並直接更新模型。但由於不知道整個圖的資訊,所以學習過程需要做如下調整:
- 不能使用衰減的學習率,但可以指定一個較小的固定的學習率。
- 無法構建Hierarchical Softmax二叉樹,除非知道或可以預測節點個數的數量級。
4.2 Non-random walks
某些網路是客戶與一些元素互動的副產品,比如網站導航的層級結構。當一個網路中進行隨機遊走的序列是非隨機的,比如只能按照導航的層級結構進行遊走時,可以直接將這種結構傳遞給模型。這樣,不僅可以捕捉到網路結構資訊,還可以知道路徑遍歷的頻率。
作者認為,自然語言模型就是Non-random walks的一個特例。句子可以被看作是在整個辭彙網路中非隨機、有目的的遊走序列。
Non-random walks可以和Streaming結合,當網路持續變化難以獲得網路整體資訊,或網路規模過大難以處理全部資訊時,使得DeepWalk演算法依舊可行。
參考文獻
1. 核心思想
[11] F. Fouss, A. Pirotte, J.-M. Renders, and M. Saerens. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. Knowledge and Data Engineering, IEEE Transactions on, 19(3):355–369, 2007.
[1] R. Andersen, F. Chung, and K. Lang. Local graph partitioning using pagerank vectors. In Foundations of Computer Science, 2006. FOCS』06. 47th Annual IEEE Symposium on, pages 475–486. IEEE, 2006.
[38] D. A. Spielman and S.-H. Teng. Nearly-linear time algorithms for graph partitioning, graph sparsification, and solving linear systems. In Proceedings of the thirty-sixth annual ACM symposium on Theory of computing, pages 81–90. ACM, 2004.
[26] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781, 2013.
[27] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
2.2.1 SkipGram
[3] Y. Bengio, R. Ducharme, and P. Vincent. A neural probabilistic language model. Journal of Machine Learning Research, 3:1137–1155, 2003.
[4] L. Bottou. Stochastic gradient learning in neural networks. In Proceedings of Neuro-Nˆımes 91, Nimes, France, 1991. EC2.
2.2.2 Hierarchical Softmax
[29] A. Mnih and G. E. Hinton. A scalable hierarchical distributed language model. Advances in neural information processing systems, 21:1081–1088, 2009
[30] F. Morin and Y. Bengio. Hierarchical probabilistic neural network language model. In Proceedings of the international workshop on artificial intelligence and statistics, pages 246–252, 2005.
3. 並行化
[36] B. Recht, C. Re, S. Wright, and F. Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems 24, pages 693–701. 2011.
[8] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. Le, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Ng. Large scale distributed deep networks. In P. Bartlett, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1232–1240. 2012.


