java並發之ConcurrentLinkedQueue源碼分析
- 2019 年 10 月 3 日
- 筆記
在並發編程中,我們可能經常需要用到執行緒安全的隊列,JDK提供了兩種模式的隊列:阻塞隊列和非阻塞隊列。阻塞隊列使用鎖實現,非阻塞隊列使用CAS實現。ConcurrentLinkedQueue是一個基於鏈表實現的無界執行緒安全隊列,對於。下面看看JDK是如何使用非阻塞的方式來實現執行緒安全隊列ConcurrentLinkedQueue的。
成員屬性
ConcurrentLinkedQueue由head和tail節點組成,節點與節點之間通過next連接,從而來組成一個鏈表結構的隊列。
private transient volatile Node<E> head; private transient volatile Node<E> tail;Node類
Node有兩個屬性item和指向下一個節點的next,item和next都被聲明成volatile類型,使用CAS來保證更新的執行緒安全。
private static class Node<E> { volatile E item; volatile Node<E> next; Node(E item) { UNSAFE.putObject(this, itemOffset, item); } //更改Node中的數據域item boolean casItem(E cmp, E val) { return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } //更改Node中的指針域next void lazySetNext(Node<E> val) { UNSAFE.putOrderedObject(this, nextOffset, val); } //更改Node中的指針域next boolean casNext(Node<E> cmp, Node<E> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } private static final sun.misc.Unsafe UNSAFE; private static final long itemOffset; private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Node.class; itemOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("item")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } }構造方法
默認的無參構造,head和tail默認情況下指向item為null的Node哨兵結點。元素入隊時被加入隊尾,出隊時候從隊列頭部獲取一個元素。
public ConcurrentLinkedQueue() { head = tail = new Node<E>(null); }offer方法
在讀源碼並按照其執行流程分析之前,先給個結論:tail不一定指向對象真正的尾節點,後面我們分析之後會發現這個特點。
private static void checkNotNull(Object v) { if (v == null) throw new NullPointerException(); } public boolean offer(E e) { //(1)如果e為null會拋出空指針異常 checkNotNull(e); //(2)創建一個新的Node結點,Node的構造函數中會調用Unsafe類的putObject方法 final Node<E> newNode = new Node<E>(e); //(3)從尾節點插入新的結點 for (Node<E> t = tail, p = t;;) { //q為尾節點的next結點,但是在多執行緒中,如果有別的執行緒修改了tail結點那麼在本執行緒中可以看到p!=null(後 //面的CAS就是這樣做的) Node<E> q = p.next; //(4)如果q為null,說明現在p是尾節點,那麼可以執行添加 if (q == null) { //(5)這裡使用cas設置p結點的next結點為newNode //(傳入null,比較p的next是否為null,為null則將next設置為newNode) if (p.casNext(null, newNode)) { //(6)下面是更新tail結點的程式碼 //在CAS執行成功之後,p(原鏈表的tail)結點的next已經是newNode,這裡就設置tail結點為newNode if (p != t) // hop two nodes at a time // 如果p不等於t,說明有其它執行緒先一步更新tail // 也就不會走到q==null這個分支了 // p取到的可能是t後面的值 // 把tail原子更新為新節點 casTail(t, newNode); // Failure is OK. return true; } } //如果被移除了 else if (p == q) //(7)多執行緒操作的時候,可能會有別的執行緒使用poll方法移除元素後可能會把head的next變成head,所以這裡需要找到新的head:這裡請參考後面的poll方法的講解圖示進行理解 p = (t != (t = tail)) ? t : head; else // (8)查詢尾節點 p = (p != t && t != (t = tail)) ? t : q; } } 上面是offer方法的實現以及注釋,這裡我們分為單執行緒執行和多執行緒執行兩種情況,按照上面的源碼實現一步步分析整個的流程。先討論單執行緒執行的過程
單執行緒執行
在單執行緒環境下執行,那麼就直接按照方法實現一步步執行判斷即可,下面通過適當的圖示來說明這個過程
-
首先當一個執行緒調用offer方法的時候,在程式碼(1)處進行非空檢查,為null拋出異常,不為null執行
(2) -
程式碼(2)
Node<E> newNode = new Node<E>(e)使用item作為構造函數的參數,創建一個新的結點 -
程式碼(3)
for (Node<E> t = tail, p = t;;)從隊列尾部開始自旋循環,保證從隊列尾部添加新的結點 -
獲得
tail的next結點(q),此時的隊列情況如下圖所示(默認構造方法中將head和tail都指向的是一個item為null的結點)。此時的q指向的是null

-
程式碼(4)
if (q == null)處執行判斷q==null為true -
程式碼(5)
if (p.casNext(null, newNode))處執行的是將p的next結以CAS方式更新為我們創建的newNode。(其中CAS會判斷p的next是否為null,為null才更新為newNode) -
此時的
p==t,所以不會執行更新tail的程式碼塊(6)casTail(t, newNode),而是從offer方法退出。這時候隊列情況如下所示
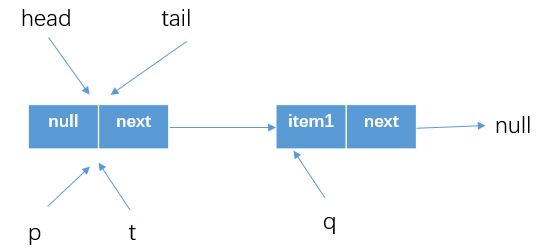
-
那麼這一個執行緒執行完,可是tail還沒有改變呢:實際上第二次進行offer的時候,會發現
p=tail,p.next!=null,就會執行程式碼(8)p = (p != t && t != (t = tail)) ? t : q,簡單分析一下:p != t:p為tail,t為tail,所以為falset != (t = tail):顯然也是false
-
所以結果就是p=q,然後進行下一次循環,之後判斷的
p.next就是null,所以可以CAS成功,也因為p!=t,所以會更新tail結點。
所以上面給的結論在這裡就體現了,即tail並不總是指向隊列的尾節點,那麼實際上也可以換種方式讓tail指向尾節點,即如下這樣實現
if (e == null) throw new NullPointerException(); Node<E> n = new Node<E>(e); for (;;) { Node<E> t = tail; if (t.casNext(null, n) && casTail(t, n)) { return true; } } 但是如果大量的入隊操作,那麼每次都需要以CAS方式更新tail指向的結點,當數據量很大的時候對性能的影響是很大的。所以最終實現上,是以減少CAS操作來提高大數量的入隊操作的性能:每間隔1次(tail指向和真正的尾節點之間差1)進行CAS操作更新tail指向尾節點(但是距離越長帶來的負面效果就是每次入隊時定位尾節點的時間就越長,因為循環體需要多循環一次來定位出尾節點(將指向真正的尾節點,然後添加newNode))。其實在前面分析成員屬性時候也知道了,tail是被volatile修飾的,而CAS方式本質上還是對於volatile變數的讀寫操作,而volatile的寫操作開銷大於讀操作的,所以Concurrent Linked Queue的是線上是通過增加對於volatile變數的讀操作次數從而相對的減少對其寫操作。下面是單執行緒執行offer方法的時候tail指向的變化簡圖示意
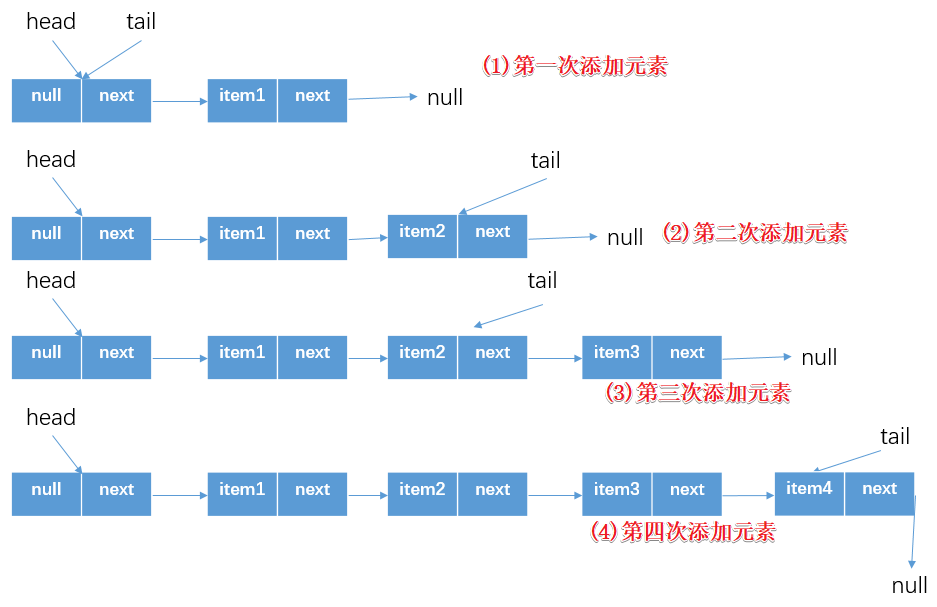
多執行緒執行
上面演示的單個執行緒的執行,那麼當在多執行緒環境下執行的話會發生什麼情況,這裡假設兩個執行緒並發的執行.
情況1
這裡分析的其實就是假設多個執行緒都會執行到CAS更新p.next結點的程式碼,我們下面看一下,假設threadA調用offer(item1),threadB調用offer(item2)都執行到p.casNext(null, newNode)位置處
- CAS操作的原子性,假設threadA先執行了上面那行程式碼,並成功更新了
p.next為newNode - 這時候threadB自然在進行CAS比較的時候就會失敗了(
p.next!=null),所以會進行下一次循環重新獲取tail結點然後嘗試更新
這時候的隊列情況如下
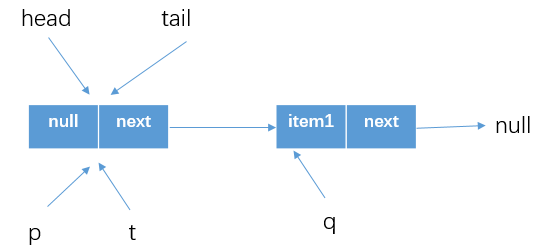
-
threadB獲得tail結點之後,發現其
q!=null(q=p.next,p=tail) -
繼續判斷
p==q也是false,所以執行程式碼(8) -
分析一下
p = (p != t && t != (t = tail)) ? t : q這個程式碼p != t:p為tail,t為tail,所以為falset != (t = tail):顯然也是false- 所以上面三目運算的結果就是
p=q,如下圖所示結果
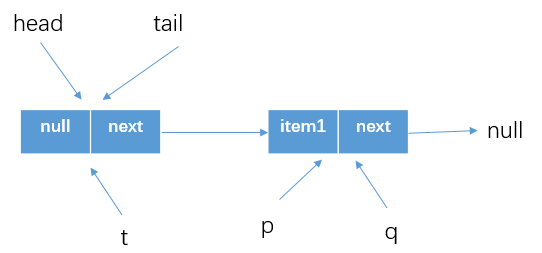
-
然後再次執行循環,這時候
p.next就是null了,所以可以執行程式碼(5)p.casNext(null,newNode)。這個時候CAS判斷得到p.next == null,所以可以設置p.next=Node(item2) -
CAS成功後,判斷
p!=t(如上圖所示),所以就可以設置tail為Node(item2)了。然後從offer退出,這個時候隊列情況為
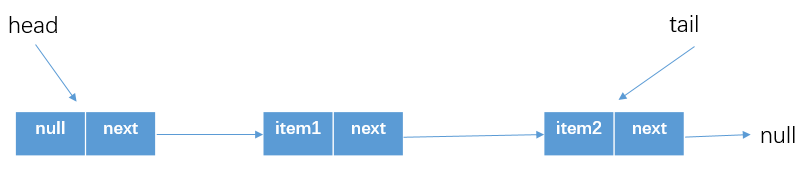
可以看出,情況1中假設兩個執行緒初始時候都拿到的是p=tail,p.next=null,那麼都會執行CAS嘗試添加newNode,但是只有一個執行緒能夠在第一次循環的時候添加成功然後返回true(但是這時候的tail還沒有變化,類似單執行緒總結那塊的tail和真正的尾節點差1或0),所以另一個執行緒會在第二次循環中重新嘗試,這個時候就會改變p的指向,即p = (p != t && t != (t = tail)) ? t : q程式碼處。然後再第三次循環中才能真正CAS添加成功(當然我們這裡分析的是假想的兩個執行緒情況,實際多執行緒環境肯定更複雜,但是邏輯還是差不多的)
情況2
這裡分析的是主要是程式碼p = (p != t && t != (t = tail)) ? t : q的另一種情況,即p=t的情況,還是先分析一下這行,假設現在
p != t為true,- t != (t = tail) : 也為true(左邊的t是再循環開始的時候獲得的指向tail的資訊,括弧中重新獲得tail並賦值給t,這個時候有可能別的執行緒已經更改了
volatile修飾的tail了)
那麼結果就是p 重新指向隊列的尾節點tail了,下面假想一種這樣的情況
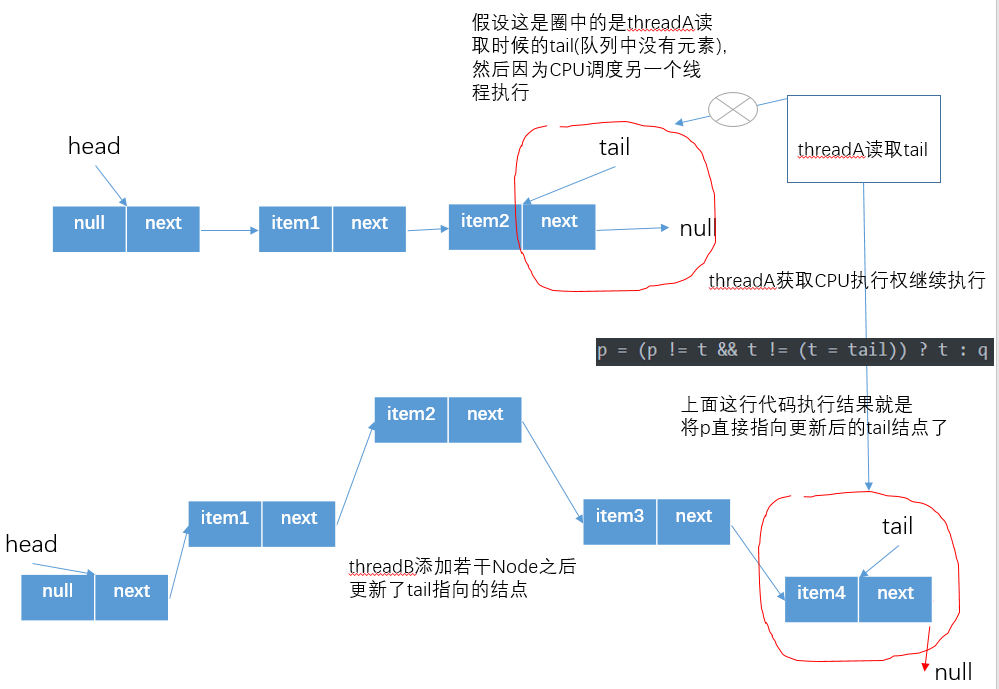
實際上這種是利用volatile的可見性,快速將一個要添加元素的執行緒找到當前隊列的尾節點,避免多餘的循環。 如圖,假設threadA此時讀取了變數tail,threadB剛好在這個時候添加若干Node後,此時會修改tail指針,那麼這個時候執行緒A再次執行t=tail時t會指向另外一個節點,所以threadA前後兩次讀取的變數t指向的節點不相同,即t != (t = tail)為true,並且由於t指向節點的變化p != t也為true,此時該行程式碼的執行結果為p和t最新的t指針指向了同一個節點,並且此時t也是隊列真正的尾節點。那麼,現在已經定位到隊列真正的隊尾節點,就可以執行offer操作了。
情況3
上面我們討論的都是多執行緒去添加元素的操作,那麼當既有執行緒offer也有執行緒調用poll方法的時候呢,這裡就要調用offer方法中的程式碼塊(7)了。因為還沒有說到poll方法,所以這裡的程式碼就先不做解釋,下面講poll方法在多執行緒中的執行的時候,會拿offer-poll-offer這種情況進行說明,那麼offer方法就可能執行這幾行程式碼了。
else if (p == q) //(7)多執行緒操作的時候,可能會有別的執行緒使用poll方法移除元素後可能會把head的next變成head,所以這裡需要找到新的head p = (t != (t = tail)) ? t : head;add方法
public boolean add(E e) { return offer(e);//這裡還是調用的offer方法,上面說到了,這裡就不說明了 }poll方法
poll方法是在隊列頭部獲取並移除一個元素,如果隊列為空就返回null,下面先看下poll方法的源碼,然後還是分別分析單執行緒和多執行緒下的執行
public E poll() { //標記 restartFromHead: for (;;) {//自旋循環 for (Node<E> h = head, p = h, q;;) { //(1)保存當前結點的item E item = p.item; //(2)如果當前結點的值不為null,那就將其變為null if (item != null && p.casItem(item, null)) { //(3)CAS成功之後會標記當前結點,並從鏈表中移除 if (p != h) // hop two nodes at a time updateHead(h, ((q = p.next) != null) ? q : p); return item; } //(4)如果隊列為空會返回null else if ((q = p.next) == null) { updateHead(h, p); return null; } //(5)如果當前結點被自引用了,重新找尋新的隊列頭節點 else if (p == q) continue restartFromHead; else p = q; //進行下一次循環,改變p的指向位置 } } } final void updateHead(Node<E> h, Node<E> p) { if (h != p && casHead(h, p)) h.lazySetNext(h); } 上面我們已經看了poll方法的源碼,下面我們就按照這個方法的實現通過圖示的方式來理解一下。
單執行緒執行
poll操作是從隊頭獲取元素,所以:
- 從head結點開始循環,首先
for (Node<E> h = head, p = h, q;;)獲得當前隊列的頭節點,當然如果隊列一開始就為空的時候,就如下所示

由於head結點是作為哨兵結點存在的,所以會執行到程式碼(4)else if ((q = p.next) == null),因為隊列為空,所以直接執行updateHead(h, p),而updateHead方法中判斷的h=p,所以直接返回null。
- 上面是隊列為空的情況 ,那麼當隊列不為空的時候呢,假設現在隊列情況如下所示
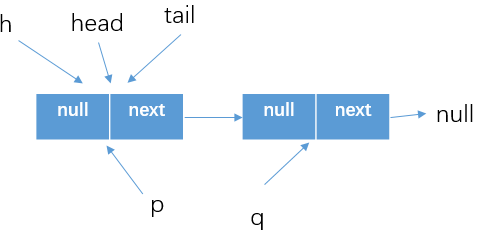
-
所以在程式碼(4)
else if ((q = p.next) == null)處的判斷結果是false, -
所以執行下一個判斷
else if (p == q),判斷結果還是false -
最後執行
p=q,完了之後下一次循環隊列狀態為
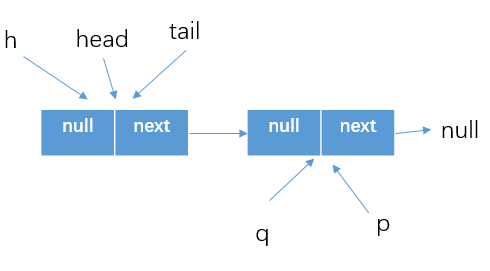
-
在新的一次循環中,可以判斷得到item!=null,所以使用CAS方式將item設置為null,(這是單執行緒情況下的測試)所以繼續執行
if(p!=h),判斷結果為true。所以執行if中的內容:updateHead(h, ((q = p.next) != null) ? q : p),什麼意思呢?如下所示,所以我們這裡的結果就是q=null,所以傳入的參數為p(p指向的位置如上圖所示)//updateHead方法的參數(Node h,Node p) q = p.next; if(null != q) { //第二個參數就是q } else { //第二個參數就是p }然後執行updateHead方法,這裡我們需要再看一下該方法的細節
final void updateHead(Node<E> h, Node<E> p) { //如果h!=p,就以CAS的方式將head結點設置為p if (h != p && casHead(h, p)) //這裡是將h結點的next結點設置為自己(h) h.lazySetNext(h); } //Node類中的方法 void lazySetNext(Node<E> val) { UNSAFE.putOrderedObject(this, nextOffset, val); }那麼執行完這些之後,隊列中狀態是什麼樣呢,如下圖所示。執行完畢就返回被移除的元素怒item1

多執行緒執行offer、poll
上面分析了單執行緒下,調用poll方法的執行流程。其實剛剛再將offer方法的時候還有一個坑沒有解決。如下描述的情況
- 假設原有隊列中有一個元素item1
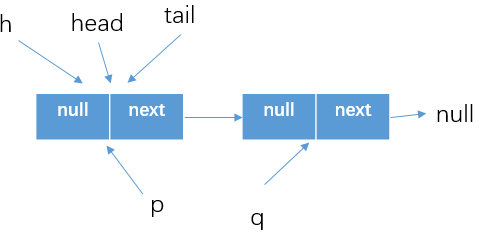
-
假設在thread1調用offer方法的時候,別的執行緒剛好調用poll方法將head結點移除了,按照上面的分析,poll方法調用後隊列的情況如下
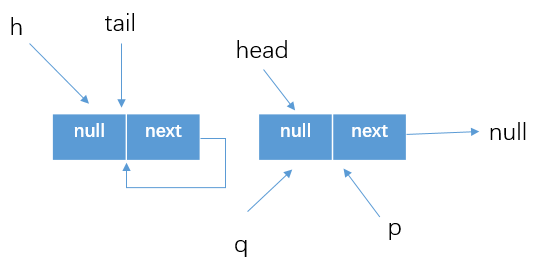
-
(這裡回憶一下offer的執行流程)所以在thread1繼續執行的時候,執行的
for (Node<E> t = tail, p = t;;)之後獲得tail指向的位置如上圖所示,但是這個tail指向的結點的next指針指向的位置還是自己。所以Node<E> q = p.next執行之後q=tail=p。所以在offer方法中就會執行以下判斷else if (p == q) //(7)多執行緒操作的時候,可能會有別的執行緒使用poll方法移除元素後可能會把head的next變成head,所以這裡需要找到新的head p = (t != (t = tail)) ? t : head;還是簡單分析一下
p = (t != (t = tail)) ? t : head這句,如下所示。簡單分析之後就能得出,p指向了poll方法調用完畢後的新的head結點(如上圖所示的head結點),然後調用offer的執行緒就能正常的添加結點了,具體流程還是和上面講到的一樣。(那這個tail又在什麼時候被指向隊尾結點呢,實際上在調用offer方法添加完元素之後p.casNext(null, newNode),就會判斷得出p != t,那完了之後就會更新tail指向的位置了)//在最開始時候獲得的t=tail t=tail; //for循環中賦值t //...offer的其他程式碼 if(t != (t = tail)) { //這裡還是一樣:tail為volatile修飾,所以重新讀取tail變數 p = t; //這裡表示tail結點不變(按照上圖poll執行完後的情況,tail指向位置沒有變化,所以p不會被賦值為t) } else { p = head; //注意這時候的head已經指向的新的首結點 }
多執行緒執行poll、poll
分析這麼多,我們發現跟offer方法留坑一樣,poll還有一處程式碼還沒有分析,所以下面還是通過圖示進行分析,先看下這個程式碼框架。
//標記 restartFromHead: for (;;) {//自旋循環 for (Node<E> h = head, p = h, q;;) { //...other code //這是自旋循環體中的一個判斷 else if (p == q) continue restartFromHead; } } 還是假設現在兩個執行緒去執行poll方法,
- 初始情況下的隊列狀態為
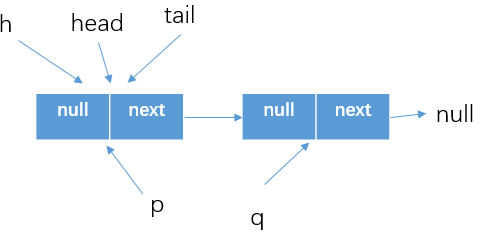
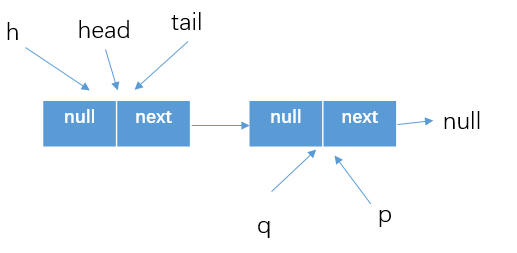
- 假設threadA執行poll方法,並成功的執行
if (item != null && p.casItem(item, null))這塊,將item1設置為了null,如下圖所示。
- 但是threadA還沒有執行updateHead方法,這個時候threadB執行poll之後,p指向了上圖中的head,如下所示
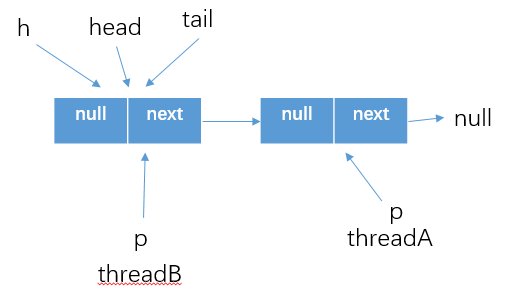
- 之後threadA執行updateHead方法更新了head的指向,並將原head的next結點指向自己.那麼執行緒B執行
q=p.next,自然得到的就是p==q的結果了,所以這個時候就需要跳到外層循環重新獲取最新的head結點,然後繼續執行
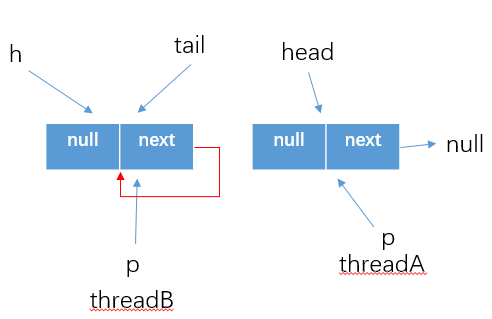
poll方法總結
poll方法在移除頭部元素的時候,使用CAS操作將頭節點的item設置為了null,然後通過沖洗設置頭節點head的指向位置來達到刪除隊列元素的效果。這個時候原來的頭部哨兵結點就是一個孤立的結點了,會被回收掉。當然,如果執行緒執行poll方法的時候發現head結點被修改(上面說的這種情況),就需要跳轉到最外層循環重新獲取新的結點。
peek方法
獲取隊列頭部的第一個元素但不刪除,如果隊列為空則返回null。下面是該方法的實現
public E peek() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; if (item != null || (q = p.next) == null) { updateHead(h, p); return item; } else if (p == q) continue restartFromHead; else p = q; } } } 需要注意的是,第一次調用peek方法的時候會刪除哨兵結點,並讓隊列中的head結點指向隊列中的第一個元素或者null.
size方法
計算當前隊列元素個數,但是因為使用的是CAS的方式在並發環境下可能因為別的執行緒刪除或者增加元素導致計算結果不準確。
public int size() { int count = 0; for (Node<E> p = first(); p != null; p = succ(p)) if (p.item != null) // Collection.size() spec says to max out if (++count == Integer.MAX_VALUE) break; return count; } //找到隊列中的第一個元素(head指向的item為null的結點不算(就是哨兵結點)), //沒有則返回null Node<E> first() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { boolean hasItem = (p.item != null); if (hasItem || (q = p.next) == null) { updateHead(h, p); return hasItem ? p : null; } else if (p == q) continue restartFromHead; else p = q; } } } remove方法
傳入的參數為要刪除的元素,如果隊列中存在該元素就刪除找到的第一個,然後返回true,否則返回false
public boolean remove(Object o) { if (o != null) { //如果傳入參數為null,直接返回false Node<E> next, pred = null; for (Node<E> p = first(); p != null; pred = p, p = next) { boolean removed = false; E item = p.item; //找到相等的就使用cas設置為null,只有一個執行緒操作成功 //別的循環查找是否又別的匹配的obj if (item != null) { if (!o.equals(item)) { //獲取next元素 next = succ(p); continue; } removed = p.casItem(item, null); } next = succ(p); if (pred != null && next != null) // unlink pred.casNext(p, next); if (removed) return true; } } return false; } 