並查集(Union Find)
並查集介紹
我們之前講的樹結構,都是由父親節點指向孩子節點,而並查集卻是由孩子指向父親的這樣一種數據結構。

給出圖中任意的兩點,問這兩點之間是否可以通過一個路徑連接起來?並查集就是處理這類連接問題的很好的數據結構。即用來處理網路中節點的連接狀態,這裡的網路是個抽象慨念,可以是用戶之間形成 的網路。其實這類連接問題我們也可以使用集合類來進行實現,即求兩個集合的並集。
本文設計的並查集主要支援兩個操作:
- union(p,q) 並,對傳入的兩個數據p和q,在並查集內部將這兩個數據,以及這兩個數據所在的集合合併起來。
- isConnected(p,q)查詢對於給定的兩個數據,他們是否屬於同一個集合。
由於並查集可以有不同的實現,我們可以設計一個並查集的介面:
public interface UF {
int getSize();
boolean isConnected(int p ,int q);
void unionElements(int p,int q);
}
對於具體元素是誰,我們並不關心,我們關心的是 id=p 和 id=q 這樣的兩個元素是否相連,而對於p和q對應具體的值,並不關心。

第一種實現
表示每一個元素都屬於不同的集合,沒有任意兩個元素是相連的
public class UnionFind01 implements UF {
//我們第一種實現,Union-Find本質就是一個數組
private int[] id;
//有參構造:指定並查集中元素的個數
public UnionFind01(int size){
id = new int[size];
//初始化, 每一個id[i]指向自己, 沒有合併的元素
for (int i=0; i<id.length; i++)
id[i] = i;
}
@Override
public int getSize() {
return id.length;
}
// 查找元素p所對應的集合編號
// O(1)複雜度
private int find(int p){
if (p < 0 || p >= id.length)
throw new IllegalArgumentException("p is out of bound");
return id[p];
}
// 查看元素p和元素q是否所屬一個集合
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合併元素p和元素q所屬的集合
// O(n) 複雜度
@Override
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID)
return;
// 合併過程需要遍歷一遍所有元素, 將兩個元素的所屬集合編號合併
for (int i = 0; i < id.length; i++){
if (id[i] == pID)
id[i] = qID;
}
}
}
第二種實現
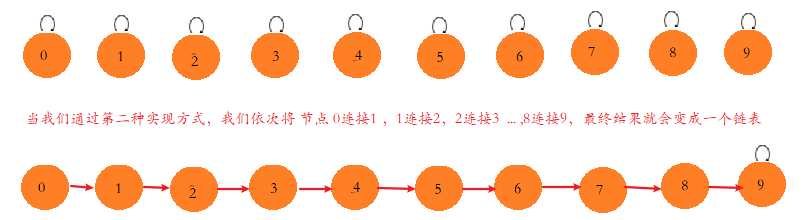
我們的第二版Union-Find, 使用一個數組構建一棵指向父節點的樹,如圖:
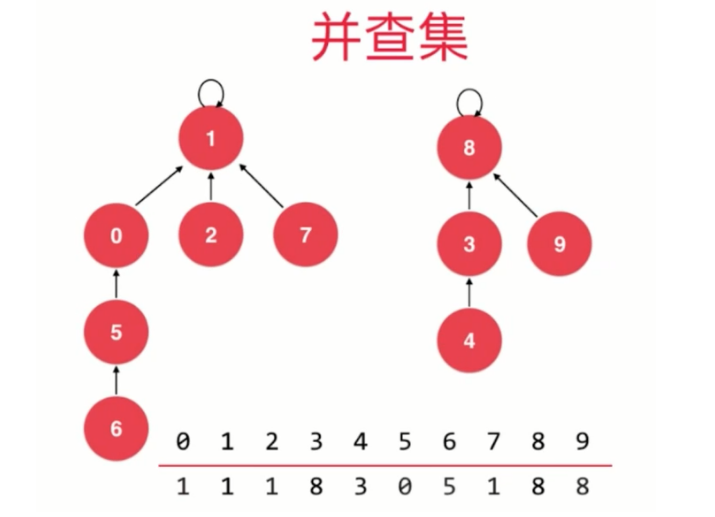
我們在初始化時,有10個元素,編號分別為0至9,即可以看成一棵只含有一個根節點的樹結構,這個根節點的值即為索引值0至9,連接操作圖如下:
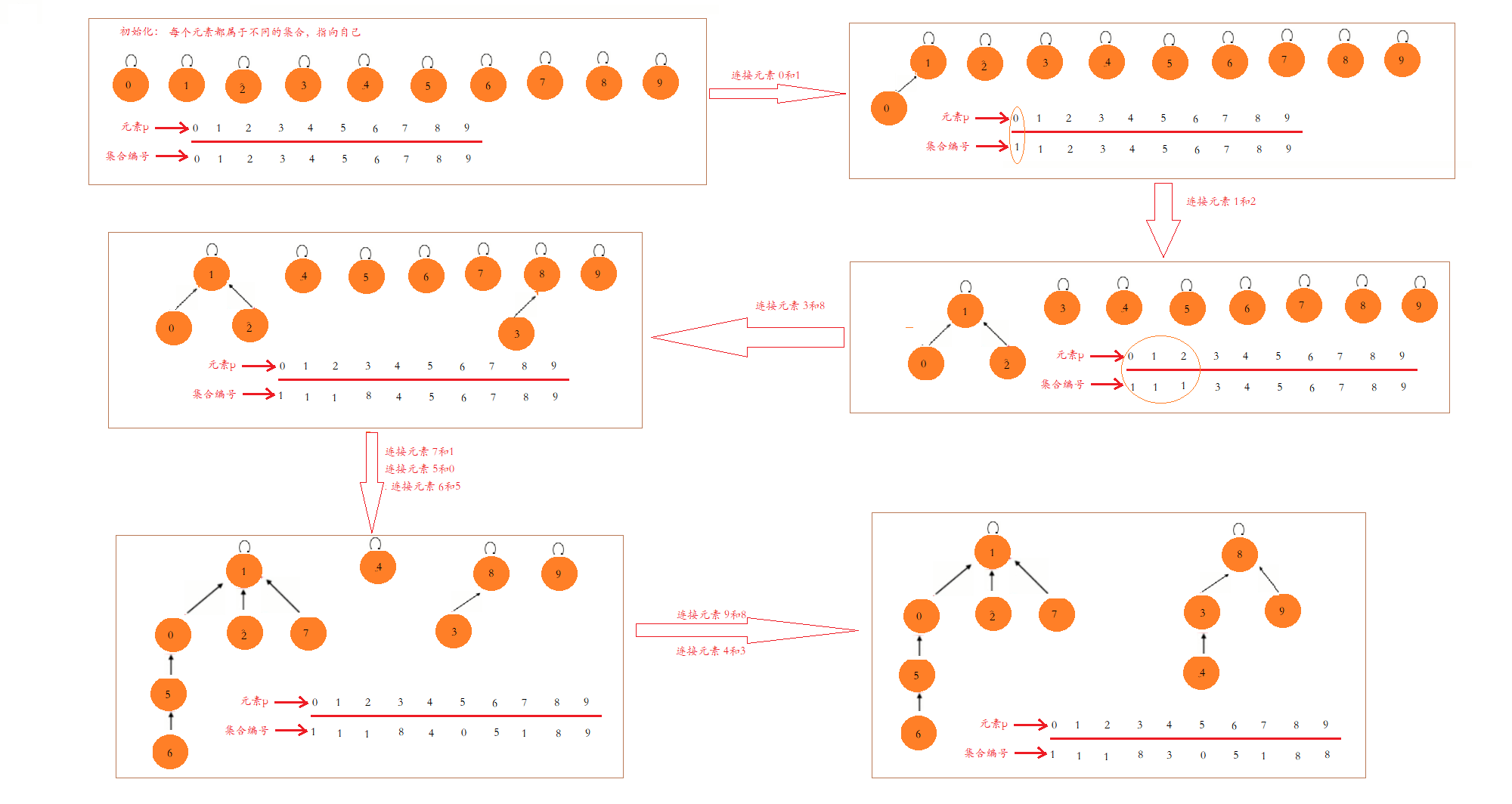
程式碼實現如下:
public class UnionFind02 implements UF {
//parent[i]表示第i個元素所指向的父節點
private int[] parent;
//構造函數
public UnionFind02(int size) {
parent = new int[size];
// 初始化, 每一個parent[i]指向自己, 表示每一個元素自己自成一個集合
for (int i = 0; i < size; i++){
parent[i] = i;
}
}
@Override
public int getSize() {
return parent.length;
}
// 查找過程, 查找元素p所對應的集合編號
// O(h)複雜度, h為樹的高度
public int find(int p){
if (p < 0 || p >= parent.length)
throw new IllegalArgumentException("p id out of bound");
// 不斷去查詢自己的父親節點, 直到到達根節點
// 根節點的特點: parent[p] == p
while (p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所屬一個集合
// O(h)複雜度, h為樹的高度
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合併元素p和元素q所屬的集合
// O(h)複雜度, h為樹的高度
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
parent[pRoot] = qRoot;
}
}
現在讓我們來簡單測試下並查集的這兩種實現方式的效率:
public class Test {
//簡單測試兩種並查集實現方式的效率
private static double testUF(UF uf, int m){
int size = uf.getSize();
Random random = new Random();
long startTime = System.nanoTime();
//測試連接操作
for (int i = 0; i < m ; i ++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.unionElements(a,b);
}
//測試這兩個元素是否連接
for (int i = 0; i < m ; i ++){
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.isConnected(a,b);
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
int size = 100000;
int m = 10000;
//第一種實現
UnionFind01 uf01 = new UnionFind01(size);
System.out.println("UnionFind01 -> "+ testUF(uf01,m) +"s");
//第二種實現
UnionFind02 uf02 = new UnionFind02(size);
System.out.println("UnionFind02 -> "+ testUF(uf02,m) +"s");
}
}
測試程式碼運行結果:
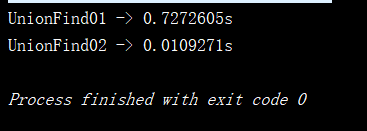
通過測試程式碼的運行結果可以看出,我們的第二種實現方式是要比第一種實現方式 效率高一些的,現在我們看一個關於並查集的應用,就是力扣網上的547號練習題,題目描述如下:
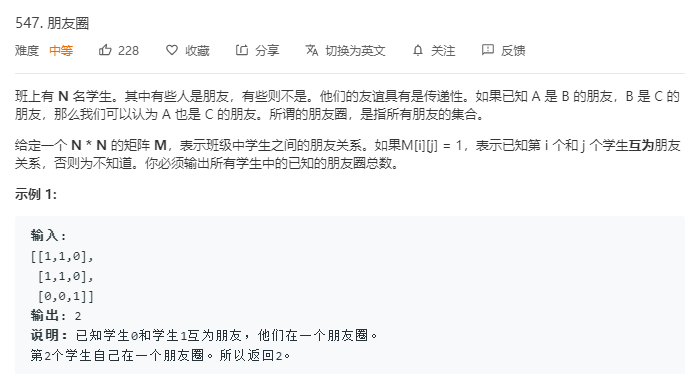
現在就讓我們基於並查集的第二種實現方式,來解決這個問題:
public int findCircleNum(int[][] M) {
int n = M.length;
UnionFind2 uf = new UnionFind2(n);
for(int i = 0 ; i < n ; i ++)
for(int j = 0 ; j < i ; j ++)
//如果M[i][j] = 1,則表示第 i 個和 j 個學生互為朋友,即屬於同一個集合
if(M[i][j] == 1)
uf.unionElements(i, j);
TreeSet<Integer> set = new TreeSet<>();
for(int i = 0 ; i < n ; i ++)
set.add(uf.find(i));
//獲取不同集合的個數
return set.size();
}
並查集的優化方式
考慮size
由於我們之前的實現方式,在進行連接操作時,總是將左邊的元素指向右邊的元素,這樣很容易就會形成一個鏈表,這樣的查詢時間複雜度就會變成O(n),為了避免這樣極端的情況,我們可以在每個節點中添加一個元素個數的變數,即該節點下連接的節點個數,這樣在進行連接操作時,就將節點加到節點個數少的集合中去,如圖:

程式碼實現如下:
public class UnionFind03 implements UF {
private int[] parent; // parent[i]表示第i個元素所指向的父節點
private int[] sz; // sz[i]表示以i為根的集合中元素個數
public UnionFind03(int size){
parent = new int[size];
sz = new int[size];
// 初始化, 每一個parent[i]指向自己, 表示每一個元素自己自成一個集合
for(int i = 0 ; i < size ; i ++){
parent[i] = i;
sz[i] = 1;
}
}
@Override
public int getSize() {
return parent.length;
}
// 查找過程, 查找元素p所對應的集合編號
// O(h)複雜度, h為樹的高度
public int find(int p){
if (p < 0 || p >= parent.length)
throw new IllegalArgumentException("p is out of bound.");
// 不斷去查詢自己的父親節點, 直到到達根節點
// 根節點的特點: parent[p] == p
while ( p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所屬一個集合
// O(h)複雜度, h為樹的高度
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合併元素p和元素q所屬的集合
// O(h)複雜度, h為樹的高度
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
// 根據兩個元素所在樹的元素個數不同判斷合併方向
// 將元素個數少的集合合併到元素個數多的集合上
if (sz[pRoot] < sz[qRoot]){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else {// sz[qRoot] <= sz[pRoot]
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}
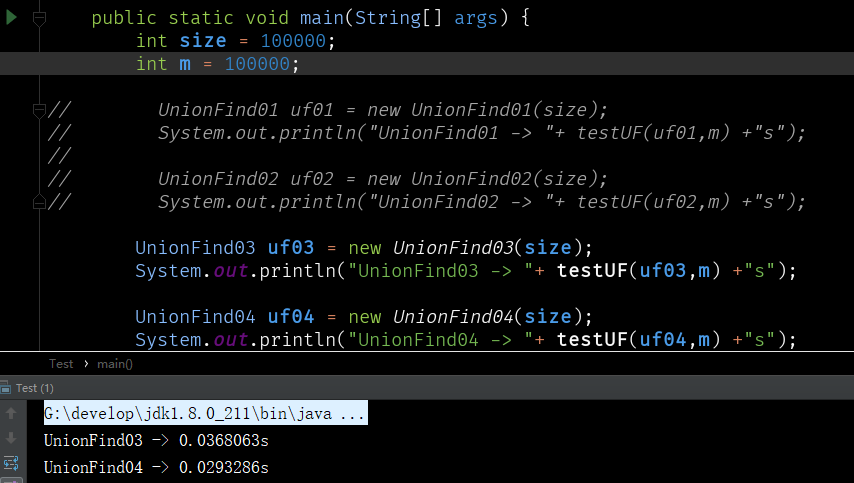
我們可以通過測試方法,對這三種實現方式進行簡單的比較,我們會發現,優化size之後的並查集,效率比前兩種是要好很多的。

基於rank的優化
rank[i]表示根節點為i的樹的高度,即根據兩個元素所在的輸的rank不同判斷合併方向,將rank低的合併到rank高的集合上

程式碼實現如下:
public class UnionFind04 implements UF {
private int[] rank; // rank[i]表示以i為根的集合所表示的樹的層數
private int[] parent; // parent[i]表示第i個元素所指向的父節點
// 構造函數
public UnionFind04(int size){
rank = new int[size];
parent = new int[size];
// 初始化, 每一個parent[i]指向自己, 表示每一個元素自己自成一個集合
for( int i = 0 ; i < size ; i ++ ){
parent[i] = i;
rank[i] = 1;
}
}
@Override
public int getSize(){
return parent.length;
}
// 查找過程, 查找元素p所對應的集合編號
// O(h)複雜度, h為樹的高度
private int find(int p){
if(p < 0 || p >= parent.length)
throw new IllegalArgumentException("p is out of bound.");
// 不斷去查詢自己的父親節點, 直到到達根節點
// 根節點的特點: parent[p] == p
while(p != parent[p])
p = parent[p];
return p;
}
// 查看元素p和元素q是否所屬一個集合
// O(h)複雜度, h為樹的高度
@Override
public boolean isConnected( int p , int q ){
return find(p) == find(q);
}
// 合併元素p和元素q所屬的集合
// O(h)複雜度, h為樹的高度
@Override
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
// 根據兩個元素所在樹的rank不同判斷合併方向
// 將rank低的集合合併到rank高的集合上
if(rank[pRoot] < rank[qRoot])
parent[pRoot] = qRoot;
else if(rank[qRoot] < rank[pRoot])
parent[qRoot] = pRoot;
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此時, 我維護rank的值
}
}
}
現在讓我們對基於size的優化,和基於rank的優化進行簡單的測試對比:
路徑壓縮優化
為什麼需要路徑壓縮優化呢?基於前面的四種實現方式,我們會發現下圖中的三顆並查集數,無論是find()還是isConnected()都是等效的

由於並查集的查找方法是和樹得高度相關的,所以我們只要讓樹得高度降低,就都是對並查集的優化,理想情況下,我們樹得高度為2,即只有根節點和葉子節點。但實際情況並不都是如此,所以我們只能儘可能降低樹得高度,這就是我們的路徑壓縮優化。那我們的路徑壓縮是如何實現的呢?我們在查找某個節點的時候,讓這個節點指向它父親節點的父親節點,然後判斷這個節點是否是待查找節點的根節點,如不是,再使用待查找節點指向它父親節點的父親節點,如下圖:
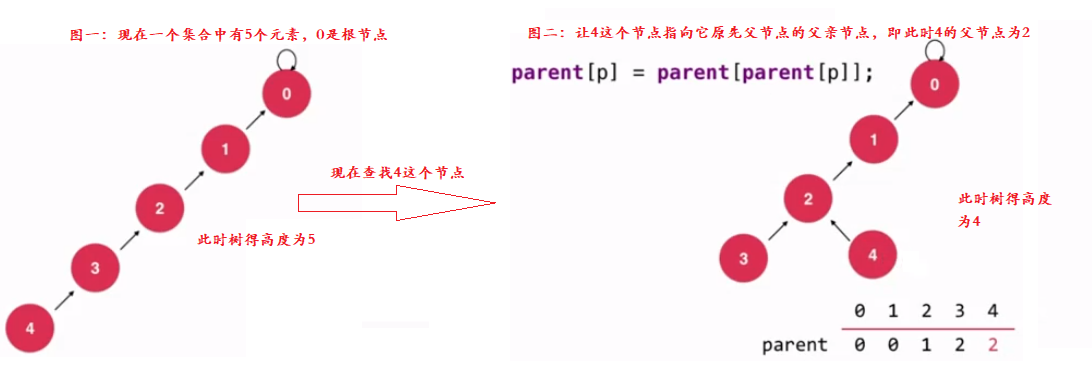

根據圖中分析,可以看出我們的路徑壓縮是在查找過程中實現的,所以我們修改查找方法即可:程式碼 實現如下:
// 查找過程, 查找元素p所對應的集合編號
// O(h)複雜度, h為樹的高度
private int find(int p){
if(p < 0 || p >= parent.length)
throw new IllegalArgumentException("p is out of bound.");
while( p != parent[p] ){
parent[p] = parent[parent[p]];
p = parent[p];
}
return p;
}

