SpringCloud入門(十一):Sleuth 與 Zipkin分散式鏈路跟蹤
- 2020 年 5 月 1 日
- 筆記
- SpringCloud
現今業界分散式服務跟蹤的理論基礎主要來自於 Google 的一篇論文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最為廣泛的開源實現是 Twitter 的 Zipkin,為了實現平台無關、廠商無關的分散式服務跟蹤,CNCF 發布了布式服務跟蹤標準 Open Tracing。中國,淘寶的 「鷹眼」、京東的 「Hydra」、大眾點評的 「CAT」、新浪的 「Watchman」、唯品會的 「Microscope」、窩窩網的 「Tracing」 都是這樣的系統。
一個分散式服務跟蹤系統主要由三部分構成:數據收集、數據存儲、數據展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,數據存儲可分為實時數據和全量數據兩部分,實時數據用於故障排查(Trouble Shooting),全量數據用於系統優化;數據收集除了支援平台無關和開發語言無關係統的數據收集,還包括非同步數據收集(需要跟蹤隊列中的消息,保證調用的連貫性),以及確保更小的侵入性;數據展示又涉及到數據挖掘和分析。雖然每一部分都可能變得很複雜,但基本原理都類似。
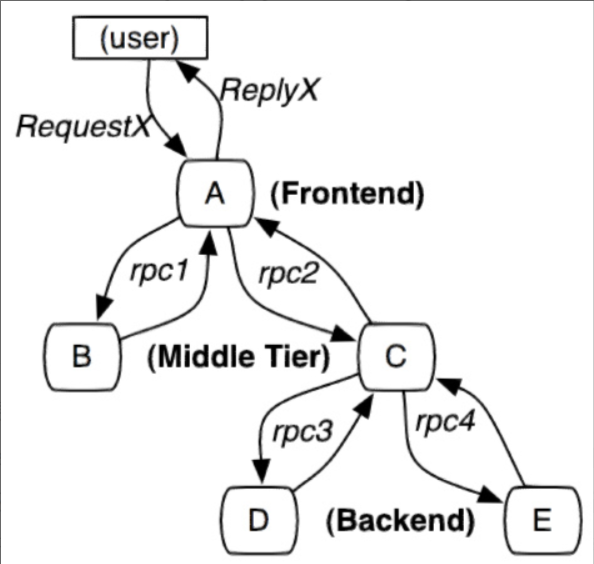
服務追蹤的追蹤單元是從客戶發起請求(request)抵達被追蹤系統的邊界開始,到被追蹤系統向客戶返迴響應(response)為止的過程,稱為一個 trace。每個 trace 中會調用若干個服務,為了記錄調用了哪些服務,以及每次調用的消耗時間等資訊,在每次調用服務時,埋入一個調用記錄,稱為一個 span。這樣,若干個有序的 span 就組成了一個 trace。在系統向外界提供服務的過程中,會不斷地有請求和響應發生,也就會不斷生成 trace,把這些帶有 span 的 trace 記錄下來,就可以描繪出一幅系統的服務拓撲圖。附帶上 span 中的響應時間,以及請求成功與否等資訊,就可以在發生問題的時候,找到異常的服務;根據歷史數據,還可以從系統整體層面分析出哪裡性能差,定位性能優化的目標。
SpringCloud Sleuth 也為我們提供了一套完整的解決方案。Sleuth 為服務之間調用提供鏈路追蹤,通過 Sleuth 可以很清楚的了解到一個服務請求經過了哪些服務,每個服務處理花費了多長。從而讓我們可以很方便的理清各微服務間的調用關係。此外 Sleuth 可以幫助我們:
耗時分析:通過 Sleuth 可以很方便的了解到每個取樣請求的耗時,從而分析出哪些服務調用比較耗時;
可視化錯誤:對於程式未捕捉的異常,可以通過集成 Zipkin 服務介面上看到;
鏈路優化:對於調用比較頻繁的服務,可以針對這些服務實施一些優化措施。
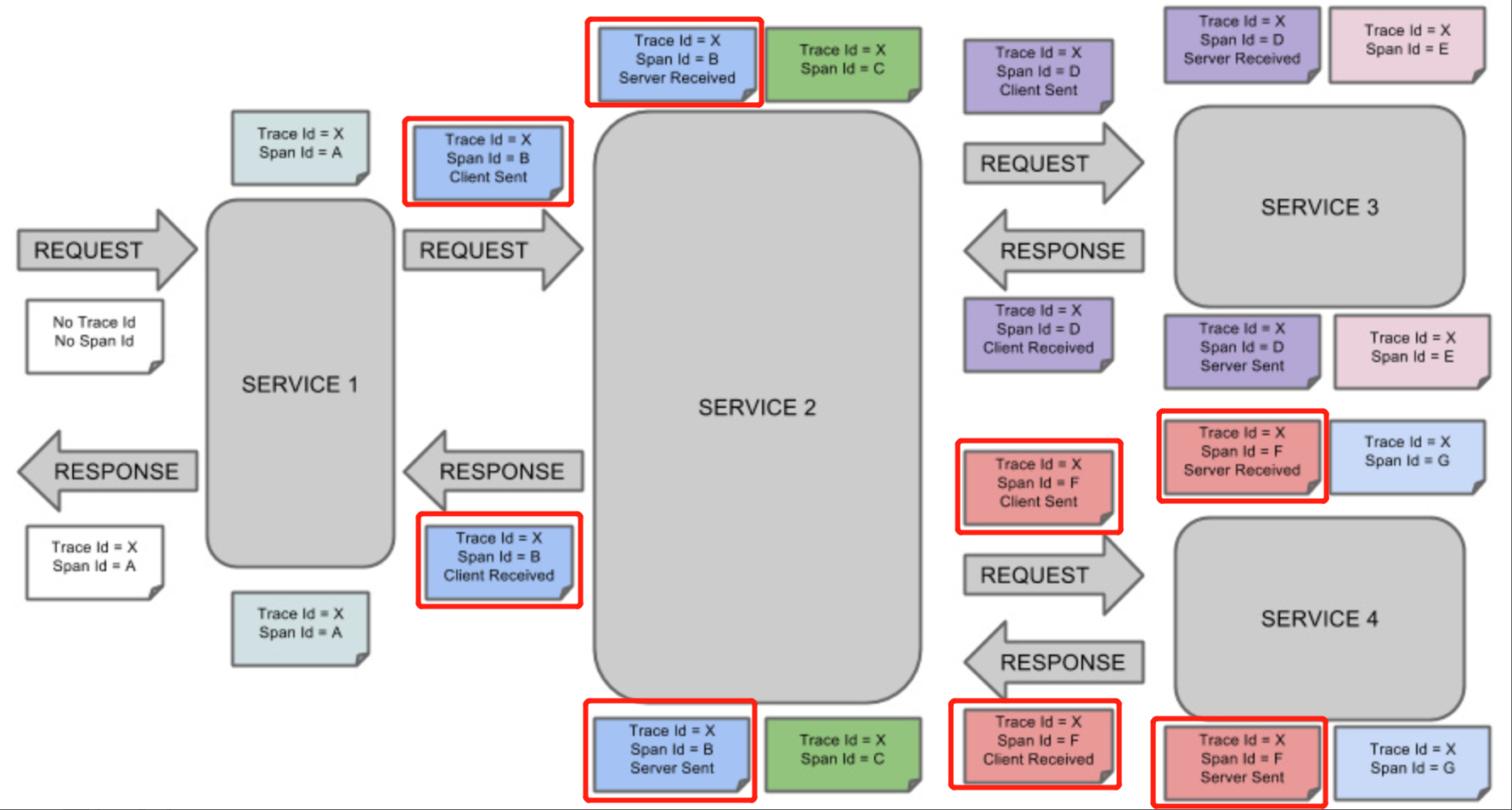
Spring Cloud Sleuth 的概念圖,圖中畫圈的部分是Sleuth的標記(Annotation,一個標註可以理解成span生命周期中重要時刻的數據快照,比如一個標註中一般包含發生時刻(timestamp)、事件類型(value)、端點(endpoint)等資訊)資訊,分別表示:
客戶端發送 client send:客戶端已經發出請求。此標記biao描繪了跨度的開始。
伺服器接收 server received:伺服器端得到請求,將開始進行處理。
伺服器發送 server send:在完成請求處理後(響應發送回客戶端時)標記。
客戶端接收 client received:表示跨度的結束,客戶端已成功接收到伺服器端的響應。
通過這四個標記,我們可以計算出相應的四個值:
請求延時=sr-cs
響應延時 cr-ss
伺服器處理時間:ss-sr
客戶端請求時間:cr-cs = 請求延時+響應延時+伺服器處理時間
SpringCloud Sleuth 入門
<!-- 1. 加入POM依賴 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- 2. 修改屬性文件,打開sleuth日誌 -->
logging.level.org.springframework.cloud.sleuth=debug
啟動項目後,通過consumer去調用provider觀察輸出的日誌資訊,會發現多出了:[ms-consumer-user,7d0cbb49820bbacd,551bf65184bbc971,false],其中四個參數分別代表[微服務應用名,traceId,spanId,是否持久化]

Sleuth 的持久化Sleuth+zipkin
SpringCloud Sleuth結合 Zipkin,將資訊發送到 Zipkin,利用 Zipkin 的存儲來存儲資訊,利用 Zipkin UI 來展示數據。Zipkin是Twitter 的一個開源項目,它基於 Google Dapper 實現,它致力於收集服務的定時數據,以解決微服務架構中的延遲問題,包括數據的收集、存儲、查找和展現。我們可以使用它來收集各個伺服器上請求鏈路的跟蹤數據,並通過它提供的 REST API 介面來輔助我們查詢跟蹤數據以實現對分散式系統的監控程式,從而及時地發現系統中出現的延遲升高問題並找出系統性能瓶頸的根源。除了面向開發的 API 介面之外,它也提供了方便的 UI 組件來幫助我們直觀的搜索跟蹤資訊和分析請求鏈路明細,比如:可以查詢某段時間內各用戶請求的處理時間等。Zipkin 提供了可插拔數據存儲方式:In-Memory、MySql、Cassandra 以及 Elasticsearch,生產推薦 Elasticsearch。
Zipkin 基礎架構如圖所示,它主要由 4 個核心組件構成:
Collector:收集器組件,它主要用於處理從外部系統發送過來的跟蹤資訊,將這些資訊轉換為 Zipkin 內部處理的 Span 格式,以支援後續的存儲、分析、展示等功能。
Storage:存儲組件,它主要對處理收集器接收到的跟蹤資訊,默認會將這些資訊存儲在記憶體中,我們也可以修改此存儲策略,通過使用其他存儲組件將跟蹤資訊存儲到資料庫中。
RESTful API:API 組件,它主要用來提供外部訪問介面。比如給客戶端展示跟蹤資訊,或是外接系統訪問以實現監控等。
Web UI:UI 組件,基於 API 組件實現的上層應用。通過 UI 組件用戶可以方便而有直觀地查詢和分析跟蹤資訊。

Zipkin 入門
Zipkin 分為兩端,一個是 Zipkin 服務端,一個是 Zipkin 客戶端,客戶端也就是微服務的應用。客戶端會配置服務端的 URL 地址,一旦發生服務間的調用的時候,會被配置在微服務裡面的 Sleuth 的監聽器監聽,並生成相應的 Trace 和 Span 資訊發送給服務端。發送的方式主要有兩種,一種是 HTTP 報文的方式,還有一種是消息匯流排的方式如 RabbitMQ。
方法一 HTTP 報文的方式:
<!-- 1. 加入POM依賴 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <!-- 2. 修改屬性文件,打開sleuth日誌 --> #zipkin server的地址 spring.zipkin.base-url=http://localhost:9411/ spring.sleuth.web.client.enabled=true #取樣比例默認是0.1 為1表示全部上報 spring.sleuth.sampler.probability=1 <!-- 3.啟動一個Zipkin的服務端,在SpringBoot1.x我們需要手動搭建,在Springboot2.x之後我們只需去官網下載,通過java -jar啟動即可 下載鏈接為https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec -->
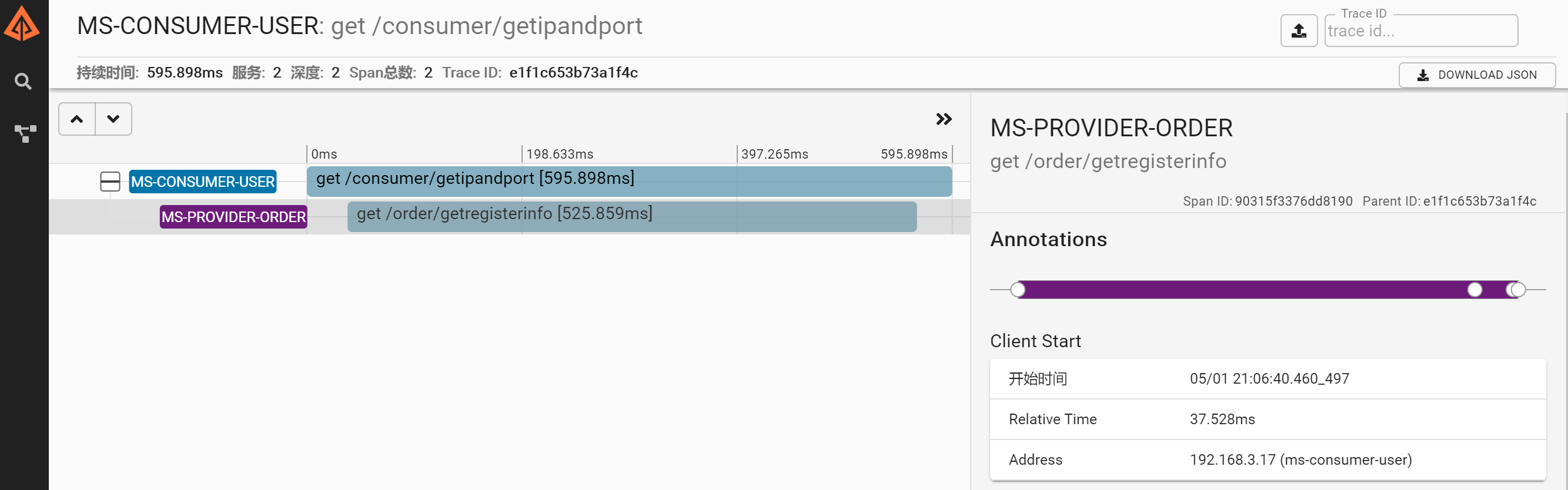
啟動後通過//localhost:9411/zipkin進入介面,消費者向提供者發送請求後,zipkinUI會顯示相關的調用鏈資訊。
方法二 RabbitMQ的方式:
<!-- 1. 加入POM依賴 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
<!-- 2. 修改屬性文件,打開sleuth日誌 -->
spring.zipkin.sender.type=rabbit
spring.sleuth.web.client.enabled=true
#取樣比例默認是0.1 為1表示全部上報
spring.sleuth.sampler.probability=1
spring.rabbitmq.host=127.0.0.1
spring.rabbitmq.port=5672
spring.rabbitmq.password=guest
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
<!-- 3.啟動一個Zipkin的服務端,通過命令指定rabbit -->
java -jar zipkin-server-2.12.9-exec.jar --zipkin.collector.rabbitmq.address=127.0.0.1
Zipkin+mysql數據持久化
<!-- 1. 創建一個zipkin的資料庫,並執行建表語句 --> CREATE TABLE `zipkin_annotations` ( `trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`), KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`), KEY `trace_id_high_3` (`trace_id_high`,`trace_id`), KEY `endpoint_service_name` (`endpoint_service_name`), KEY `a_type` (`a_type`), KEY `a_key` (`a_key`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; <!-- 2.啟動一個Zipkin的服務端,通過命令指定mysql --> zipkin server啟動java -jar zipkin-server-2.11.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306
備註:文章參考 //windmt.com/2018/04/24/spring-cloud-12-sleuth-zipkin/
