數據挖掘入門系列教程(十二)之使用keras構建CNN網路識別CIFAR10
簡介
在上一篇部落格:數據挖掘入門系列教程(十一點五)之CNN網路介紹中,介紹了CNN的工作原理和工作流程,在這一篇部落格,將具體的使用程式碼來說明如何使用keras構建一個CNN網路來對CIFAR-10數據集進行訓練。
如果對keras不是很熟悉的話,可以去看一看官方文檔。或者看一看我前面的部落格:數據挖掘入門系列教程(十一)之keras入門使用以及構建DNN網路識別MNIST,在數據挖掘入門系列教程(十一)這篇部落格中使用了keras構建一個DNN網路,並對keras的做了一個入門使用介紹。
CIFAR-10數據集
CIFAR-10數據集是影像的集合,通常用於訓練機器學習和電腦視覺演算法。它是機器學習研究中使用比較廣的數據集之一。CIFAR-10數據集包含10 種不同類別的共6w張32×32彩色影像。10個不同的類別分別代表飛機,汽車,鳥類,貓,鹿,狗,青蛙,馬,輪船 和卡車。每個類別有6,000張影像
在keras恰好提供了這些數據集。載入數據集的程式碼如下所示:
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print(x_train.shape, 'x_train samples')
print(x_test.shape, 'x_test samples')
print(y_train.shape, 'y_trian samples')
print(y_test.shape, 'Y_test samples')
輸出結果如下:

訓練集有5w張圖片,測試集有1w張圖片。在\(x\)數據集中,圖片是\((32,32,3)\),代表圖片的大小是\(32 \times 32\),為3通道(R,G,B)的圖片。
展示圖片內容
我們可以稍微的展示一下圖片的內容,python程式碼如下所示:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12,10))
x, y = 8, 6
for i in range(x*y):
plt.subplot(y, x, i+1)
plt.imshow(x_train[i],interpolation='nearest')
plt.show()
下面就是數據集中的部分圖片:

數據集變換
同樣,我們需要將類標籤進行one-hot編碼:
import keras
# 將類向量轉換為二進位類矩陣。
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
實際上這一步還有很多牛逼(騷)操作,比如說對數據集進行增強,變換等等,這樣都可以在一定程度上提高模型的魯棒性,防止過擬合。這裡我們就怎麼簡單怎麼來,就只對數據集標籤進行one-hot編碼就行了。
構建CNN網路
構建的網路模型程式碼如下所示:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten,Conv2D, MaxPooling2D
# 構建CNN網路
model = Sequential()
# 添加卷積層
model.add(Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:]))
# 添加激活層
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
# 添加最大池化層
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 將上一層輸出的數據變成一維
model.add(Flatten())
# 添加全連接層
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
# 網路模型的介紹
print(model.summary())
這裡解釋一下程式碼:
Conv2D
Conv2D代表2D的卷積層,可能這裡會有人問,我的圖片不是3通道(RGB)的嗎?為什麼使用的是Conv2D而不是Conv3D。首先先說明,在Conv2D中的這個「2」代表的是卷積層可以在兩個維度(也就是width,length)進行移動。那麼同理Conv3D中的「3」代表這個卷積層可以在3個維度進行移動(比如說影片中的width ,length,time)。那麼針對RGB這種3通道(channels),卷積過程中輸入有多少個通道,則濾波器(卷積核)就有多少個通道。
簡單點來說就是:
輸入
單色圖片的input,是2D, \(w \times h\)
彩色圖片的input,是3D,\(w \times h \times channels\)
卷積核filter
單色圖片的filter,是2D, \(w \times h\)
彩色圖片的filter,是3D, \(w \times h \times channels\)
值得注意的是,卷積之後的結果是二維的。(因為會將3維卷積得到的結果進行相加)
接著繼續解釋Conv2D的參數:
Conv2D(32, (3, 3), padding='same',input_shape=x_train.shape[1:])
32表示的是輸出空間的維度(也就是filter濾波器的輸出數量)(3,3)代表的是卷積核的大小strides(這裡沒有用到):這個代表是滑動的步長。input_shape:輸入的維度,這裡是(28,28,3)
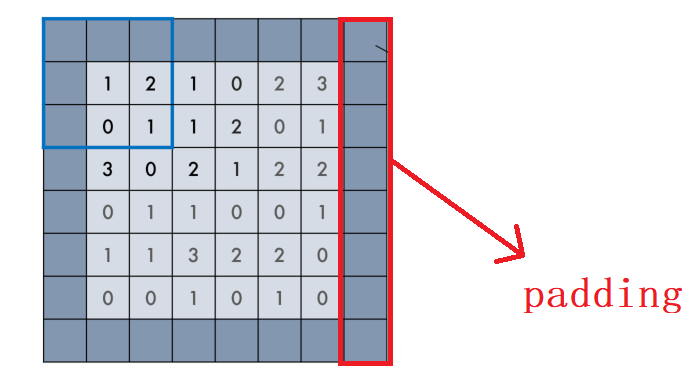
padding在上一篇部落格介紹過,在keras中有兩個取值:"valid" 或 "same" (大小寫敏感)。
- valid padding:不進行任何處理,只使用原始影像,不允許卷積核超出原始影像邊界
- same padding:進行填充,允許卷積核超出原始影像邊界,並使得卷積後結果的大小與原來的一致
Flatten
Flatten這一層就是為了將多維數據變成一維數據:

構建網路
from keras.optimizers import RMSprop
# 利用 RMSprop 來訓練模型。
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy']
)
其他的參數在上兩篇部落格中已經講了,就不再贅述。
進行訓練評估
這裡大家可以根據自己的電腦配置適當調整一下batch_size的大小。
history = model.fit(x_train, y_train,
batch_size=32,
epochs=64,
verbose=1,
validation_data=(x_test, y_test)
)
在i5-10代u,mx250的情況下,訓練一輪大概需要27s左右。
訓練完成之後,進行評估:
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
結果如下所示:

這個結果可以說的上是一言難盡,😔。
查看歷史訓練情況
import matplotlib.pyplot as plt
# 繪製訓練過程中訓練集和測試集合的準確率值
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# 繪製訓練過程中訓練集和測試集合的損失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
最終在batch_size=1024的情況下(為什麼不用程式碼中batch_size=32的那張圖呢?因為那張圖沒有保存,而我實在是不想再訓練等那麼久了。)

總結
總的來說效果不是很好,因為我就是用最基本的網路結構,用的圖片也沒有進行其他處理。不過本來這篇部落格就是為了簡單的介紹如何使用keras搭建一個cnn網路,效果差一點就差一點吧。如果想得到更好的效果,kaggle歡迎大家。
參考
- CIFAR-10
- keras中文文檔
- 數據挖掘入門系列教程(十一點五)之CNN網路介紹
- 數據挖掘入門系列教程(十一)之keras入門使用以及構建DNN網路識別MNIST
- RGB影像在CNN中如何進行convolution?
- 卷積的三種模式full, same, valid以及padding的same, valid


