Python爬蟲之記錄一次下載驗證碼的嘗試
好久沒有寫過爬蟲的文章了,今天在嘗試著做驗證碼相關的研究時,遇到了驗證碼的收集問題。
一般,驗證碼的載入都有著比較複雜的演算法和加密在裡邊,但是筆者今天碰到的驗證碼卻比較幸運,有跡可循。在此,給出本爬蟲的相關記錄。
注意,文章和程式碼中均不會給出相關的真實網站的資訊,避免不道德的行為。
首先,讓我們來看一看該驗證碼的頁面,如下:
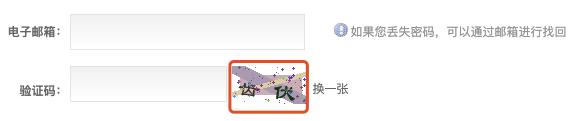
如果我們嘗試著查看該驗證碼載入時的源程式碼,會發現源碼如下:

我們可以發現,該驗證碼的載入機制其實並不複雜,只是在網址後面跟了一個時間戳,而這個時間戳,是由JavaScript中的方法產生的,函數內容為new Date().getTime()。
知道了驗證碼背後載入的原理,那麼我們不難通過Python來實現驗證碼的下載。
可惜的是,上述JS函數產生的時間戳是13位數字,而Python的time.time()方法產生的時間戳為浮點數,小數點前10位,小數點後6位。那麼,我們如果來產生符合上述JS函數產生的時間戳呢?
一個簡單的想法是,我們讓Python來調用JS。真的可以嗎?幸運的是,前人已經提我們做好了這個工作,有個神奇的Python第三方模組,叫做PyExecJS。顧名思義,這個模組就是用來執行JS程式碼的。
該模組的源碼中給出了一個例子,我們可以嘗試下,程式碼如下:
# -*- coding: utf-8 -*-
import execjs
print(execjs.eval("'red yellow blue'.split(' ')"))
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
""")
print(ctx.call("add", 1, 2))
輸出結果如下:
['red', 'yellow', 'blue']
3
OK,有了上面的例子,我們就知道如何使用該模組了,我們可以輕鬆地寫出下面的程式碼來下載驗證碼了:
# -*- coding: utf-8 -*-
import execjs
import urllib.request
js_func = """
function get_milliseconds(){
return new Date().getTime();
}
"""
ctx = execjs.compile(js_func)
result = ctx.call("get_milliseconds")
print(len(str(result)))
# 注意,網址已經隱藏
url = "//***/captcha/?%s" % result
urllib.request.urlretrieve(url, "1.png")
下載的驗證碼如下:
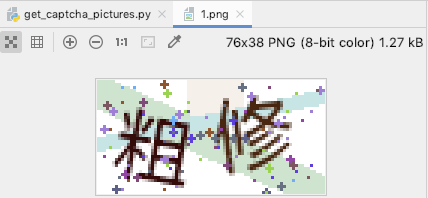
通過我們這次的嘗試,發現如下:
- PyExecJS支援Python對JavaScript的操作,所以下次有機會,可以在Python中執行JS函數;
- 驗證碼的載入演算法不宜簡單,要注意加密。
本次分享到此結束,感謝大家的閱讀~


