小白也能輕鬆上手的Prometheus教程
- 2020 年 4 月 30 日
- 筆記
- Kubernetes, Prometheus, 普羅米修斯, 監控
這篇文章將承接此前關於使用Prometheus配置自定義告警規則的文章。在本文中,我們將demo安裝Prometheus的過程以及配置Alertmanager,使其能夠在觸發告警時能發送郵件,但我們將以更簡單的方式進行這一切——通過Rancher安裝。

我們將在這篇文章中看到沒有使用依賴項的情況下如何完成這一操作。在本文中,我們不需要:
-
專門配置運行指向Kubernetes集群的kubectl
-
有關kubectl的知識,因為我們可以使用Rancher UI
-
Helm binary的安裝/配置
前期準備
-
一個Google雲平台帳號(免費的即可),其他雲也是一樣的
-
Rancher v2.4.2(文章發布時的最新版本)
-
運行在GKE(版本為1.15.11-gke.3)上的Kubernetes集群(EKS或者AKS也可以)
啟動一個Rancher實例
首先,啟動一個Rancher實例。你可以根據Rancher的指引啟動:
使用Rancher部署一個GKE集群
使用Rancher來設置並配置一個Kubernetes集群。你可以訪問下方鏈接獲取文檔:
//rancher2.docs.rancher.cn/docs/cluster-provisioning/_index
部署Prometheus
我們將利用Rancher的應用商店來安裝Prometheus。Rancher的應用商店主要集合了許多Helm Chart,以便於用戶能夠重複部署應用程式。
我們的集群起來並且開始運行之後,讓我們在「Apps」的標籤下選擇為其創建的默認項目,然後單擊「Launch」按鈕。

現在我們來搜索我們感興趣的chart。我們可以設置很多欄位——但是對於本次demo來說我們將保留默認值。你可以在Detailed Description部分找到關於這些值的有用資訊。無需擔心出現問題,儘管去查看它們的用途。在頁面底部,點擊【Launch】。Prometheus Server以及Alertmanager將會被安裝以及配置。
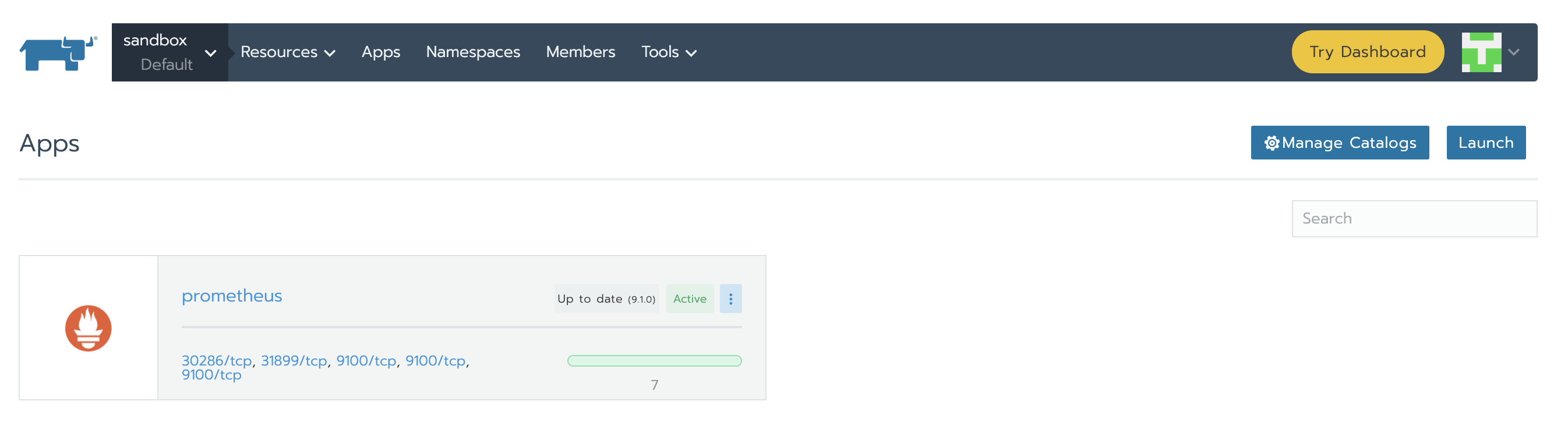
當安裝完成時,頁面如下所示:
接下來,我們需要創建Services以訪問Prometheus Server以及Alertmanager。點開資源下方的工作負載標籤,在負載均衡部分,我們可以看到目前還沒有配置。點擊導入YAML,選擇prometheus namespace,一次性複製兩個YAML並點擊導入。稍後你將了解我們如何知道使用那些特定的埠和組件tag。
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 9090
protocol: TCP
selector:
component: server
apiVersion: v1
kind: Service
metadata:
name: alertmanager-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 9093
protocol: TCP
selector:
component: alertmanager
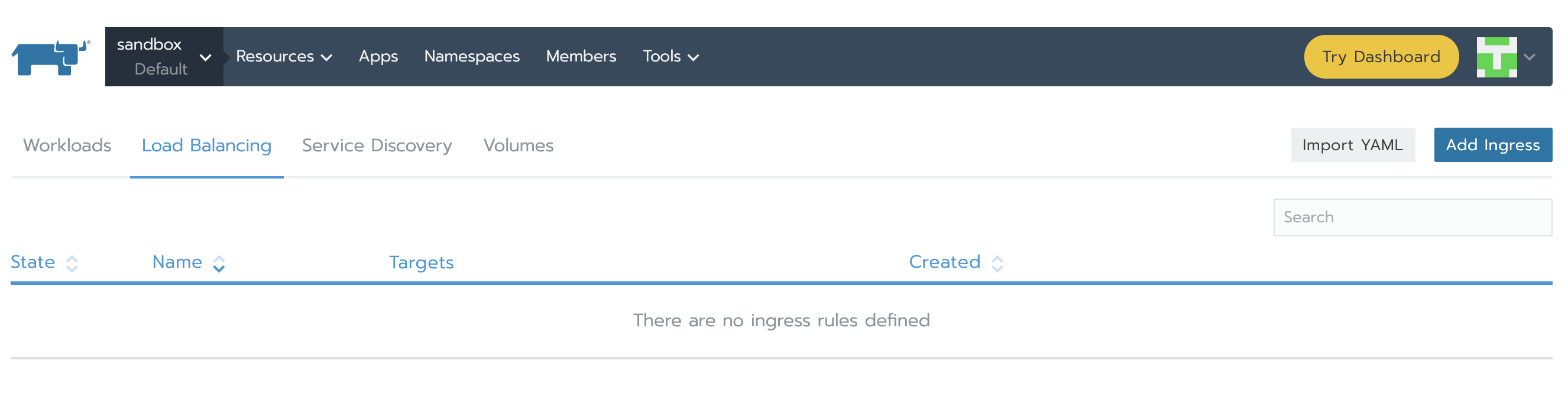
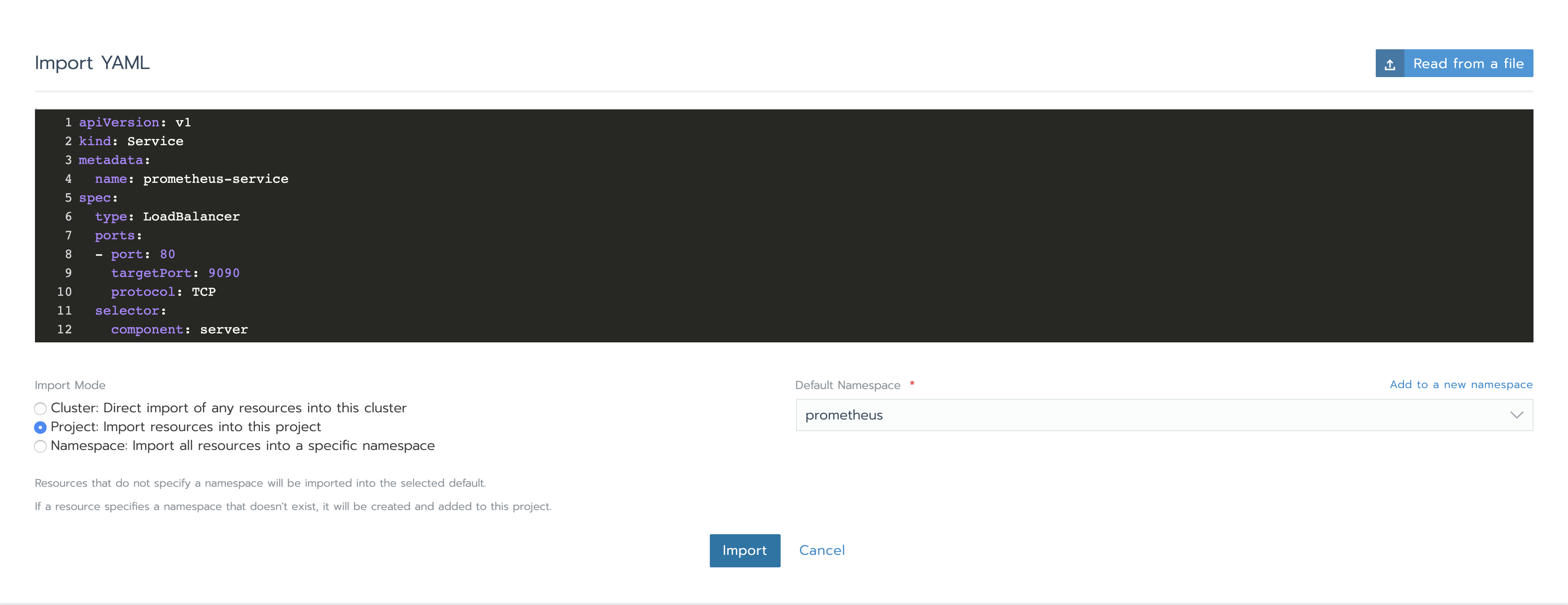
完成之後,service將顯示Active。
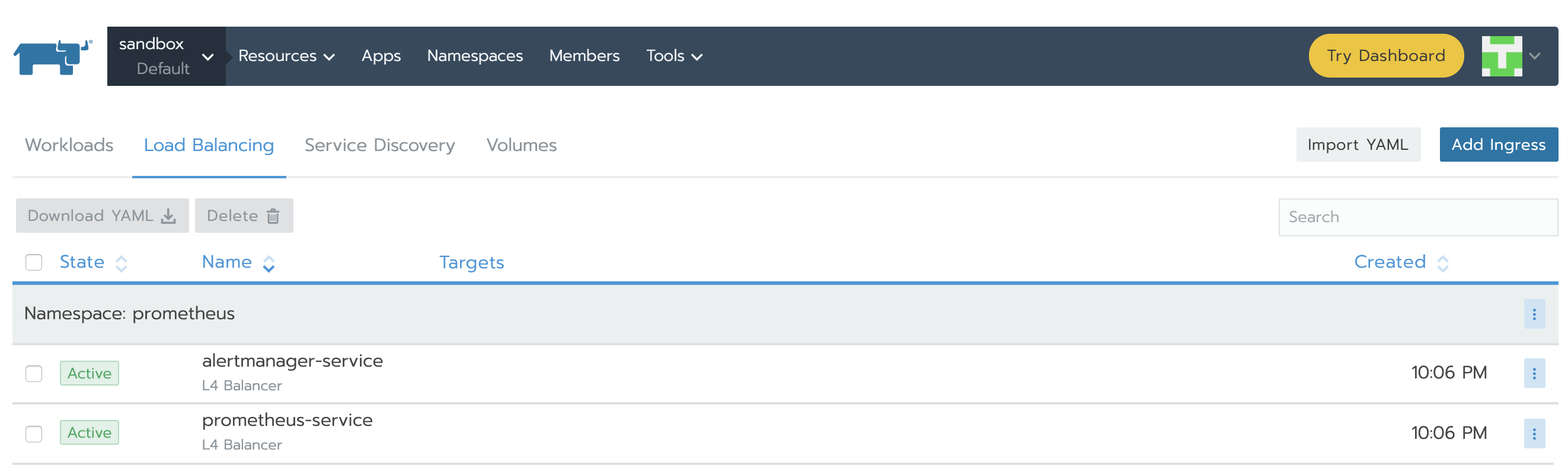
在右側垂直省略號的下拉菜單里你能找到IP並點擊View/Edit YAML。在yaml文件的底部,你將會看到類似的部分:
status:
loadBalancer:
ingress:
- ip: 34.76.22.14
訪問IP將為我們展示Prometheus Server和Alertmanager的GUI。你會發現這時沒有什麼內容可以查看的,因為尚未定義規則以及配置告警。
添加規則
規則可以讓我們觸發告警。這些規則都是基於Prometheus的表達式語言。無論何時,只要符合條件,告警就會被觸發並發送給Alertmanager。
現在來看看我們如何添加規則。
在資源->工作負載標籤下,我們可以看到Deployment在運行chart時創建了什麼。我們來詳細看看prometheus-server和prometheus-alertmanager。
我們從第一個開始並理解其配置,我們如何編輯它並了解服務在哪個埠上運行。點擊垂直省略號菜單按鈕並點擊View/Edit YAML。
首先,我們看到的是兩個與Deplolyment關聯的容器:prometheus-server-configmap-reload和prometheus-server。容器prometheus-server的專屬部分有一些相關資訊:
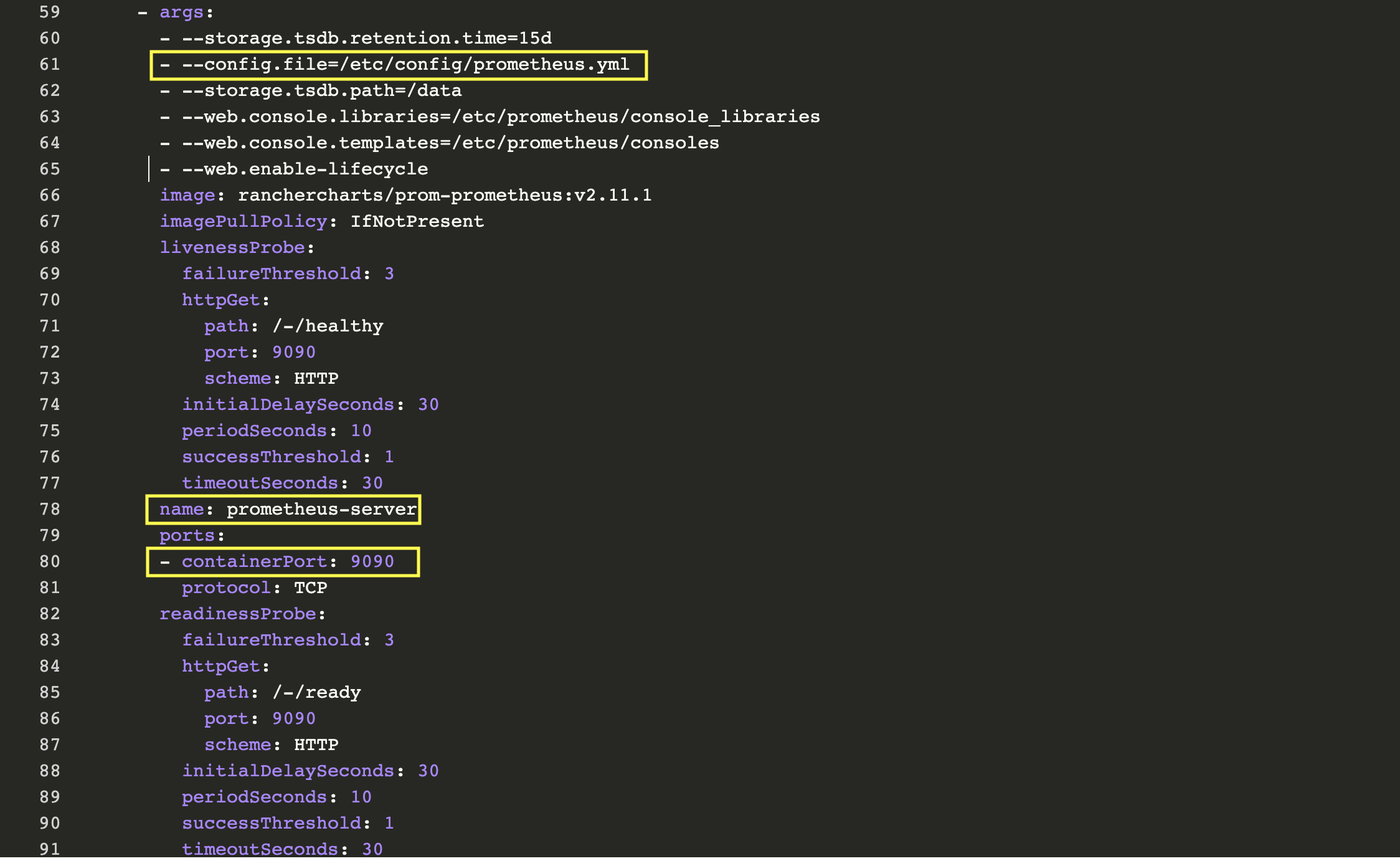
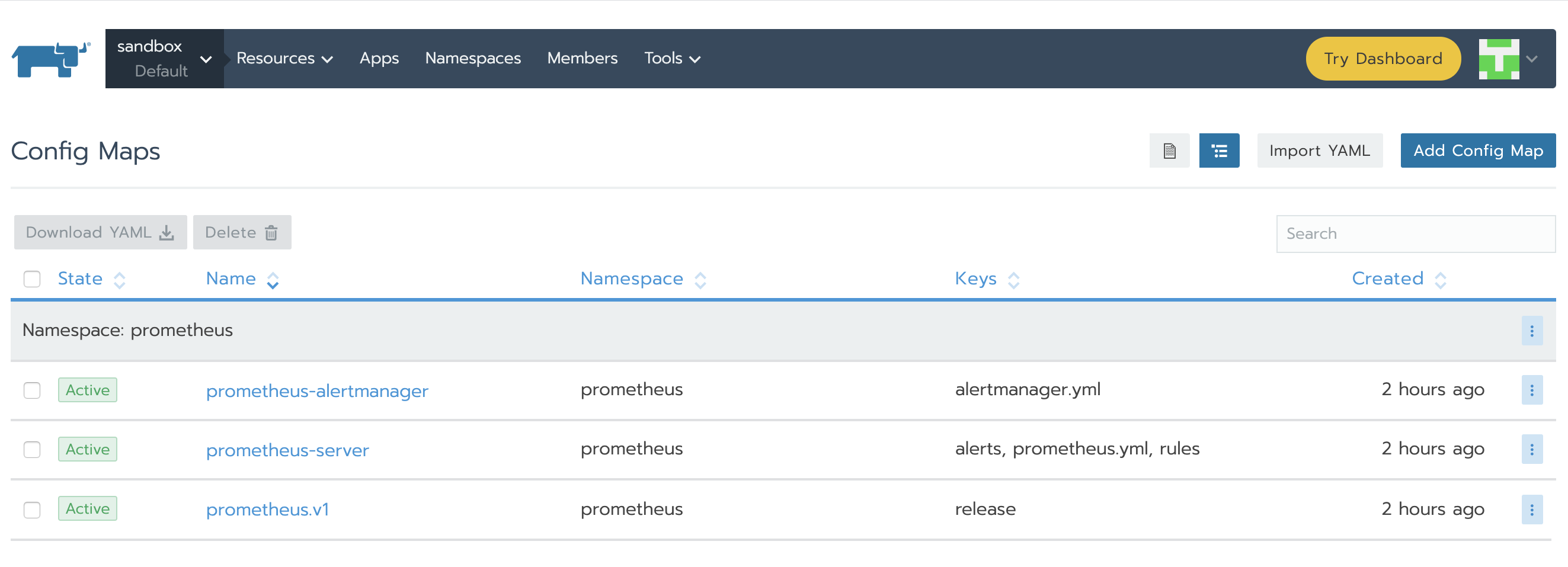
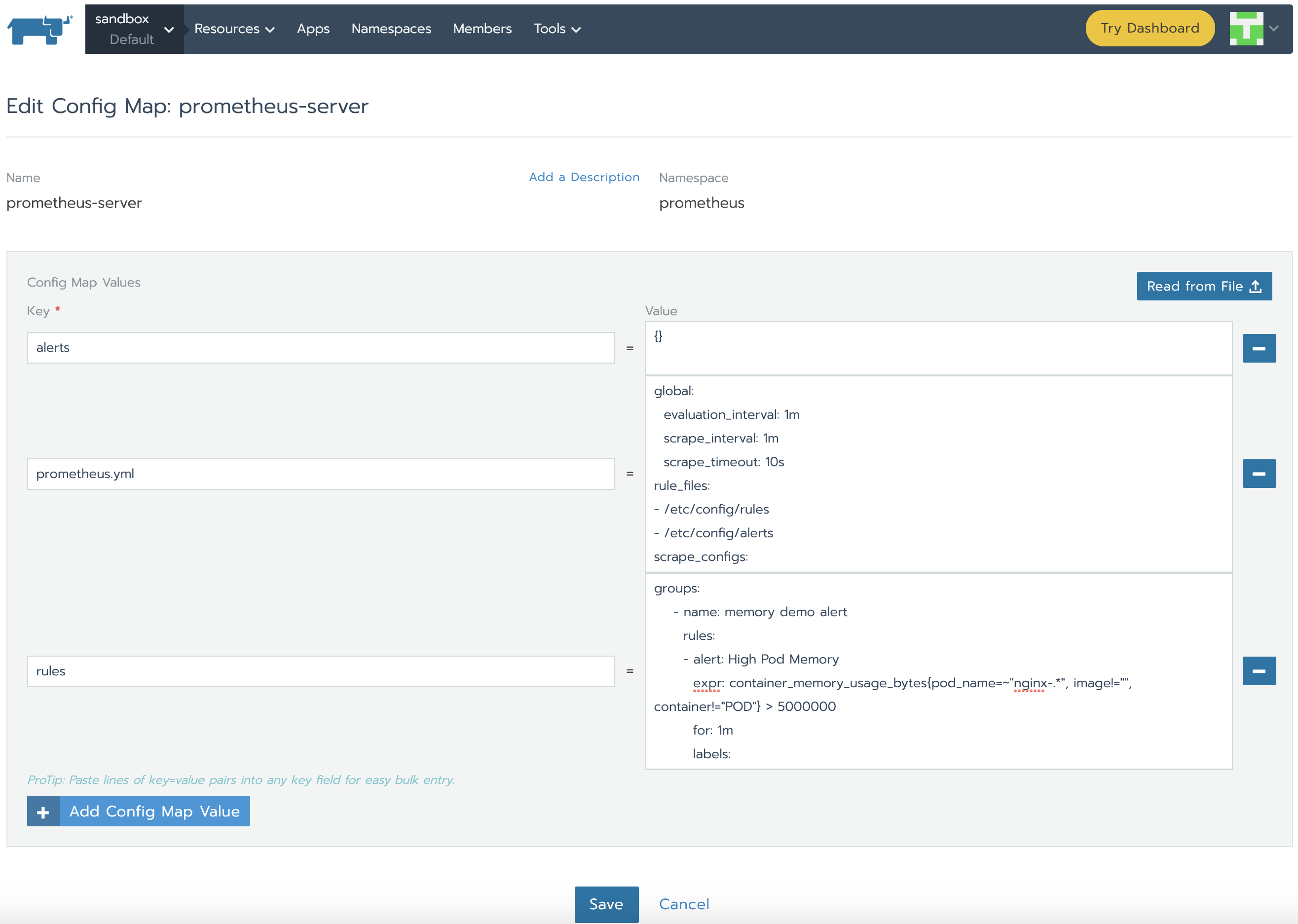
正如我們所了解的,Prometheus通過prometheus.yml進行配置。該文件(以及其他在serverFiles中列出的文件)將掛載到server pod。為了添加/編輯規則,我們需要修改這個文件。實際上,這就是一個Config Map,可以在Resources Config的標籤頁下找到。點擊垂直的省略菜單按鈕並Edit。在規則部分,讓我們添加新的規則並點擊保存。
groups:
- name: memory demo alert
rules:
- alert: High Pod Memory
expr: container_memory_usage_bytes{pod_name=~"nginx-.*", image!="", container!="POD"} > 5000000
for: 1m
labels:
severity: critical
annotations:
summary: High Memory Usage
- name: cpu demo alert
rules:
- alert: High Pod CPU
expr: rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m]) > 0.04
for: 1m
labels:
severity: critical
annotations:
summary: High CPU Usage
規則將會由Prometheus Server自動載入,然後我們在Prometheus Server GUI中能看到它們:
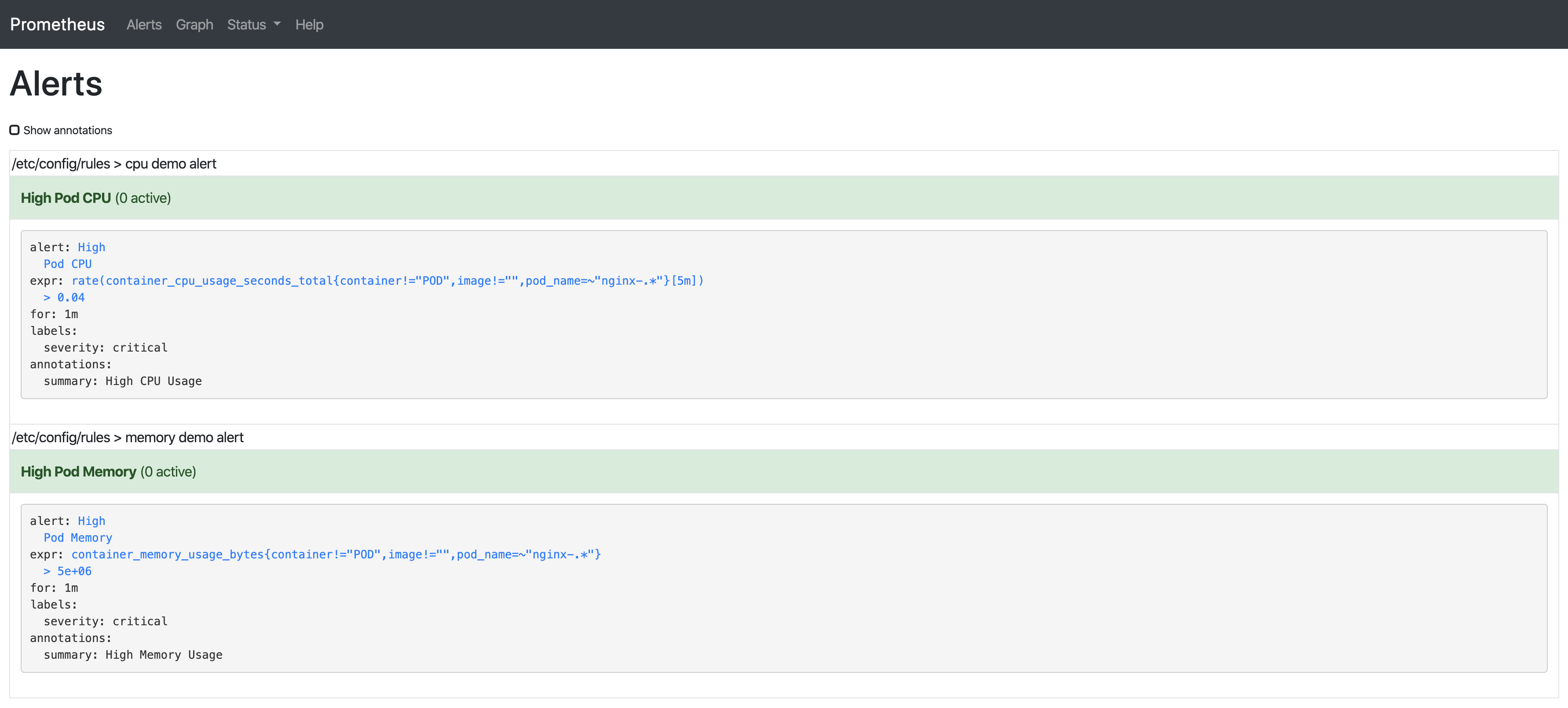
這是關於以上兩條規則的解釋:
-
container_memory_usage_bytes:當前記憶體使用情況(以位元組為單位),包括所有記憶體,無論任何時候訪問。 -
container_cpu_usage_seconds_total:累積的CPU時間(以秒為單位)
所有的指標都能夠在以下頁面中找到:
//github.com/google/cadvisor/blob/master/metrics/prometheus.go
在Prometheus中所有正則表達式都使用RE2 syntax。使用正則表達式,我們只能為名稱與特定模式匹配的Pod選擇時間序列。在我們的示例中,我們需要尋找以nginx-開頭的pod,並且排除「POD」,因為這是容器的父cgroup,而且會顯示pod內所有容器的統計資訊。
對於container_cpu_usage_seconds_total來說,我們使用所謂的子查詢(Subquery)。它會每5分鐘返回我們的指標。
如果你想了解更多關於查詢以及例子,可以在官方的Prometheus文檔中查看。
配置告警
只要出現問題,告警就能立即提醒我們,使得我們能夠立刻知道系統中發生了錯誤。而Prometheus通過Alertmanager組件來提供告警。
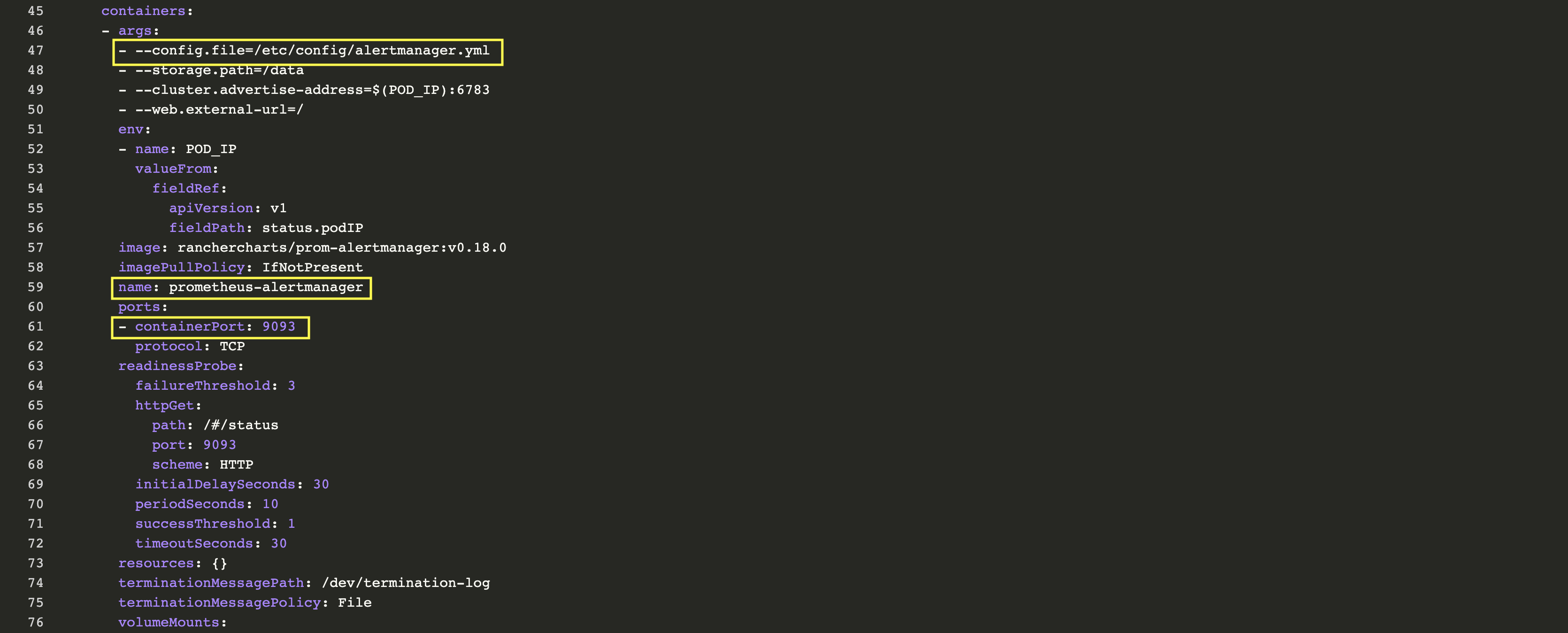
與Prometheus Server的操作步驟相同:在資源->工作負載標籤頁下,點擊prometheus-alertmanager右側菜單欄按鈕,選擇View/Edit YAML,檢查其配置:
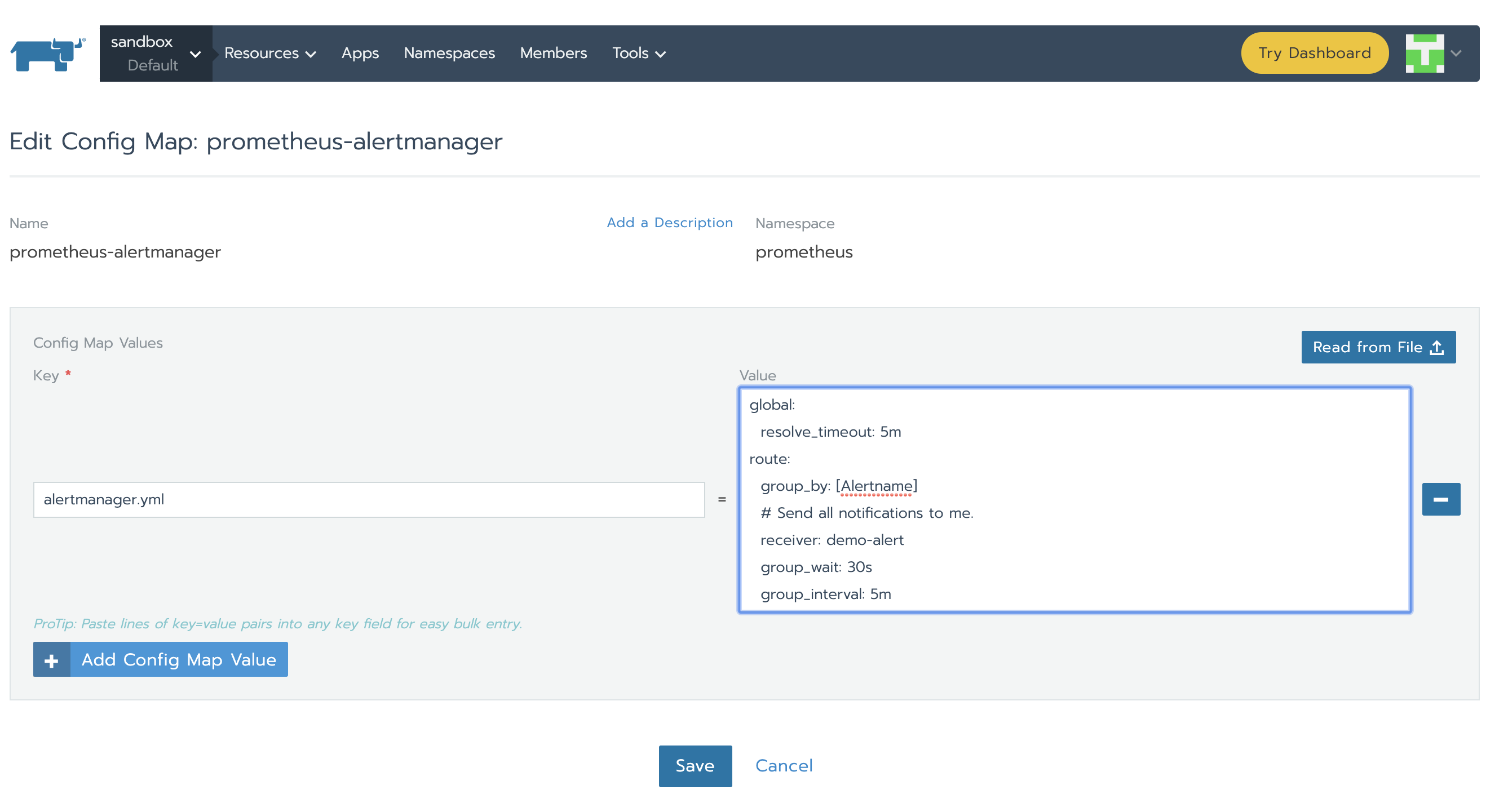
Alertmanager通過alertmanager.yml進行配置。該文件(及其他列在alertmanagerFiles內的文件)將掛載到alertmanager pod上。接下來我們需要修改與alertmanager相關聯的configMap以便於設置告警。在Config標籤頁下,點擊prometheus-alertmanager行的菜單欄,然後選擇Edit。使用以下程式碼代替基本配置:
global:
resolve_timeout: 5m
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: demo-alert
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- match:
alertname: DemoAlertName
receiver: "demo-alert"
receivers:
- name: demo-alert
email_configs:
- to: [email protected]
from: [email protected]
# Your smtp server address
smarthost: smtp.gmail.com:587
auth_username: [email protected]
auth_identity: [email protected]
auth_password: 16letter_generated token # you can use gmail account password, but better create a dedicated token for this
headers:
From: [email protected]
Subject: "Demo ALERT"
新配置將會由Alertmanager重新載入,並且我們能在Status標籤頁下看到GUI。
測試End-to-End方案
讓我們部署一些組件來進行監控。對於練習來說部署一個簡單的nginx deployment就足夠了。使用Rancher GUI,在資源->工作負載標籤頁下點擊導入YAML,粘貼以下程式碼(本次使用默認的命名空間)並點擊導入:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
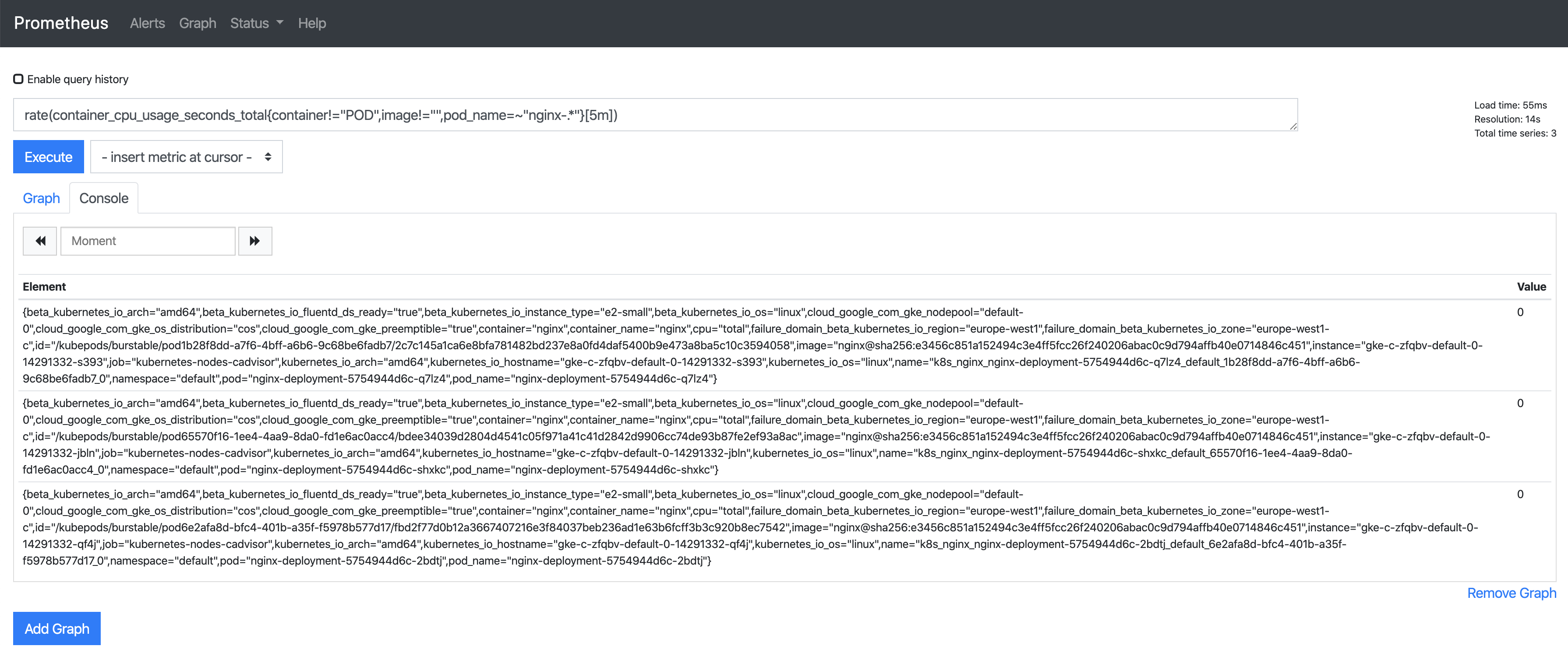
在Prometheus UI中,我們為使用此前為告警配置的兩個表達式中的1個來查看一些指標:
rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m])
讓我們在其中一個Pod中添加一些負載以查看值的變化。當值大於0.04時,我們應該獲得告警。為此,我們需要選擇其中一個nginx Deployment Pod並點擊Execute Shell。在其中我們將執行一個命令:

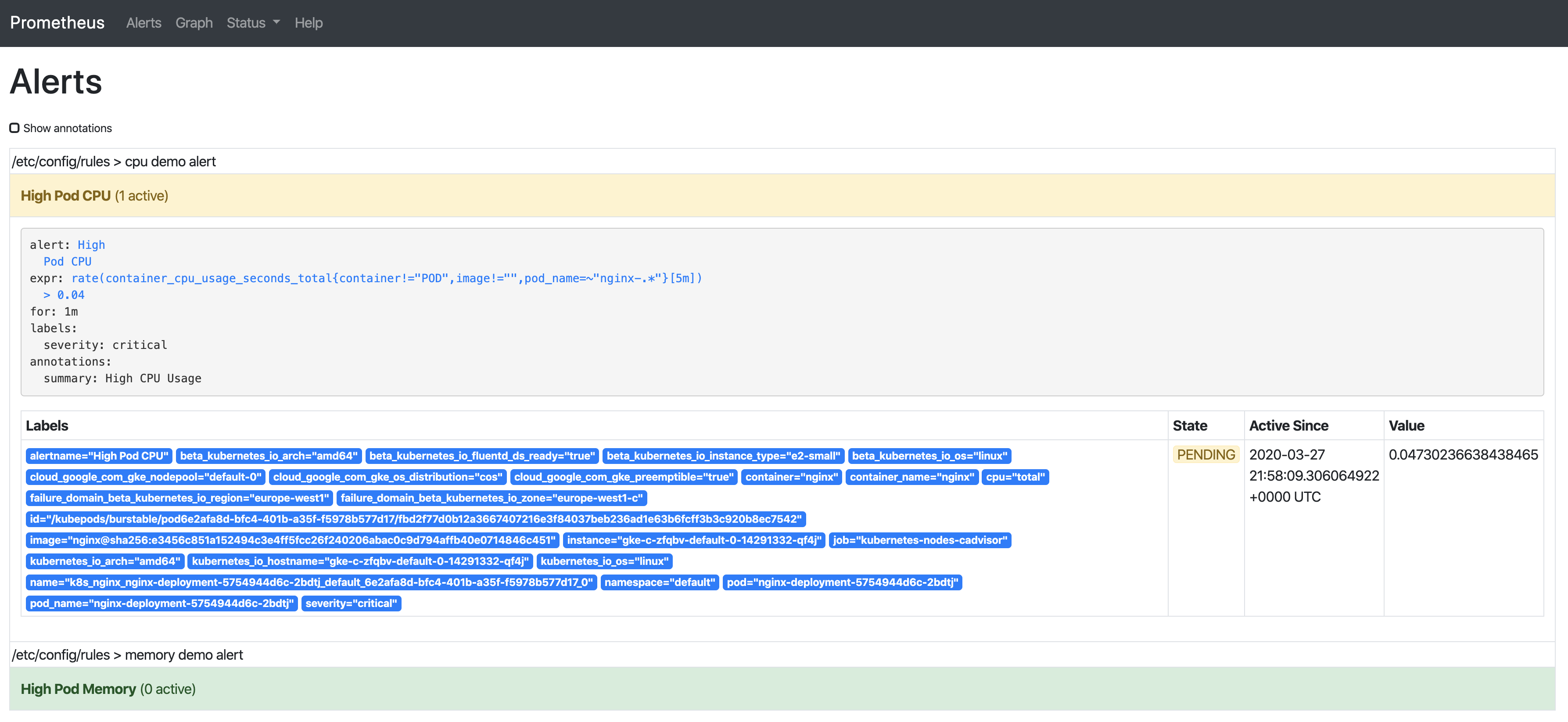
告警有3個階段:
-
Inactive-條件不滿足
-
Pending-滿足條件
-
Firing-告警被觸發
我們已經看到告警處於inactive狀態,所以繼續在CPU上增加負載讓我們能觀察到剩餘兩種狀態:
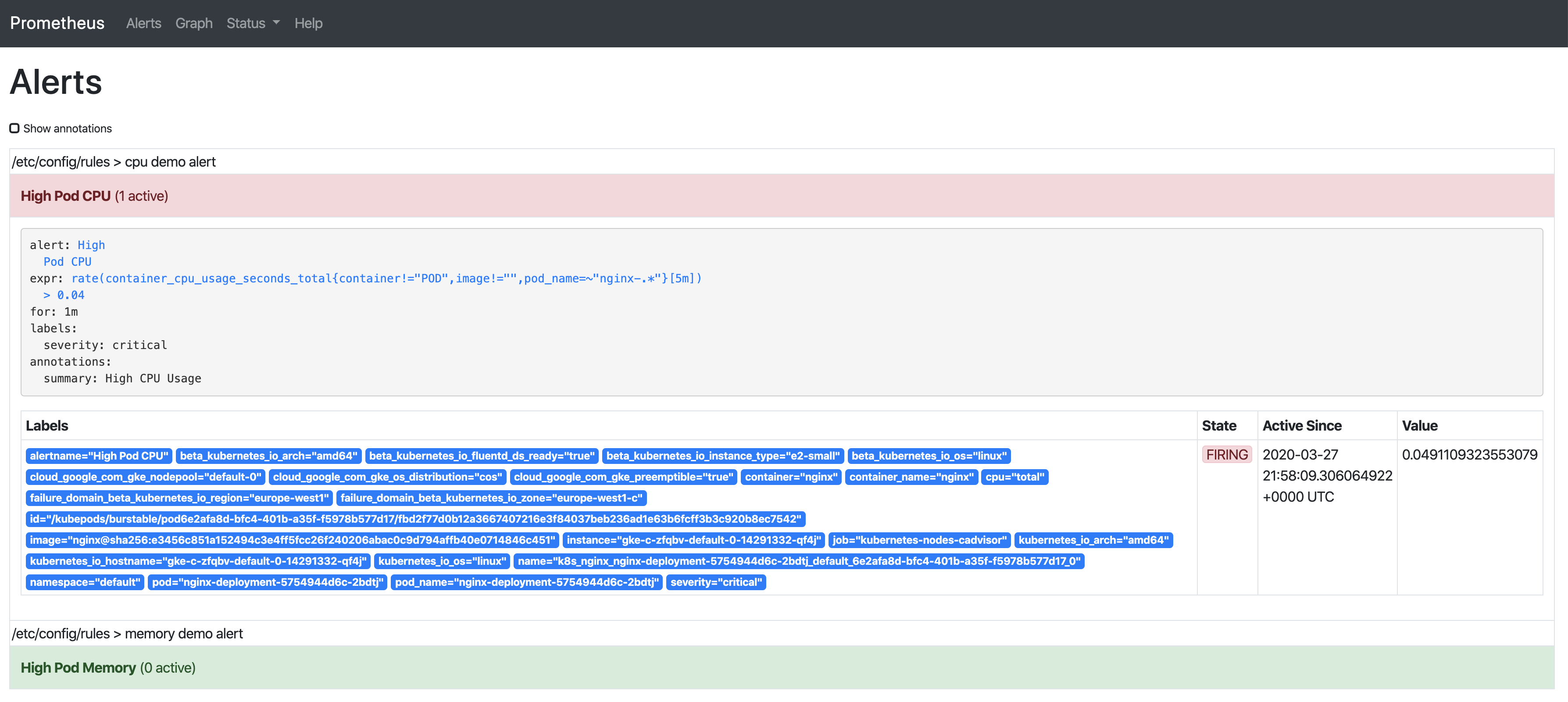
只要告警觸發,將會顯示在Alertmanager中:
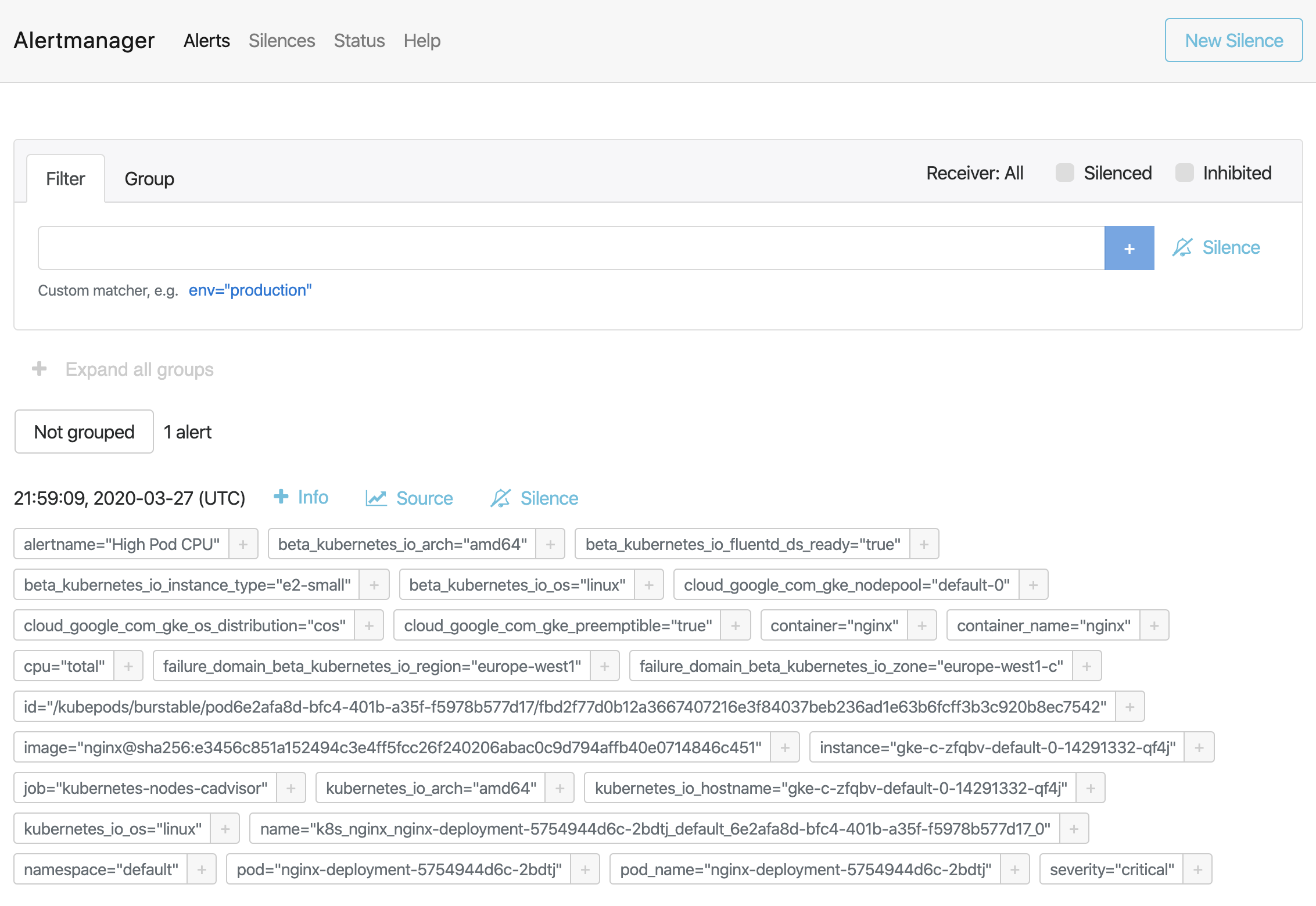
將Alertmanager配置為在我們收到告警時發送電子郵件。如果我們查看收件箱,則會看到類似的內容:

總 結
我們都知道監控在整個運維過程中多麼重要,但是如果沒有告警,監控是不完整的。告警可以在問題發生時,然後我們立刻知道系統中出現了問題。Prometheus囊括了這兩種功能:監控解決方案以及其Alertmanager組件的告警功能。本文中我們看到了使用Rancher部署Prometheus如此容易並且將Prometheus Server與Alertmanager集成。我們還使用Rancher配置了告警規則並推送了Alertmanager的配置,所以它能在問題發生時提醒我們。最後,我們了解了如何根據Alertmanager的定義/集成收到一封包含觸發告警詳細資訊的電子郵件(也可以通過Slack或PagerDuty發送)。


