Java面試系列第3篇-HashMap相關面試題
- 2020 年 4 月 27 日
- 筆記
HashMap是非執行緒安全的,如果想要用執行緒安全的map,可使用同步的HashTable或通過Collections.synchronizeMap(hashMap)讓HashMap變的同步,或者使用並發集合ConcurrentHashMap。下面來介紹一些常見的HashMap面試題目。
1、為何HashMap的數組長度一定是2的次冪?
我們知道,HashMap的存儲對於JDK1.7來說,是通過數組加鏈表的方式實現的。通過hash值獲取數組下標存儲索引,通過鏈表來解決衝突。下面看一下調用hash()方法獲取hash值的源程式碼實現,如下:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
在HashMap中得到hash值後會調用indexFor()計算數組中的索引位置,實現如下:
static int indexFor(int h, int length) {
return h & (length-1); // 保證獲取的索引是數組的合法索引
}
通過hashcode與length-1進行與運算,之前已經說過,數組長度length一定是2的冪次,所以減去1之後,結果用二進位表示時,其右邊的log2(length)個二進位位都為1,也就是說,hashcode的log2(length)個低二進位位決定最終的存儲索引位置,如果數組長度length不為2的冪次,那麼length-1的結果用二進位表示時,右邊的log2(length)個二進位位會含有0,導致hashcode的log2(length)個低二進位位中的部分數據不起作用,會增加索引位置衝突的機率。
2、為什麼Map桶中個數超過8才轉為紅黑樹
在 JDK 1.7 中,是用鏈表存儲的,這樣如果碰撞很多的話,就變成了在鏈表上的查找;在 JDK 1.8 進行了優化,當鏈表長度較大時(超過 8),會採用紅黑樹來存儲,這樣大大提高了查找效率。針對JDK 1.8版本的衝突解決,經常會被問到為什麼是超過8才用紅黑樹的問題。
當桶中個數達到8就轉成紅黑樹,當長度降到6就轉成普通鏈表存儲,而7就是為了防止鏈表和樹頻繁轉換。至於選擇8的原因,根據源程式碼的解析,是因為一個桶中存儲8個或以上的概率非常小,這樣小的事件都發生了,說明產生了嚴重的衝突,需要更高效的查找方式。
3、為什麼HashMap鏈表會形成死循環
JDK1.7 的 HashMap 鏈表會有死循環的可能,因為JDK1.7是採用的頭插法,在多執行緒環境下有可能會使鏈表形成環狀,從而導致死循環。JDK1.8做了改進,用的是尾插法,不會產生死循環。
因為如果兩個執行緒都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,存儲在鏈表中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap並不會將元素放在鏈表的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生,那麼就死造成死循環。簡書中//www.jianshu.com/p/1e9cf0ac07f4給了一個非常生動的例子,如下:
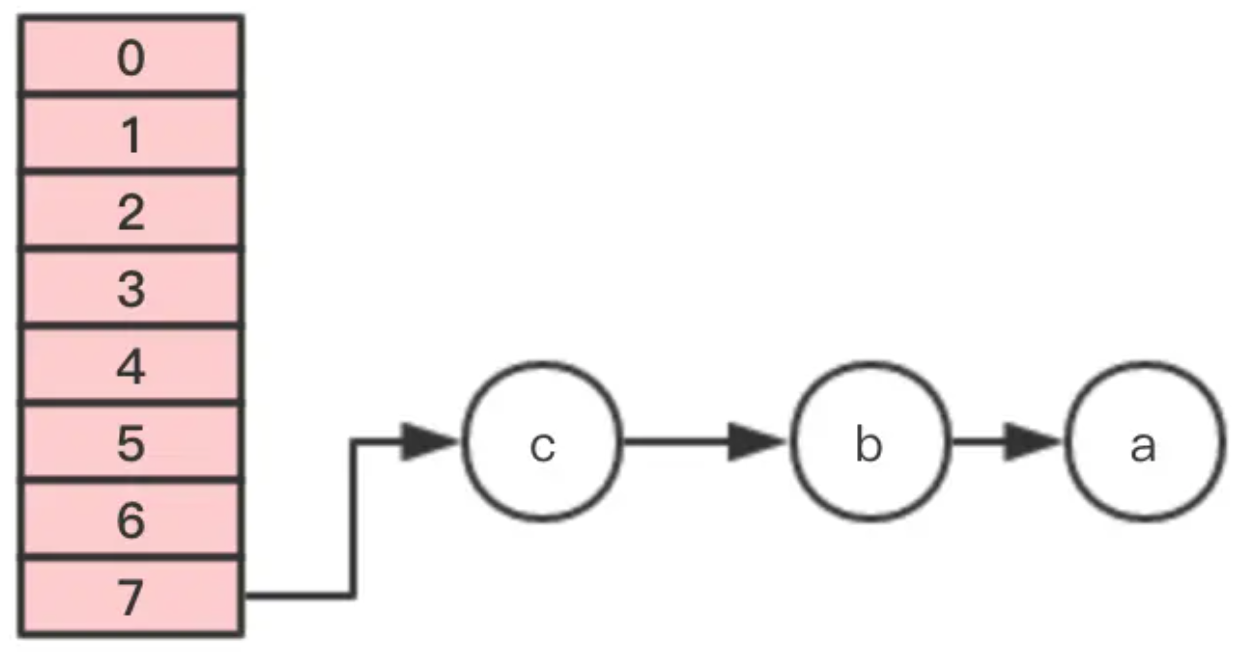
假設HashMap初始化大小為4,插入個3節點,不巧的是,這3個節點都hash到同一個位置,如果按照默認的負載因子的話,插入第3個節點就會擴容,為了驗證效果,假設負載因子是1。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
下面進行圖示說明。
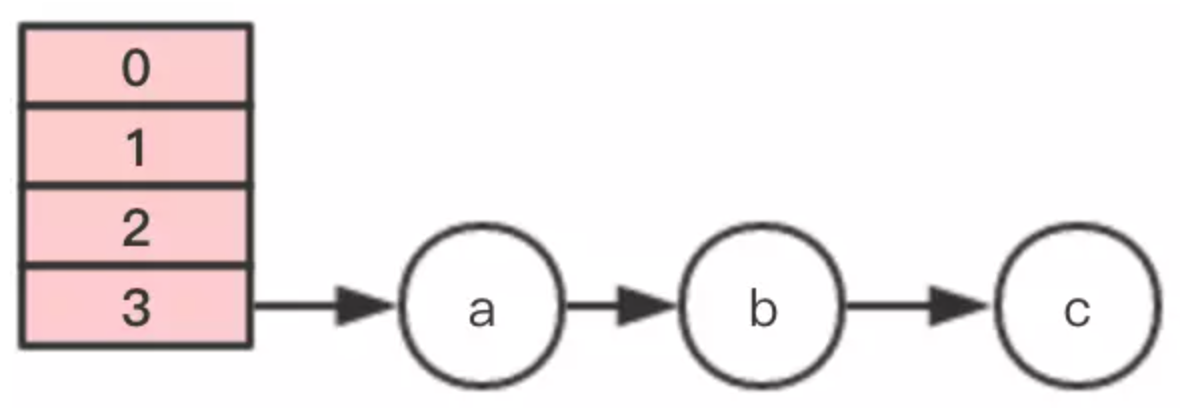
插入第4個節點時,發生rehash,假設現在有兩個執行緒同時進行,執行緒1和執行緒2,兩個執行緒都會新建新的數組。
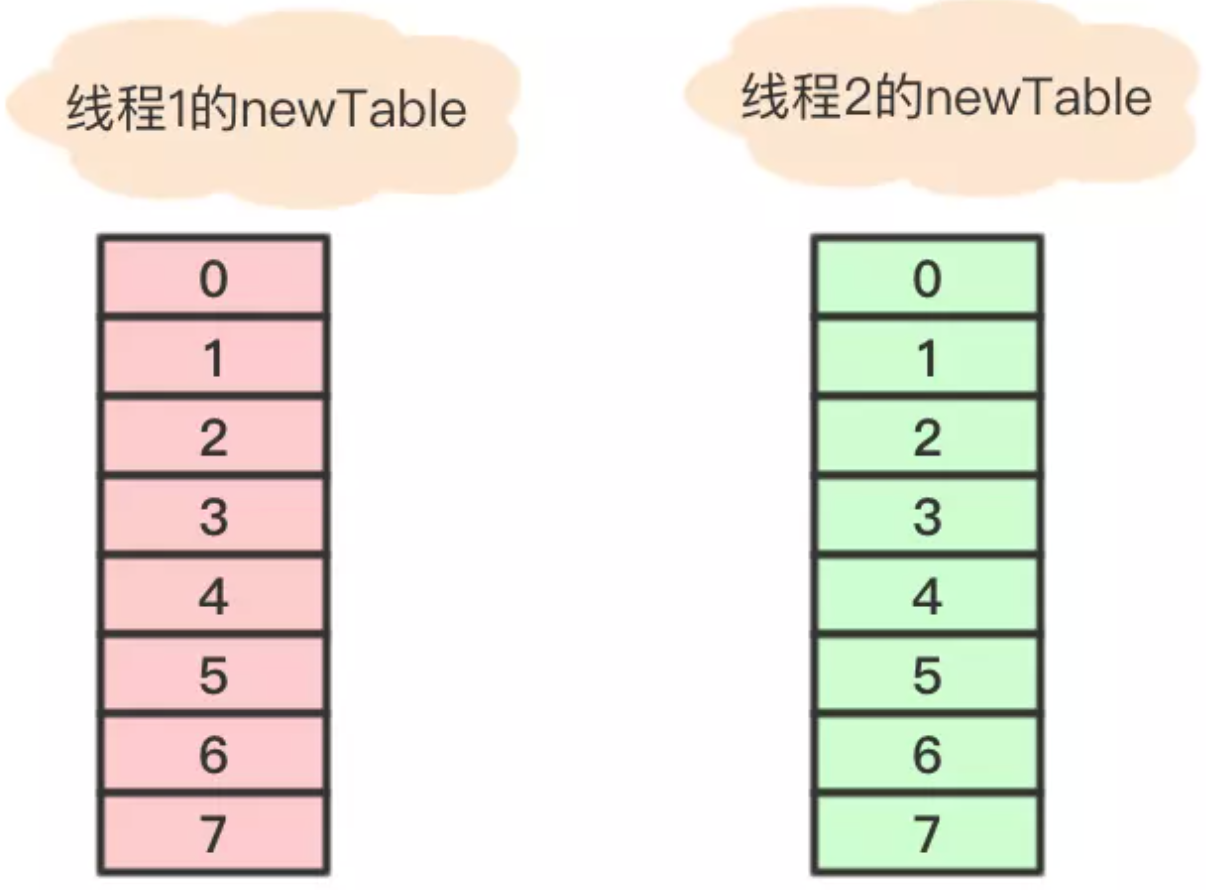
假設 執行緒2 在執行到Entry<K,V> next = e.next;之後,cpu時間片用完了,這時變數e指向節點a,變數next指向節點b。
執行緒1繼續執行,很不巧,a、b、c節點rehash之後又是在同一個位置7,開始移動節點
第一步,移動節點a
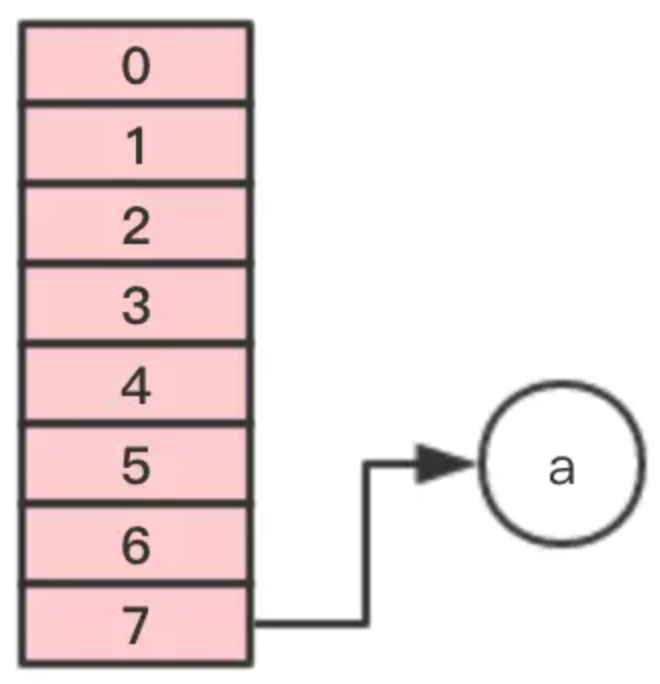
第二步,移動節點b
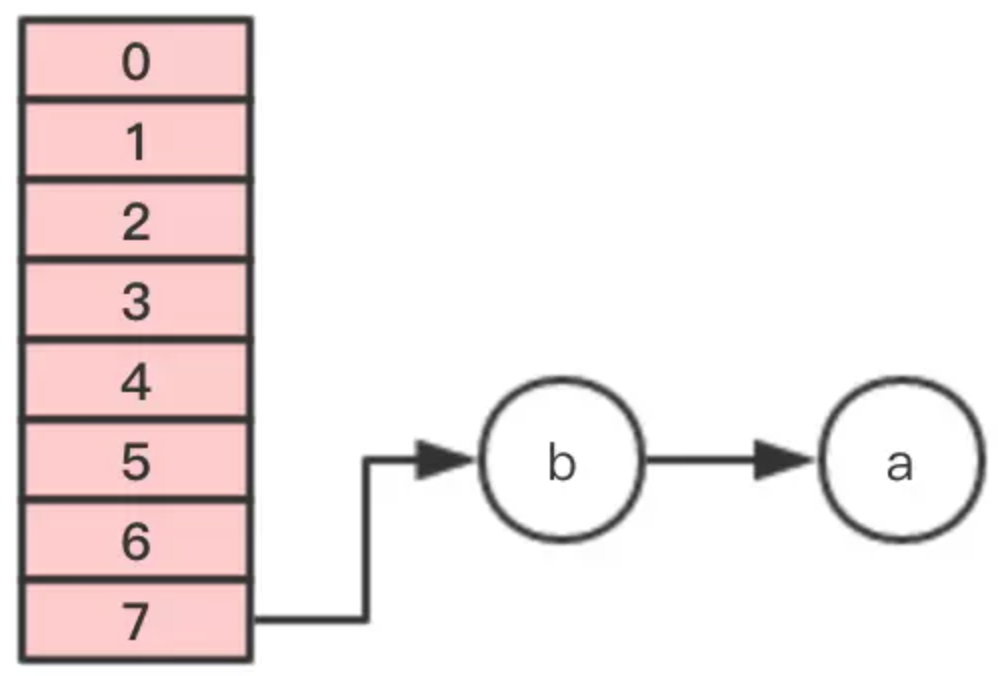
注意,這裡的順序是反過來的,繼續移動節點c
這個時候 執行緒1 的時間片用完,內部的table還沒有設置成新的newTable, 執行緒2 開始執行,這時內部的引用關係如下:
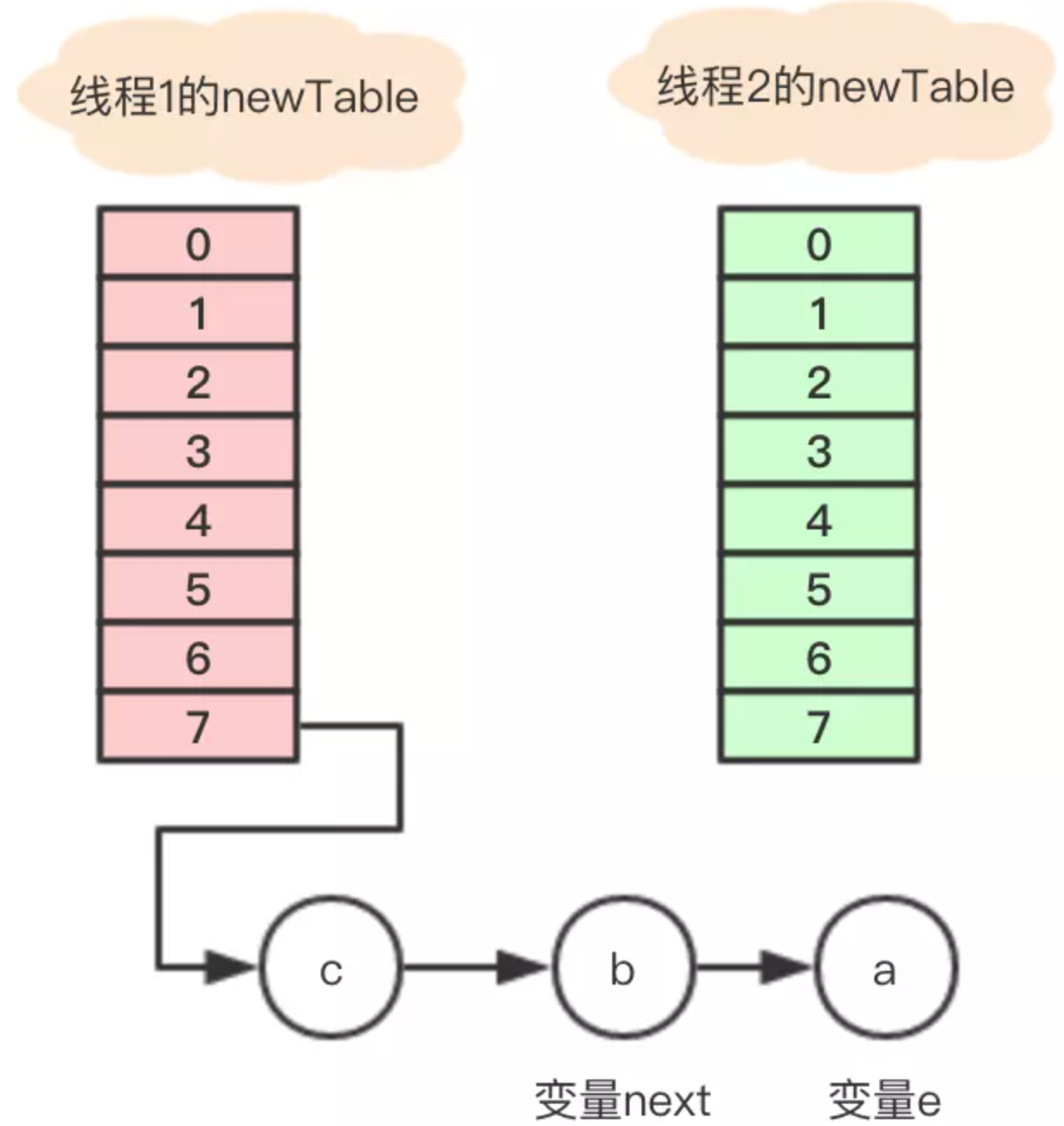
這時,在 執行緒2 中,變數e指向節點a,變數next指向節點b,開始執行循環體的剩餘邏輯。
Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next;
執行之後的引用關係如下圖。
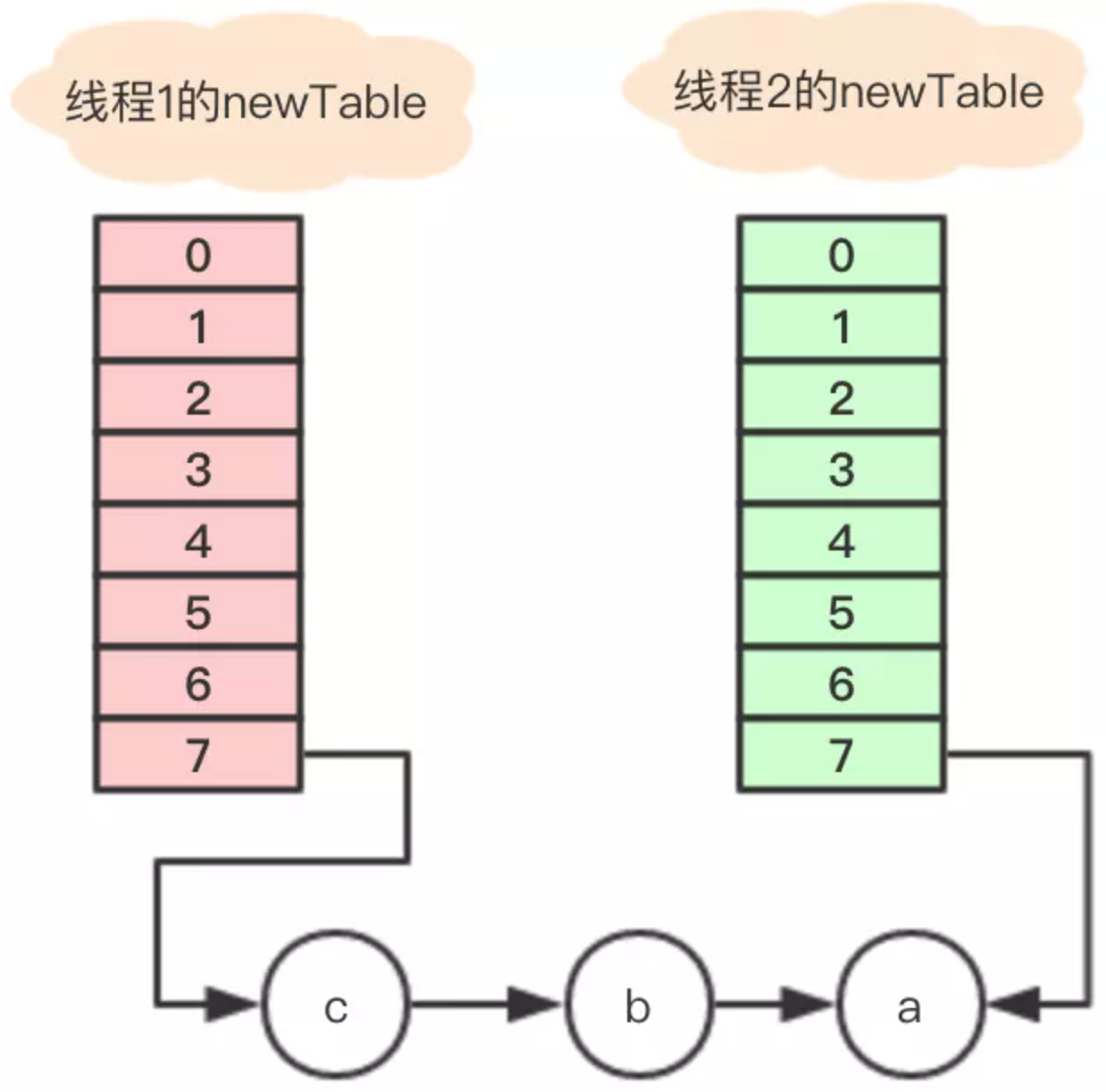
執行後,變數e指向節點b,因為e不是null,則繼續執行循環體,執行後的引用關係
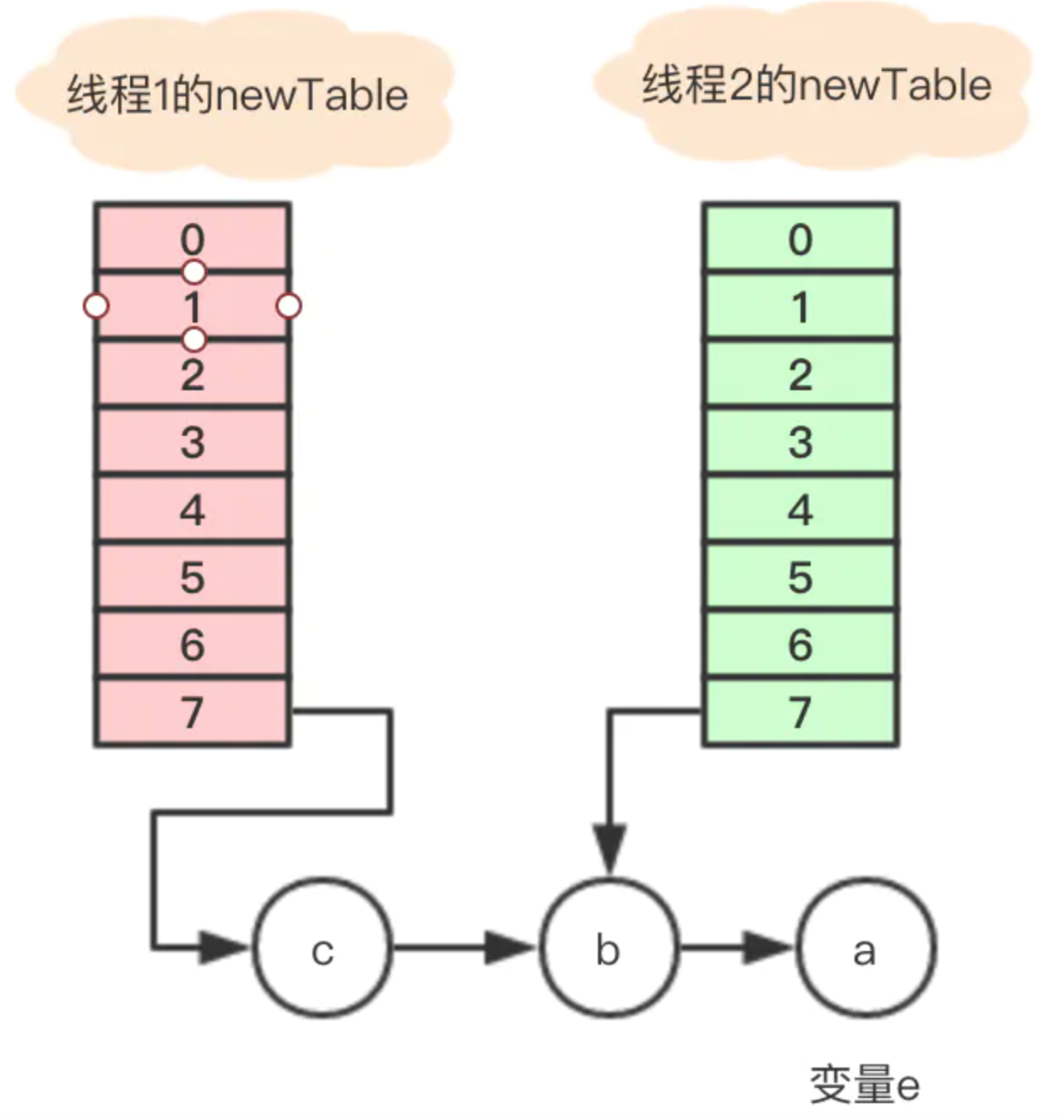
1、執行完Entry<K,V> next = e.next;,目前節點a沒有next,所以變數next指向null;
2、e.next = newTable[i]; 其中 newTable[i] 指向節點b,那就是把a的next指向了節點b,這樣a和b就相互引用了,形成了一個環;
3、newTable[i] = e 把節點a放到了數組i位置;
4、e = next; 把變數e賦值為null,因為第一步中變數next就是指向null;
所以最終的引用關係是這樣的:
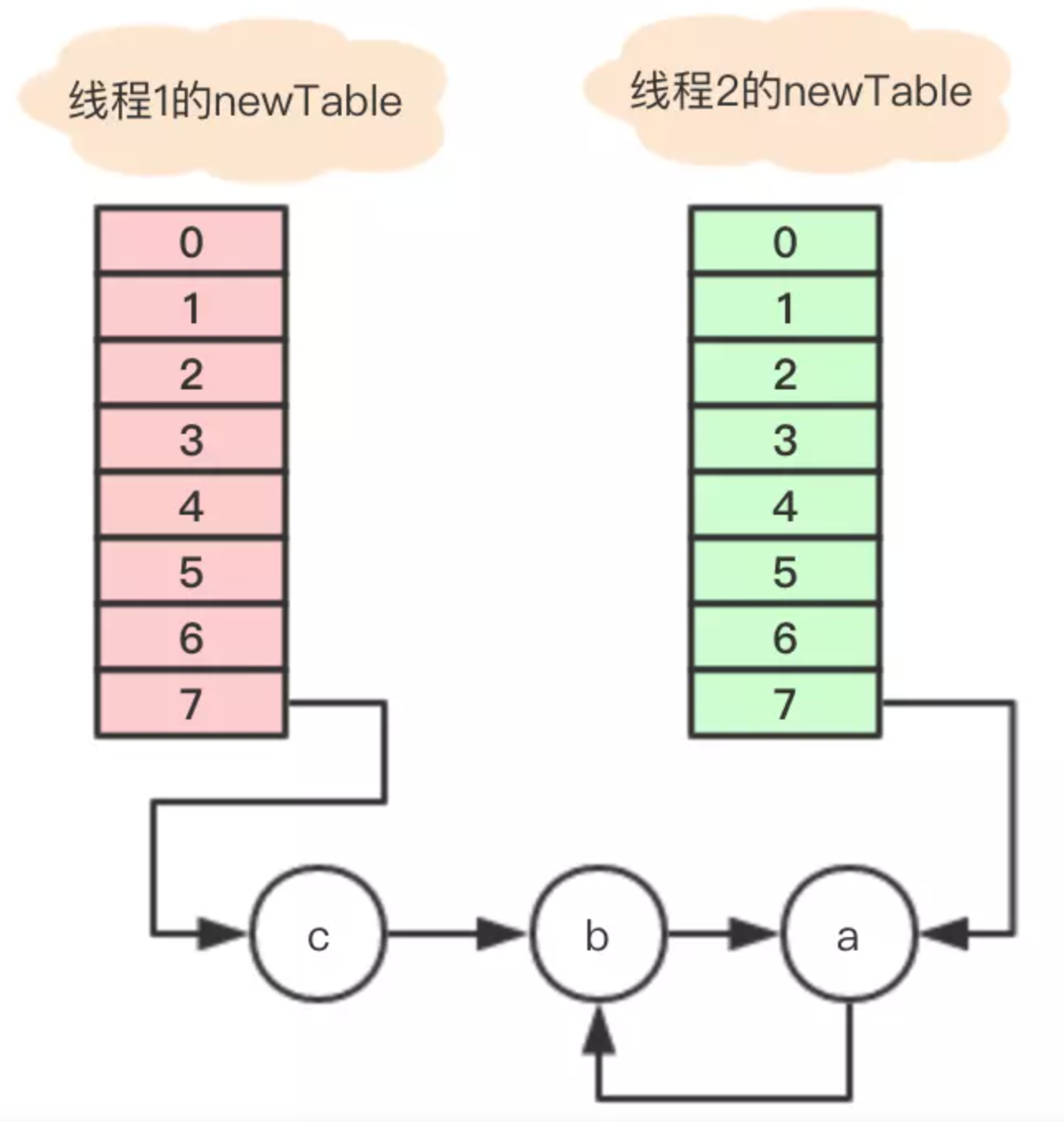
節點a和b互相引用,形成了一個環,當在數組該位置get尋找對應的key時,就發生了死循環。
另外,如果執行緒2把newTable設置成到內部的table,節點c的數據就丟了,看來還有數據遺失的問題。
4、為什麼重寫 equals() 方法,一定要重寫 hashCode() 呢?
一般情況下,任何兩個Object的hashCode在默認情況下都是不同的,如果有兩個Object相等,在不重寫 hashCode()方法的情況下,那麼很可能存儲到數組中不同的索引位置,而Java為了加快查找速度,通常對以散列表做為存儲結構的集合進行查找時,首先要通過hash來定位查詢的索引位置,如果存儲到其它索引位置,則沒有辦法查找。
5、rehashing的時機
通過負載因子來判斷,即用元素數量除以索引的數量,也就是平均每個索引處存儲多少個元素。Java 中默認值是 0.75f,如果超過了這個值就會 rehashing。

