2019前端面試系列——HTTP、瀏覽器面試題
- 2019 年 10 月 3 日
- 筆記
瀏覽器存儲的方式有哪些
| 特性 | cookie | localStorage | sessionStorage | indexedDB |
|---|---|---|---|---|
| 數據生命周期 | 一般由伺服器生成,可以設置過期時間 | 除非被清理,否則一直存在 | 頁面關閉就清理 | 除非被清理,否則一直存在 |
| 數據存儲大小 | 4K | 5M | 5M | 無限 |
| 與服務端通訊 | 每次都會攜帶在 header,中,對於請求性能影響 | 不參與 | 不參與 | 不參與 |
補充:cookie 原本並不是用來儲存的,而是用來與服務端通訊的,需要存取請自行封裝 api。
而 localStorage 則自帶 getItem 和 setItem 方法,使用很方便。
localStorage 注意點:
- localStorage 只能存字元串,存取 JSON 數據需配合 JSON.stringify() 和 JSON.parse()
- 遇上禁用 setItem 的瀏覽器,需要使用 try…catch 捕獲異常
對前後端跨域可以說一下嗎?如何解決跨域的?
九種跨域方式實現原理
如何跨域我們已經明白了,如果這樣問:瀏覽器沒有同源策略會有什麼危險?是不是有點瞬間懵逼?
下面是摘選的事例,參考:AJAX跨域訪問被禁止的原因
假設有一個黑客叫做小黑,他從網上抓取了一堆美女圖做了一個網站,每日訪問量爆表。
為了維護網站運行,小黑掛了一張收款碼,覺得網站不錯的可以適當資助一點,可是無奈伸手黨太多,小黑的網站入不敷出。
於是他非常生氣的在網頁中寫了一段js程式碼,使用ajax向淘寶發起登陸請求,因為很多數人都訪問過淘寶,所以電腦中存有淘寶的cookie,不需要輸入帳號密碼直接就自動登錄了,然後小黑在ajax回調函數中解析了淘寶返回的數據,得到了很多人的隱私資訊,轉手一賣,小黑的網站終於盈利了。
如果跨域也可以發送AJAX請求的話,小黑就真的獲取到了用戶的隱私並成功獲利了!!!
瀏覽器 cookie 和 session 的認識。
session 是基於 cookie 實現的。cookie 保存在客戶端瀏覽器中,而 session 保存在伺服器上。cookie 機制是通過檢查客戶身上的「通行證」來確定客戶身份的話,那麼 session 機制就是通過檢查伺服器上的「客戶明細表」來確認客戶身份。session 相當於程式在伺服器上建立的一份客戶檔案,客戶來訪的時候只需要查詢客戶檔案表就可以了。
cookie 和 session 的區別:
- 存在的位置:
cookie 存在於客戶端,臨時文件夾中;session 存在於伺服器的記憶體中,一個 session 域對象為一個用戶瀏覽器服務 - 安全性
cookie 是以明文的方式存放在客戶端的,安全性低,可以通過一個加密演算法進行加密後存放;session 存放於伺服器的記憶體中,所以安全性好 - 生命周期(以 20 分鐘為例)
cookie 的生命周期是累計的,從創建時,就開始計時,20 分鐘後 cookie 生命周期結束;
session 的生命周期是間隔的,從創建時,開始計時如在 20 分鐘,沒有訪問 session,那麼 session 生命周期被銷毀。但是,如果在 20 分鐘內(如在第 19 分鐘時)訪問過 session,那麼,將重新計算 session 的生命周期。關機會造成 session 生命周期的結束,但是對 cookie 沒有影響 - 訪問範圍
cookie 為多個用戶瀏覽器共享;session 為一個用戶瀏覽器獨享
好文推薦:徹底理解 cookie、session、token
輸入URL發生什麼?
- DNS 域名解析(域名解析成ip地址,走UTP協議,因此不會有握手過程):瀏覽器將 URL 解析出相對應的伺服器的 IP 地址(1. 本地瀏覽器的 DNS 快取中查找 2. 再向系統DNS快取發送查詢請求 3. 再向路由器DNS快取 4. 網路運營商DNS快取 5. 遞歸搜索),並從 url 中解析出埠號
- 瀏覽器與目標伺服器建立一條 TCP 連接(三次握手)
- 瀏覽器向伺服器發送一條 HTTP 請求報文
- 伺服器返回給瀏覽器一條 HTTP 響應報文
- 瀏覽器進行渲染
- 關閉 TCP 連接(四次揮手)
瀏覽器渲染的步驟
- HTML 解析出 DOM Tree
- CSS 解析出 Style Rules
- 兩者關聯生成 Render Tree
- Layout(布局)根據 Render Tree 計算每個節點的資訊
- Painting 根據計算好的資訊進行渲染整個頁面
瀏覽器解析文檔的過程中,如果遇到 script 標籤,會立即解析腳本,停止解析文檔(因為 JS 可能會改變 DOM 和 CSS,如果繼續解析會造成浪費)。
如果是外部 script, 會等待腳本下載完成之後在繼續解析文檔。現在 script 標籤增加了 defer 和 async 屬性,腳本解析會將腳本中改變 DOM 和 css 的地方> 解析出來,追加到 DOM Tree 和 Style Rules 上
頁面渲染優化
基於對渲染過程的了解,推薦一下優化:
- HTML 文檔結構層次盡量少,最好不深於 6 層
- 腳本盡量放後邊,避免組織頁面載入
- 少量首屏樣式可以放在便簽內
- 樣式結構層次盡量簡單
- 腳本減少 DOM 操作,減少迴流,盡量快取訪問 DOM 的樣式資訊
- 盡量減少 JS 修改樣式,可以通過修改 class 名的方式解決
- 減少 DOM 查找,快取 DOM 查找結果
- 動畫在螢幕外或頁面滾動時,盡量停止
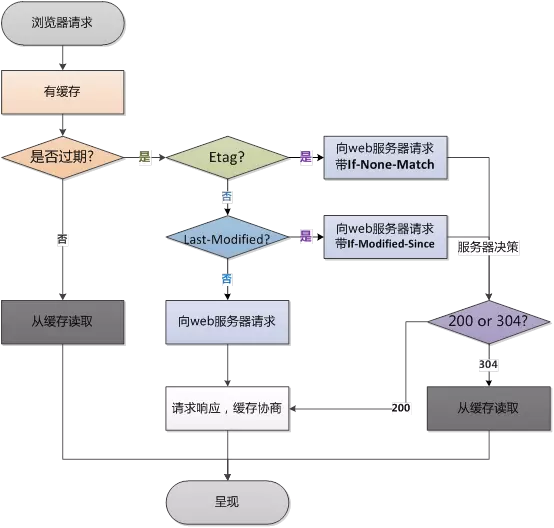
強制快取和協商快取
-
強制快取是我們在第一次請求資源時在 http 響應頭設置一個過期時間,在時效內都將直接從瀏覽器進行獲取,常見的 http 響應頭欄位如 Cache-Control 和 Expires
-
協商快取是我們通過 http 響應頭欄位 etag 或者 Last-Modified 等判斷伺服器上資源是否修改,如果修改則從伺服器重新獲取,如果未修改則 304 指向瀏覽器快取中進行獲取
GET 和 POST 請求的區別
- GET 參數通過 url 傳遞,POST 放在 body 中。(http 協議規定,url 在請求頭中,所以大小限制很小)
- GET 請求在 url 中傳遞的參數是有長度限制的,而 POST 沒有。原因見上↑↑↑
- GET 在瀏覽器回退時是無害的,而 POST 會再次提交請求
- GET 請求會被瀏覽器主動 cache,而 POST 不會,除非手動設置
- GET 比 POST 更不安全,因為參數直接暴露在 url 中,所以不能用來傳遞敏感資訊
- 對參數的數據類型,GET 只接受 ASCII字元,而 POST 沒有限制
- GET 請求只能進行 url(x-www-form-urlencoded)編碼,而 POST 支援多種編碼方式
- GET 產生一個 TCP 數據包;POST 產生兩個 TCP 數據包。對於 GET 方式的請求,瀏覽器會把 http 的 header 和 data 一併發送出去,伺服器響應200(返回數據)。而對於 POST,瀏覽器先發送 header,伺服器響應100 continue,瀏覽器再發送 data,伺服器響應200 ok(返回數據)
HTTP1.0 / 1.1 / 2.0 及HTTPS
你需要知道的HTTP常識
可能是全網最全的http面試答案
如何優雅的談論HTTP/1.0/1.1/2.0
HTTP1.1 是當前使用最為廣泛的HTTP協議
- HTTP1.0 和 HTTP1.1 相比
- HTTP1.0 定義了三種請求方法: GET, POST 和 HEAD 方法。HTTP1.1 新增了六種請求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
- 快取處理:在HTTP1.0中主要使用header里的If-Modified-Since,Expires來做為快取判斷的標準,HTTP1.1則引入了更多的快取控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供選擇的快取頭來控制快取策略。
- 頻寬優化及網路連接的使用:HTTP1.0中,存在一些浪費頻寬的現象,例如客戶端只是需要某個對象的一部分,而伺服器卻將整個對象送過來了,並且不支援斷點續傳功能,HTTP1.1則在請求頭引入了range頭域,它允許只請求資源的某個部分,即返回碼是206(Partial Content),這樣就方便了開發者自由的選擇以便於充分利用頻寬和連接。
- 錯誤通知的管理:在HTTP1.1中新增了24個錯誤狀態響應碼,如409(Conflict)表示請求的資源與資源的當前狀態發生衝突;410(Gone)表示伺服器上的某個資源被永久性的刪除。
- Host頭處理:在HTTP1.0中認為每台伺服器都綁定一個唯一的IP地址,因此,請求消息中的URL並沒有傳遞主機名(hostname)。但隨著虛擬主機技術的發展,在一台物理伺服器上可以存在多個虛擬主機(Multi-homed Web Servers),並且它們共享一個IP地址。HTTP1.1的請求消息和響應消息都應支援Host頭域,且請求消息中如果沒有Host頭域會報告一個錯誤(400 Bad Request)。
- 長連接:HTTP 1.1支援長連接(PersistentConnection)和請求的流水線(Pipelining)處理,在一個TCP連接上可以傳送多個HTTP請求和響應,減少了建立和關閉連接的消耗和延遲,在HTTP1.1中默認開啟Connection: keep-alive,一定程度上彌補了HTTP1.0每次請求都要創建連接的缺點。通過設置http的請求頭部和應答頭部,保證本次數據請求結束之後,下一次請求仍可以重用這一通道,避免重新握手。
- HTTP2.0 和 HTTP1.X 相比
- 新的二進位格式(Binary Format):HTTP1.x的解析是基於文本。基於文本協議的格式解析存在天然缺陷,文本的表現形式有多樣性,要做到健壯性考慮的場景必然很多,二進位則不同,只認0和1的組合。基於這種考慮HTTP2.0的協議解析決定採用二進位格式,實現方便且健壯。
- 多路復用(MultiPlexing):即連接共享,即每一個request都是是用作連接共享機制的。一個request對應一個id,這樣一個連接上可以有多個request,每個連接的request可以隨機的混雜在一起,接收方可以根據request的 id將request再歸屬到各自不同的服務端請求裡面。
- header壓縮:如上文中所言,對前面提到過HTTP1.x的header帶有大量資訊,而且每次都要重複發送,HTTP2.0使用了專門為首部壓縮而設計的 HPACK 演算法,使用encoder來減少需要傳輸的header大小,通訊雙方各自cache一份header fields表,既避免了重複header的傳輸,又減小了需要傳輸的大小。
- 服務端推送(server push):服務端推送能把客戶端所需要的資源伴隨著index.html一起發送到客戶端,省去了客戶端重複請求的步驟。正因為沒有發起請求,建立連接等操作,所以靜態資源通過服務端推送的方式可以極大地提升速度。例如我的網頁有一個sytle.css的請求,在客戶端收到sytle.css數據的同時,服務端會將sytle.js的文件推送給客戶端,當客戶端再次嘗試獲取sytle.js時就可以直接從快取中獲取到,不用再發請求了。
- HTTPS 與 HTTP 相比
- HTTPS協議需要到CA申請證書,一般免費證書很少,需要交費。
- HTTP協議運行在TCP之上,所有傳輸的內容都是明文,HTTPS運行在SSL/TLS之上,SSL/TLS運行在TCP之上,所有傳輸的內容都經過加密的。
- HTTP和HTTPS使用的是完全不同的連接方式,用的埠也不一樣,前者是80,後者是443。
- HTTPS可以有效的防止運營商劫持,解決了防劫持的一個大問題。
HTTPS 介紹:HTTPS在傳輸數據之前需要客戶端(瀏覽器)與服務端(網站)之間進行一次握手,在握手過程中將確立雙方加密傳輸數據的密碼資訊。TLS/SSL協議不僅僅是一套加密傳輸的協議,TLS/SSL中使用了非對稱加密,對稱加密以及HASH演算法。
握手過程的簡單描述如下:
1.瀏覽器將自己支援的一套加密規則發送給網站。
2.網站從中選出一組加密演算法與HASH演算法,並將自己的身份資訊以證書的形式發回給瀏覽器。證書裡面包含了網站地址,加密公鑰,以及證書的頒發機構等資訊。
3.獲得網站證書之後瀏覽器要做以下工作:
a. 驗證證書的合法性(頒發證書的機構是否合法,證書中包含的網站地址是否與正在訪問的地址一致等),如果證書受信任,則瀏覽器欄裡面會顯示一個小鎖頭,否則會給出證書不受信的提示。
b. 如果證書受信任,或者是用戶接受了不受信的證書,瀏覽器會生成一串隨機數的密碼,並用證書中提供的公鑰加密。
c. 使用約定好的HASH計算握手消息,並使用生成的隨機數對消息進行加密,最後將之前生成的所有資訊發送給網站。
4.網站接收瀏覽器發來的數據之後要做以下的操作:
a. 使用自己的私鑰將資訊解密取出密碼,使用密碼解密瀏覽器發來的握手消息,並驗證HASH是否與瀏覽器發來的一致。
b. 使用密碼加密一段握手消息,發送給瀏覽器。
5.瀏覽器解密並計算握手消息的HASH,如果與服務端發來的HASH一致,此時握手過程結束,之後所有的通訊數據將由之前瀏覽器生成的隨機密碼並利用對稱加密演算法進行加密。
這裡瀏覽器與網站互相發送加密的握手消息並驗證,目的是為了保證雙方都獲得了一致的密碼,並且可以正常的加密解密數據。其中非對稱加密演算法用於在握手過程中加密生成的密碼,對稱加密演算法用於對真正傳輸的數據進行加密,而HASH演算法用於驗證數據的完整性。由於瀏覽器生成的密碼是整個數據加密的關鍵,因此在傳輸的時候使用了非對稱加密演算法對其加密。非對稱加密演算法會生成公鑰和私鑰,公鑰只能用於加密數據,因此可以隨意傳輸,而網站的私鑰用於對數據進行解密,所以網站都會非常小心的保管自己的私鑰,防止泄漏。TLS握手過程中如果有任何錯誤,都會使加密連接斷開,從而阻止了隱私資訊的傳輸。正是由於HTTPS非常的安全,攻擊者無法從中找到下手的地方,於是更多的是採用了假證書的手法來欺騙客戶端,從而獲取明文的資訊。

介紹下304過程
a. 瀏覽器請求資源時首先命中資源的Expires 和 Cache-Control,Expires 受限於本地時間,如果修改了本地時間,可能會造成快取失效,可以通過Cache-control: max-age指定最大生命周期,狀態仍然返回200,但不會請求數據,在瀏覽器中能明顯看到from cache字樣。
b. 強快取失效,進入協商快取階段,首先驗證ETagETag可以保證每一個資源是唯一的,資源變化都會導致ETag變化。伺服器根據客戶端上送的If-None-Match值來判斷是否命中快取。
c. 協商快取Last-Modify/If-Modify-Since階段,客戶端第一次請求資源時,服務服返回的header中會加上Last-Modify,Last-modify是一個時間標識該資源的最後修改時間。再次請求該資源時,request的請求頭中會包含If-Modify-Since,該值為快取之前返回的Last-Modify。伺服器收到If-Modify-Since後,根據資源的最後修改時間判斷是否命中快取。
HTTP 狀態碼
- 1xx(臨時響應)表示臨時響應並需要請求者繼續執行操作的狀態碼
- 100 – 繼續 請求者應當繼續提出請求。伺服器返回此程式碼表示已收到請求的第一部分,正在等待其餘部分
- 101 – 切換協議 請求者已要求伺服器切換協議,伺服器已確認並準備切換
- 2xx(成功)表示成功處理了請求的狀態碼
- 200 – 成功 伺服器已經成功處理了請求。通常,這表示伺服器提供了請求的網頁
- 201 – 已創建 請求成功並且伺服器創建了新的資源
- 202 – 已接受 伺服器已接受請求,但尚未處理
- 203 – 非授權資訊 伺服器已經成功處理了請求,但返回的資訊可能來自另一來源
- 204 – 無內容 伺服器成功處理了請求,但沒有返回任何內容
- 205 – 重置內容 伺服器成功處理了請求,但沒有返回任何內容
- 206 – 部分內容 伺服器成功處理了部分GET請求
- 3xx(重定向)表示要完成請求,需要進一步操作;通常,這些狀態程式碼用來重定向
- 300 – 多種選擇 針對請求,伺服器可執行多種操作。伺服器可根據請求者(user agent)選擇一項操作,或提供操作列表供請求者選擇
- 301 – 永久移動 請求的網頁已永久移動到新位置。伺服器返回此響應(對GET或HEAD請求的響應)時,會自動將請求者轉到新位置
- 302 – 臨時移動 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以後的請求
- 303 – 查看其它位置 請求者應當對不同的位置使用單獨的GET請求來檢索響應時,伺服器返回此程式碼
- 304 – 未修改 自上次請求後,請求的網頁未修改過。伺服器返回此響應,不會返回網頁的內容
- 305 – 使用代理 請求者只能使用代理訪問請求的網頁。如果伺服器返回此響應,還表示請求者應使用代理
- 307 – 臨時性重定向 伺服器目前從不同位置的網頁響應請求,但請求者應繼續使用原有的位置來進行以後的請求
- 4xx(請求錯誤)這些狀態碼錶示請求可能出錯,妨礙了伺服器的處理
- 400 – 錯誤請求 伺服器不理解請求的語法
- 401 – 未授權 請求要求身份驗證。對於需要登錄的網頁,伺服器可能返回此響應
- 403 – 禁止 伺服器拒絕請求
- 404 – 未找到 伺服器找不到請求的網頁
- 405 – 方法禁用 禁用請求中指定的方法
- 406 – 不接受 無法使用請求的內容特性響應請求的網頁
- 407 – 需要代理授權 此狀態碼與401(未授權)類似,但指定請求者應當授權使用代理
- 408 – 請求超時 伺服器等候請求時發生超時
- 409 – 衝突 伺服器在完成請求時發生衝突。伺服器必須在響應中包含有關衝突的資訊
- 410 – 已刪除 如果請求的資源已永久刪除,伺服器就會返回此響應
- 411 – 需要有效長度 伺服器不接受不含有效內容長度標頭欄位的請求
- 412 – 未滿足前提條件 伺服器未滿足請求者在請求者設置的其中一個前提條件
- 413 – 請求實體過大 伺服器無法處理請求,因為請求實體過大,超出了伺服器的處理能力
- 414 – 請求的URI過長 請求的URI(通常為網址)過長,伺服器無法處理
- 415 – 不支援媒體類型 請求的格式不受請求頁面的支援
- 416 – 請求範圍不符合要求 如果頁面無法提供請求的範圍,則伺服器會返回此狀態碼
- 417 – 未滿足期望值 伺服器未滿足「期望」請求標頭欄位的要求
- 5xx(伺服器錯誤)這些狀態碼錶示伺服器在嘗試處理請求時發生內部錯誤。這些錯誤可能是伺服器本身的錯誤,而不是請求出錯
- 500 – 伺服器內部錯誤 伺服器遇到錯誤,無法完成請求
- 501 – 尚未實施 伺服器不具備完成請求的功能。例如,伺服器無法識別請求方法時可能會返回此程式碼
- 502 – 錯誤網關 伺服器作為網關或代理,從上游伺服器無法收到無效響應
- 503 – 伺服器不可用 伺服器目前無法使用(由於超載或者停機維護)。通常,這只是暫時狀態
- 504 – 網關超時 伺服器作為網關代理,但是沒有及時從上游伺服器收到請求
- 505 – HTTP版本不受支援 伺服器不支援請求中所用的HTTP協議版本
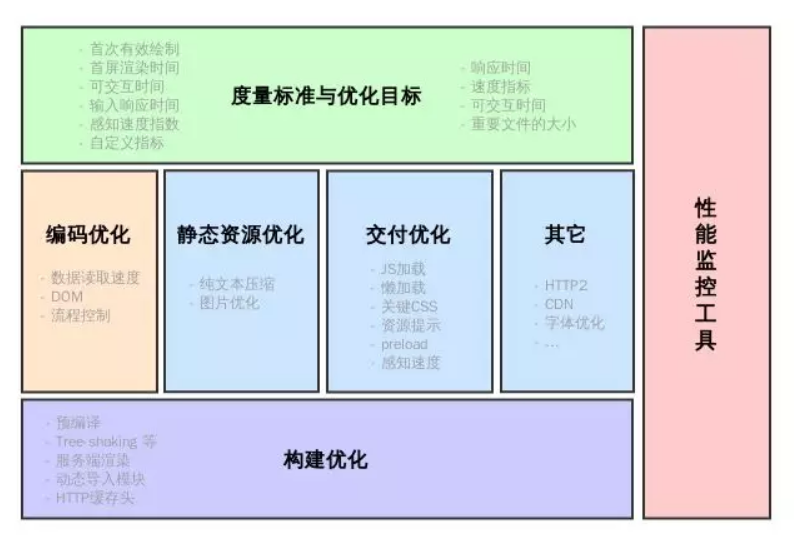
Web性能優化
2019前端面試系列——CSS面試題
2019前端面試系列——JS面試題
2019前端面試系列——JS高頻手寫程式碼題
2019前端面試系列——Vue面試題
2019前端面試系列——HTTP、瀏覽器面試題
