Spark面试题(五)——数据倾斜调优
- 2021 年 11 月 15 日
- 笔记
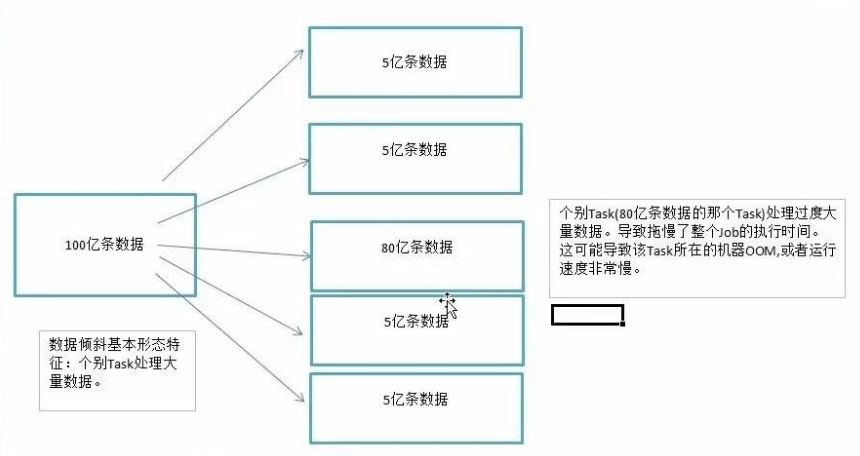
1、数据倾斜 数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著 …
Continue Reading1、数据倾斜 数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著 …
Continue Readingspark-sql 写代码方式 1、idea里面将代码编写好打包上传到集群中运行,上线使用 spark-submit提交 …
Continue Reading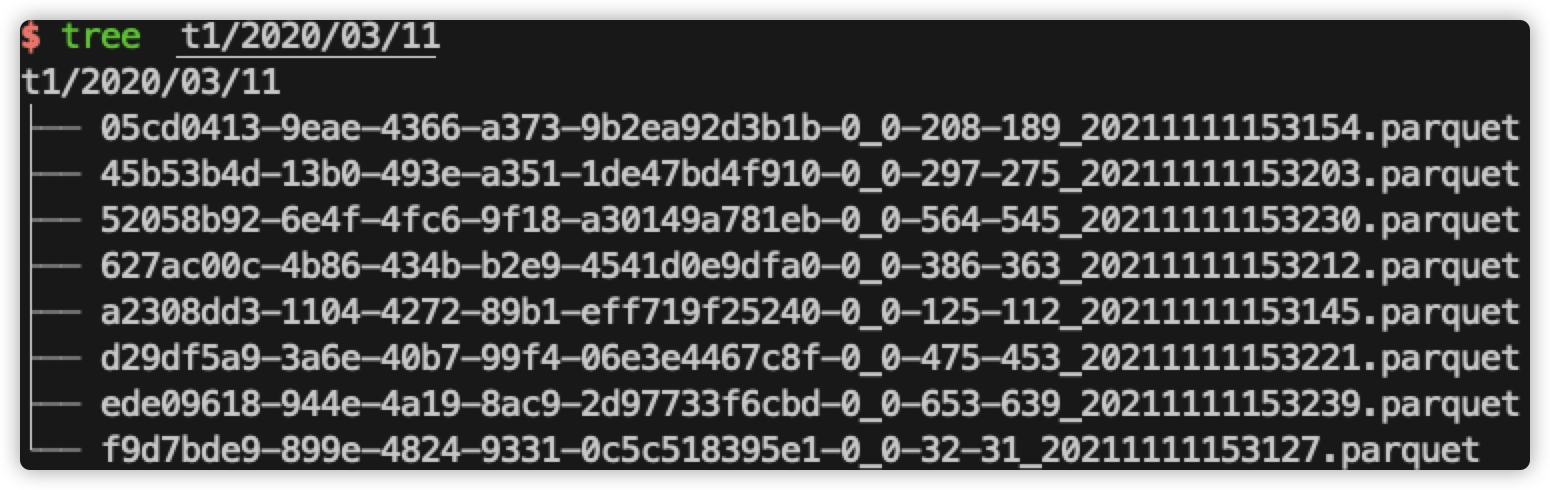
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28) …
Continue Reading
Spark比MR快的原因 1、Spark基于内存的计算 2、粗粒度资源调度 3、DAG有向无环图:可以根据宽窄依赖划分出 …
Continue Reading
小文件合并解析 执行代码: import org.apache.hudi.QuickstartUtils._ impor …
Continue Reading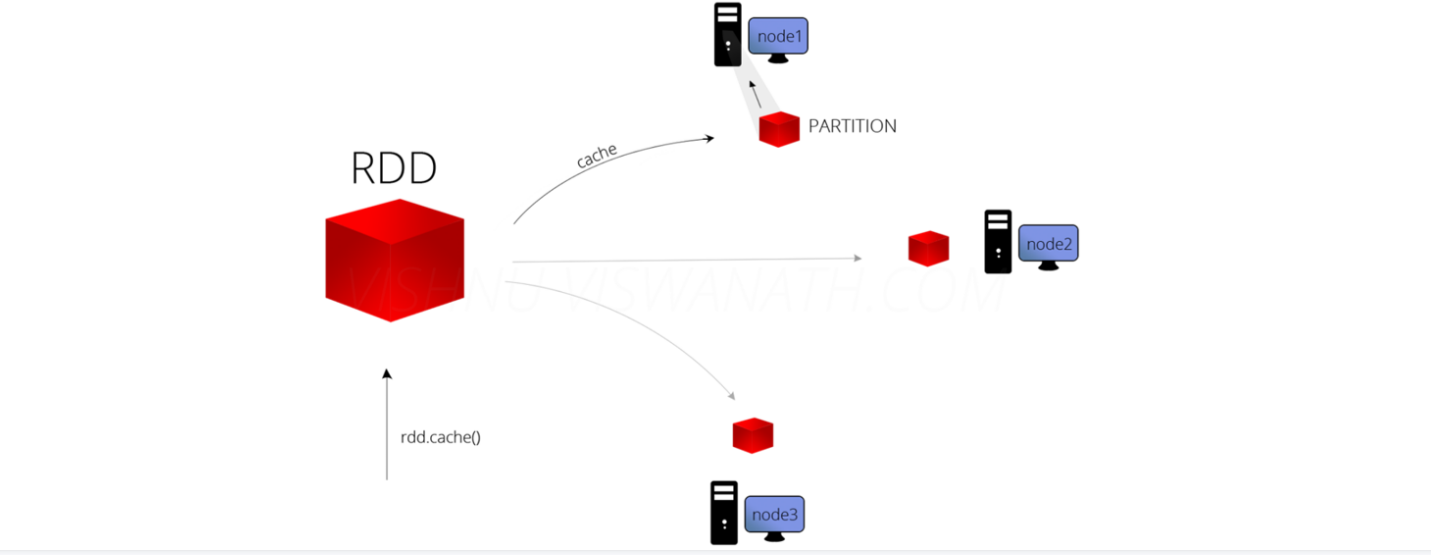
RDD的缓存/持久化 缓存解决的问题 缓存解决什么问题?-解决的是热点数据频繁访问的效率问题 在Spark开发中某些RD …
Continue Reading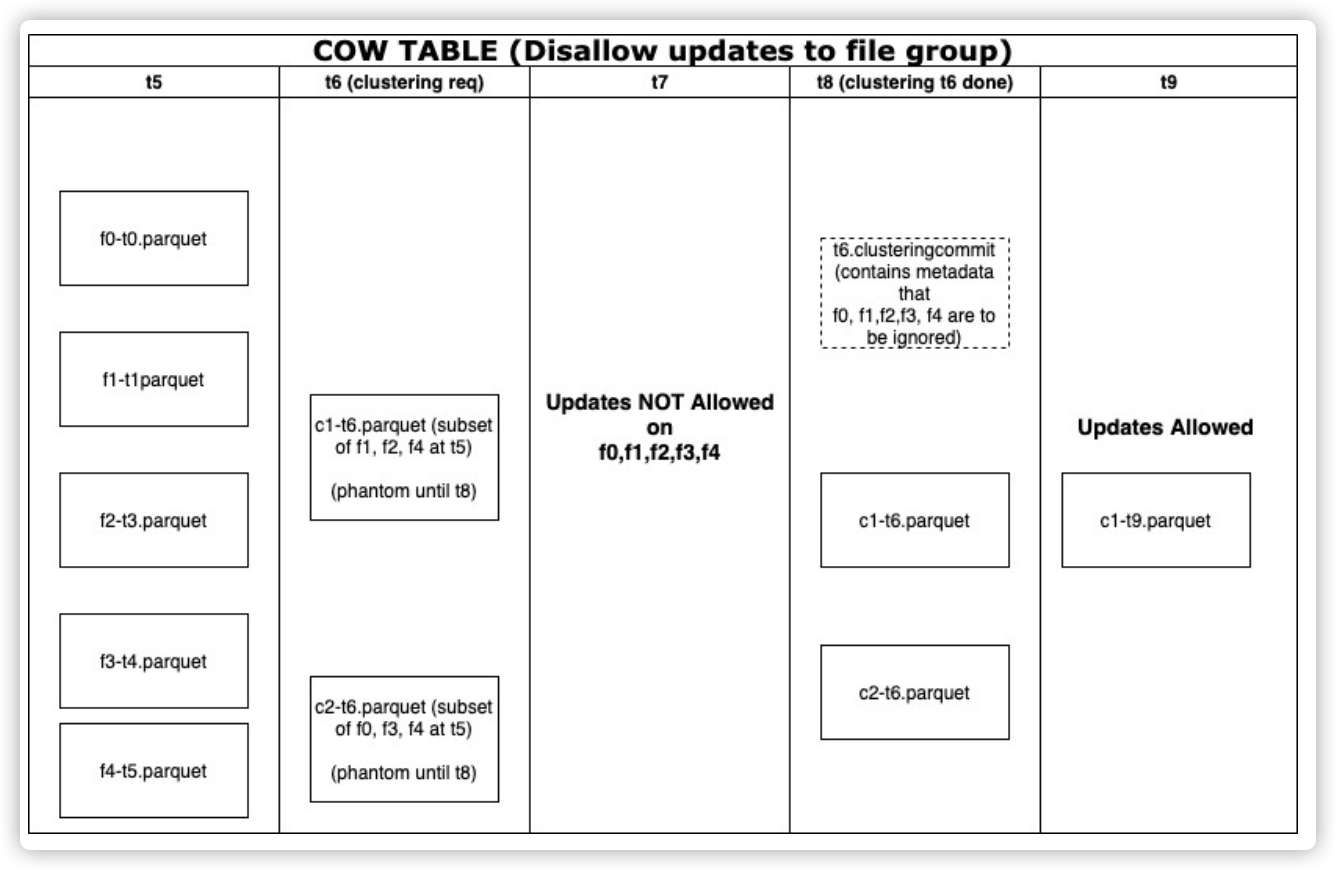
概要 数据湖的业务场景主要包括对数据库、日志、文件的分析,而管理数据湖有两点比较重要:写入的吞吐量和查询性能,这里主要说 …
Continue Reading
RDD的详解 RDD:弹性分布式数据集,是Spark中最基本的数据抽象,用来表示分布式集合,支持分布式操作! RDD的创 …
Continue Reading
目录 算子分类 转换(Transformations)算子 Map FlatMap MapPartitions Filt …
Continue Reading
1.Spark下载 //archive.apache.org/dist/spark/ 2.上传解压,配置环境变量 配 …
Continue Reading