简单的线程池(四)
- 2021 年 12 月 13 日
- 笔记
- C++, Thread, thread pool
概要
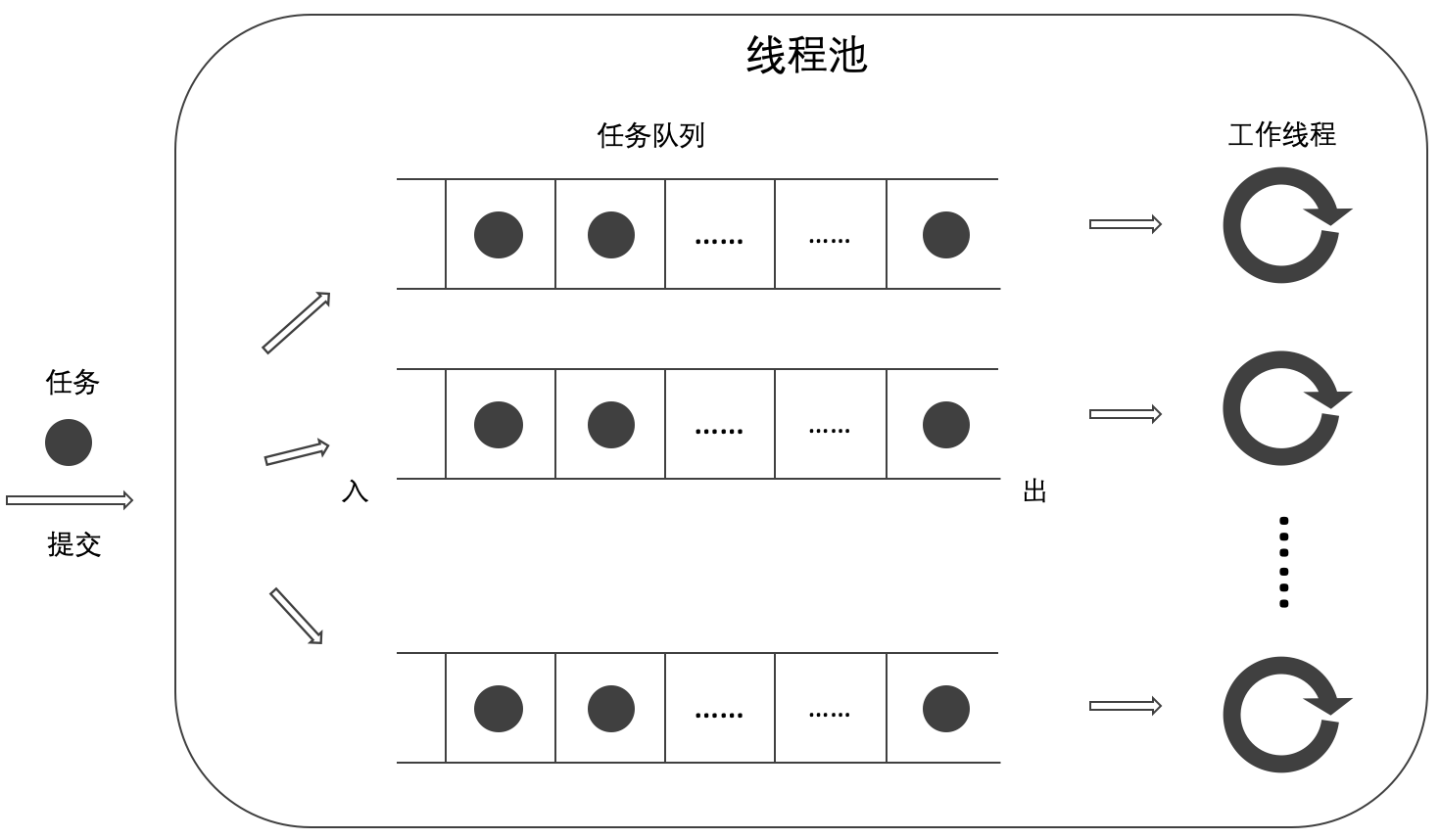
笔者对 《简单的线程池(一)》 中的非阻塞式线程池进行了改造。在新的线程池中,为每个工作线程配备一个独占的任务队列。线程池用户提交的任务被随机地分配到各个独占的任务队列中。工作线程从独占的任务队列中获取任务并执行。
本文不再赘述与 《简单的线程池(一)》 相同的内容。如有不明之处,请参考该博客。
实现
以下代码给出了此线程池的实现,(lockwise_unique_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _suspend_; // #5
atomic<bool> _done_;
unsigned _workersize_;
thread* _workers_;
Lockwise_Queue<Task_Wrapper>* _workerqueues_; // #2
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #4
task();
while (_suspend_.load(memory_order_acquire)) // #7
std::this_thread::yield();
}
}
void stop() {
size_t remaining = 0;
_suspend_.store(true, memory_order_release); // #6
for (unsigned i = 0; i < _workersize_; ++i)
remaining += _workerqueues_[i].size();
_suspend_.store(false, memory_order_release); // #8
for (unsigned i = 0; i < _workersize_; ++i)
while (!_workerqueues_[i].empty())
std::this_thread::yield();
std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining);
_done_.store(true, memory_order_release);
for (unsigned i = 0; i < _workersize_; ++i)
if (_workers_[i].joinable())
_workers_[i].join();
delete[] _workers_;
delete[] _workerqueues_; // #9
}
public:
Thread_Pool() : _suspend_(false), _done_(false) {
try {
_workersize_ = thread::hardware_concurrency();
_workers_ = new thread[_workersize_]();
_workerqueues_ = new Lockwise_Queue<Task_Wrapper>[_workersize_](); // #1
for (unsigned i = 0; i < _workersize_; ++i)
_workers_[i] = thread(&Thread_Pool::work, this, i);
} catch (...) {
stop();
throw;
}
}
~Thread_Pool() {
stop();
}
template<class Callable>
future<typename std::result_of<Callable()>::type> submit(Callable c) {
typedef typename std::result_of<Callable()>::type R;
packaged_task<R()> task(c);
future<R> r = task.get_future();
_workerqueues_[std::rand() % _workersize_].push(std::move(task)); // #3
return r;
}
};
构造 Thread_Pool 对象时,为每个工作线程配备一个独占的任务队列(#1),由 _workerqueues_ 指针引用(#2)。线程池用户提交的任务被随机地分配到各个独占的任务队列中(#3),每个线程根据自己的索引编号从与之对应的任务队列(#4)中获取任务并执行。
在线程池退出时,将 atomic<bool> _suspend_ 数据成员(#5)置为 true(#6),工作线程被暂停(#7);准确地统计完剩余的工作任务后,将其置为 false(#8),工作线程继续处理剩余的工作任务。最后,需要回收任务队列资源(#9)。
逻辑
以下类图展现了此线程池的代码主要逻辑结构。它与 《简单的线程池(一)》 中的线程池的区别在于 Thread_Pool 类到 Lockwise_Queue<> 类的多重性由 1 变为 1..* 。
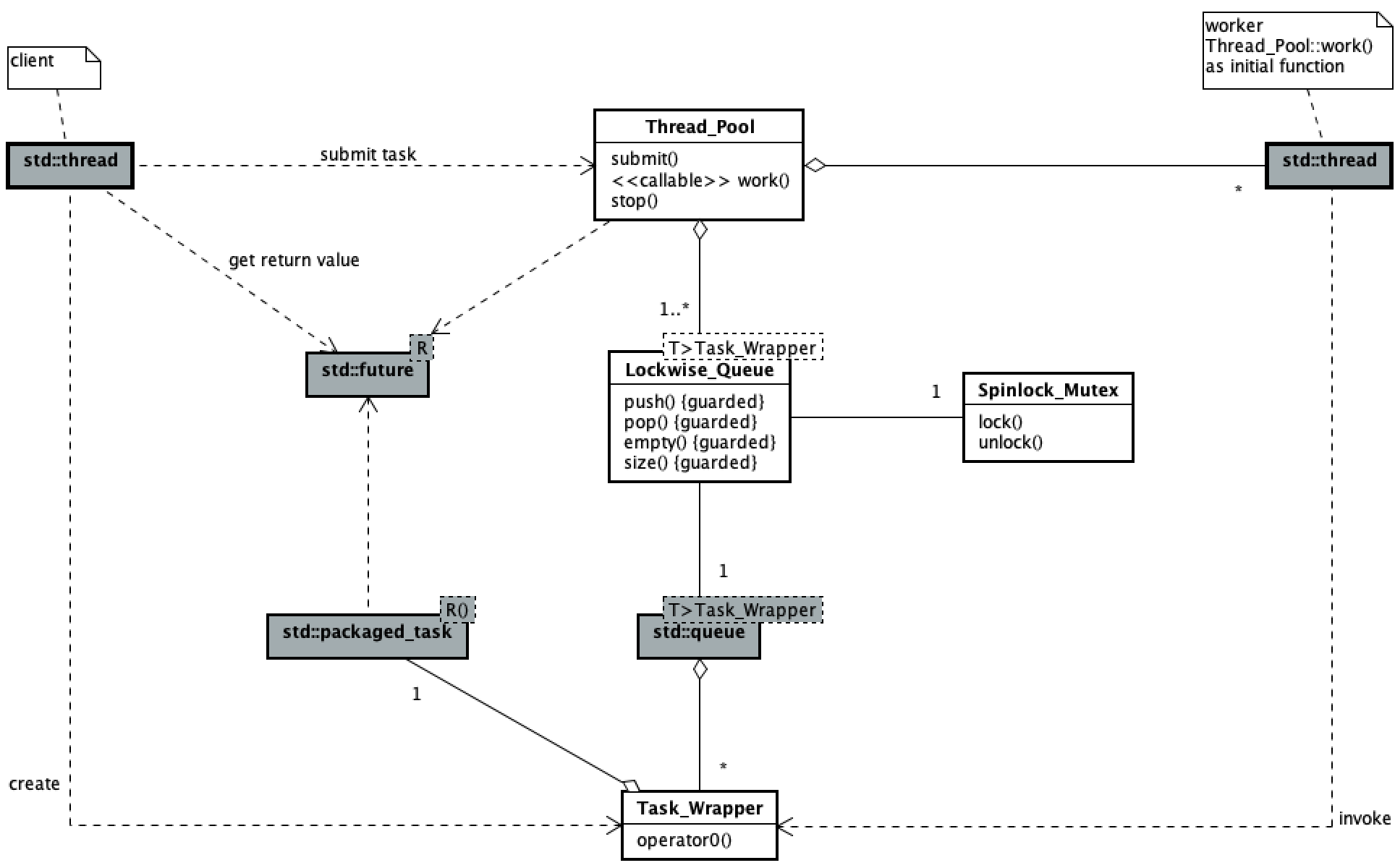
线程池用户提交任务与工作线程执行任务的并发过程与 《简单的线程池(一)》 中的一致,此处略。
验证
验证过程采用了 《简单的线程池(三)》 中定义的的测试用例,对应的测试结果均保存在 [github] cnblogs/15661191 中。
最后
完整的代码与测试数据请参考 [github] cnblogs/15661191 。