想学好深度学习,你需要了解——熵!
- 2020 年 1 月 2 日
- 笔记

熵的概念比较晦涩难懂。但是,我们还是想最大化的用容易理解的语言将它说明白。尽量不要让这部分知识成为大家学习的绊脚石。
欢迎一起讨论,不足之处还望多多指正。具体内容如下。
7.7 快速了解信息熵 (information entropy)
信息熵 (information entropy)是一个度量单位,用来对信息进行量化。比如可以用信息熵来量化一本书所含有的信息量。它就好比用米、厘米对长度进行量化一样。
信息熵这个词是克劳德·艾尔伍德·香农从热力学中借用过来的。在热力学中,用热熵来表示分子状态混乱程度的物理量。克劳德·艾尔伍德·香农用信息熵的概念来描述信源的不确定度。
7.7.1 信息熵与概率的计算关系
任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。
信息熵是指去掉冗余信息后的平均信息量。其值与信息中每个符号的概率密切相关。
提示:
在Shannon 编码定理中,介绍了熵是传输一个随机变量状态值所需的比特位下界。该定理的主要依据就是信息熵中没有冗余信息。
依据Shannon 编码定理信息熵还可以应用在数据压缩方面。
一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之不确定性就大,则信息熵就越大。
1.信息熵的特点
假设计算信息熵的函数是I,计算概率的函数是P,则信息熵的特点可以有如下表示:
(1)I是P的减函数。
(2)两个独立符号所产生的不确定性(信息熵)应等于各自不确定性之和,即I(P1,P2)=I(P1)+I(P2)。
2.自信息的计算公式
信息熵属于一个抽象概念,其计算方法本没有固定公式。任何符合信息熵特点的公式都可以被用作信息熵的计算。
对数函数是一个符合信息熵特性的函数。具体解释如下:
(1)假设两个是独立不相关事件的概率为P(x,y),则P(x,y)=P(x)P(y)。
(2)如果将对数公式引入信息熵计算的计算,则I(x,y)= log(P(x,y))=log(P(x))+log(P(y))。
(3)因为I(x)=log(P(x)),I(y)=log(P(y)),则I(x,y)=I(x)+I(y),正好符合信息熵的可加性。
为了满足I是P的减函数,则直接对P取倒数即可。于是,引入对数函数的信息熵其公式可以写成公式7-3。

(式7-3)
公式7-3中的I(x) 也被称为随机变量 x 的自信息 (self-information),描述的是随机变量的某个事件发生所带来的信息量。该函数在坐标轴上的曲线如图7-46所示。

图7-46 自信息公式
由图7-46可以看出,因为概率p的取值范围为0~1,公式7-3中的负号也可以用来保证信息量是非负数。
3.信息熵的计算公式
在信源中,假如一个符号U可以有n种取值:U1…Ui…Un,对应概率为:P1…Pi…Pn,且各种符号的出现彼此独立。则该信源所表达的信息量可以通过求 I(x)=−logp(U)关于概率分布 p(U) 的期望得到。那么U的信息熵便可以写成公式7-4。

(式7-4)
目前,信息熵大多都是通过公式7-4进行计算的。在数学中对数一般取2为底,单位为比特。在神经网络中,对数一般以自然对数e为底,单位常常被称为奈特(nats)。
由公式7-4可以看出,随机变量的取值个数越多,状态数也就越多,信息熵就越大,说明混乱程度就越大。
以一个最简单的单符号二元信源为例,该信源中的符号U仅可以取值为a或b。其中,取a的概率为p,则取b的概率为1-p。该信源的信息熵可以记为H(U)=pI(p)+(1-p)I(1-p)。所形成的曲线如图7-47所示。

图7-47 二元信源的信息熵
图7-47中,x轴代表符号U取值为a的概率值P,y轴代表符号U的信息熵H(U)。由图7-47可以看出信息熵有如下几个特性:
(1)确定性:当符号U取值为a的概率值P=0和P=1时,U的值是确定的,没有任何变化量,所以信息熵为0。
(2)极值性:当P=0.5时,U的信息熵达到了最大。这表明当变量U的取值为均匀分布时(所有的取值的概率都相同),熵最大。
(3)对称性:即对称于P=0.5
(4)非负性:即收到一个信源符号所获得的信息量应为正值,H(U)≥0。
4.了解连续信息熵及其特性
在“3 信息熵的计算公式”中所介绍公式适用于离散信源,即信源中的变量都是从离散数据中取值。
在信息论中,还有一种连续信源,即信源中的变量是从连续数据中取值。连续信源可以取值无限,信息量是无限大,对其求信息熵已无意义。一般常会已其它的连续信源做参照,用相对熵的值进行度量。此时连续信息熵可以用来表示,它是一个有限的相对值,又称相对熵(见7.7.4小节)。
连续信息熵与离散信源的信息熵特性相似,仍具有可加性。不同的是,连续信源的信息熵不具非负性。但是,在取两熵的差值为互信息时,它仍具有非负性。这与力学中势能的定义相仿。
7.7.2 了解联合熵 (Joint entropy)
联合熵 (Joint entropy)是将一维随机变量分布推广到多维随机变量分布。设两个变量X和Y ,它们的联合信息熵也可以由联合概率P(X,Y)进行计算得来。如公式7-5。

公式7-5
公式7-5中的联合概率分布P(X,Y)是指X,Y同时满足某一条件的概率。还可以被记作P(XY)或者P(X∩Y)。
7.7.3 了解条件熵 (Conditional entropy)
条件熵 H()表示在已知随机变量X的条件下随机变量Y的不确定性。条件熵 H() 可以由联合概率P(x,y)和条件概率P(y|x)进行计算得来。见公式7-6。
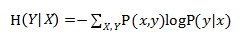
公式7-6
1.条件概率及对应的计算公式
公式7-6中的条件概率分布P(Y|X)是指Y基于X的条件概率,即在X的条件下Y出现的概率。它与联合概率的关系见公式7-7。

公式7-7
公式7-7中的P(X)是指X的边际概率(也叫边缘概率)。整个公式可以描述为:“XY的联合概率”等于“Y基于X的条件概率”乘以“X的边际概率”。
2.条件熵对应的计算公式
条件熵 H(Y|X)的计算公式与条件概率非常相似,也可以由X和Y 的联合信息熵计算而来。见公式7-8。

公式7-8
公式7-8可以描述为:条件熵 H(Y|X)=联合熵 H(X,Y) 减去X单独的熵(边缘熵) H(X)。即描述X和Y所需的信息是描述X自己所需的信息,加上给定X的条件下具体化Y所需的额外信息。
7.7.4 交叉熵 (Cross entropy)
交叉熵在神经网络中常用于计算分类模型的损失。其数学意义可以有如下解释:
假设样本集的概率分布为p(x),模型预测结果的概率分布为q(x),则真实样本集的信息熵如公式7-9

(式7-9)
如果使用模型预测结果的概率分布为q(x)来表示来数据集中样本分类的信息熵,则公式可以写成7-10

(式7-10)
公式7-10则为q(x)与p(x)的交叉熵。因为分类的概率来自于样本集,所以式中的概率部分用q(x),而熵部分则是神经网络的计算结果,所以用q(x)。
7.7.5 相对熵 (Relative entropy)——KL散度
相对熵(relative entropy)又被称为KL散度(Kullback-Leibler divergence)或信息散度(information divergence),用来度量是两个概率分布(probability distribution)间的非对称性差异。在信息理论中,相对熵等价于两个概率分布的信息熵(Shannon entropy)的差值。
1.相对熵的公式
设 p(x)、q(x) 是离散随机变量X中取值的两个概率分布,则p对 q的相对熵见公式7-11。

公式7-11
由公式7-11可知,当p(x)与q(x) 两个概率分布相同时,相对熵为0(因为log1=0),并且相对熵具有不对称性。
2.相对熵的与交叉熵之间的关系
将7-11的对数部分展开,可以看到相对熵与交叉熵之间的关系。见公式7-12

公式7-12
由7-12可以看出,p与 q的相对熵是由二者的交叉熵去掉p边缘熵而来的。在深度学习中,由于训练数据集是固定的,即p的熵一定,最小化交叉熵便等价于最小化预测结果与真实分布之间的相对熵(模型的输出分布与真实分布的相对熵越小,表明模型对真实样本拟合效果越好)。这也是为什么要用交叉熵作为损失函数的原因。
在变分自编码中,使用相对熵来计算损失,该损失函数用于指导生成器模型输出的样本分布更接近于高斯分布。因为目标分布不再是常数(不是来自于固定的样本集),所以无法用交叉熵来代替。这也是为什么变分自编码中使用KL散度的原因。
7.7.6 互信息(Mutual Information)
互信息(Mutual Information)是信息论里一种有用的信息度量,它用于度量2个变量间的共享信息量。可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
1.互信息公式
设两个变量X和Y ,它们的联合概率分布为P(X,Y),边际概率分别是P(X)、P(Y)。互信息是指联合概率P(X,Y)与边际概率P(X)、P(Y)的相对熵。见公式7-13

公式7-13
2.互信息的特性
互信息具有一下特性:
(1) 对称性:由于互信息属于两个变量间的共享信息,则
(2)独立的变量间互信息为0:如果两个变量独立,则它们之间没有任何共享信息,所以此时的互信息为0。
(3)非负性:共享信息要么有,要么没有,所以互信息量不会出现负值。
3.互信息与条件熵之间的换算
由条件熵的公式7-8得知 (见7.7.3小节) ,联合熵H(X,Y)可以由条件熵 H(Y|X)与X边缘熵 H(X)相加而成。见公式7-14:

公式7-14
将7-14中等号两边交换位置,则也可以得到互信息的公式,见式7-15

公式7-15
公式7-15与7-13是等价的(这里省略了证明等价的推导过程)。
4.互信息与联合熵之间的换算
将式7-15的互信息公式进一步展开,可以得到互信息与联合熵之间的关系。见公式7-16
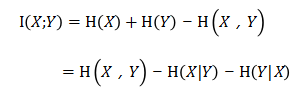
公式7-16
如果把互信息当作集合运算中的并集。则会更好理解。如图7-48所示。
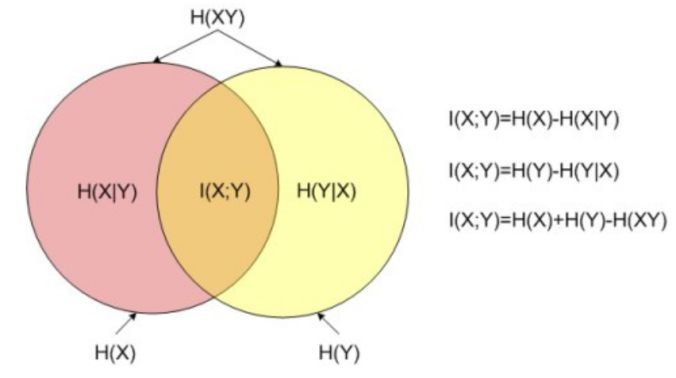
5.互信息与相对熵之间的换算
互信息还可以表示为两个随机变量X、Y 边缘分布的乘积,相对于X、Y 联合概率分布的相对熵。具体公式如式7-17。

公式7-17
在对抗神经网络(f-gan)以及图神经网络(DGI)中,使用了互信息来做为无监督方式提取特征的方法。具体实现过程及配套代码请参考7.8节、11.10节。
以上内容节选自代码医生工作室正在编写的深度学习系列书籍——《深度学习之Pytorch:入门、原理与进阶实战》

推荐阅读

点击“阅读原文”图书配套资源


