浅析数据库与缓存的双写一致性问题
- 2019 年 10 月 3 日
- 笔记
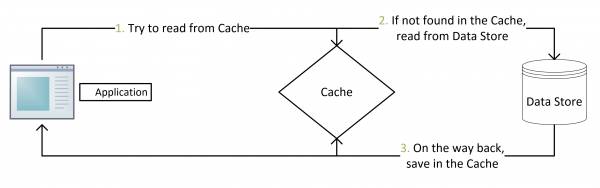
缓存由于其高并发和高性能的特性,在项目中被广泛使用。读缓存流程如下图:
双写一致性有以下三个要求:
- 缓存不能读到脏数据
- 缓存可能会读到过期数据,但要在可容忍时间内实现最终一致
- 这个可容忍时间尽可能的小
要想同时满足上面三条,可以采用读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况。但是,串行化之后,就会导致系统的吞吐量会大幅度的降低,要用比正常情况下多几倍的机器去支撑线上请求。

所以,在这里,我们讨论三种常见方法:
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
1. 先更新数据库,再更新缓存
这种方法是大家普遍反对的,原因集中在下面两点:
原因1:线程安全角度。
同时有请求A和请求B进行更新操作,那么会出现:
- 线程A更新了数据库
- 线程B更新了数据库
- 线程B更新了缓存
-
线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。"先更新缓存,再更新数据库"这种方案同理,也是造成脏数据,所以不被考虑
原因2:业务场景角度。
有如下两点:
- 如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致数据压根还没读到,缓存就被频繁的更新,浪费性能。
- 如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
如果一定要更新缓存,可以考虑给缓存数据增加版本号

2. 先删除缓存,再更新数据库
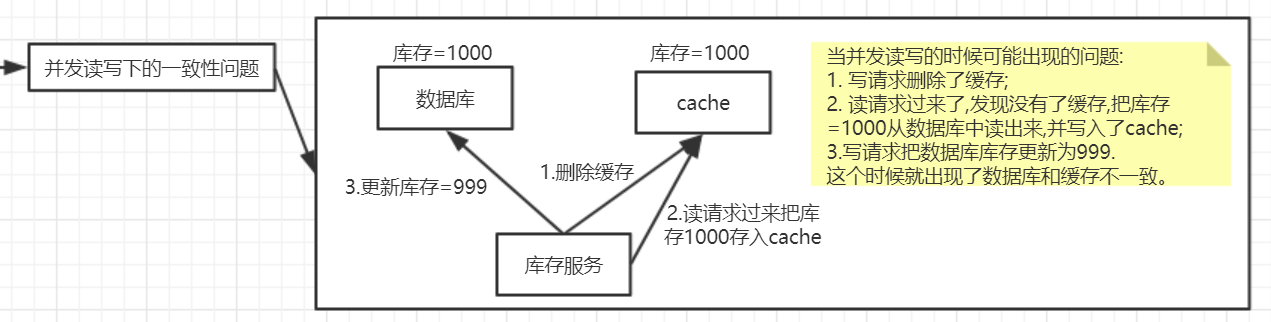
该方案同样会导致不一致。同时有请求A和请求B进行更新操作,那么会出现:
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
解决方法:
- 先删除缓存
- 再写数据库(这两步和原来一样)
- 休眠一定时间(例如1秒或200ms),再次删除缓存。这么做,可以将缓存脏数据再次删除。
然而这种解决方案由于要休眠线程还是很影响吞吐量的
3. 先更新数据库,再删除缓存
这种方案是很多工程采用的方案,我们来看下是否一定安全。
假设有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
- 缓存刚好失效
- 请求A查询数据库,得一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查到的旧值写入缓存
这样,脏数据就产生了,然而上面的情况是假设在数据库写请求比读请求还要快。实际上,工程中数据库的读操作的速度远快于写操作的。
要么通过2PC或是Paxos协议保证一致性,要么就是想尽办法降低并发时脏数据的概率,大概是因为2PC太慢,而Paxos又太复杂,综合考虑,Facebook选择了这个第三种方案。
如果删除缓存失败了怎么办?
启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
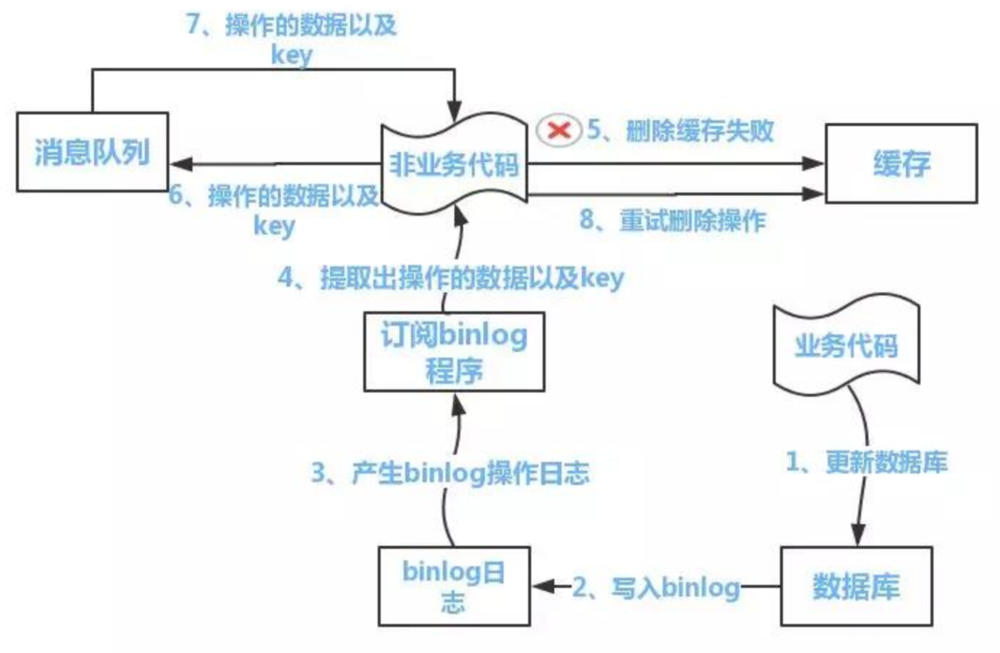
阿里开源的中间件canal可以完成订阅binlog日志的功能。
总结
本文是对目前互联网中已有的一致性方案进行了一个总结,希望大家有所收获。
最后,限于笔者经验水平有限,欢迎读者就文中的观点提出宝贵的建议和意见。如果想获得更多的学习资源或者想和更多的技术爱好者一起交流,可以关注我的公众号‘全菜工程师小辉’后台回复关键词领取学习资料、进入前后端技术交流群和程序员副业群。同时也可以加入程序员副业群Q群:735764906 一起交流。

