MySQL深入研究–学习总结(2)
前言
接上文,继续学习后续章节。
第四章&第五章《深入浅出索引》
这两章节主要介绍的索引结构及其如何合理建立索引,但是我觉得讲的比较简单。
总结回顾下吧,其实在我之前的文章《数据库原理研究与优化》对索引这块已有详细的介绍了,并对如何合理建立和使用索引给出了建议。
索引的常见模型:哈希表,有序数组和搜索树。
哈希表:典型的k-v储存结构,比如memcached就用的哈希表作为索引结构。
有序数组:数组的优缺点不用多数了,对于插入删除成本太高,一般只用于插入场景很少的时候,比如存一写静态的数据。
搜索树:二叉搜索树,AVL树,B树,B+树这些基本概念没什么好说的,属于基础了。InnoDB使用的索引结构就是B+树,之所有使用B+树,是因为它更符合磁盘的访问模式。
InnoDB的索引模型
在InnoDB中索引被分为主键索引和非主键索引,我们常说InnoDB中数据即索引,索引即数据。
主键索引:主键索引的叶子节点存储了具体的数据,所有又叫聚簇索引。
非主键索引:又叫辅助索引,辅助索引的叶子节点存储的是对应的主键ID。
所以通过辅助索引查询时,为了获取其他数据,需要再去主键索引中查询一遍获取具体数据,这就叫回表。
显然回表查询时会额外增加查询时间的,为了减少回表操作,我们可通过覆盖索引来解决。
覆盖索引:当我们根据辅助索引查询时,需要得知的数据已经在辅助索引中,就不需要回表了,比如查询结果只需要返回主键ID,那么辅助索引就已经存了,就不需要再回表查询了。
了解了索引模型,在如何优化SQL方面,其实就是围绕如何合理使用索引,使得查询效率更高。
索引的维护
如何主键是递增的,那么在插入数据时,只需要按索引顺序插入即可。
但当有索引字段的数据并不是按顺序插入时,当要插入的位置的数据页已经写满了,那就需要申请一个新的数据页,把部分数据移动到新的数据页,以为改数据的插入,这成为页分裂。页分裂不仅影响性能,还会影响数据页空间使用率。当然数据的查询,当页利用率很低后还会有页的合并操作。
索引设计与使用原则
参考文章《数据库原理研究与优化》
扩展:B+树深入剖析
由于作者讲这块比较浅,这里我做一个扩展。
为什么要使用B+树
⾸先需要明确的是,B树或B+树要⽐⼆叉树更适合作为索引存储,因为B树中的节点可以存储多个数据,从⽽就可以减少树的⾼度,也就减少了提升了查找性能。那为什么不选B树,而选B+树呢?
主要原因体现在3个⽅⾯:
-
B+树的磁盘读写代价更低
B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更⼩,如果把所有同⼀内部节点的关键字存放在同⼀盘块中,那么盘块所能容纳的关键字数量也越多,⼀次性读⼊内存的需要查找的关键字也就越多,相对IO读写次数就降低了。 -
B+树的查询效率更加稳定
-
由于⾮终节点并不是最终指向⽂件内容的节点,⽽只是叶⼦节点中关键字的索引。所以任何关键字的查找必须⾛⼀条从根节点到叶⼦节点的路。
-
所有关键字查询的路径⻓度相同,导致每⼀个数据的查询效率相当。
-
-
由于B+树的数据都存储在叶⼦节点中,分⽀节点均为索引,⽅便扫库,只需要扫⼀遍叶⼦节点即可,但是B树因为其分⽀节点同样存储着数据,我们要找到具体的数据,需要从根节点按序开始扫描,所以B+树更加适合在区间查询的情况,所以通常B+树⽤于数据库索引。
索引的实现
InnoDB中的索引结构与MyISAM的索引结构有很⼤的不同。
第⼀个重⼤区别是InnoDB的数据⽂件本身就是索引⽂件。在MyISAM中,索引⽂件和数据⽂件是分离的,索引⽂件仅保存数据记录的地址。⽽在InnoDB中,表数据⽂件本身就是按B+Tree组织的⼀个索引结构,这棵树的叶节点data域保存了完整的数据记录,这个索引的key是数据表的主键,所以InnoDB表数据⽂件本身就是主索引。这种索引叫做聚集索引。
因为InnoDB的数据⽂件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会⾃动选择⼀个可以唯⼀标识数据记录的列作为主键,如果不存在这种列,则MySQL⾃动为InnoDB表⽣成⼀个隐含字段作为主键,这个字段⻓度为6个字节,类型为⻓整形。
第⼆个与MyISAM索引的不同是,InnoDB的辅助索引data域存储相应记录主键的值⽽不是地址。换句话说InnoDB的所有辅助索引都引⽤主键作为data域。
聚集索引这种实现⽅式使得按主键的搜索⼗分⾼效,但是辅助索引搜索需要检索两遍索引:⾸先检索辅助索引获得主键,然后⽤主键到主索引中检索获得记录。
InnoDB的B+ 树索引的特点是⾼扇出性,因此⼀般树的⾼度为2~4层,这样我们在查找⼀条记录时只⽤I/O 24次。当前机械硬盘每秒⾄少100次I/O/s,因此查询时间只需0.020.04s。
第六章《全局锁和表锁》&第七章《行锁》
根据加锁的范围, 根据加锁的范围, MySQL里面的锁大致可以分成全局锁、表级锁和行锁三类 里面的锁大致可以分成全局锁、表级锁和行锁三类 。
全局锁
顾名思义,就是对整个库加锁,加锁之后,整个库变成了只读。一般只用于对整个库进行备份的场景。
加全局锁备份,是为了保证数据的一致性。但其实但对数据库进行dump的时候,MySQL会启动一个事务,来确保拿到一致性视图,由MVCC的支持,这时候数据依然可以正常更新的。
既然有这机制为什么还要有全局锁的操作,需要注意的是,事务是有存储引擎实现的,并不是所有的引擎都支持。当你库中表都是innoDB引擎的时候,就可以这样备份。所以为什么建议大家默认使用innoDB引擎。
表级锁
表级锁分两种:一种表锁(TL),一种元数据锁(MDL)
表锁分为:读锁跟写锁
当一个线程执行lock t1 read,t2 write时,其他线程对表T1只能读,对T2读写都被阻塞。线程本身对T1可读,对T2可读写。
一般情况下不建议使用表锁,除非引擎不支持行锁。
元数据锁(MDL):
MDL锁不需要显式加上,当访问一张表(增删改查都会加)的时候,会自动加MDL读锁,当需要对一张表更改表结构时会自动加MDL写锁。
读锁之前不互斥,多个线程可以同时对同一张表CRUD;
读锁与写锁,写锁与写锁之间都是互斥的。当一个线程对表进行CRUD时,另外一个线程要对这张表删除一列,则需要等待第一个线程操作结束。或者两个线程同时对一张表进行加字段时,需要串行。
MDL锁会在事务提交时释放,所以在长事务里,事务不提交,就会一直占着MDL锁。
行锁
行锁是基于引擎层实现的,并不是所有引擎都支持行锁,MyISAM是不支持的,innoDB支持行锁。
但平时我们操作数据库时,并不需要关心什么时候加锁,什么时候释放锁,因为这都是MySQL自动帮我们处理的。例如当我们需要更新id=1这行数据时,就会对这行进行加锁,当有另外一个线程也要更新id=1这行数据时,就需要等待。
在事务中,行锁的释放,不是对该行数据执行完就立即释放的,而是等事务提交才释放。这就是所谓的两阶段锁。
那么为了减少行多带来的性能问题,当你一个事务中要更新多行对多个行进行加锁时,把可能有并发操作的哪一行操作放到最后执行,以减少锁等待时间。当然这还得取决于业务流程。
死锁
当并发系统多个线程循环争夺资源,线程之间都在等待其他线程释放资源,就会导致这些线程处于无限等待状态,这称为死锁。
以数据库为例,两个线程,第一个线程同时先对id=1再对id=2这行进行更新,第二个线程需要先对id=2再对id=1进行更新,当线程1执行到要对id=2更新是,由于此时id=2的行锁被线程2持有,便处于等待状态,当线程2执行到id=1进行更新时,此时id=1的行锁被线程1持有,这便造成了死锁。
显然我们不可能一直让这状态无限持续下去,MySQL可以对锁等待时间进行设置,通过innoDB_lock_wait_timeout来设置,比如设置60s,那么时间到了之后,第一个被锁住的就会超时退出。但有些业务场景,无法等待这么久的时间的,当也不能设置太短,设置1s,也会对其他正常锁等待的线程,造成误伤。
除此之外,还可以通过死锁主动检测,通过innoDB_deadlock_detect设置on,默认就是on。它会主动检测发生死锁的时候,然后快速发现处理,但这本身也有额外负担的。
当一个新的线程加入处于堵塞状态,就要判断是否由于自己加入导致了死锁,当有1000个这样的线程,那么可想而知这性能消耗,会占用大量的CPU资源。
所以一般在并发量不高的系统可以这么用。
笔者锁在的系统使用的是第一个,设置锁等待时间。
第八章《事务到底是隔离还是不隔离》

先看个例子:已经k的初始值是1,那么在事务ABC中分别查到的k值是多少呢?前提是数据库的隔离级别:可重复读。start transaction with consistent snapshot执行该命名表示立即开启事务。
结果是:A中k=1,B中k=3,Ck=2;你是否答对了呢?
1、A先开启时了事务,由于隔离级别为可重复读,所有在该事务内,无论什么时候读取k,都是。
2、B开启了事务,还未执行更新时,C紧接着执行了更新,C的事务时在执行更新语句时自动开启,在更新结束后自动提交的,所以C更新完,此时k=2。
3、当B执行更新时,由于C也在更新,所以出于行锁等待C更新完毕,轮到B时,此时K已经是2了,所以B执行更新时,把K更新成了3。所以更新完再次查询时,查出来的就是。
此时有人可能有疑惑,不是说在可重复隔离级别下,开启事务后,在事务内查的结果都不会变吗,B是在C更新之前开启的时候,那时候K还是1,怎么后面再查询就变成了3了呢,这就得引入当前读(current read)了。
有一条这样的规则:更新数据都是先读后写的,而这个读,只能读当前的值。所以当B执行更新时先读的是K当前的值2,在2的基础上进行更新的。
MVCC如何实现的
在MySQL中有两个视图的概念:
1、就是view,就是用查询语句定义的虚拟表,通过create view…创建。
2、还有个就是innoDB在实现MVCC用到的一致性视图,即consistent read view,用于支持读提交和可重复读隔离级别的实现。
当一致性视图指的并不是实际存在的物理结构,只是一个逻辑定义,他定义了在事务执行期间能看到什么数据。
那么这个一致性视图到底是如何实现的?
在逻辑上我们认为,当开启事务后,就会生成一个静态的”视图“,这个“视图”是基于整个库的。如果这个“视图”是真实存在的,假设整个图有几百G的数据,要为这个库在秒级生成对应的静态视图,是不是不大可能?
实际上,innoDB中每个事务都有一个唯一的事务ID,transaction id。它在事务开始的时候向事务系统申请的,并且顺序严格递增的。
而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把transaction id赋值给这个数据版本的事务ID,记为row trx _id。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。
也就是说,数据表中的一行记录,其实可能有多个版本( row ) ,每个版本有自己的row trx _id。
实际上这个每个版本的数值,是根据undo log 推算出来的。
按照可重复读的定义,在事务启动的时候,innoDB为这个事务构造了一个数组,用来保存事务启动的瞬间,当前正在活跃的所有事务id。数组中id最小值为低水位,最大值+1位高水位,这个数组事务+高水位组成了当前的一致性视图(read-view)。
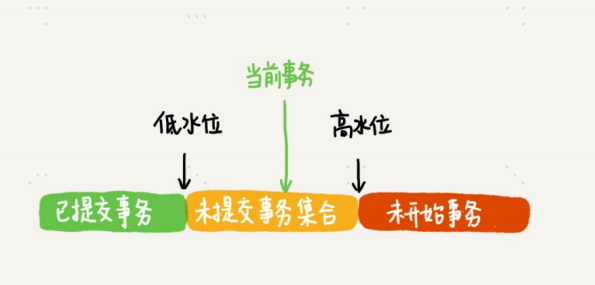
所以当一个事务开启后,一个版本的row trx_id如果比低水位小,那就是说明这是已提交的事务,这个数据是可见的.
如果比高水位高,说明是将来的事务,是不可见的。
如果处于低水位和高水位的,说明row trx_id在数组中,说明是还未提交的事务,不可见,如果不在,说明是已提交的事务,是可见的。
所以,innoDB利用“所有数据都有多个版本”这个特性,实现了秒级创建”快照“的能力。