SpringBoot进阶教程(七十一)详解Prometheus+Grafana
- 2021 年 2 月 18 日
- 笔记
- Spring Boot, springboot
随着容器技术的迅速发展,Kubernetes已然成为大家追捧的容器集群管理系统。Prometheus作为生态圈Cloud Native Computing Foundation(简称:CNCF)中的重要一员。Prometheus是一套开源的系统监控报警框架。它启发于Google的borgmon监控系统,由工作在SoundCloud的google前员工在2012年创建,作为社区开源项目进行开发,并于2015年正式发布。2016年,Prometheus正式加入Cloud Native Computing Foundation,成为受欢迎度仅次于Kubernetes的项目。
vPrometheus特点
作为新一代的监控框架,Prometheus具有以下特点:
1. 强大的多维度数据模型:
(1) 时间序列数据通过metric名和键值对来区分。
(2) 所有的metrics都可以设置任意的多维标签。
(3) 数据模型更随意,不需要刻意设置为以点分隔的字符串。
(4) 可以对数据模型进行聚合,切割和切片操作。
(5) 支持双精度浮点类型,标签可以设为全unicode。
2. 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个metrics进行乘法、加法、连接、取分数位等操作。
3. 易于管理: Prometheus server是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
4. 高效:平均每个采样点仅占 3.5 bytes,且一个Prometheus server可以处理数百万的metrics。
5. 使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的metrics。
6. 可以采用push gateway的方式把时间序列数据推送至Prometheus server 端。
7. 可以通过服务发现或者静态配置去获取监控的targets。
8. 有多种可视化图形界面。
9. 易于伸缩。
需要指出的是,由于数据采集可能会有丢失,所以Prometheus不适用对采集数据要100%准确的情形。但如果用于记录时间序列数据,Prometheus具有很大的查询优势,此外,Prometheus适用于微服务的体系架构。
vPrometheus组成及架构
Prometheus官方文档中的架构图:
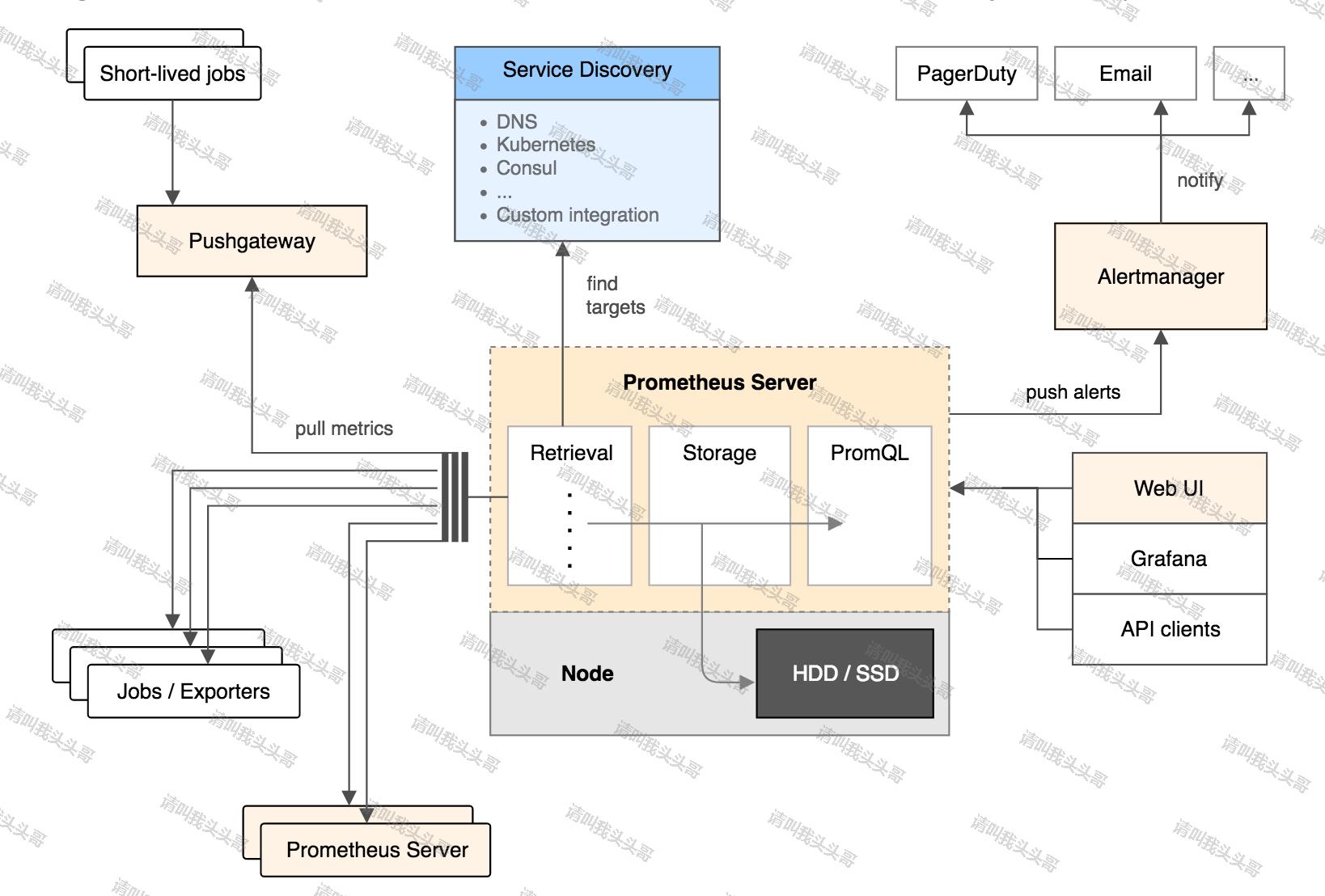
从上图可以看出,Prometheus的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。
Prometheus生态圈中包含了多个组件,其中许多组件是可选的:
1. Prometheus Server: 用于收集和存储时间序列数据。
2. Client Library: 客户端库,为需要监控的服务生成相应的metrics并暴露给Prometheus server。当Prometheus server来 pull 时,直接返回实时状态的metrics。
3. Push Gateway: 主要用于短期的jobs。由于这类jobs存在时间较短,可能在Prometheus来pull之前就消失了。为此,这次jobs可以直接向Prometheus server端推送它们的metrics。这种方式主要用于服务层面的metrics,对于机器层面的metrices,需要使用node exporter。
4. Exporters: 用于暴露已有的第三方服务的metrics给Prometheus。
5. Alertmanager: 从Prometheus server端接收到alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook等。
6. 一些其他的工具。
其大概的工作流程是:
1. Prometheus server定期从配置好的jobs或者exporters中拉metrics,或者接收来自Pushgateway发过来的metrics,或者从其他的Prometheus server中拉metrics。
2. Prometheus server在本地存储收集到的metrics,并运行已定义好的alert.rules,记录新的时间序列或者向Alertmanager推送警报。
3. Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
4. 在图形界面中,可视化采集数据。
vPrometheus相关概念
下面将对Prometheus中的数据模型,metric类型以及instance和job等概念进行介绍,以便读者在Prometheus的配置和使用中可以有一个更好的理解。
数据模型
Prometheus中存储的数据为时间序列,是由metric的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
- metric 名字:该名字应该具有语义,一般用于表示metric的功能,例如:httprequests_total, 表示http请求的总数。其中,metric名字由ASCII字符,数字,下划线,以及冒号组成,且必须满足正则表达式
[a-zA-Z:][a-zA-Z0-9_:]*。 - 标签:使同一个时间序列有了不同维度的识别。例如
httprequests_total{method="Get"}表示所有http请求中的Get请求。当method="post"时,则为新的一个metric。标签中的键由ASCII字符,数字,以及下划线组成,且必须满足正则表达式[a-zA-Z:][a-zA-Z0-9_:]*。 - 样本:实际的时间序列,每个序列包括一个float64的值和一个毫秒级的时间戳。
- 格式:
{=,…},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
四种Metric类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
1. Counter一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
例子:查询 http_requests_total{method="get", job="Prometheus", handler="query"} 返回8,10秒后,再次查询,则返回14。
2. Gauge一种常规的metric,典型的应用如:温度,运行的goroutines的个数;可以任意加减。
例子: go_goroutines{instance="172.17.0.2″, job="Prometheus"} 返回值147,10秒后返回124。
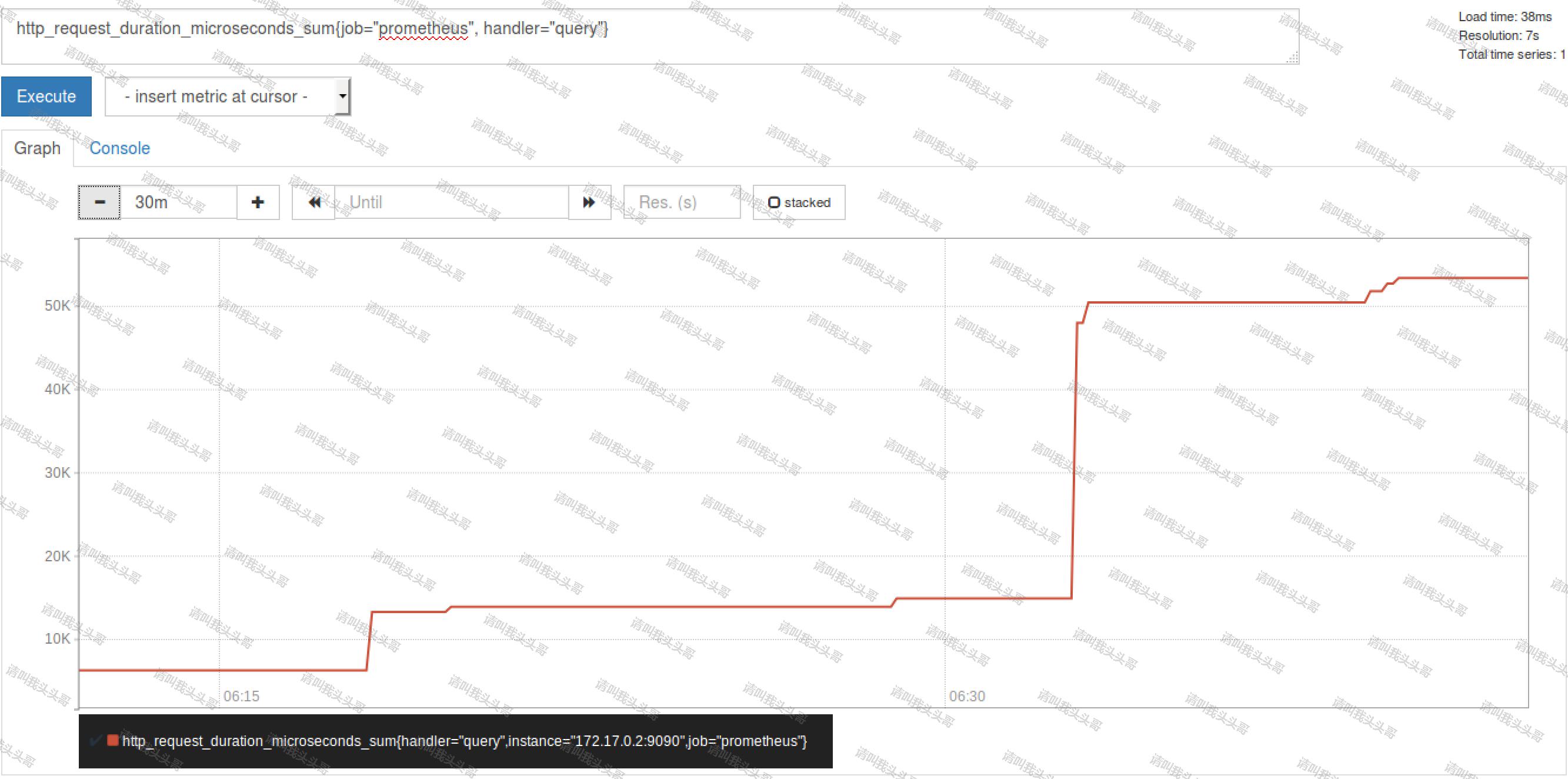
3. Histogram可以理解为柱状图,典型的应用如:请求持续时间,响应大小;可以对观察结果采样,分组及统计。
例子:查询 http_request_duration_microseconds_sum{job="Prometheus", handler="query"} 时,返回结果如下:
4. Summary类似于Histogram, 典型的应用如:请求持续时间,响应大小;提供观测值的count和sum功能;提供百分位的功能,即可以按百分比划分跟踪结果。
instance和jobs
instance: 一个单独scrape的目标, 一般对应于一个进程。
jobs: 一组同种类型的instances(主要用于保证可扩展性和可靠性),例如:
job和instance的关系:
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671
当scrape目标时,Prometheus会自动给这个scrape的时间序列附加一些标签以便更好的分别,例如: instance,job。
注意:以上段落均出自《Prometheus入门与实践》, 感兴趣的可以看看原文。
vPrometheus安装
1. 下载所需镜像
docker pull prom/node-exporter docker pull prom/prometheus docker pull grafana/grafana
2. 启动node-exporter
docker run -d -p 9100:9100 \ -v "/proc:/host/proc:ro" \ -v "/sys:/host/sys:ro" \ -v "/:/rootfs:ro" \ --net="host" \ prom/node-exporter
3. 验证node-exporter
url访问 //toutou.com:9100/metrics ,效果如下:
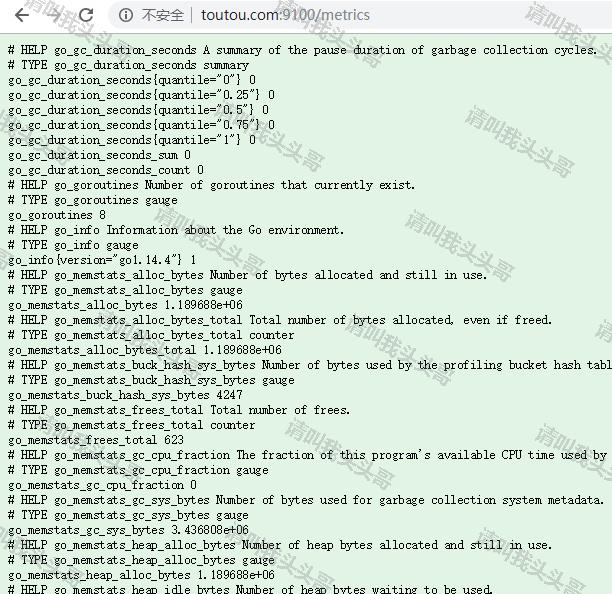
Node exporter主要用于暴露metrics给Prometheus,其中metrics包括:cpu的负载,内存的使用情况,网络等。有了这些就可以做数据展示了
4. 启动prometheus
mkdir /data/prometheus
mkdir config
cd /data/prometheus/config
vim prometheus.yml
# 全局设置,可以被覆盖
global:
# 默认值为 15s,用于设置每次数据收集的间隔
scrape_interval: 15s
# 估算规则的默认周期 每15秒计算一次规则
evaluation_interval: 15s
# 设置报警规则
#rule_files:
#- "first_rules.yml"
#抓取配置列表
scrape_configs:
# 一定要全局唯一, 采集 Prometheus 自身的 metrics
- job_name: prometheus
# 静态目标的配置
static_configs:
#这个自带的默认监控prometheus所在机器的prometheus状态
- targets: ['localhost:9090']
labels:
instance: prometheus
# 一定要全局唯一, 采集 Prometheus 自身的 metrics
- job_name: linux
static_configs:
# 本机 node_exporter 的 endpoint
- targets: ['localhost:9100']
labels:
# 新添加的标签,可以自定义
instance: toutoudemo
docker run -d \
-p 9090:9090 \
-v /data/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
--name pr \
prom/prometheus
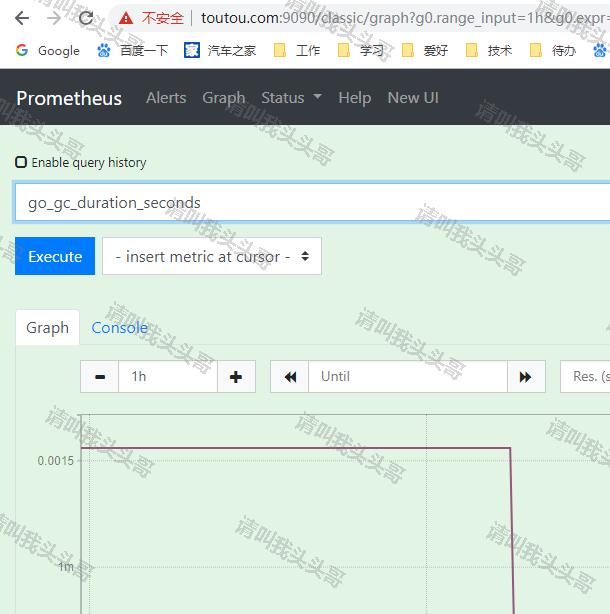
5. 验证prometheus
url访问 //toutou.com:9090/graph ,效果如下:
vGrafana安装
1. 上文中已经拉取了grafana的镜像,这里直接启动即可
创建/data/app/grafana/data文件夹存储数据,创建好了以后启动grafana。
docker run -d \
-p 3000:3000 \
--name=grafana \
-v /data/app/grafana/data:/var/lib/grafana \
grafana/grafana
我们发现运行以后,docker实例并没有起来,于是我们用 docker logs grafana 查看了docker日志。
[root@localhost data]# docker logs grafana
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: //docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
mkdir: can't create directory '/var/lib/grafana/plugins': Permission denied
因为grafana用户会在这个目录写入文件,所以需要设置权限
2. /data/app/grafana/data设置权限
chmod 777 -R /data/app/grafana/data
3. 验证grafana
url访问 //toutou.com:3000 ,效果如下:

打开之后的登录界面用默认账号/密码admin登录即可,会引导你修改密码,这里由于是本地测试的,就不设置了,直接skip跳过。
4. Add data source
点开Configuration(齿轮图标)->Data Source,然后点击Add data source按钮。然后选择Prometheus则进入到Prometheus数据源配置。
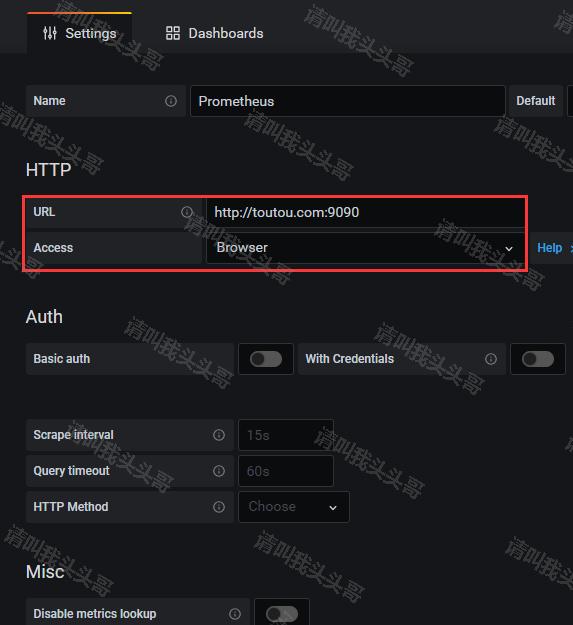
注意,access中选择Browser,配置好Prometheus点击save & test,弹出提示”Data source is working”即可。
4. Create Dashboard
回到首页,在创建(加号图标)中点击Dashboard,然后点击Add new panel按钮。然后点击Panel Title,点击标题下拉框中的Edit。
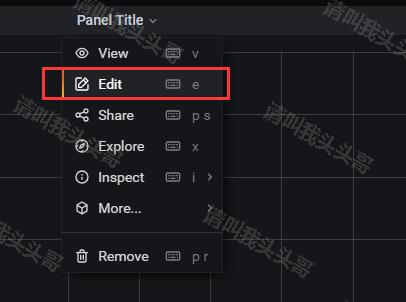
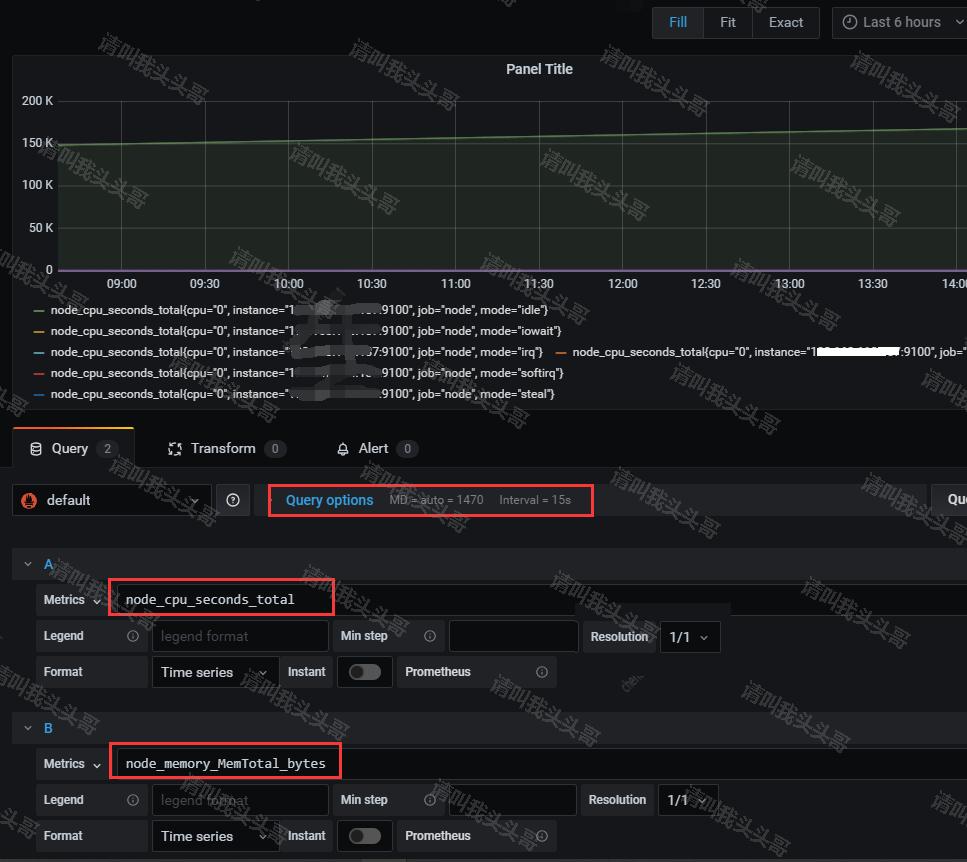
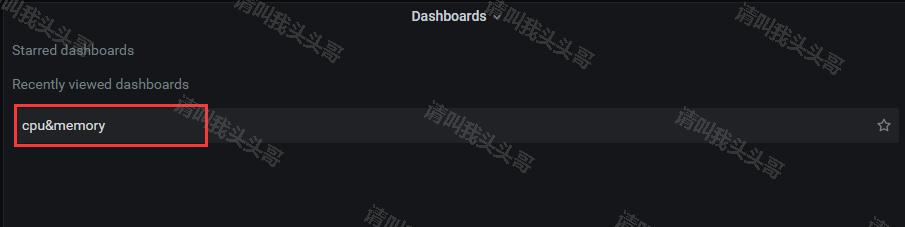
这里我们添加内存和cpu信息,点击保存,输入dashboard名称—cpu&memory(自定义)。回到首页即可看到我们保存的cpu&memory。
vSpringboot整合Prometheus+Grafana监控
1. 添加引用
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency>
2. 添加application.properties
management.endpoints.web.exposure.include=prometheus
3. 验证效果
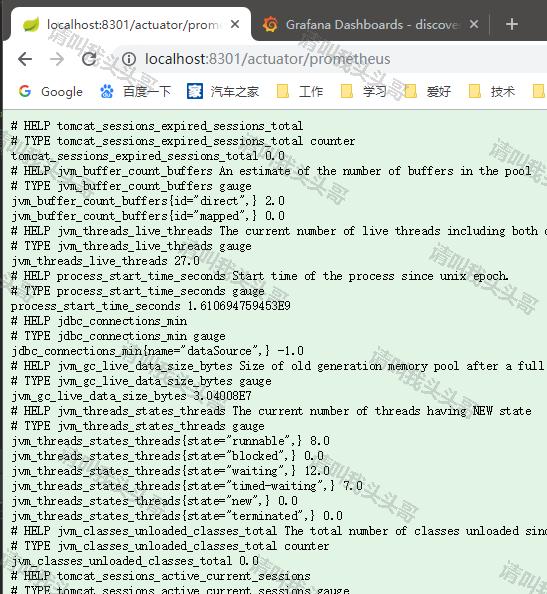
注意:开启actuator后要注意要防护,开启actuator的服务千万不能直接对外。常见的方法可以新增一个过滤器对 /actuator 路径过滤,只允许内网IP地址访问。
如果不知道如何在springboot过滤拦截的话,可以看看这个。传送门:SpringBoot入门教程(十一)过滤器和拦截器
4. 部署springboot
部署好了以后,重启docker实例,并查看效果。
如果不知道如何部署springboot的话,可以看看这个。传送门:SpringBoot入门教程(二)CentOS部署SpringBoot项目从0到1

5. prometheus.yml中添加job
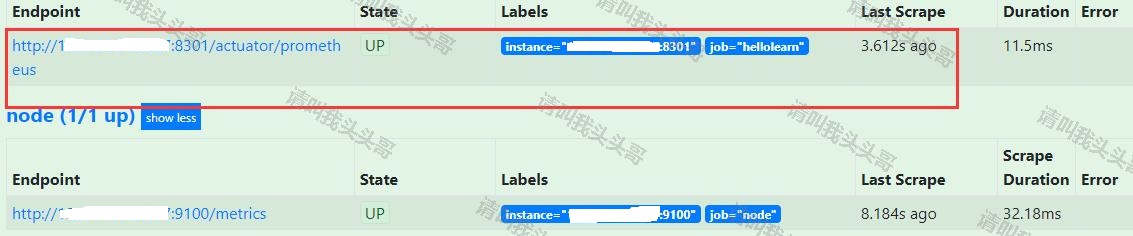
global: # 全局设置,可以被覆盖 scrape_interval: 15s # 默认值为 15s,用于设置每次数据收集的间隔 external_labels: # 所有时间序列和警告与外部通信时用的外部标签 monitor: 'codelab-monitor' rule_files: # 警告规则设置文件 - '/etc/prometheus/alert.rules' # 用于配置 scrape 的 endpoint 配置需要 scrape 的 targets 以及相应的参数 scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # 一定要全局唯一, 采集 Prometheus 自身的 metrics # 覆盖全局的 scrape_interval scrape_interval: 5s static_configs: # 静态目标的配置 - targets: ['localhost:9090'] - job_name: 'node' # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter scrape_interval: 10s static_configs: - targets: ['127.0.0.1:9100'] - job_name: 'hellolearn' # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter scrape_interval: 10s metrics_path: /actuator/prometheus #params: #format: ["prometheus"] static_configs: - targets: ['127.0.0.1:8301']
6. import模板
上文中我们已经演示了如何在dashboard中逐条添加指标,逐条添加就是熟悉一下指标格式。同样的,Grafana也提供了很多功能强大的模板(更多模板可以在这找),这里我们直接引入一个酷炫一点的模板。更多模板可以在这里找到。


点击+号 –> Import –> 输入模板链接或ID –> 点击Load。
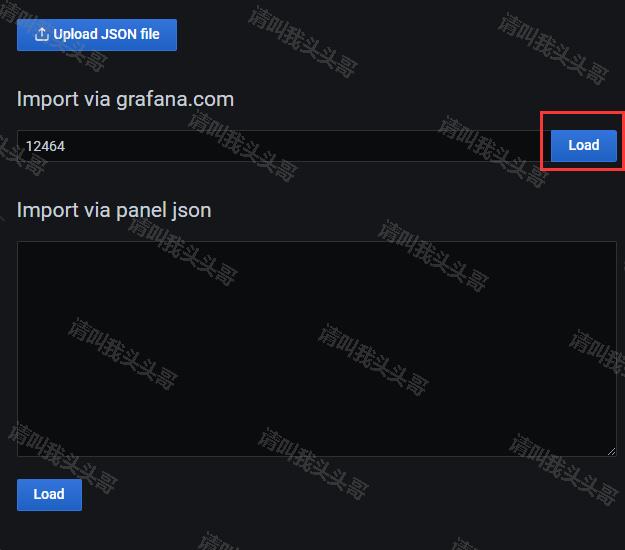
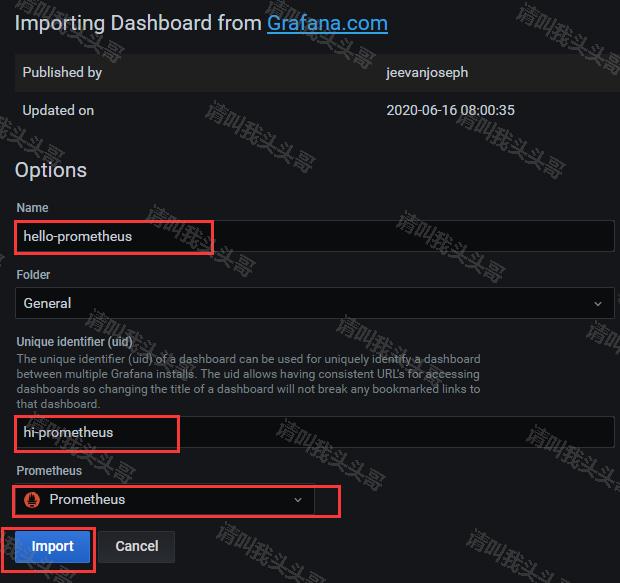
Name和Unique identifier (uid)可以自定义,也可以用默认的。
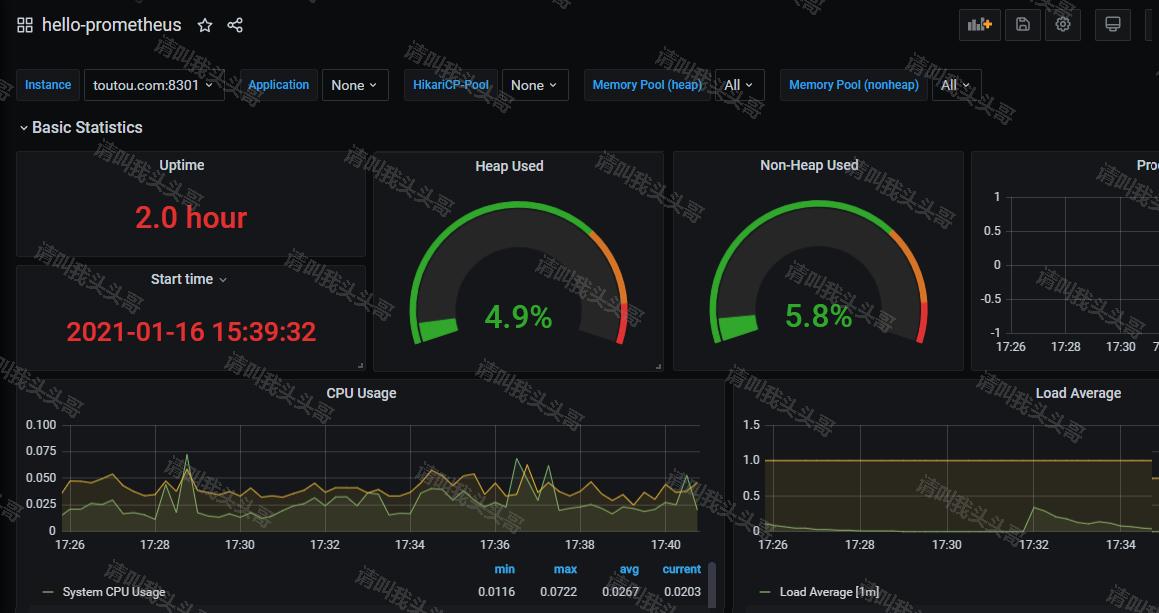
点击import,效果如下:
7. 配置多个应用
若是想配置多个应用,在prometheus.yml中添加job_name,添加好了之后重启docker即可。
- job_name: 'hellolearn' # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter
scrape_interval: 10s
metrics_path: /actuator/prometheus
#params:
#format: ["prometheus"]
static_configs:
- targets: ['127.0.0.1:8301']
- job_name: 'hellolearn-6' # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter
scrape_interval: 10s
metrics_path: /actuator/prometheus
#params:
#format: ["prometheus"]
static_configs:
- targets: ['127.0.0.1:8306']
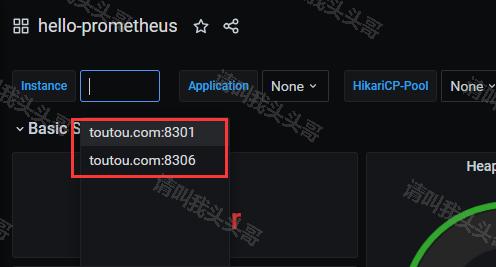
在Grafana的dashboard直接切换即可。
其他参考/学习资料:
v源码地址
//github.com/toutouge/javademosecond/tree/master/hellolearn
作 者:请叫我头头哥
出 处://www.cnblogs.com/toutou/
关于作者:专注于基础平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!

