Zoom-Net 关系检测论文笔记
Background
- 论文动机
- 通过加强分支间的信息共享和特征交互,objetcs和object对之间的关系都能被很好地检测出来,不需要语言先验
- 论文贡献
- 提出独特的逆RoI pool操作
- 提出金字塔RoI pool操作单元,用于传播全局预测特征
Model

appearance,context and spatiality

-
Appearance Module: 模型主要关注每个RoI内部的相互依存关系。也就是说subjetc, predicate 和 object分支的特征是独立学习的,没有任何信息传递。
-
Context-appearance Module: 直接融合三个分支中任意两个分支的特征,这使得subject和object特征能够从predicate特征中吸收上下文信息,predicate特征接收subject和object的信息。这些特征被直接连接起来,忽略它们在原始图像中的相对空间布局。
-
Spatiality-Context-Appearance Module: 相对位置等信息在CA-M并没有充分体现。因此,作者提出SCA-M,如下图所示:
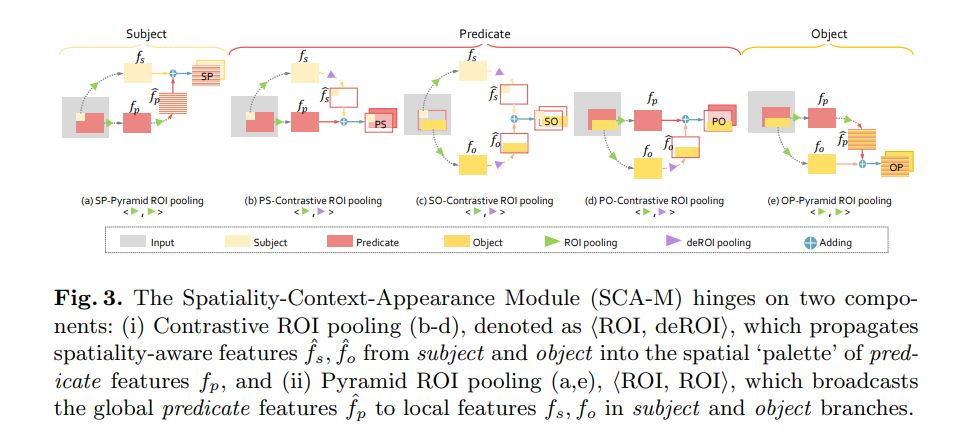
它由两个部分组成:
Contrast RoI Pool和Pyramid RoI Pool,主要用于在不同分支间进行信息传递。相较于CA-M。SCA-M以空间感知的方式重构了局部和全局信息聚合,从而在捕捉关系三元组特征间的空间和上下文关系方面具有卓越的能力。将subject, predicate和object的感兴趣区域感受野分别表示为\mathcal{R}_s, \mathcal{R}_p, \mathcal{R}_o。\mathcal{R}_p表示刚好覆盖subject和object的联合边界框。这三个区域经过ROI-pooled后的特征为\mathbf{f}_t, t\in \{s,p,o\}。
- Contrastive ROI Pooling: 表示为一对<ROI,逆ROI>操作。object的特征\mathbf{f}_o首先经过ROI pool操作,提取归一化局部特征,然后这些特征会经过逆ROI pool操作,被汇集到predicat特征的空间调色板上,以便产生空间感知的object特征\hat{\mathbf{f}}_{o},它的尺寸与predicat特征\mathbf{f}_P。注意,\hat{\mathbf{f}}_{o}中相对objectROI之外的区域都被设置为0。空间重现的局部特征\hat{\mathbf{f}}_{o}可以影响全局特征图\mathbf{f}_p的感受野区域。逆ROI可以视为传统ROI的逆操作,就像自上而下的反卷积和自下而上的卷积。
- 在SCA-M中,有三个 Contrastive ROI pool单元用于聚合特征对
subject-predicate,subject-object和predicat-object,如图3中的b-d所示。通过多个卷积层,subject和object的特征在空间融合到predicate中,以增强表示能力。
- 在SCA-M中,有三个 Contrastive ROI pool单元用于聚合特征对
- Pyramid ROI Pooling: 表示为一对<ROI, ROI>操作,用于传递全局预测特征到subject和object分支的局部特征。如图3中的a和e。
- Contrastive ROI Pooling: 表示为一对<ROI,逆ROI>操作。object的特征\mathbf{f}_o首先经过ROI pool操作,提取归一化局部特征,然后这些特征会经过逆ROI pool操作,被汇集到predicat特征的空间调色板上,以便产生空间感知的object特征\hat{\mathbf{f}}_{o},它的尺寸与predicat特征\mathbf{f}_P。注意,\hat{\mathbf{f}}_{o}中相对objectROI之外的区域都被设置为0。空间重现的局部特征\hat{\mathbf{f}}_{o}可以影响全局特征图\mathbf{f}_p的感受野区域。逆ROI可以视为传统ROI的逆操作,就像自上而下的反卷积和自下而上的卷积。

zoom-net: stacked SCA-M
通过堆叠多个SCA-M层,提出的ZooM-Net能够通过动态的上下文和空间信息聚合来捕捉多尺度的特征相互作用。
在经过模型之后,每个分支互动增强过的特征被送入全连接层,去对subject, predicate和object进行分类。
hierarcghical relation classification
视觉关系检测并非一个简单的任务:
- Variety: 目标种类非常多,关系种类也是
- Ambiguity: 一些object种类的外观非常相似
- Imbalance: 长尾分布
为了解决上述问题,一般的方法是对数据进行清洗。作者提出构建两个层次结构内树,用于测量object和predicate类内的关联性。

