Java进阶专题(十八) 系统缓存架构设计 (下)
前言
上章节介绍了Redis相关知识,了解了Redis的高可用,高性能的原因。很多人认为提到缓存,就局限于Redis,其实缓存的应用不仅仅在于Redis的使用,比如还有Nginx缓存,缓存队列等等。这章节我们会将讲解Nginx+Lua实现多级缓存方法,来解决高并发访问的场景。
缓存的应用
我们来看一张微服务架构缓存的使用
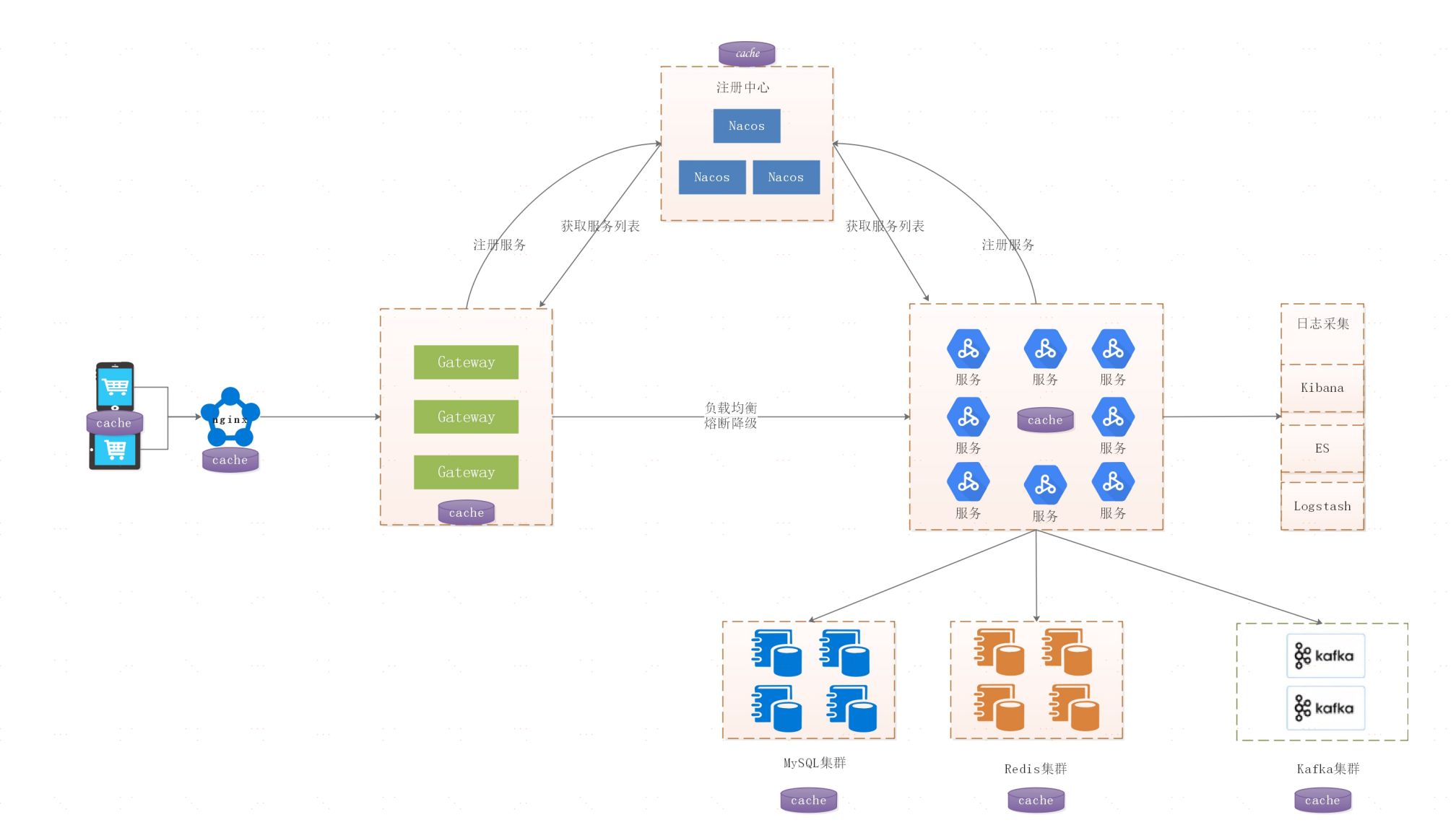
我们可以看到微服务架构中,会大量使用到缓存
1.客户端缓存(手机、PC)
2.Nginx缓存
3.微服务网关限流令牌缓存
4.Nacos缓存服务列表、配置文件
5.各大微服务自身也具有缓存
6.数据库查询Query Cache
7.Redis集群缓存
8.Kafka也属于缓存
高并发站点缓存技术选型
应对高并发的最有效手段之一就是分布式缓存,分布式缓存不仅仅是缓存要显示的数据这么简单,还可以在限流、队列削峰、高速读写、分布式锁等场景发挥重大作用。分布式缓存可以说是解决高并发场景的有效利器。以以下场景为例:
1、凌晨突然涌入的巨大流量。【队列术】【限流术】
2、高并发场景秒杀、抢红包、抢优惠券,快速存取。【缓存取代MySQL操作】
3、高并发场景超卖、超额抢红包。【Redis单线程取代数据库操作】
4、高并发场景重复抢单。【Redis抢单计数器】
一谈到缓存架构,很多人想到的是Redis,但其实整套体系的缓存架构并非只有Redis,而应该是多个层面多个软
件结合形成一套非常良性的缓存体系。比如咱们的缓存架构设计就涉及到了多个层面的缓存软件。
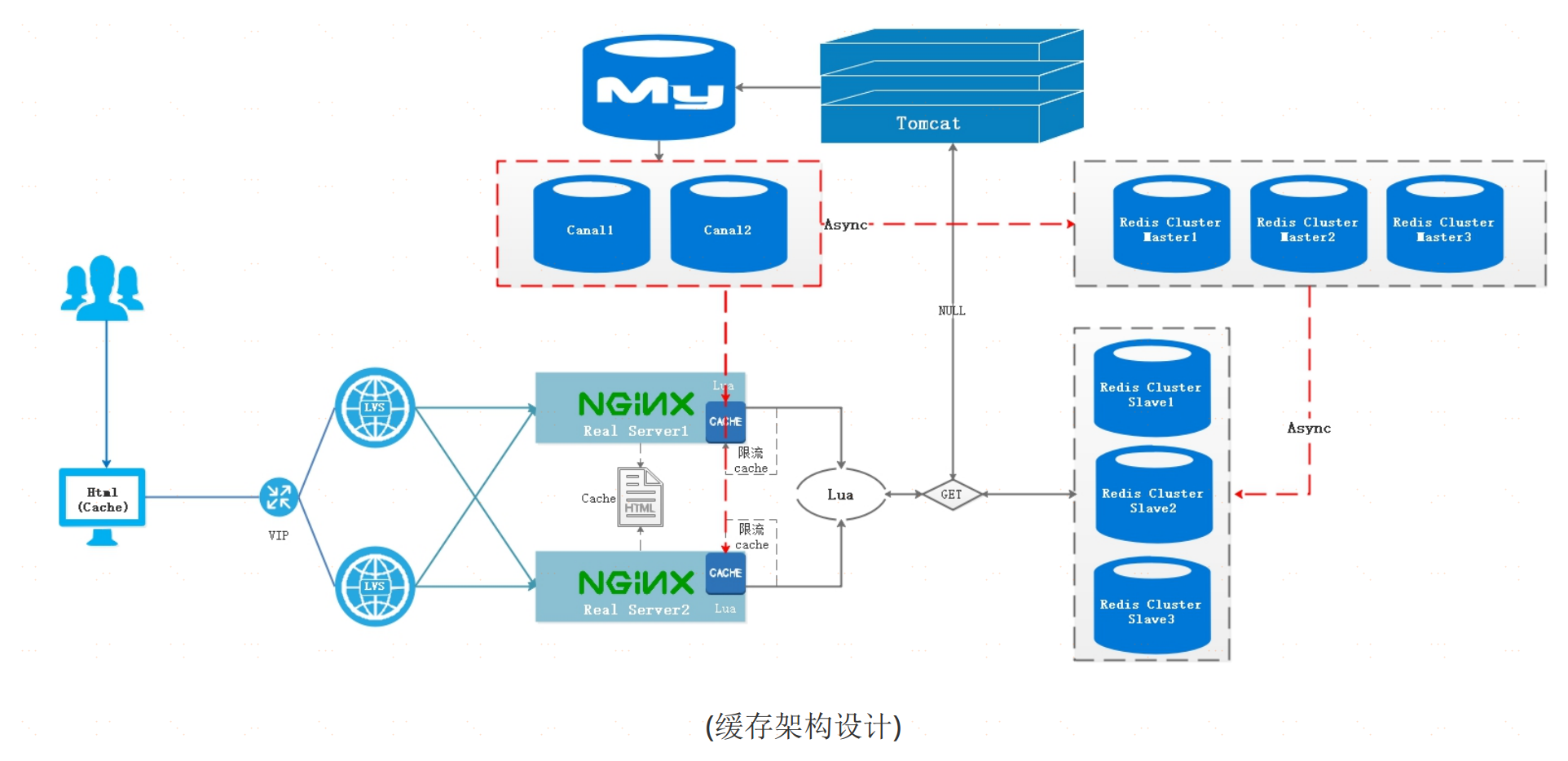
1、HTML页面做缓存,浏览器端可以缓存HTML页面和其他静态资源,防止用户频繁刷新对后端造成巨大压力
2、Lvs实现记录不同协议以及不同用户请求链路缓存
3、Nginx这里会做HTML页面缓存配置以及Nginx自身缓存配置
4、数据查找这里用Lua取代了其他语言查找,提高了处理的性能效率,并发处理能力将大大提升
5、数据缓存采用了Redis集群+主从架构,并实现缓存读写分离操作
6、集成Canal实现数据库数据增量实时同步Redis
Nginx缓存
浏览器缓存
客户端侧缓存一般指的是浏览器缓存、app缓存等等,目的就是加速各种静态资源的访问,降低服务器压力。我们通过配置Nginx设置网页缓存信息,从而降低用户对服务器频繁访问造成的巨大压力。

HTTP 中最基本的缓存机制,涉及到的 HTTP 头字段,包括 Cache‐Control, Last‐Modified, If‐Modified‐Since,
Etag,If‐None‐Match 等。
Last‐Modified/If‐Modified‐Since
Etag是服务端的一个资源的标识,在 HTTP 响应头中将其传送到客户端。所谓的服务端资源可以是一个Web页面,也可
以是JSON或XML等。服务器单独负责判断记号是什么及其含义,并在HTTP响应头中将其传送到客户端。比如,浏览器第
一次请求一个资源的时候,服务端给予返回,并且返回了ETag: "50b1c1d4f775c61:df3" 这样的字样给浏览器,当浏
览器再次请求这个资源的时候,浏览器会将If‐None‐Match: W/"50b1c1d4f775c61:df3" 传输给服务端,服务端拿到
该ETAG,对比资源是否发生变化,如果资源未发生改变,则返回304HTTP状态码,不返回具体的资源。
Last‐Modified :标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
If‐Modified‐Since :当资源过期时(使用Cache‐Control标识的max‐age),发现资源具有 Last‐Modified 声
明,则再次向web服务器请求时带上头。
If‐Modified‐Since ,表示请求时间。web服务器收到请求后发现有头 If‐Modified‐Since 则与被请求资源的最后修
改时间进行比对。若最后修改时间较新,说明资源有被改动过,则响应整片资源内容(写在响应消息包体内),HTTP
200;若最后修改时间较旧,说明资源无新修改,则响应 HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保
存的 cache 。
Pragma行是为了兼容 HTTP1.0 ,作用与 Cache‐Control: no‐cache 是一样的
Etag/If‐None‐Match
Etag :web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定),如果给定URL中的
资源修改,则一定要生成新的Etag值。
If‐None‐Match :当资源过期时(使用Cache‐Control标识的max‐age),发现资源具有Etage声明,则再次向web服
务器请求时带上头 If‐None‐Match (Etag的值)。web服务器收到请求后发现有头 If‐None‐Match 则与被请求资源
的相应校验串进行比对,决定返回200或304。
Etag:
Last‐Modified 标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文
件的修改时间,如果某些文件会被定期生成,当有时内容并没有任何变化,但 Last‐Modified 却改变了,导致文件没
法使用缓存有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形 Etag是服务器自动生成
或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。 Last‐Modified 与 ETag 是可以
一起使用的,服务器会优先验证 ETag ,一致的情况下,才会继续比对 Last‐Modified ,最后才决定是否返回304。
代理缓存

用户如果请求获取的数据不是需要后端服务器处理返回,如果我们需要对数据做缓存来提高服务器的处理能力,我们可以按照如下步骤实现:
1、请求Nginx,Nginx将请求路由给后端服务
2、后端服务查询Redis或者MySQL,再将返回结果给Nginx
3、Nginx将结果存入到Nginx缓存,并将结果返回给用户
4、用户下次执行同样请求,直接在Nginx中获取缓存数据
多级缓存架构
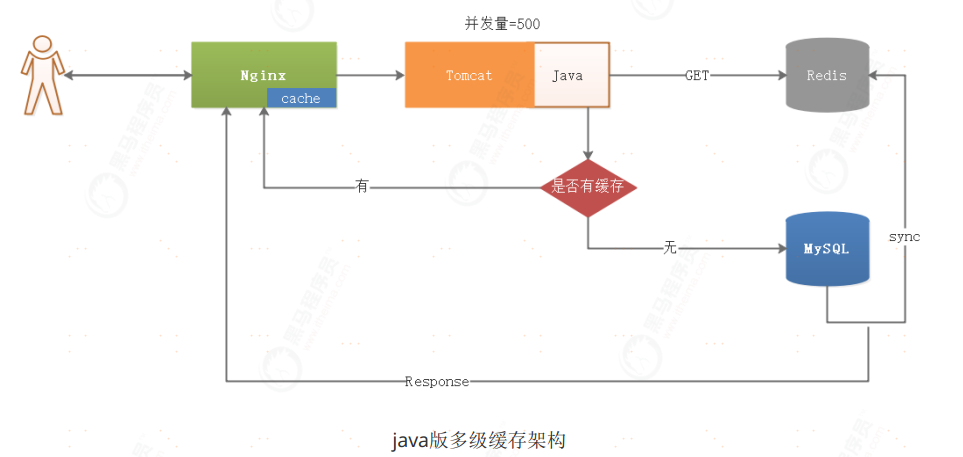
具体流程
1、用户请求经过Nginx
2、Nginx检查是否有缓存,如果Nginx有缓存,直接响应用户数据
3、Nginx如果没有缓存,则将请求路由给后端Java服务
4、Java服务查询Redis缓存,如果有数据,则将数据直接响应给Nginx,并将数据存入缓存,Nginx将数据响应给用户
5、如果Redis没有缓存,则使用Java程序查询MySQL,并将数据存入到Reids,再将数据存入到Nginx中
优缺点
优点:
1、采用了Nginx缓存,减少了数据加载的路径,从而提升站点数据加载效率
2、多级缓存有效防止了缓存击穿、缓存穿透问题
缺点
Tomcat并发量偏低,导致缓存同步并发量失衡,缓存首次加载效率偏低,Tomcat 大规模集群占用资源高
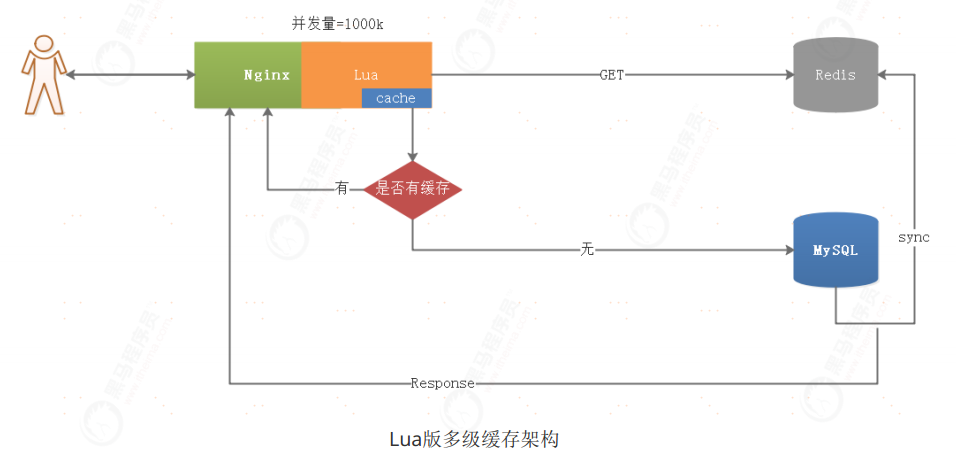
优点
1、采用了Nginx缓存,减少了数据加载的路径,从而提升站点数据加载效率
2、多级缓存有效防止了缓存击穿、缓存穿透问题
3、使用了Nginx+Lua集成,无论是哪次缓存加载,效率都高
4、Nginx并发量高,Nginx+Lua集成,大幅提升了并发能力
抢红包案例架构设计分享
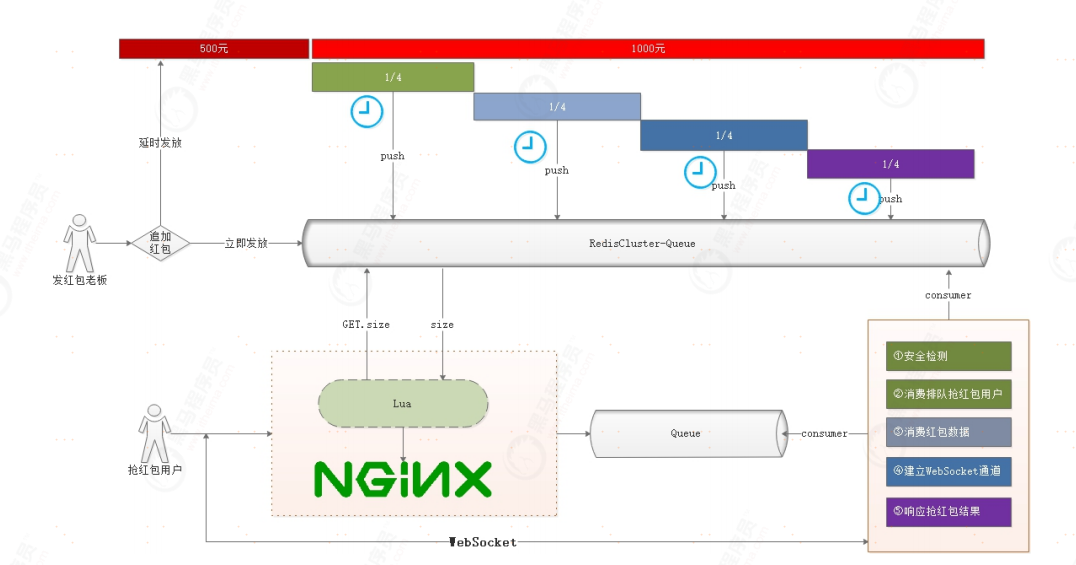
上面我们已经分析过红包雨的特点,要想实现一套高效的红包雨系统,缓存架构是关键。我们根据红包雨的特点设计了如上图所示的红包雨缓存架构体系。
1、红包雨分批次导入到Redis缓存而不要每次操作数据库
2、很多用户抢红包的时候,为了避免1个红包被多人抢到,我们要采用Redis的队列存储红包
3、追加红包的时候,可以追加延时发放红包,也可以直接追加立即发放红包
4、用户抢购红包的时候,会先经过Nginx,通过Lua脚本查看缓存中是否存在红包,如果不存在红包,则直接终止抢红包
5、如果还存在红包,为了避免后台同时处理很多请求,这里采用队列术缓存用户请求,后端通过消费队列执行抢红包
缓存队列使用场景
1、队列控制并发溢出:并发量非常大的系统,例如秒杀、抢红包、抢票等操作,都是存在溢出现象,比如秒杀超卖、抢红包超额、一票多单等溢出现象,如果采用数据库锁来控制溢出问题,效率非常低,在高并发场景下,很有可能直接导致数据库崩溃,因此针对高并发场景下数据溢出解决方案我们可以采用Redis缓存提升效率。
2、队列限流:解决大量并发用户蜂拥而上的方法可以采用队列术将用户的请求用队列缓存起来,后端服务从队列缓存中有序消费,可以防止后端服务同时面临处理大量请求。缓存用户请求可以用RabbitMQ、Kafka、RocketMQ、ActiveMQ等。用户抢红包的时候,我们用Lua脚本实现将用户抢红包的信息以生产者角色将消息发给RabbitMQ,后端应用服务以消费者身份从RabbitMQ获取消息并抢红包,再将抢红包信息以WebSocket方式通知给用户。
Nginx限流
nginx提供两种限流的方式:一是控制速率,二是控制并发连接数。
1、速率限流
控制速率的方式之一就是采用漏桶算法。具体配置如下:
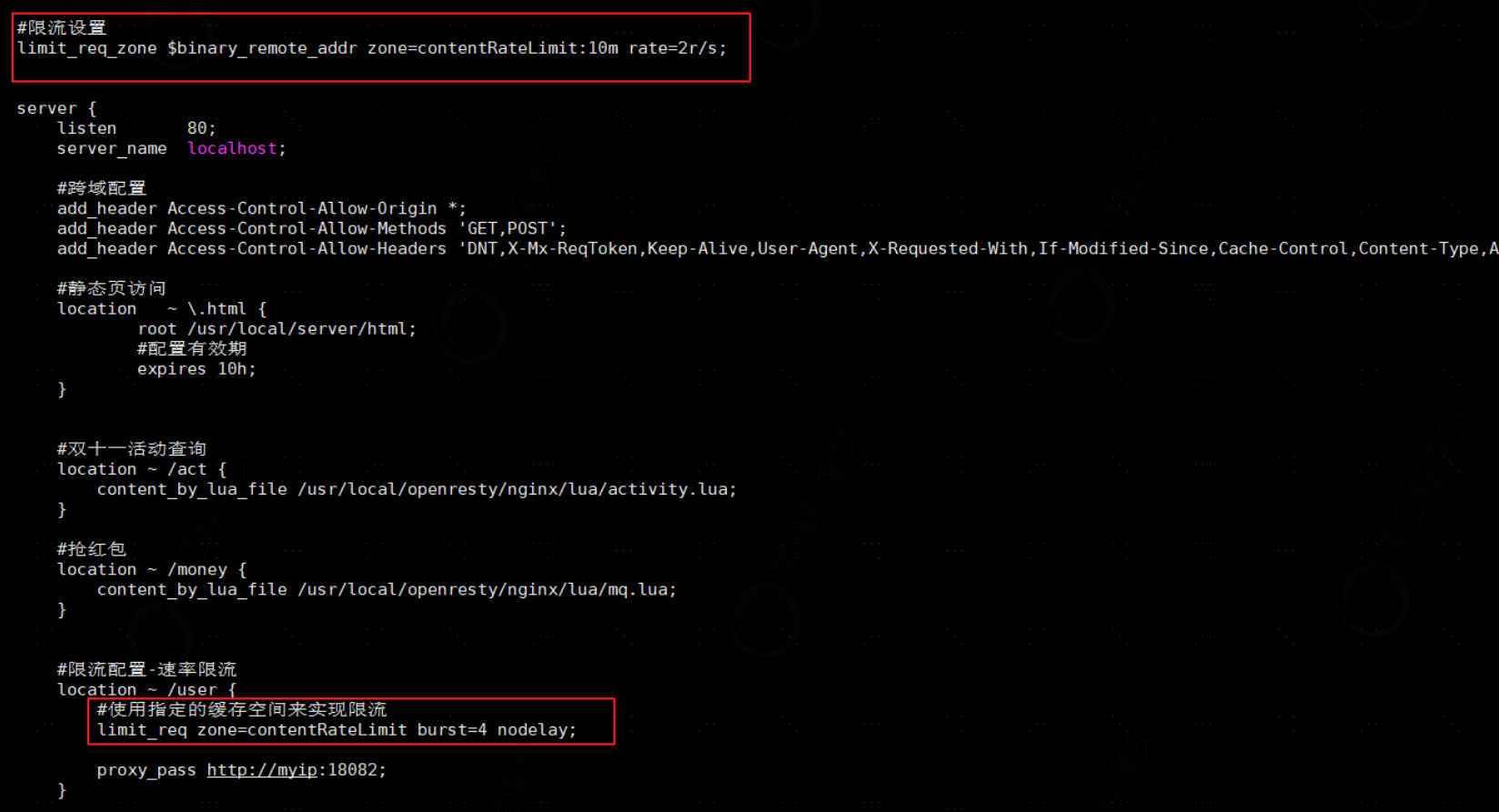
2、控制并发量
ngx_http_limit_conn_module 提供了限制连接数的能力。主要是利用limit_conn_zone和limit_conn两个指令。利用连接数限制 某一个用户的ip连接的数量来控制流量。
(1)配置限制固定连接数
如下,配置如下:
配置限流缓存空间:
根据IP地址来限制,存储内存大小10M
limit_conn_zone $binary_remote_addr zone=addr:1m;
location配置:
limit_conn addr 2;
参数说明:
limit_conn_zone $binary_remote_addr zone=addr:10m; 表示限制根据用户的IP地址来显示,设置存储地址为的
内存大小10M
limit_conn addr 2; 表示 同一个地址只允许连接2次。
(2)限制每个客户端IP与服务器的连接数,同时限制与虚拟服务器的连接总数。
限流缓存空间配置:
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
location配置
limit_conn perip 10;#单个客户端ip与服务器的连接数
limit_conn perserver 100; #限制与服务器的总连接数
每个IP限流 3个
总量5个
缓存灾难问题如何解决
缓存穿透
产生原因
当我们查询一个缓存不存在的数据,就去查数据库,但此时如果数据库也没有这个数据,后面继续访问依然会再次查询数据库,当有用户大量请求不存在的数据,必然会导致数据库的压力升高,甚至崩溃。
如何解决
1、当查询到不存在的数据,也将对应的key放入缓存,值为nul,这样再次查询会直接返回null,如果后面新增了该key的数据,就覆盖即可。
2、使用布隆过滤器。布隆过滤器主要是解决大规模数据下不需要精确过滤的业务场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等。
缓存击穿
产生原因
当缓存在某一刻过期了,一般如果再查询这个缓存,会从数据库去查询一次再放到缓存,如果正好这一刻,大量的请求该缓存,那么请求都会打到数据库中,可能导致数据库打垮。
如何解决
1、尽量避免缓存过期时间都在同一时间。
2、定时任务主动刷新更新缓存,或者设置缓存不过去,适合那种key相对固定,粒度较大的业务。
分享下我在公司的负责的系统是如何防止缓存击穿的,由于业务场景,缓存的数据都是当天有效的,当天查询的只查当日有效的数据,所以当时数据都是设置当天凌晨过期,并且缓存是懒加载,这样导致0点高峰期数据库压力明显增大。后来改造了下,做了个定时任务,每天凌晨3点,跑第二天生效的数据,并且设置失效时间延长一天。有效解决了该问题,相当于缓存预热。
3、多级缓存
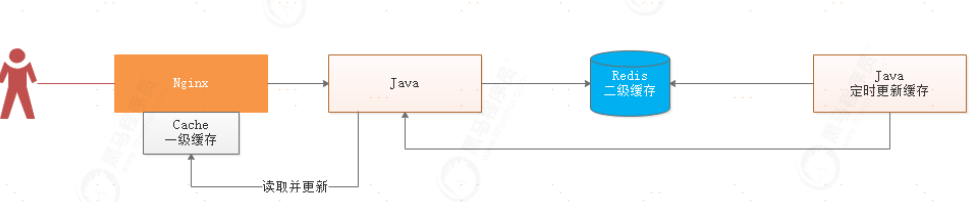
采用多级缓存也可以有效防止击穿现象,首先通过程序将缓存存入到Redis缓存,且永不过期,用户查询的时候,先查询Nginx缓存,如果Nginx缓存没有,则查询Redis缓存,并将Redis缓存存入到Nginx一级缓存中,并设置更新时间。这种方案不仅可以提升查询速度,同时又能防止击穿问题,并且提升了程序的抗压能力。
4、分布式锁与队列。解决思路主要是防止多请求同时打过去。分布式锁,推荐使用Redisson。队列方案可以使用nginx缓存队列,配置如下。
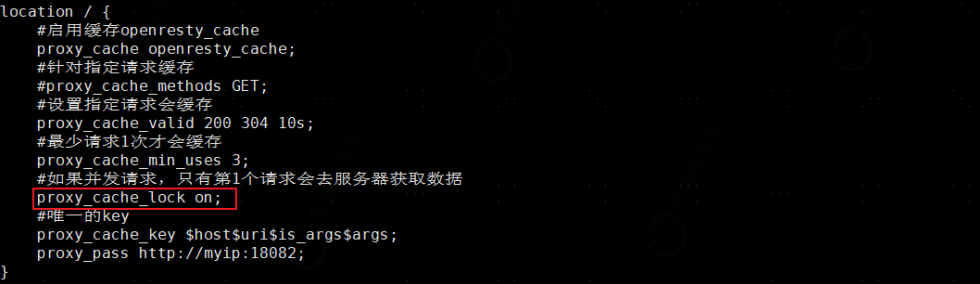
缓存雪崩
产生原因
缓存雪崩是指,由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服
务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
如何解决
1、做缓存集群。即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,比如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
2、做好限流。微服务网关或者Nginx做好限流操作,防止大量请求直接进入后端,使后端载荷过重最后宕机。
3、缓存预热。预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀,不要同时失效。
4、加锁。数据操作,如果是带有缓存查询的,均使用分布式锁,防止大量请求直接操作数据库。
5、多级缓存。采用多级缓存,Nginx+Redis+MyBatis二级缓存,当Nginx缓存失效时,查找Redis缓存,Redis缓存失效查找MyBatis二级缓存。
缓存一致性
问题描述
数据的在增量数据,未同步到缓存。导致缓存与数据库数据不一致。
解决方案Canal
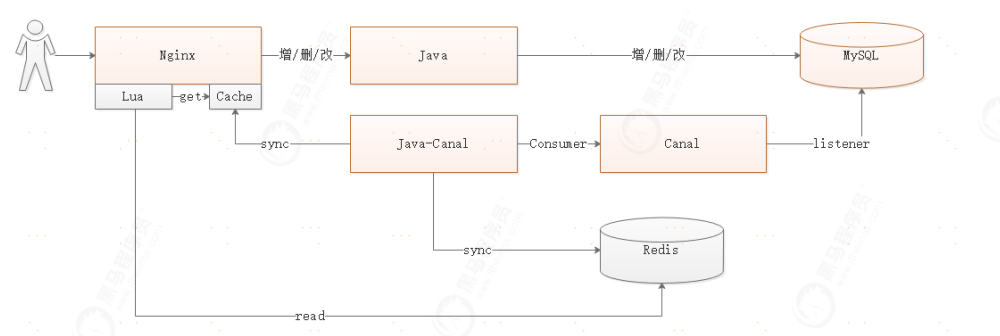
用户每次操作数据库的时候,使用Canal监听数据库指定表的增量变化,在Java程序中消费Canal监听到的增量变化,并在Java程序中实现对Redis缓存或者Nginx缓存的更新。
用户查询的时候,先通过Lua查询Nginx的缓存,如果Nginx缓存没有数据,则查询Redis缓存,Redis缓存如果也没有数据,可以去数据库查询。


