InnoDB 中的缓冲池(Buffer Pool)
本文主要说明 InnoDB Buffer Pool 的内部执行原理,其生效的前提是使用到了索引,如果没有用到索引会进行全表扫描。
结构
在 InnoDB 存储引擎层维护着一个缓冲池,通过其可以避免对磁盘频繁的IO操作。下面是其内部结构的概要图(实际没有这么简单,本文只着重说一下它的“读”、“写”缓存)。其本质就是将磁盘上的数据页移到内存中,以此来减少对磁盘数据的直接IO。
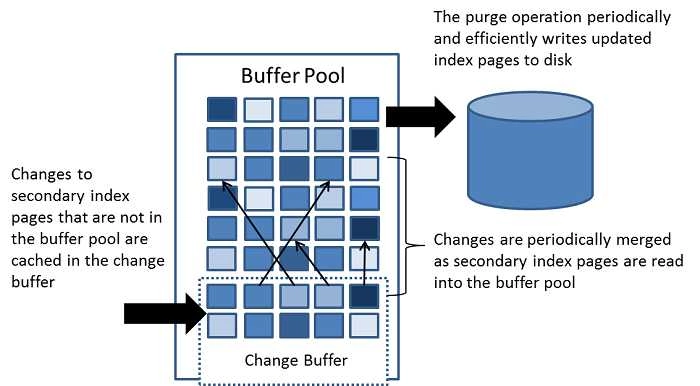
可以看到内部含有一个小区域,叫做 Change Buffer,这个是用 InnoDB 的 “写”缓存,而外面的是 InnoDB 的 “读”缓存。
读缓存
预读
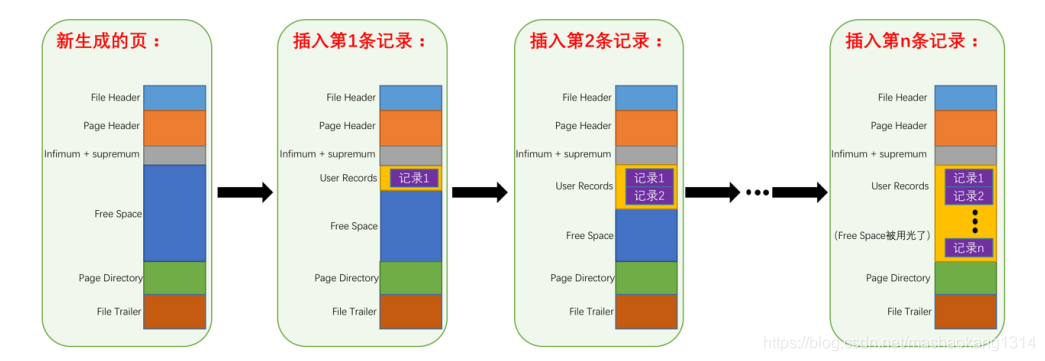
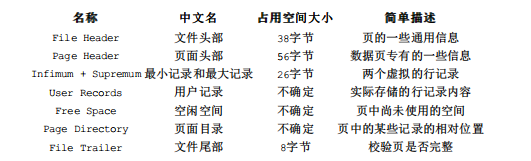
MySQL 在磁盘上读取数据时,一般都会使用缓冲池,而如果多次语句操作的是相邻的记录,那么就会多次进行磁盘读取,导致速度降低,所以 MySQL 一般在读取数据时都是采用预读方式,读取指定数据周围的多条数据。而在 InnoDB 引擎中的数据是以页为单位进行存储的,并且提出了“数据页”概念。数据页的结构如下,大小默认为 16K,关于数据页这里就不过多阐述,感兴趣可以查看原博客。对硬盘上的数据读取最小单位就是数据页。
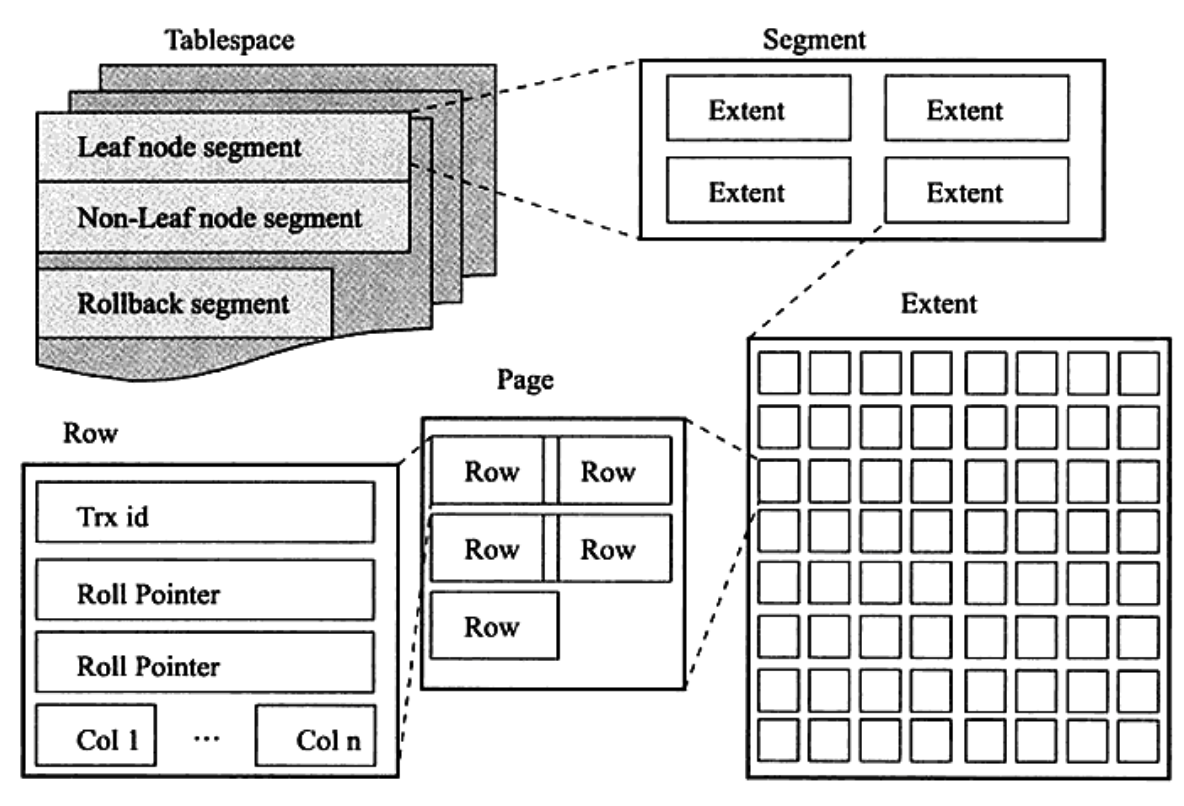
而在数据页上面,还分为区(Extent)、段(Segment)、表空间(Tablespace),它们之间的包含关系如下图。具体可以查看原博客。
InnoDB 引擎在预读时, 有两种预读算法。线性预读和随机预读。
1、线性预读(innodb_read_ahead_threshold)
选择是否预读下一个 Extent 的数据。有一个重要的参数 innodb_read_ahead_threshold,如果当前 Extent 中连续读取的数据页超过规定值,就会将下一个 Extent 的数据也读到缓冲池中。innodb_read_ahead_threshold 的范围是 0-64(因为一个 Extent 也就64页)。
2、随机预读(innodb_random_read_ahead)
用来设置是否将当前 Extent 的剩余页也预读到缓冲池中,由于这种预读性能不稳定,所以MySQL 5.5开始默认关闭。
缓冲池的LRU算法
InnoDB 的缓冲池数据的存储算法是改进版的 LRU 算法,以此来避免了传统 LRU 算法的两个问题,预读失效和缓冲池污染。
LRU 算法简单来说,如果用链表来实现,将最近命中(加载)的数据页移在头部,未使用的向后偏移,直至移除链表。这样的淘汰算法就叫做 LRU 算法。但是其会含有前面说得两个问题。
1、预读失效
在磁盘上读取数据时,可能会因为操作不当导致多个用不到的数据页加载到缓冲池。从而导致之前经常被使用的数据页缓存被无用的数据页挤到尾部,甚至被移出缓存,那么就会降低性能。而 InnoDB 的解决方案是将缓冲池分为两部分,新生代和老年代,比例默认为5:3,分别存储常用的数据页以及不常用的数据页,新生代位于头部,新生代位于尾部,这两部分都有头部和尾部。当从磁盘的数据页移入缓冲池中时,首先是放入老年代的头部,然后进行筛选,使用到的数据页会移入新生代的头部,未使用的数据页会随着时间流逝而慢慢移入老年代的尾部,直至淘汰。
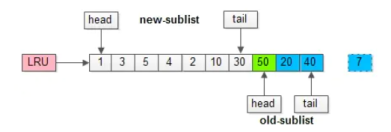
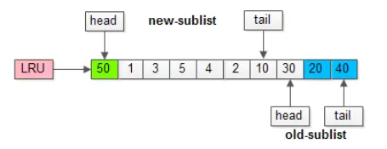
2、缓冲池污染。
在处理数据页时,如果需要对大量数据页进行筛选(但是没有用到),那么还是会使大量的热点数据页被挤出。如 select * from student where name like ‘张%’;name字段包含索引,那么在执行时虽然会先加载到老年代的头部,但是因为每条数据都需要筛选,所以都会移入新生代头部,导致新生代热点数据页被挤到老年代甚至移除。InnoDB 为了解决这个问题,使用了 “老年代停留时间窗口” 机制,这个机制是设置一个时间,如果在老年代的数据页被调用后还需要去检查它在老年代的停留时间是否达到了这个规定时间,达到了才能移入新生代头部,否则只会移到老年代头部。
写缓存(Change Buffer)
写缓存(Change Buffer)在5.5之前叫做 插入缓存(insert Buffer),因为只支持插入的缓存,在随后版本又添加了 update、delete,所以改名 change Buffer。因为直接对磁盘进行IO操作会比较耗时,如果我们的程序在高并发的场景,同时某段时间写操作非常多,那么如果直接更新到磁盘上数据库的压力就会非常大,甚至崩溃。为了避免这种情况,可以错开高峰期,让数据在系统空闲时再更新到磁盘,那么该如何实现,Change Buffer就起到这样的作用。
执行
在更新语句进来时,首先会判断数据页缓存中有没有对应的数据,如果有直接更新对应的缓存数据,否则将其记录在 Change Buffer 中。随后(前面是哪种情况)再将这条sql依次写入 redo log、bin log(Server 层的日志,所有执行引擎都可以用,而 redo log 是InnoDB内部维护的,binlog 一般用于主从复制数据更新)。
redo log落盘的时机
将日志中的sql更新到硬盘上的操作叫做“落盘(merge)”。
1、mysql系统后台会定期落盘
2、查询 redo log中sql操作过的数据时需要先落盘
3、mysql 正常关闭时
Change Buffer 适用场景
1、更新后立刻需要读取该数据场景少。因为读取更新过的数据需要先落盘,那么 Change Buffer 存在的意义就没有了,同时还增加了redo log 写入的成本。
2、非唯一索引,如果使用的是唯一索引进行查询,那么操作的数据需要进行唯一性检查,所以需要将相应数据页先加载到缓冲池中,然后再判断,更新,过程中不会用到 Change Buffer。
写入redo log不也是磁盘数据IO么?为什么就比直接更新到磁盘上效率高?
使用 redo log 只是将操作存储进去,而更新到磁盘数据则是需要先读操作查找 B+ 树,找到数据后再进行写操作。
相关参数
Buffer Pool :
1、innodb_buffer_pool_size:缓冲池大小,在内存足够的条件下,越大越好。
2、innodb_old_blocks_pct:老年代占整个LRU链长度的比例,默认是37,即整个LRU的新生代和老年代长度比例是63:37。(如果配置是100就变成普通的LRU了)
3、innodb_old_blocks_time:老年代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老年代停留时间超过1秒”两个条件,才会被插入到新生代头部。
Change Buffer:
1、innodb_change_buffer_max_size:
配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
画外音:写多读少的业务,才需要调大这个值,读多写少的业务,25%其实也多了。
2、innodb_change_buffering:
介绍:配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
参考文献:
//blog.csdn.net/mashaokang1314/article/details/109716569
//blog.csdn.net/fu_zhongyuan/article/details/90244503
//www.cnblogs.com/geaozhang/p/7397699.html
//www.cnblogs.com/virgosnail/p/10454150.html

