【云原生下离在线混部实践系列】深入浅出 Google Borg
Google Borg 是资源调度管理和离在线混部领域的鼻祖,同时也是 Kubernetes 的起源与参照,已成为从业人员首要学习的典范。本文尝试管中窥豹,简单从《Large-scale cluster management at Google with Borg》一文中剖析 Google Borg 的设计理念和功能特点,用以抛砖引玉。
Google Borg 是什么?
Google Borg 是 Google 内部自研的一套资源管理系统,用于集群资源管控、分配和调度等。在 Borg 中,资源的单位是 Job 和 Task。Job 包含一组 Task。Task 是 Borg 管理和调度的最小单元,它对应一组 Linux 进程。熟悉 Kubernetes 的读者,可以将 Job 和 Task 大致对应为 Kubernetes 的 Service 和 Pod。
在架构上,Borg 和 Kubernetes 类似,由 BorgMaster、Scheduler 和 Borglet 组成。
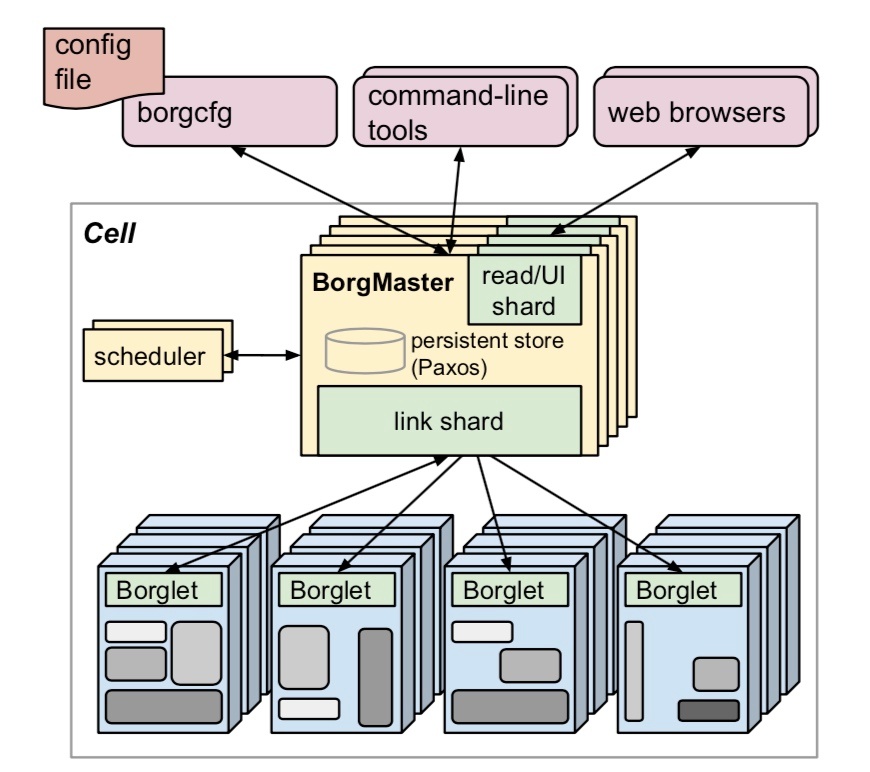
Borg Allocs
Borg Alloc 代表一组可用于运行 Task 的资源,如 CPU、内存、IO 和磁盘空间。它实际上是集群对物理资源的抽象。Alloc set 类似 Job,是一堆 Alloc 的集合。当一个 Alloc set 被创建时,一个或多个 Job 就可以运行在上面了。
Priority 和 Quota
每个 Job 都可以设置 Priority。Priority 可用于标识 Job 的重要程度,并影响一些资源分配、调度和 Preemption 策略。比如在生产中,我们会将作业分为 Routine Job 和 Batch Job。Routine Job 为生产级的例行作业,优先级最高,它占用对应实际物理资源的 Alloc set。Batch Job 代表一些临时作业,优先级最低。当资源紧张时,集群会优先 Preempt Batch Job,将资源提供给 Routine Job 使用。这时 Preempted Batch Job 会回到调度队列等待重新调度。
Quota 代表资源配额,它约束 Job 的可用资源,比如 CPU、内存或磁盘。Quota 一般在调度之前进行检查。Job 若不满足,会立即在提交时被拒绝。生产中,我们一般依据实际物理资源配置 Routine Job Quota。这种方式可以确保 Routine Job 在 Quota 内一定有可用的资源。为了充分提升集群资源使用率,我们会将 Batch Job Quota 设置为无限,让它尽量去占用 Routine Job 的闲置资源,从而实现超卖。这方面内容后面会在再次详述。
Schedule
调度是资源管理系统的核心功能,它直接决定了系统的“好坏”。在 Borg 中,Job 被提交后,Borgmaster 会将其放入一个 Pending Queue。Scheduler 异步地扫描队列,将 Task 调度到有充足资源的机器上。
通常情况下,调度过程分为两个步骤:Filter 和 Score。
-
Filter,或是 Feasibility Checking,用于判断机器是否满足 Task 的约束和限制,比如 Schedule Preference、Affinity 或 Resource Limit。
-
Filter 结束后,就需要 Score 符合要求的机器,或称为 Weight。上述两个步骤完成后,Scheduler 就会挑选相应数量的机器调度给 Task 运行。实际上,选择合适的调度策略尤为重要。
这里可以拿一个我们生产遇到的调度问题举例。
生产初期,我们的调度系统采用的 Score 策略类似 Borg E-PVM,它的作用是将 Task 尽量均匀的调度到整个集群上。从正面效果上讲,这种策略分散了 Task 负载,并在一定程度上缩小了故障域。但从反面看,它也引发了资源碎片化的问题。由于我们底层环境是异构的,机器配置并不统一,并且 Task 配置和物理配置并无对应关系。这就造成一些配置过大的 Task 无法运行,由此在一定程度上降低了资源的分配率和使用率。
为了应付此类问题,我们自研了新的 Score 策略,称之为 “Best Fillup”。它的原理是在调度 Task 时选择可用资源最少的机器,也就是尽量填满。不过这种策略的缺点显而易见:单台机器的负载会升高,从而增加 Bursty Load 的风险;不利于 Batch Job 运行;故障域会增加。
本篇论文作者采用了一种被称为 hybrid 的方式,据称比第一种策略增加 3-5% 的效率。
Utilization
资源管理系统的首要目标是提高资源使用率,Borg 亦是如此。不过由于过多的前置条件,诸如 Job 放置约束、负载尖峰、多样的机器配置和 Batch Job,导致不能仅选择 “average utilization” 作为策略指标。在Borg中,使用Cell Compaction 作为评判基准。简述之就是:能承载给定负载的最小 Cell。
Borg 提供了一些提高 utilization 的思路和实践方法,有些是我们在生产中已经采用的,有些则非常值得我们学习和借鉴。
Cell Sharing
Borg 发现,将各种优先级的 Task,比如 prod 和 non-prod 运行在共享的 Cell 中可以大幅度的提升资源利用率。
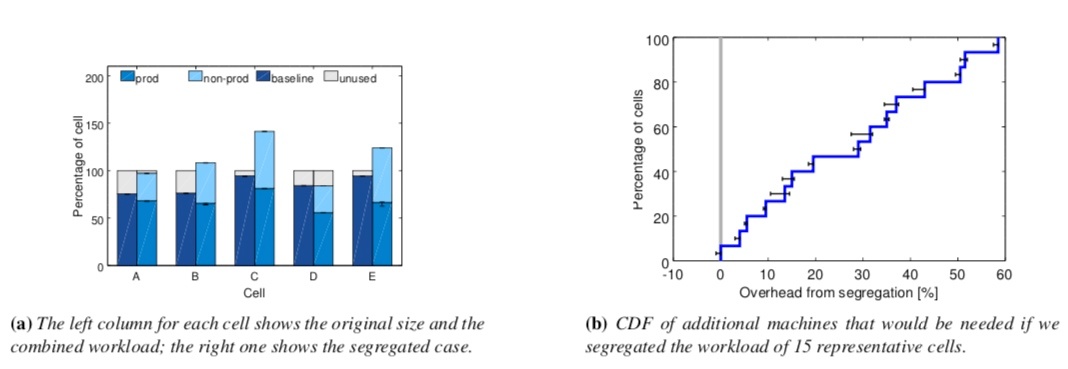
上面(a)图表明,采用 Task 隔离的部署方式会增加对机器的需求。图(b)是对额外机器需求的分布函数。图(a)和图(b)都清楚的表明了将 prod Job 和 non-prod Job 分开部署会消耗更多的物理资源。Borg 的经验是大约会新增 20-30% 左右。
个中原理也很好理解:prod Job 通常会为应对负载尖峰申请较大资源,实际上这部分资源在多数时间里是闲置的。Borg 会定时回收这部分资源,并将之分配给 non-prod Job 使用。在 Kubernetes 中,对应的概念是 request limit 和 limit。我们在生产中,一般设置 Prod Job 的 Request limit 等于 limit,这样它就具有了最高的 Guaranteed Qos。该 QoS 使得 pod 在机器负载高时不至于被驱逐和 OOM。non-prod Job 则不设置 request limit 和 limit,这使得它具有 BestEffort 级别的 QoS。kubelet 会在资源负载高时优先驱逐此类 Pod。这样也达到了和 Borg 类似的效果。
Large cells
Borg 通过实验数据表明,小容量的 cell 通常比大容量的更占用物理资源。
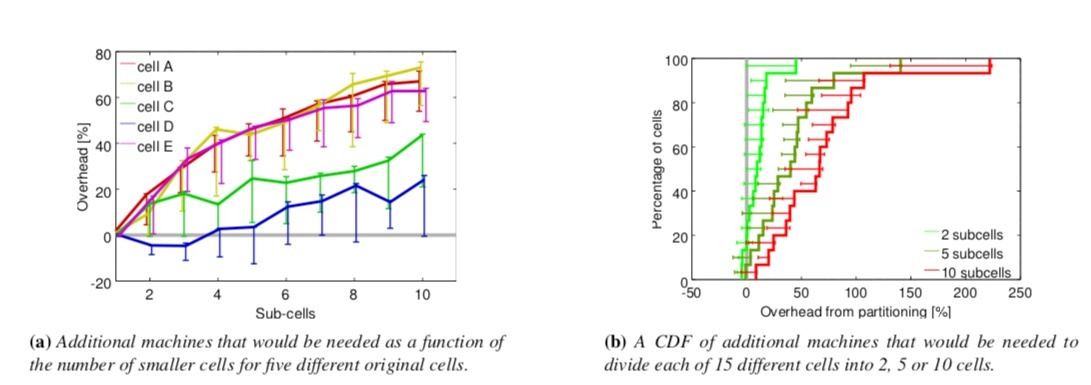
这点对我们有很重要的指导意义。通常情况下,我们会在设计集群时对容量问题感到犹豫不决。
显而易见,小集群可以带来更高的隔离性、更小的故障域以及潜在风险。但随之带来的则是管理和架构复杂度的增加,以及更多的故障点。
大集群的优缺点正好相反。在资源利用率这个指标上,我们凭直觉认为是大集群更优,但苦于无坚实的理论依据。Borg 的研究表明,大集群有利于增加资源利用率,这点对我们的决策很有帮助。
Fine-grained resource requests
Borg 对资源细粒度分配的方法,目前已是主流,在此就不再赘述。
Resource reclamation
了解 Kubernetes 的读者,应该对 resource request 和 limit,在 Google Borg 中概念类似。Job 在提交时需要指定 resource limit,它能确保内部的 Task 有足够资源可以运行。
有些用户会为 Task 申请过大的资源,以应对可能的请求或计算的突增。但实际上,部分资源在多数时间内是闲置的。与其资源浪费,不如利用起来。这需要系统有较精确的预测机制,可以评估 Task 对实际资源的需求,并将闲置资源回收以分配给低 priority 的任务,比如 Batch Job。
上述过程在 Borg 中被称为 resource reclamation,对使用资源的评估则被称为 reservation。Borgmaster 会定期从 Borglet 收集 resource consumption,并执行 reservation。在初始阶段,reservation 等于 resource limit。随着 Task 的运行,reservation 就变为了资源的实际使用量,外加 safety margin。
在 Borg 调度时,Scheduler 使用 resource limit 为 prod Task 过滤和选择主机,这个过程并不依赖 reclaimed resource。从这个角度看,并不支持对 prod Task 的资源超卖。但 non-prod Task 则不同,它是占用已有 Task 的 resource reservation。所以 non-prod Task 会被调度到拥有 reclaimed resource 的机器上。
这种做法当然也是有一定风险的。若资源评估出现偏差,机器上的可用资源可能会被耗尽。在这种情况下,Borg 会杀死或者降级 non-prod Task,prod Task 则不会受到任何影响。
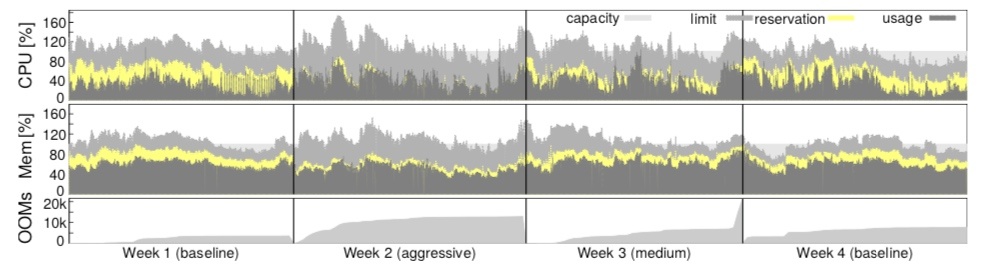
上图证实了这种策略的有效性。参照 Week 1 和 4 的 baseline,Week 2 和 3 在调整了 estimation algorithm 后,实际资源的 usage 与 reservation 的 gap 在显著缩小。在 Borg 的一个 median cell 中,有 20% 的负载是运行在 reclaimed resource 上。
相较于 Borg,Kubernetes 虽然有 resource limit 和 capacity 的概念,但却缺少动态 reclaim 机制。这会使得系统对低 priority Task 的资源缺少行之有效的评估机制,从而引发系统负载问题。这个功能对资源调度和提升资源使用率影响巨大。
Isolation
由于 Google Borg 天生就考虑混部场景,所以资源隔离对其尤为重要。在内部场景,Google Borg 多使用 Linux 隔离,比如 chroot、cgroup 等,类似容器隔离机制。公有云侧,Google Borg 则通过 VM 或沙箱技术实现 Task 间的强隔离。
在性能隔离方面,Google Borg 通过区分应用优先级的方式保证服务质量。latency-sensitive(LS) 高优任务拥有高的资源保证,Batch 低优任务占用资源则会根据需要被抑制。
在集群资源方面,Google Borg 将之分为可压缩和不可压缩资源。与流速相关的资源,诸如 CPU、磁盘 IO 等,被定义为可压缩资源。这部分资源若被耗尽,Borglet 会首先降级处理低优任务,而不是直接杀死。这种做法能最大程度保证低优任务服务质量。不可压缩资源,包括内存、磁盘空间等,在资源紧张时,任务会被按照优先级从低到高杀死,直到紧张情况缓解。
在内核层面,Google Borg 同样有策略保证资源隔离与复用。比如 LS 任务可独享物理 CPU 核心,其他 LS 任务不可复用。Batch 任务能共用这部分 CPU,通过设置低 cpus_share 的方式与 LS 任务隔离。Borget 也会周期性的调整 LS 任务,以避免 Batch 任务被饿死。为了支持高敏任务,Google Borg 对 CFS 做了增强,使之可根据 cgroup 负载预测提前抢占 Batch 任务,从而降低 CFS 调度延迟。
总结
离在线混合部署是一套复杂的系统和技术,需要从方法论、业务、应用、资源调度系统、操作系统等多个层面的实现和配合,并且也需要长期的实战和经验积累。Google Borg 作为 Google 内部的经验结晶,系统的阐述了混部应有的基本形态,很有启发意义。目前我们在腾讯内部也开发和上线了一套基于 Kubernetes 的离在线混合部署系统,支持动态资源预测、资源回收和内核级隔离。后续会持续分享混部相关的理论和实战经验。
参考资料
- Large-scale cluster management at Google with Borg://iwiki.oa.tencent.com/images/43438.pdfThe
- evolution of cluster scheduler architecture://www.firmament.io/blog/scheduler-architectures.html
- poseidon://github.com/kubernetes-sigs/poseidonPoseidon
- design://docs.google.com/document/d/1VNoaw1GoRK-yop_Oqzn7wZhxMxvN3pdNjuaICjXLarA/edit?usp=sharing
- firemament://github.com/camsas/firmament
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


