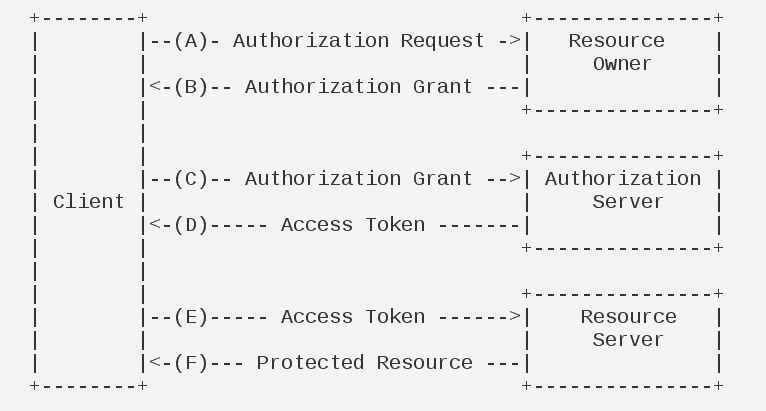
API 网关的选型和持续集成
- 2019 年 10 月 23 日
- 笔记
2019 年 8 月 31 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·成都站,APISIX 作者温铭在活动上做了《 API 网关的选型和持续集成 》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 中国社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。

温铭,深圳支流科技联合创始人,开源微服务 API 网关 APISIX PMC,OpenResty软件基金会发起人,《OpenResty 从入门到实战》专栏作者,创业之前在互联网安全公司工作了 10 年,主要从事服务端的开发和架构,负责开发过木马云查杀、反钓鱼系统和企业安全产品。曾在奇虎 360 担任架构师,开源委员会发起人、委员。
以下是分享全文:
我和院生在做的一个开源的 API 网关项目叫 APISIX,今天介绍这个项目涉及到 OpenResty 的技术和选型,主要包括三个方面:
- 第一, API 网关是什么,它有什么作用;
- 第二,如何去做 API 网关,如何做选型;
- 第三,APISIX 是一个开源项目,介绍我们在只有两个人的情况下是怎么去做测试和持续集成,里面会涉及 OpenResty 的一些通用的东西,值得大家借鉴。
API 网关的作用
什么是 API 网关

以 Kong 为例,左图没有 API 网关,但是后面挂了很多服务,如果每个服务都要实现包括认证、统计、安全校验等功能,会有很多重复的工作。API 网关的作用就是把这些公共的东西抽取出来,如右图,下面的这几个服务,每个服务都只关心自身业务相关的东西,和业务无关的东西全部都丢到API 网关上,即 API 网关就是把公共的东西如统计、安全、限流、限速、缓存等提取出来做了一个中间层。
API 网关的传统功能
- 让 API 请求更安全、更高效的得到处理。传统的 API 网关有一些基本的功能直到现在都适用的,管理不管南北向的还是东西向的 API 流量可以能够快速、安全地得到处理,这个是 API 网关最原始的目的。
- 覆盖 Nginx 的所有功能。API 的网关覆盖了 Nginx 的所有功能,包括反向代理、负载均衡以及基本的缓存、安全的认证、限流限速等。
- 支持 Nginx 等 Web 服务器实现不了的功能。如动态上游、动态 SSL 证书、动态限流限速,以及主动/被动健康检查、服务熔断等,这些动态的能力都是传统的 Nginx、Apache 这类Web 服务器支持不了的。
- 全生命周期管理。在 API 网关领域,最大的玩家是谷歌,谷歌在 2016 年收购了一家上市公司 Apigee,它现在把整个功能集成在谷歌云上。API 网关除了我们熟悉的反向代理、负载均衡、限流限速的插件外,它还包括了 API 的设计、文档以及测试等,这一整套都属于 API 网关的功能,我们叫做 API 的全生命周期管理,从项目设计到测试上线,所有的东西都在整个 API 网关的功能范畴内。
云原生下的新功能
为什么现在包括 Kong、APISIX 还要把传统的东西再做一遍呢?这是因为在云原生和微服务体系下,用户和技术架构有了一些新的变化:
技术架构新变化
- 需要对接云原生里面像 Prometheus、Zipkin、Skywalking 等重要组件;
- gRPC 代理和协议转换(REST<=>gRPC):HTTP 这种协议在微服务里面用的越来越少,很多人开始用 gRPC,那在从 HTTP 到 gRPC 协议的转换,这种功能也是需要的,包括 gRPC 的代理;
- 身份认证方式改变:在传统的 Nginx 里面,一般是流量进来后根据路由的规则去做反向代理、负载均衡,很少对发流量的客户端的身份做认证。但是在云原生里面就不一样,因为很多是在微服务里的流量,这里面需要做严格的身份认证,包括加密、OpenID 之类的身份认证。这块就是一些新的功能,可以把自己企业里面需要做身份认证相关的东西放到第三方的外部认证的厂商去做;
- Serverless 也是最近几年非常火的一个概念,比如希望在边缘节点上面动态地把一个函数跑起来或者把一个函数给停掉,或者动态地去改里面的内容,你可以把你的 API 网关部署在边缘节点上,具备了这种 FaaS 的功能,你的边缘节点就会更加地灵活。APISIX 里面最近就支持了 Serverless,可以让你的一个 Lua 的函数动态地在边缘结点跑起来;
- 无状态、随意扩容和缩容:API 网关在十多年前性能要求没有那么高,因为当时互联网的流量更多地是从浏览器到服务端,没有手机和物联网的设备,也没有微服务、内网这些流量。但是现在的流量很大,包括 4G、5G下面有很多的手机、IoT 设备去访问服务端,流量特别地大。此时,就需要一个性能更高的 API 网关去做支撑。云原生的一个重要的标准是所有的服务都可以通过容器的方式随意地去扩容和缩容,对 Kubernetes 友好;
- 支持多云和混合云:现在上云已经是一个趋势,但是我们一般不太会把服务只放在一个云上,比如腾讯云、谷歌云、阿里云各放一部分,私有云再放一部分,根据它们的安全和价格做调整,私有的一些数据安全性更高的放在私有云上,资源比如和 CDN 相关的哪个便宜就放哪个云上,做动态的切换,那么此时就需要有一个和厂商无关的 API 网关放在前面做分发。
应用
举两个例子,介绍下新的 API 网关是做什么的。
- 替换 Nginx 的所有功能处理南北向的流量
它和 Nginx 比好处很明显,是完全动态来实现的,不管是 Kong 或 APISIX,动态的都是最基本的点。在 Nginx 里面修改任何一个配置文件,都需要 reload 之后才能生效的。我们设想一个场景,用 Nginx 做最前面的路由,做负载均衡,突发的流量来了,此时需要快速地增加很多上游服务器,就要不停地修改 Nginx 配置文件,然后 reload,等突发流量过了之后再把上游的服务摘掉,那么这时候还要再改 Nginx 文件并 reload 。这个代价是很大的,但是你如果用 Kong、APISIX 这种 Web 服务器,就不会有这样的问题,通过 API 可以很轻松地实时修改整个集群里面所有机器上游的配置、动态证书的配置,当然性能会比 Nginx 稍微低一点,但是这个低也是可以接受的,因为它带来了很大的灵活性。现在很多的厂商都是在做这样的替换,不仅互联网公司,还有一些传统企业都在把 Nginx 慢慢地拿掉。
- 零信任网关
近两年安全领域里很火的概念就是零信任,即zero trust。在传统的安全领域里面,我们认为边界防护非常重要,所以会用防火墙对进来的流量做一层校验,这个校验其实是命中规则的校验,如果是黑的就把它拒绝掉。那么这个时候就会有一个问题:如果一些规则更新不及时,它就可以穿越防火墙,以前的安全更多是基于边界的防护,过了边界内网是可以畅通无阻的。
但是零信任网关可以彻底解决这个问题,它认为所有的流量都是不安全的,以前的边界防护是非黑即白。现在的零信任安全网关则是非白即黑,你不是白的,那么你就是黑的,所以它是完全基于身份来认证的。一个 API 的请求过来会到身份认证的服务器,第三方的身份认证厂商比如 Author0、OKTA 的身份认证服务器认证你的身份,身份认证过了,请求才可以通过,不然就直接拒绝掉,这是是安全领域的一个趋势。
企业用户的需求
- 不锁定,可回退
所有企业用户的最大需求都是:不要锁定用户。API 网关是整个流量的入口,不能把用户锁定在里面。比如你用了阿里云的 API 网关,其实你就已经被它锁定了,因为它是流量的入口,你没有办法分发到其它云厂商上。此外还需要可回退,我使用了这个API 网关,比如原来是 Nginx,我可以很轻松地回退过去,这也是我们在做 APISIX 会考虑到的。可能用户觉得用了一段时间不爽,想退回 Nginx,我们也可以支持这种能力。
- 保持核心的稳定
APISIX 虽然每个月的迭代非常快,每个月有 200 多个 commit,有 10 个左右大的功能,但是 APISIX 里面有一个叫 core 的目录变化是很少的,我们会保持它的核心是稳定的。功能迭代可以很快,但是核心很稳定。
- 支持企业个性需求的开发
无论是国内还是国外的企业,都没有办法拿产品去适应所有的需求。如果你适应了所有的需求,那么你就做成了一个巨无霸,会是个很大很杂的产品,它的性能、可扩展性就会降的很低。所以我们就有插件,如果你需要有个性化的东西,就去定制自己的插件,需要什么功能就把这个插件放上去,不需要就把它拿掉。我可以保证最下面核心层是很稳定的,上面那层可以根据用户需求定制。
如何做网关的选型
行业现状了解
- 参考 Gartner 报告

这个是我们选型的思路,我们做选型并不是先从技术上去做,而是先看整个行业,Gartner 的报告可以作为参考。如上图所示,谷歌、IBM、RedHat 等头部玩家吃掉全球大部分 API 市场,虽然技术圈都知道 Kong,但它其实处于远见者的地位,此外Kong 作为新兴的玩家还是第一个将自身 API 网关开源出来的。
- 参考 CNCF 全景图

Gartner 的报告更偏商业化,可以在此基础之上参考开源社区中云原生软件基金会CNCF 维护的全景图,很多开源和闭源项目都被其分层、分功能地罗列出来。全景图中云原生领域有十几款软件是做 API 网关选型时可以选择的,其中有一半是大厂的产品,如 3SCALE 是Red Hat 的产品,剩下的 Kong、APISIX、TYK 等是开源项目,如果要做 API 选型可以在其中做选择。
产品选型比较
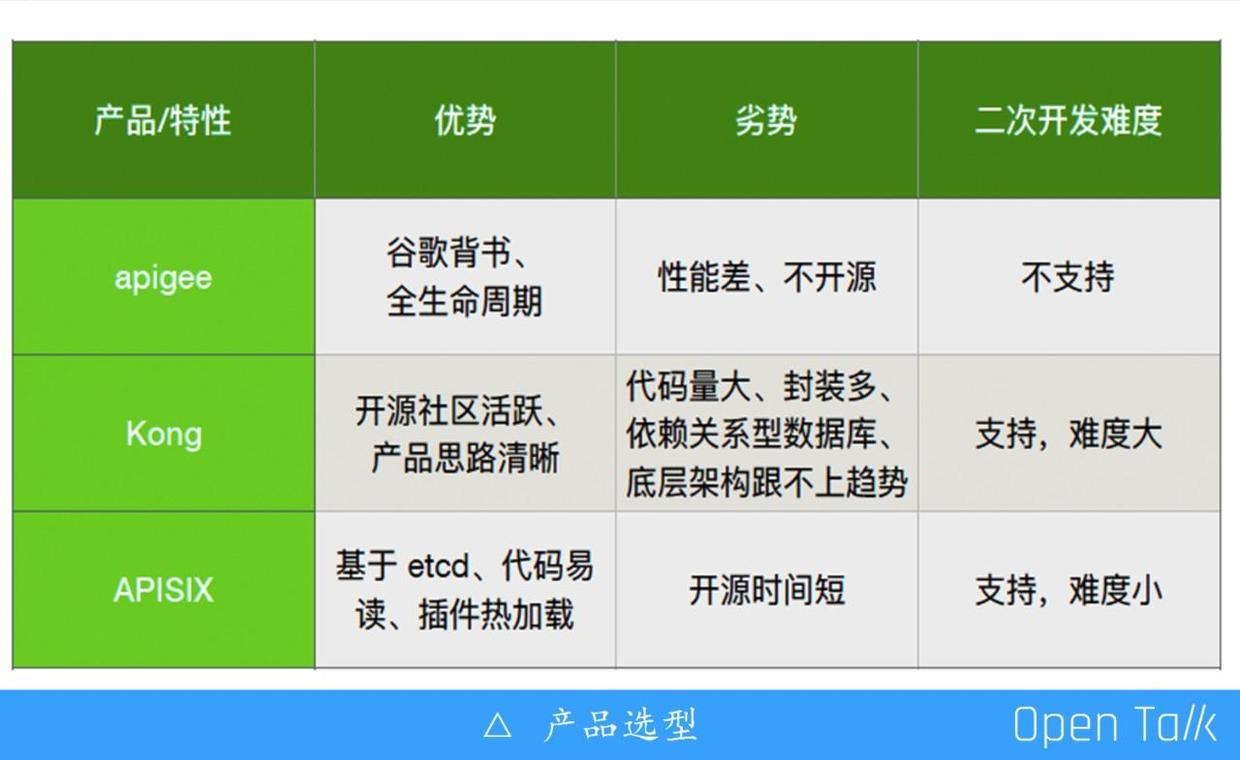
在参考 Gartner 报告和 CNCF 全景图之后,我们比较了主流的 API 网关,决定不用已有的 API 网关而是要自己做一个。
- apigee
apigee 是最大的玩家,其优势在于全生命周期,即从 API 设计、开发、文档、测试以及上线等全部是谷歌全家桶。但 apigee 是闭源项目,无法进行定制化开发,而且是被谷歌云锁定的。
- Kong
Kong 解决了 apigee 的痛点,既不会锁定也支持自定义开发,但 Kong 是 2015 年开发的,当时是把数据都放在Postgres 比较重的关系性数据库里,代码繁杂,性能存在问题。Kong 的优势在于产品思路好,方向看得准。
- APISIX
APISIX 借鉴 Kong 的思路,选型时完全基于 etcd,将所有的数据都放在 etcd 里面,完成 Kong 在postgres 上做的大量重复代码,例如消息分发、高可用和可扩展性都是基于 etcd 进行,操作更加简单。APISIX 的不足在于开源时间短,从 2019 年 6 月 6 号开源到现在尚未经受大用户的检验,但优势明显:二次开发难度比 Kong 小很多。以限流限速功能开发举例, 在 APISIX 的文件里增加六七十行代码就能完成,但 Kong 则需要修改五六个文件、两三百行代码。
如何做网关的技术选型?
API 网关的核心组件:
- 路由,路由可以认为是 Nginx 里面的各个 location,怎么把 location 分发到上游服务将各个插件加载起来是路由的一个功能。选择时需要思考的是做遍历还是做一个树?二者需要的时间和复杂程度是不一样的,我们选择像 Kong 一样做遍历。
- 插件,插件是 API 网关的核心功能,有了插件就可以很轻松地开发属于自己的代码,而不用等开源社区增加相关功能。在做插件时需要思考要不要做成热加载,热加载的意义在于新增插件或者修改某一个插件时,不需要重启整个服务就能生效。我们希望做到修改或新增插件时,可以通过 API 的调用马上生效。
- schema 的校验,schema 的校验指的是用户请求进来后需要校验上传的字段、类型等是否合法,如果自己写插件,其参数、输入值是否合法,这相当于是对 API 的描述,使得个人和前端的配合十分便利。
- 存储, 放在关系型数据库还是键值数据库,亦或是放在 etcd 里等同于是在做技术选型,需要把这些都选好后才能像搭积木一样搭建起来。
选型原则:做云原生友好的、高性能的、开源的 API 网关
- 要对开发者友好。使用 API 网关的是开发者,我们希望不管是开发者看代码、学代码还是修改插件都能很轻松,不用像我和院生当时看 Kong 的代码那样痛苦。
- 追求性能。虽说 OpenResty 的性能高,但是真正动手写的时候会发现写出来的代码性能不高,因为在 OpenResty 里面代码都是很容易写,但是很难保证写出一个极致的代码,它里面有非常多的坑,这是大部分人很难去注意到的。
APISIX 的选型
- 路由:最开始选择 lua-resty-r3,最近新增路由 FFI;
- 插件:灵感来自 Kong,但架构和设计完全不一样,大幅简化编写难度,热加载;
- schema:借用腾讯开源的 rapidjson,在 rapidjson 实现 json schema,用 json schema标准做校验;
- 存储:选用 etcd,当时没有 Lua-resty-etcd 库,需要从头 lua 帮助 etcd 进行访问。
APISIX 独有的功能
- 超强性能,性能是主打标签,内部测试发现 APISIX 的性能是 Kong 的 10 倍;
- 插件热更新,修改或增加插件,不用重启服务,所有的更新都是热的;
- 路由可以实现插件化,如果不喜欢 r3 的复杂路由,可以使用前缀匹配的路由;
- 支持版本变更控制,如果发布新版本出错可以轻松回退老版本;
- 以身份为基础的零信任,新合并的 future 可以支持外部身份认证,此时很容易实现零信任,可以接入所有外部身份认证厂商的服务。使用时只需简单调配部分参数,就可以将身份认证功能直接加入 API 中。Kong 的商业版也支持此功能,但 APISIX 直接开源。
测试、持续集成的最佳实践
测试
大公司都有专门的 QA 团队做测试,开发部门只需要写完代码简单自测后提交给 QA 团队。但开源项目没有 QA 团队,甚至连开发团队都是兼职,此时就必须用自动化的测试,即测试驱动开发的方式才能玩转开源项目。
OpenResty 的开源项目将近 70 个,其商业公司有将近 100 个闭源的项目,总共将近 200 个项目不到 10 个人维护。如果手工测试,那就什么都做不了,所以要想办法实现解决这个问题。
- 开发即测试
刚开始较慢,因为开发完一个新功能需要一块提交对应的测试案例,否则PR 不会被合并。例如给 OpenResty 贡献一个功能却没有提交对应的测试案例,或者提交了测试案例但不全,不管功能写的有多好,此PR 一定不会被合并,因为破坏了整个开源项目的原则,测试需要是自动化跑起来的。
APISIX 多引入一个条件,即代码的覆盖率不能低于70%,现在已经改为不能低于 80%。如果你的改动引入新代码,也增加了测试案例,但是降低了原有测试案例的覆盖率,那也不能被接受合并。
- 单元测试完全基于 test:nginx
测试案例完全基于 test:nginx ,可以认为 test:Nginx 是一个小语言或者一个DSL,文档较少,学习门槛比较高,我和院生对它比较熟悉才完全基于此进行测试。
- 代码风格检测:luackeck 和 lua-relang
Luackeck 非常好用,可以用于 Lua 和 OpenResty,提供有几个参数进行选择,还可以使用春哥写的 lua-relang。我们是两个程序都跑起来做代码风格检测,以确保不管是新的提交者还是我们自己的代码风格的一致性。
- 代码覆盖率检测:luacov
代码覆盖率检测使用luacov,这是标准 lua 的一个功能,可以将代码覆盖率跑起来。
合并 PR 是在上述测试即 test:nginx 测试、代码风格测试、代码覆盖率测试都跑过的前提下进行,每月 6 号发行新版本时进行性能测试,比较新老版本之间性能的差异。一般会跑火焰图,同时定期做fuzzing 测试,混乱输入如 uri、args 等做压力测试。毕竟 APISIX 是一个 API 网关,作为流量的入口要保证足够的稳定。
持续集成
测试不能依赖于人,否则总有一天会跑不下去。那么如何让单元测试、性能测试、代码风格检测等测试不依赖于人稳定地运行呢?
- 强依赖 GitHub:issue、Milestone、code review、PR approved。GitHub 的 code review 非常好用,它可以评论每一行代码,如果它觉得这行代码必须要改动,而实际没有修改,是没有办法合并 approved。
- 强依赖 travis CI:单元测试、代码风格检测、多平台测试(ubuntu 和 mac)、前端打包、自动提交。travis 是 GitHub 的持续集成插件,APISIX 并没有用自己的服务器资源去跑测试,而是跑在云端的,现在自带APISIX 的前端,其打包、提交都是自动化进行。因为我们要从vue 的代码编译为 html,这一切都是通过 travis 来做的。
- http://coveralls.io,将代码覆盖率的结果上传到http://coveralls.io 网站,以可视化的方式呈现所有和代码覆盖率相关的东西,例如哪一行代码没有被检测到,和上一个版本有什么变化等,使得代码覆盖率检测自动化进行。前文曾提到要始终保证 APISIX 的核心稳定,这就需要保证core 目录里所有文件代码覆盖率能够达到 100%,即核心板块的每一行代码都被测试到。
总结
- 资源少不一定是坏事。不管是开源项目还是商业公司,只有在资源少的时候,才会思考如何借助外部的力量或者是想出一些鬼点子解决问题;
- APISIX 的选型、测试和 CI 都是找“取巧”和自动化的方式,借助巧用外部力量的方式去做,没有造轮子;
- APISIX 的选型、测试和 CI 三者非常重要,比性能重要。虽然我们主打性能,但更值得大家琢磨的不只是代码,而是选型怎么测试和 CI 的,大家可以将其运用到业务中,即使不用 OpenResty 和 APISIX,还是可以学习开源项目是怎么做的;
- GitHub 和 SaaS 能提供的服务,绝对不会自己去造,克制住自己造轮子的冲动。
查看演讲PPT及视频:
本文由博客一文多发平台 OpenWrite 发布!