详解机器学习中的数据处理(二)——特征归一化
摘要:在机器学习中,我们的数据集往往存在各种各样的问题,如果不对数据进行预处理,模型的训练和预测就难以进行。这一系列博文将介绍一下机器学习中的数据预处理问题,以\(\color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I}\)数据集为例详细介绍缺失值处理、连续特征离散化,特征归一化及离散特征的编码等问题,同时会附上处理的\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程序代码,这篇博文先介绍下特征归一化,其要点可见本文目录。
前言
这篇博文我会以机器学习中经常使用的\(\color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I}\)数据集为例进行介绍。关于\(\color{#4285f4}{U}\color{#ea4335}{C}\color{#fbbc05}{I}\)数据集的介绍和整理,在我前面的两篇博文:UCI数据集详解及其数据处理(附148个数据集及处理代码)、UCI数据集整理(附论文常用数据集)都有详细介绍,有兴趣的读者可以点过去了解一下。
俗话说,“巧妇难为无米之炊”。在机器学习中,数据和特征便是“米”,模型和算法则是“巧妇”。没有充足的数据、合适的特征,再强大的模型结构也无法得到满意的输出。正如一句业界经典的话所说,“Garbage in,garbage out”。对于一个机器学习问题,数据和特征往往决定了结果的上限,而模型、算法的选择及优化则是在逐步接近这个上限。
1. 特征归一化
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
归一化和标准化都可以使特征无量纲化,归一化使得数据放缩在[0, 1]之间并且使得特征之间的权值相同,改变了原数据的分布;而标准化将不同特征维度的伸缩变换使得不同度量之间的特征具有可比性,同时不改变原始数据的分布。下面一个小节的方法部分引自诸葛越、葫芦娃的《百面机器学习》关于特值归一化的介绍。
特征归一化方法
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。例如,分析一个人的身高和体重对健康的影响,如果使用米(m)和千克(kg)作为单位,那么身高特征会在1.6~1.8m的数值范围内,体重特征会在50~100kg的范围内,分析出来的结果显然会倾向于数值差别比较大的体重特征。想要得到更为准确的结果,就需要进行特征归一化(Normalization)处理,使各指标处于同一数值量级,以便进行分析。
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种。
(1)线性函数归一化(Min-Max Scaling):它对原始数据进行线性变换,使结果映射到[0, 1]的范围,实现对原始数据的等比缩放。归一化公式如下:
\]
其中\(X\)为原始数据,\(X_{max}\)、\(X_{min}\)分别为数据最大值和最小值。
(2)零均值归一化(Z-Score Normalization):它会将原始数据映射到均值为0、标准差为1的分布上。具体来说,假设原始特征的均值为\(\mu\)、标准差为\(\sigma\),那么归一化公式定义为:
\]
为什么需要对数值型特征做归一化呢?我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征,\(x_{1}\)的取值范围为[0, 10],\(x_{2}\)的取值范围为[0, 3],于是可以构造一个目标函数符合图1.1 (a)中的等值图。在学习速率相同的情况下,\(x_{1}\)的更新速度会大于\(x_{2}\),需要较多的迭代才能找到最优解。如果将\(x_{1}\)和\(x_{2}\)归一化到相同的数值区间后,优化目标的等值图会变成图1.1 (b)中的圆形,\(x_{1}\)和\(x_{2}\)的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。
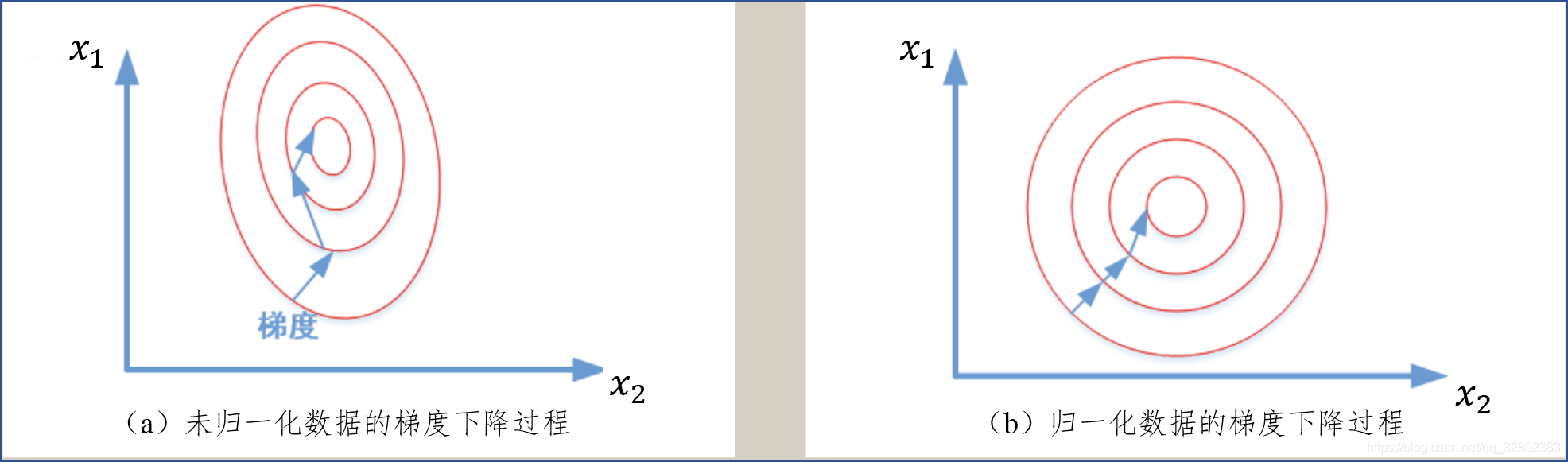
在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。当然,数据归一化并不是万能的,这一方法对于决策树模型并不适用。
Matlab代码实现
这里我给大家介绍下如何用代码实现。在\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)中对于上面提到的两种归一化方法均有自带的处理函数,为避免二次开发我们使用其自带的函数,它们分别是最大最小值映射:mapminmax( )和z值标准化:zscore( )。这里我们分别介绍以下这两个函数,mapminmax( )函数官方文档介绍如下:
mapminmax
通过将行的最小值和最大值映射到[ -1 1] 来处理矩阵
语法
[Y,PS] = mapminmax(X,YMIN,YMAX)
[Y,PS] = mapminmax(X,FP)
Y = mapminmax(‘apply’,X,PS)
说明
[Y,PS] = mapminmax(X,YMIN,YMAX) 通过将每行的最小值和最大值归一化为[ YMIN,YMAX] 来处理矩阵。
[Y,PS] = mapminmax(X,FP) 使用结构体作为参数: FP.ymin,FP.ymax。
Y = mapminmax(‘apply’,X,PS) 给定 X和设置PS,返回Y。
——MATLAB官方文档
mapminmax( )函数是按行进行归一化处理的,我们可以通过在命令行键入指令进行测试,由于数据集中的数据属性是按列的所以在计算时需要对矩阵进行转置,测试指令和运行结果如下:
>> x1 = [1 2 4; 1 1 1; 3 2 2; 0 0 0]
x1 =
1 2 4
1 1 1
3 2 2
0 0 0
>> [y1,PS] = mapminmax(x1');
>> y1'
ans =
-0.3333 1.0000 1.0000
-0.3333 0 -0.5000
1.0000 1.0000 0
-1.0000 -1.0000 -1.0000
zscore( )的使用文档介绍如下,该函数按列将每个元素归一化为均值到0,标准差为1的分布上,详情可参考zscore( )函数官方文档。
zscore
z值标准化
语法
Z = zscore(X)
Z = zscore(X,flag)
Z = zscore(X,flag,’all’)
说明
Z = zscore(X) 为X的每个元素返回Z值,将X每列数据映射到均值为0、标准差为1的分布上。Z与的大小相同X。
Z = zscore(X,flag) 使用由flag表示的标准偏差来缩放X。
Z = zscore(X,flag,’all’) 使用X中的所有值的平均值和标准偏差来归一化X。
——MATLAB官方文档
zscore( )函数是按列的均值和标准差进行归一化处理的,我们可以通过在命令行键入指令进行测试,测试指令和运行结果如下:
>> x2 = [1 2 4; 1 1 1; 3 2 2; 0 0 0]
x2 =
1 2 4
1 1 1
3 2 2
0 0 0
>> y2 = zscore(x2);
>> y2
y2 =
-0.1987 0.7833 1.3175
-0.1987 -0.2611 -0.4392
1.3908 0.7833 0.1464
-0.9934 -1.3056 -1.0247
对此我们以UCI数据集中的wine( )数据集为例对其数据进行线性函数归一化及零均值归一化,首先在官网下载页下载并保存文件“wine.data”保存在自定义文件夹下,用\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)打开文件部分数据截图如下图所示:
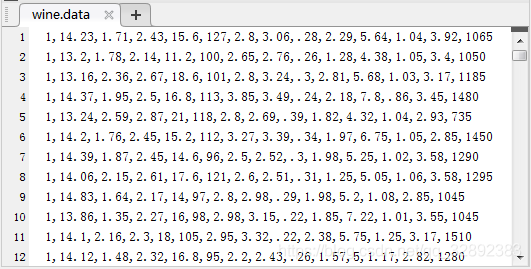
在该目录下新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)文件“data_normal.m”并在编辑器中键入如下代码:
% Normalization
% author:sixu wuxian, website://wuxian.blog.csdn.net
clear;
clc;
% 读取数据
wine_data = load('wine.data'); % 读取数据集数据
data = wine_data(:,2:end); % 读取属性
label = wine_data(:, 1); % 读取标签
% y =(ymax-ymin)*(x-xmin)/(xmax-xmin)+ ymin;
xmin = -1;
xmax = 1;
[y1, PS] = mapminmax(data', xmin, xmax); % 最大最小值映射归一化
mapminmax_data = y1';
save('wine_mapminmax.mat', 'mapminmax_data', 'label'); % 保存归一化数据
% y = (x-mean)/std
zscore_data = zscore(data); % 零均值归一化
save('wine_zscore.mat', 'zscore_data', 'label');% 保存归一化数据
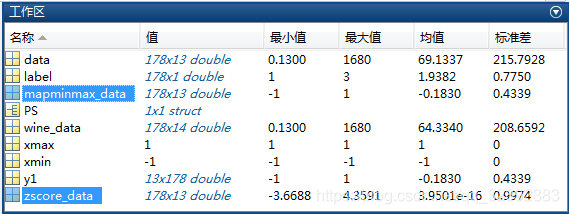
以上代码运行后将结果分别保存在文件“wine_mapminmax.mat”和“wine_zscore.mat”中,通过工作区的变量显示情况可以看出数据已归一化到较理想情况,如下图所示:
2. 代码资源获取
这里对博文中涉及的数据及代码文件做一个整理,本文涉及的代码文件如下图所示。所有代码均在\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\) \(\color{#4285f4}{R}\color{#ea4335}{2}\color{#fbbc05}{0}\color{#4285f4}{1}\color{#34a853}{6}\color{#ea4335}{b}\)中调试通过,点击即可运行。
后续博文会继续分享数据处理系列的代码,敬请关注博主的机器学习数据处理分类专栏。
【资源获取】
若您想获得博文中介绍的填充缺失数据涉及的完整程序文件(包含数据集的原始文件、归一化代码文件及整理好的文件),可点击下方卡片关注公众号“AI技术研究与分享”,后台回复“NM20200301”,后续系列的代码也会陆续分享打包在里面。
更多的UCI数据及处理方式已打包至博主面包多网页,里面有大量的UCI数据集整理和数据处理代码,可搜索思绪无限查找。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
【参考文献】
[1] //ww2.mathworks.cn/help/deeplearning/ref/mapminmax.html
[2] //ww2.mathworks.cn/help/stats/zscore.html


