牛亚男:基于多Domain多任务学习框架和Transformer,搭建快精排模型
- 2022 年 6 月 18 日
- 笔记
- DataFunTalk, 人工智能, 大数据, 算法

导读: 本文主要介绍了快手的精排模型实践,包括快手的推荐系统,以及结合快手业务展开的各种模型实战和探索,全文围绕以下几大方面展开:
- 快手推荐系统
- CTR模型——PPNet
- 多domain多任务学习框架
- 短期行为序列建模
- 长期行为序列建模
- 千亿特征,万亿参数模型
- 总结和展望
—
01 快手推荐系统
快手的推荐系统类似于一个信息检索范式,只不过没有用户显示query。结构为数据漏斗,候选集有百亿量级的短视频,在召回层,会召回万级的视频给粗排打分,再选取数百个短视频,给精排模型打分,最后会有数十个短视频进行重排。推荐主要是双类或单类,快手推荐的特点是用户比较多,会超过3.0亿。我们的短视频,每天有百亿的分发量,候选的短视频有百亿之多,用户的行为差距会非常之大,比如,有些用户每天会刷成百上千条短视频,有些用户又刷得非常少。相对于电商或者新闻来说,短视频的玩法会更丰富,用户的兴趣非常广泛,并且是不变的。
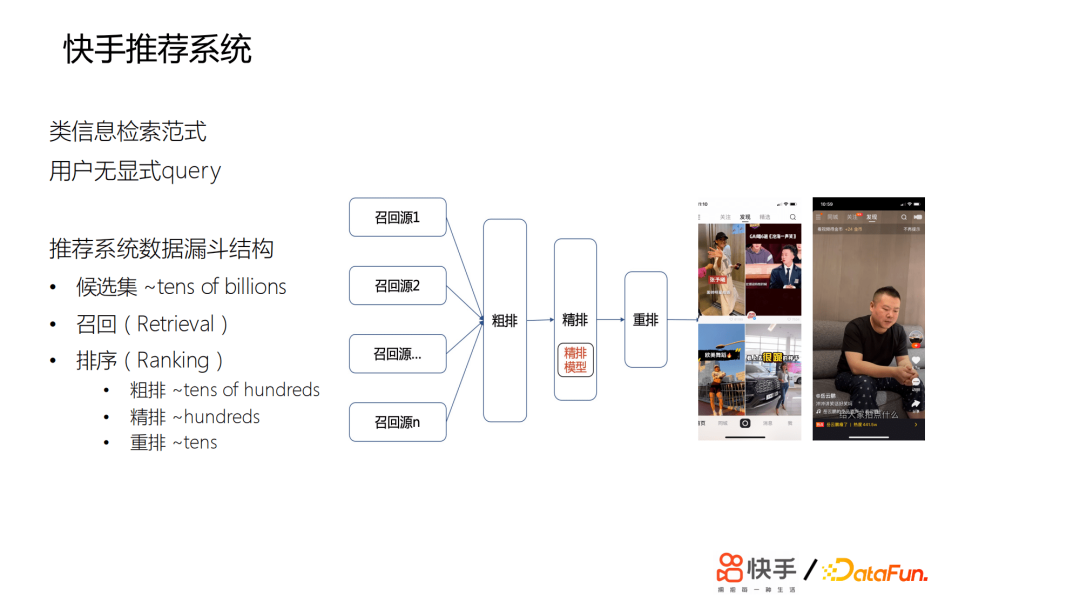
用户的交互类型非常多,场景复杂。这里简单展示一下,主要有主站的双列发现页、主站精选、极速版发现页,这些主要是用来帮助用户发现可能感兴趣的视频,还有关注页、同城页。除了短视频之外,还有直播、电商直播的推荐。对于整个推荐系统来说,我们最大的挑战是如何为用户的兴趣精准建模。

—
02 CTR模型——PPNet

这是我们2019年的模型,ctr的个性化预估是推荐系统的核心,主要用来预估用户对视频会不会点击,预估效果直接影响用户体验。
从业界的演化来看,一方面是从特征的交叉角度,另一方面是从用户的行为序列建模来提升模型个性化。这里DNN核心为全连接网络。
特征全局共享,主要用来捕捉全局用户和短视频的特征。要做到真正的千人千面,需要用户个性化的特征更强一些。所以当时我们探索了如何为DNN网络增加个性化。我们尝试了一些方法,最开始尝试用stacking的方法,在最顶层或中间加一些user独有的一些网络,对网络的参数,每个用户是不同的,但是收益甚微。然后我们尝试了另外一种方式,受LHUC的启发,思想来源于语音识别,给每个用户学习个性化的偏置项。
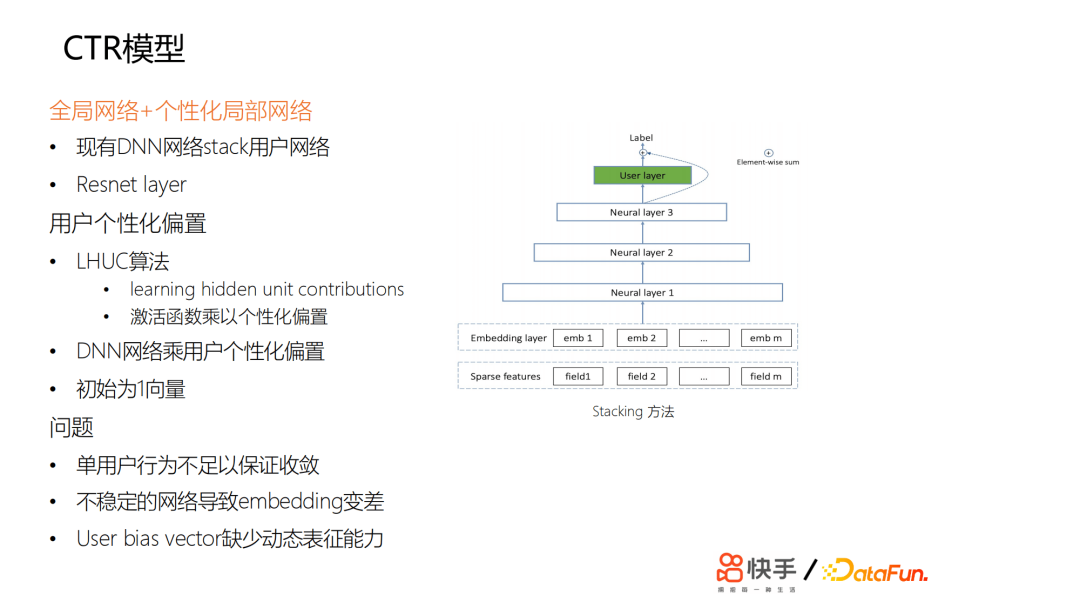
在网络输出的激活函数那里,设置了个性化的偏置项,可以认为是给每个用户学了一个bias和一个vector。我们做了一些尝试,但是基本上没有太大的收益。
我们发现一些问题,总结来说,首先是用户每天刷的样本不足以让网络的参数收敛,因为参数量相对来说比较少,这相当于是给一个用户学一个最宽的一个id的embedding向量。
另外用户每天都在上传新的视频,我们推荐的视频,主要约束在两天以内,所以会有一个视频冷启动的问题,而且基于流式训练,会导致训练样本中各方面的噪声非常大,如果是一个不稳定的网络,也会导致embedding的效果变差。如果只是简单学一个优质的id的embedding,则缺少足够的动态表达能力。另外,如果只是通过bp的方法传导梯度来更新id的embedding,其修正能力非常慢。最终我们在lte的基础上设计了一个pnet,以全局共享为基础,进行个性化的微调;我们又设计了gate网络来拟合个性化的参数:
- 白色的部分可以认为是原来的基线。这个基线主要是训练原来的ctr模型。
- 灰色和绿色部分是新加的,灰色部分是基于所有用户共享的,绿色部分是门控网络,通过门控网络与灰色部分的网络来学习用户的个性化。
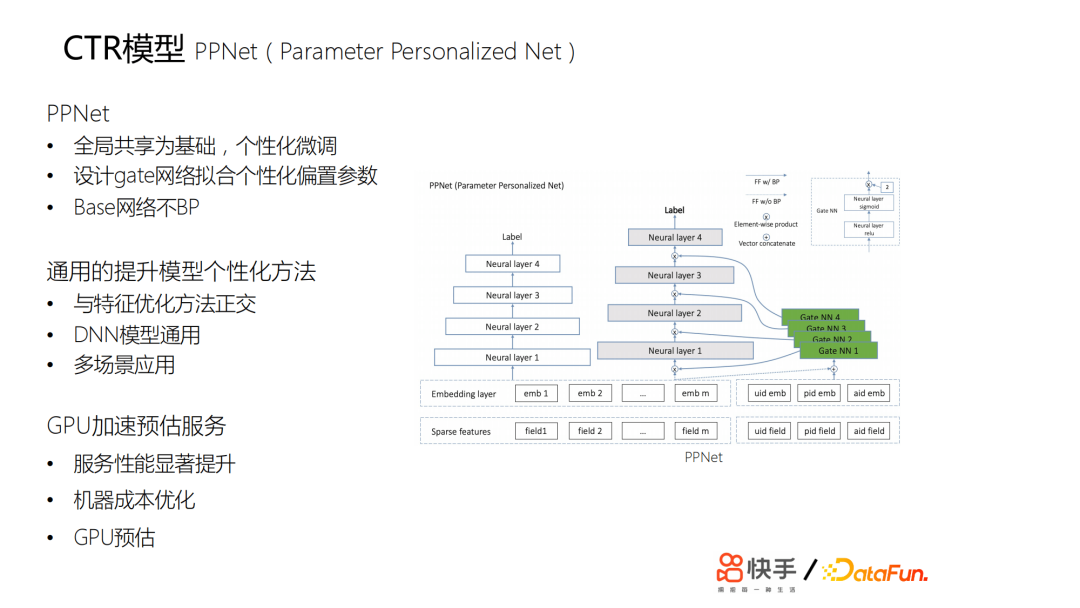
这两部分的网络也就是ppnet的网络结构。上线后,收益非常明显。包括所有用户细分上提升都是非常明显的,特别是一些行为比较稀疏的用户,他们的提升非常大,因为他们的行为相对来说比较少,之前的两个方案模型很难学到他们的一些特征。这套方案给我们提供了一个比较通用的提升模型个性化的方法。
我们推广到了一些其他场景,实现多场景应用。但是这个算法的计算量比较大,因此我们对线上的预估服务做了一次升级——原来是cpu预估,我们在2019年10月份做了gpu加速预估。
—
03 多domain多任务学习框架

快手的产品场景非常多样,包括主站发现页、主站精选、发现页内流、极速版发现页等。另一方面,人群多样化,包括新用户、老用户、激活用户等。另外,这两个场景正交,就有几十个目标。因此,我们要预估的目标也会非常多。这样会存在一系列的问题,比如业务独占模型会导致训练资源低效、迭代低效、业务间不共享网络等。为了解决这些问题,我们在模型融合场景下做了多任务学习。

对于模型融合,我们做了很多工作,比如特征语义对齐,主要包括删减无用特征,改正语义不一致特征,添加单列播放列表类特征、交叉特征;embedding空间的对齐,通过Embedding transform gate,直接学习映射关系;特征重要性对齐,这里用到了slot gate,主要参考了前面提到的ppnet里面的gate设计方案。在不同的场景下,不同的用户或视频,对于特征的重要性选择,gate会把它约束在0~2,均值是1,动态选择这个特征是重要还是不重要,这样我们可以将样本的特征做一个比较好的对齐。最后,我们做了一个多目标的mmoe,动态建模目标之间的关系,每个task tower输入添加个性化偏置项。通过上面的工作,我们成功将在线与离线的模型融合成一套模型,全业务推全,用户交互涨幅提升近10%,效果显著。
—
04 短期行为序列建模
接下来介绍短期行为序列建模的工作,在2019年初,快手交互场景越来越多,同时出现了单双列的交互体验,单双列业务下用户行为序列存在差异。单列剥夺了用户主动点的权利,用户更多是被动来看推荐系统推荐的短视频,因此,单列更适合作E&E。双列的交互体验下用户获得的主动性、可选择性强,用户的点击历史没有太多的特征可以学习,用户会不断地释放自己想看的内容,释放自己的欲望,可能会一直不断地在看相关的一些内容。我们当时做了一些尝试,发现RNN表现不如sum pooling,其相关性大于时序性。因此我们对算法做了四个方面的改进:
① 使用encoder部分:对历史序列进行表征
② 使用用户视频播放历史序列
- 包含用户更多信息(观看时长,交互label)
- 不同业务语义一致
③ Transformer layer self attention替为target attention
- Self attention无明显收益
- 使用当前embedding层对sequence做attention
- 简化计算复杂度 O(n2d) -> O(nd)
④ log(now – 视频观看时间戳) 代替position embedding
- 最近观看视频更相关,log处理更合适
- 更久之前观看视频体现用户长期兴趣分布
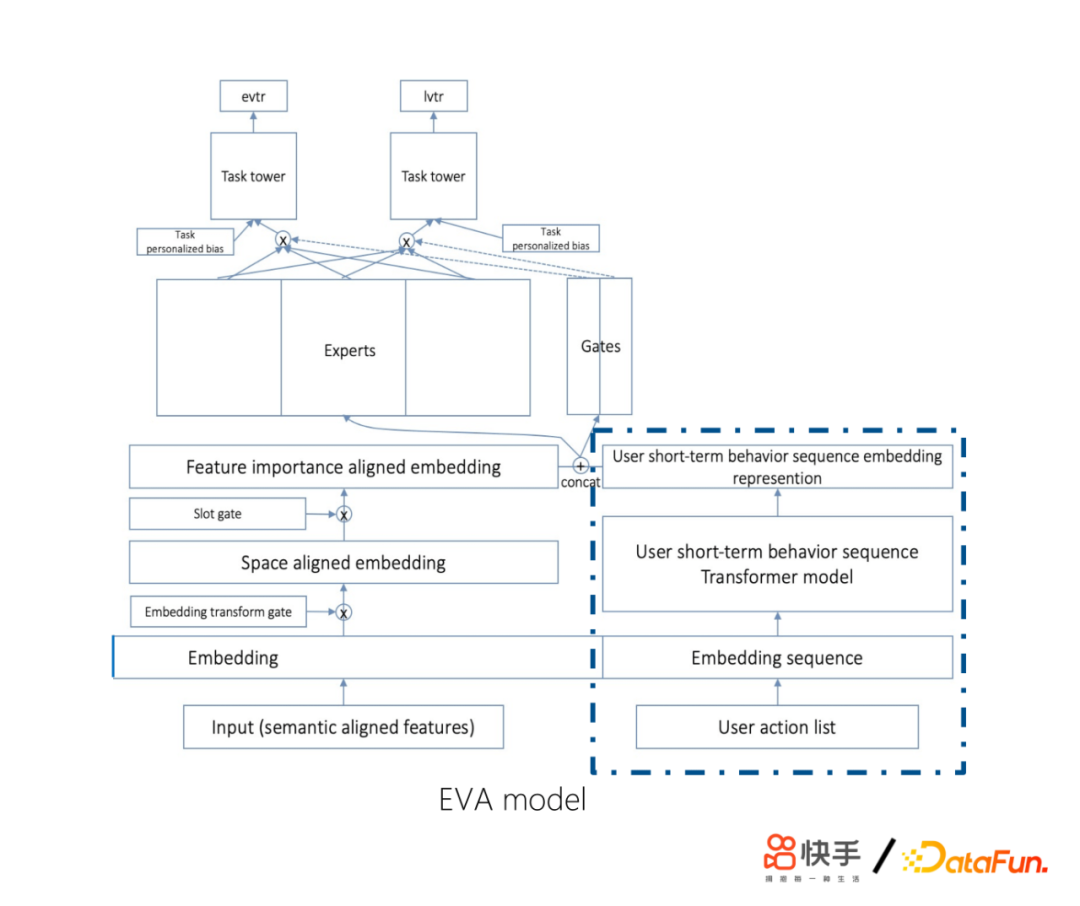
首先,使用encoder部分对历史序列进行表征。其次,使用用户视频播放历史序列,因为里面包含用户更多信息(观看时长、交互label)。另外,将Transformer layer self attention替换为target attention,主要是self attention无明显收益,然后使用当前embeding层对sequence做attention,因为我们认为对用户的行为历史作为监测的时候,不应该只看要推荐的这个视频,我们还会关注这是一个什么用户,这个用户的上下文信息是非常有用的。最后,使用log(现在时间-视频观看时间)代替position embedding,因为最近观看视频更相关,log处理更合适。上线之后,取得了非常大的收益。
—
05 长期行为序列建模
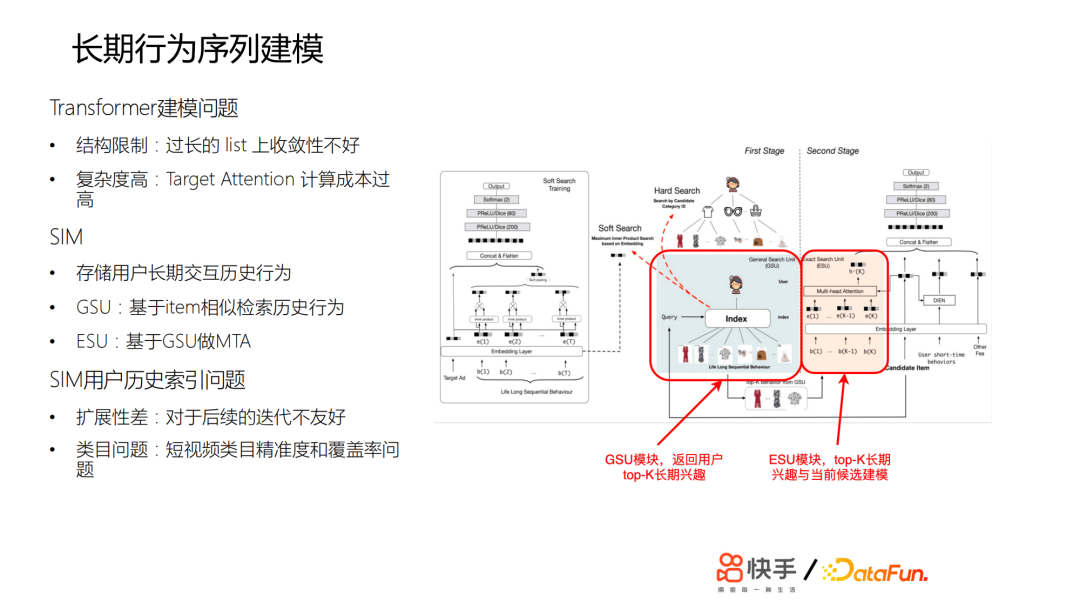
推荐系统拥有短期记忆,容易导致信息茧房或者出现多样性不足的一些问题。但是在长期行为建模的时候又遇到了各种问题,比如:Transformer建模问题,SIM用户历史索引问题等。Transformer建模容易出现结构限制,模型在过长的list上收敛性不好。另外,模型复杂度高,Target Attention计算成本也会很高。SIM用户历史索引的扩展性差,对于后续的迭代不友好,而且对于短视频类目精准度和覆盖率也有问题。为了能够捕捉到用户不同程度的兴趣偏好,我们迭代了两个版本模型,作了很多探索和改进。
下面介绍快手在长期行为序列建模的工作。
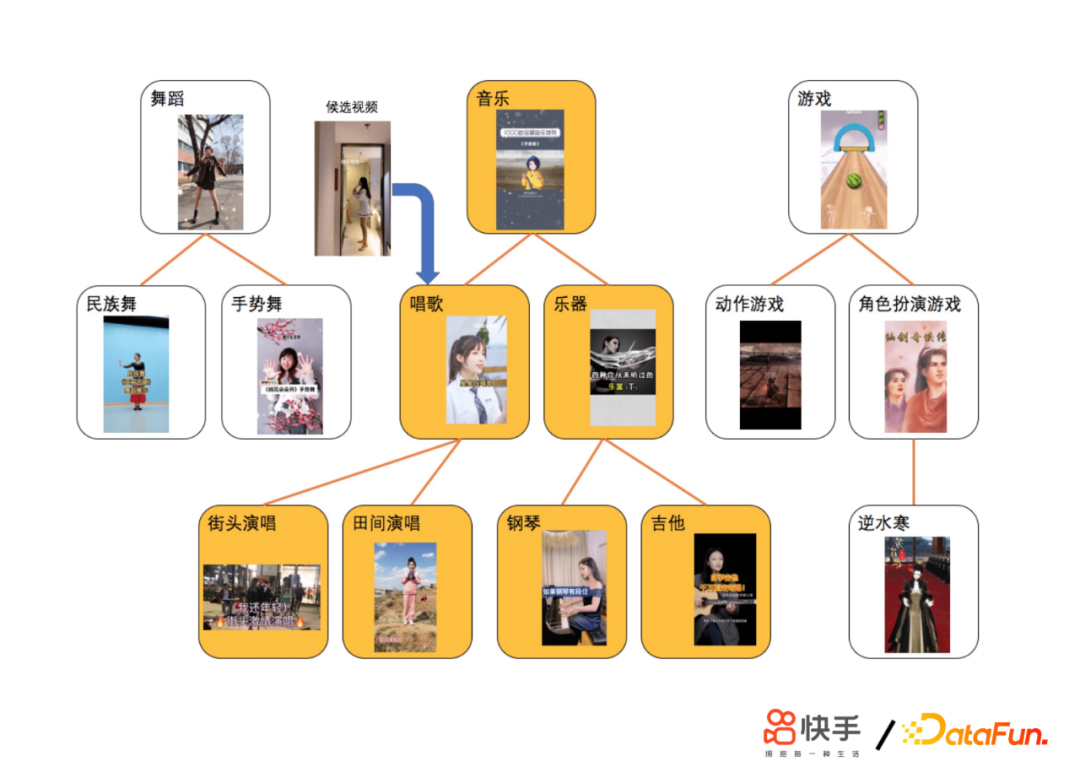
- 第一个版本方案V1.0(基于Tag检索)
为了应对上面提到的一些问题,我们采用了独立存储方案,依托AEP高密度存储设备直接存储用户超长行为历史;进一步完善类目体系;GSU检索采用回溯补全算法,最大路径匹配的算法衡量相似度;ESU采用短时。关于Transformer方案,难点在于计算量增加,因此我们进行了算法优化;合并相同Tag候选视频的搜索过程;提前建立类目倒排链,简化搜索流程;成本优化,利用线上 GPU 推理服务器的闲置 CPU 资源。通过这些尝试,我们做到了让SIM算法首次在短视频推荐落地;在业界首次覆盖用户历史至年,这是数万级别的;收益巨大,建立了护城河;扩展到了其他场景。
- V2.0(基于Embedding距离检索)
后面又做了第二个版本,基于视频内容embedding的聚类。采用GSU检索算法:优先聚类内视频;最近聚类补全;近似做了余弦相似度检索。
其次,又节省了余弦相似度计算量。通过这些工作,我们取得了一些成果:建立了快手特色的长期行为建模机制;收益巨大,建立了护城河;扩展到了其他场景。
经过这两版的迭代,整体效果提升明显,人均app使用时长提升显著,其中我们的工作做了非常多的贡献。
—
06 千亿特征,万亿参数模型
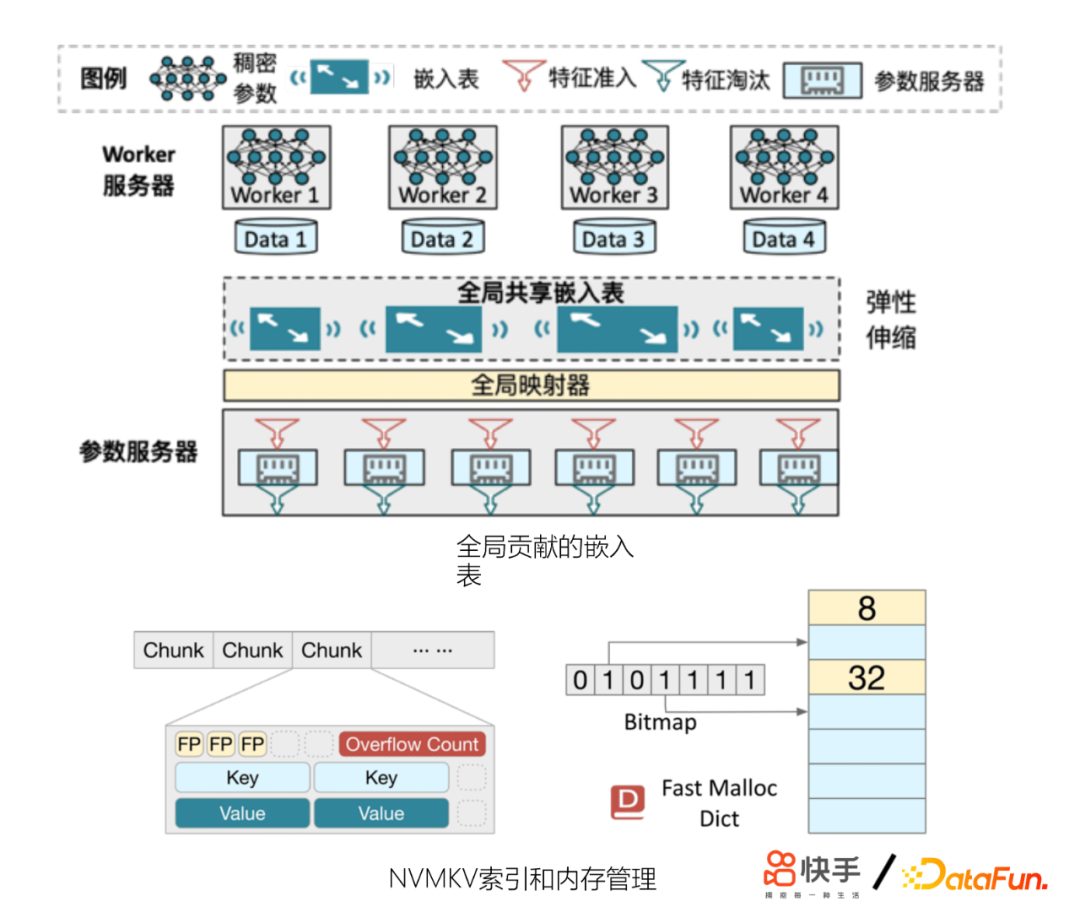
另外,我们发现模型的特征量还会制约模型精排的效果。模型收敛不稳定,模型更容易逐出低频特征、冷启动效果变差等。为此,我们在工程上做了一些优化,也起到了非常好的收益。主要包括:
- 改进参数服务器(GSET)
- 更好地控制内存使用
- 定制feature score淘汰策略
- 效果优于LFU,LRU等淘汰策略
- 结合新的硬件:非易失内存(Intel AEP)
- 底层KV引擎NVMKV来支撑GSET
—
07 总结和展望
对于未来优化的重点,我们会放在模型融合,多任务学习方向。另外用户长短期兴趣怎样更好得建模和融合,以及用户的留存建模也是我们未来优化的重点。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。


