面试官:你给我说一下什么是时间轮吧?
- 2021 年 11 月 16 日
- 笔记
你好呀,我是歪歪。
今天我带大家来卷一下时间轮吧,这个玩意其实还是挺实用的。
常见于各种框架之中,偶现于面试环节,理解起来稍微有点难度,但是知道原理之后也就觉得:

大多数人谈到时间轮的时候都会从 netty 开始聊。
我就不一样了,我想从 Dubbo 里面开始讲,毕竟我第一次接触到时间轮其实是在 Dubbo 里面,当时就惊艳到我了。
而且,Dubbo 的时间轮也是从 Netty 的源码里面拿出来的,基本一模一样。
时间轮在 Dubbo 里面有好几次使用,比如心跳包的发送、请求调用超时时间的检测、还有集群容错策略里面。
我就从 Dubbo 里面这个类说起吧:
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker
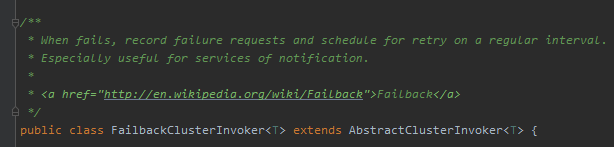
Failback,属于集群容错策略的一种:

你不了解 Dubbo 也没有关系,你只需要知官网上是这样介绍它的就行了:

我想突出的点在于“定时重发”这四个字。
我们先不去看源码,提到定时重发的时候,你想到了什么东西?
是不是想到了定时任务?
那么怎么去实现定时任务呢?
大家一般都能想到 JDK 里面提供的 ScheduledExecutorService 和 Timer 这两个类。
Timer 就不多说了,性能不够高,现在已经不建议使用这个东西。
ScheduledExecutorService 用的还是相对比较多的,它主要有三个类型的方法:

简单说一下 scheduleAtFixedRate 和 scheduleWithFixedDelay 这两个方法。
ScheduleAtFixedRate,是每次执行时间为上一次任务开始起向后推一个时间间隔。
ScheduleWithFixedDelay,是每次执行时间为上一次任务结束起向后推一个时间间隔。
前者强调的是上一个任务的开始时间,后者强调的是上一个任务的结束时间。
你也可以理解为 ScheduleAtFixedRate 是基于固定时间间隔进行任务调度,而 ScheduleWithFixedDelay 取决于每次任务执行的时间长短,是基于不固定时间间隔进行任务调度。
所以,如果是我们要基于 ScheduledExecutorService 来实现前面说的定时重发功能,我觉得是用 ScheduleWithFixedDelay 好一点,含义为前一次重试完成后才应该隔一段时间进行下一次重试。
让整个重试功能串行化起来。
那么 Dubbo 到底是怎么实现这个定时重试的需求的呢?
撸源码啊,源码之下无秘密。
准备发车。
撸源码
有的同学看到这里可能着急了:不是说讲时间轮吗,怎么又开始撸源码了呀?
你别猴急呀,我这不得循序渐进嘛。
我先带你手撕一波 Dubbo 的源码,让你知道源码这样写的问题是啥,然后我再说解决方案嘛。
再说了,我直接,啪的一下,把解决方案扔你脸上,你也接受不了啊。
我喜欢温柔一点的教学方式。

好了,先看下面的源码。
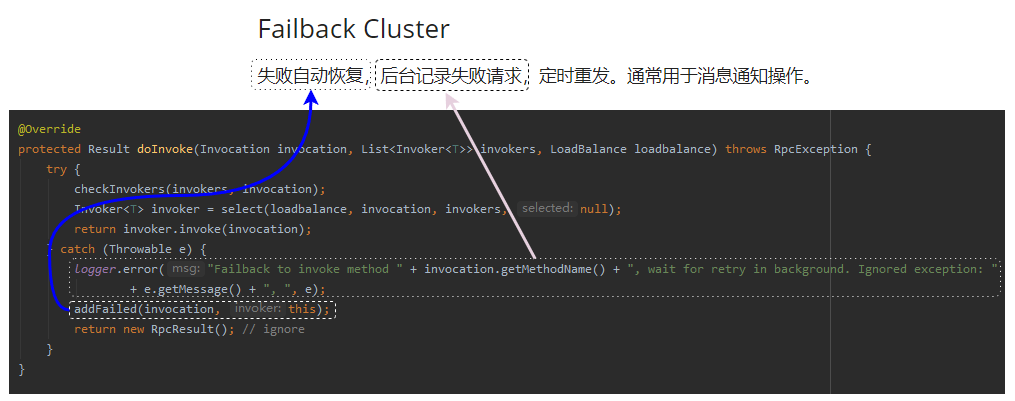
这几行代码你要是没看明白没有关系,你主要关注 catch 里面的逻辑。
我把代码和官网上的介绍帮你对应了一下。
意思就是调用失败了,还有一个 addFailed 来兜底。
addFailed 是干了啥事呢?
干的就是“定时重发”这事:
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker#addFailed
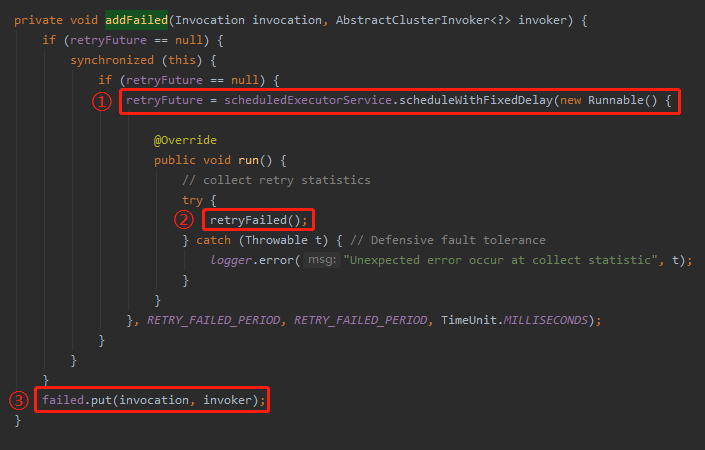
这个方法就可以回答前面我们提出的问题:Dubbo 集群容错里面,到底是怎么实现这个定时重试的需求的呢?
从标号为 ① 的地方可以知道,用的就是 ScheduledExecutorService,具体一点就是用的 scheduleWithFixedDelay 方法。
再具体一点就是如果集群容错采用的是 failback 策略,那么在请求调用失败的 RETRY_FAILED_PERIOD 秒之后,以每隔 RETRY_FAILED_PERIOD 秒一次的频率发起重试,直到重试成功。
RETRY_FAILED_PERIOD 是多少呢?
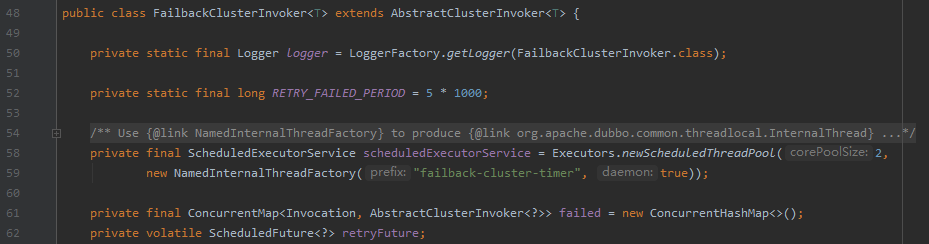
看第 52 行,它是 5 秒。
另外,你可以在前面 addFailed 方法中看到标号为 ③ 的地方,是在往 failed 里面 put 东西。
failed 又是一个什么东西呢?
看前面的 61 行,是一个 ConcurrentHashMap。
标号为 ③ 的地方,往 failed put 的 key 就是这一次需要重试的请求,value 是处理这一次请求对应的服务端。
failed 这个 map 是什么时候用呢?
请看标号为 ② 的 retryFailed 方法:
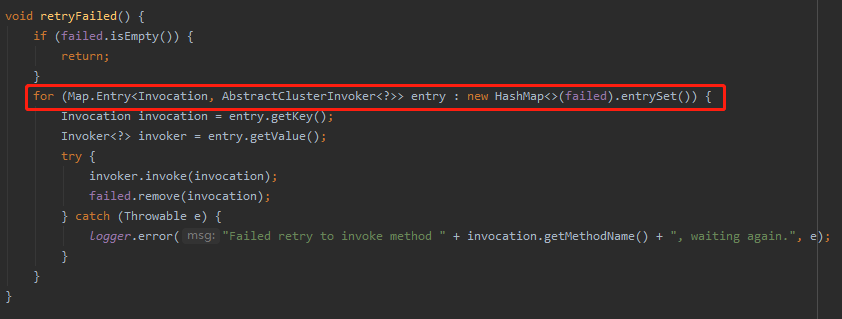
在这个方法里面会去遍历 failed 这个 map,全部拿出来再次调用一遍。
如果成功了就调用 remove 方法移除这个请求,没有成功的会抛出异常,打印日志,然后等待下次再次重试。
到这里我们就算是揭开了 Dubbo 的 FailbackClusterInvoker 类的神秘面纱。
面纱之下,隐藏的就是一个 map 加 ScheduledExecutorService。
感觉好像也没啥难的啊,很常规的解决方案嘛,我也能想到啊。
于是你缓缓的在屏幕上打出一个:

但是,朋友们,抓好坐稳,要“但是”了,要转弯了。
这里面其实是有问题的,最直观的就是这个 map,没有限制大小,由于没有限制大小,那么在一些高并发的场景下,是有可能出现内存溢出的。
好,那么问题来了,怎么防止内存溢出呢?
很简单,首先我们可以限制 map 的大小,对吧。
比如限制它的容量为 1000。
满了之后,怎么办呢?
可以搞一个淘汰策略嘛,先进先出(FIFO),或者后进先出(LIFO)。
然后也不能一直重试,如果重试超过了一定次数应该被干掉才对。
上面说的内存溢出和解决方案,都不是我乱说的。
我都是有证据的,因为我是从 FailbackClusterInvoker 这个类的提交记录上看到了它的演进过程的,前面截图的代码也是优化之前版本的代码,并不是最新的代码:
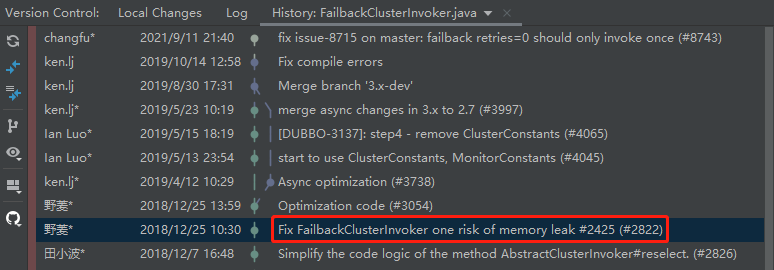
这一次提交,提到了一个编号叫 2425 的 issue。
//github.com/apache/dubbo/issues/2425

这里面提到的问题和解决方案,就是我前面说的事情。
终于,铺垫完成,关于时间轮的故事要正式开始了。

时间轮原理
有的朋友又开始猴急了。
要我赶紧上时间轮的源码。
你别着急啊,我直接给你讲源码,你肯定会看懵逼的。
所以我决定,先给你画图,看懂原理。
给大家画一下时间轮的基本样子,理解了时间轮的工作原理,下面的源码解析理解起来也就相对轻松一点了。
首先时间轮最基本的结构其实就是一个数组,比如下面这个长度为 8 的数组:
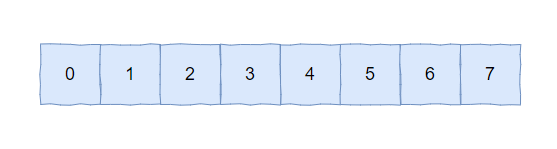
怎么变成一个轮呢?
首尾相接就可以了:

假如每个元素代表一秒钟,那么这个数组一圈能表达的时间就是 8 秒,就是这样的:

注意我前面强调的是一圈,为 8 秒。
那么 2 圈就是 16 秒, 3 圈就是 24 秒,100 圈就是 800 秒。
这个能理解吧?
我再给你配个图:
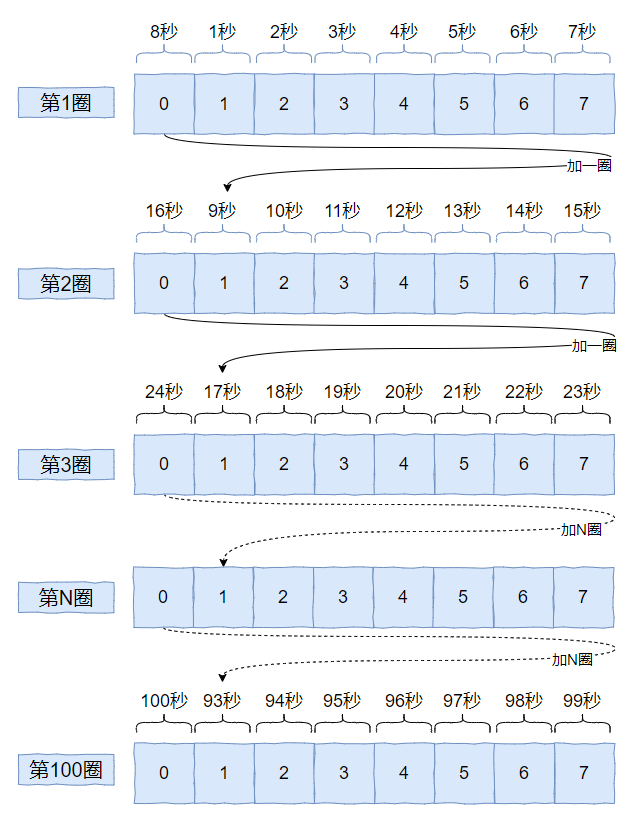
虽然数组长度只有 8,但是它可以在上叠加一圈又一圈,那么能表示的数据就多了。
比如我把上面的图的前三圈改成这样画:

希望你能看明白,看不明白也没有关系,我主要是要你知道这里面有一个“第几圈”的概念。
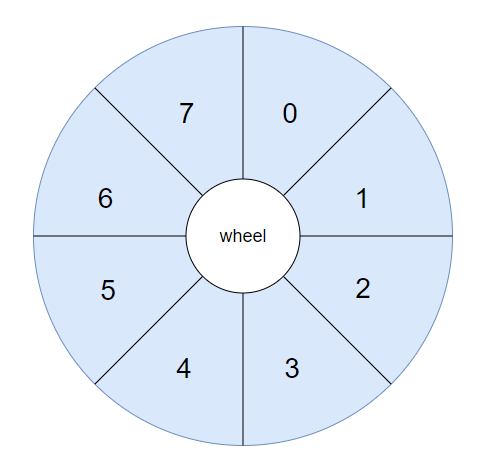
好了,我现在把前面的这个数组美化一下,从视觉上也把它变成一个轮子。
轮子怎么说?
轮子的英文是 wheel,所以我们现在有了一个叫做 wheel 的数组:
然后,把前面的数据给填进去大概是长这样的。
为了方便示意,我只填了下标为 0 和 3 的位置,其他地方也是一个意思:

那么问题就来了。假设这个时候我有一个需要在 800 秒之后执行的任务,应该是怎么样的呢?
800 mod 8 =0,说明应该挂在下标为 0 的地方:

假设又来一个 400 秒之后需要执行的任务呢?
同样的道理,继续往后追加即可:
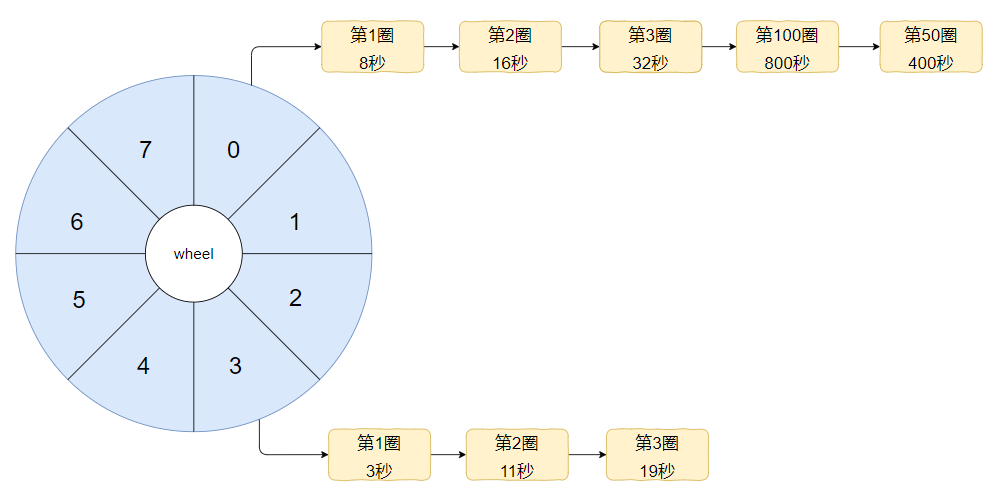
不要误以为下标对应的链表中的圈数必须按照从小到大的顺序来,这个是没有必要的。
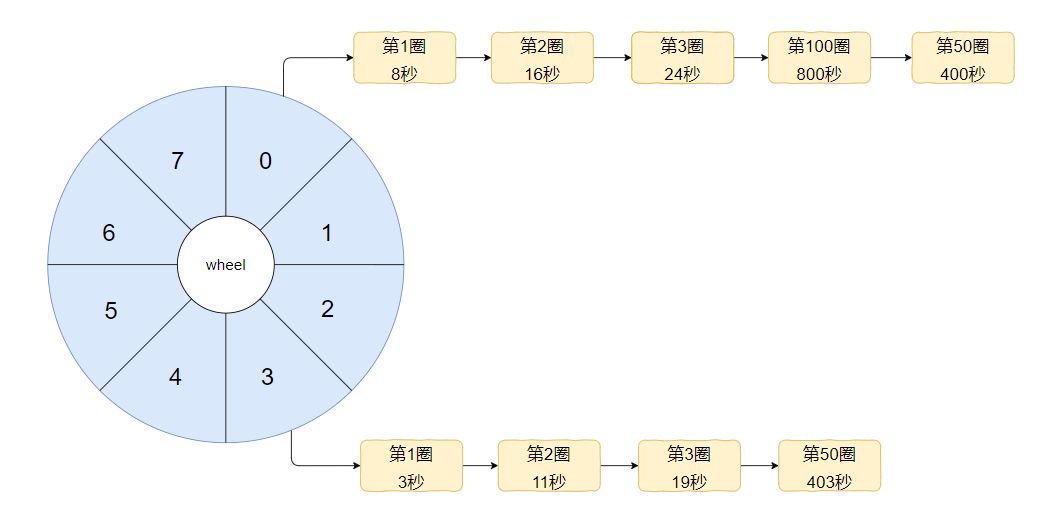
好,现在又来一个 403 秒后需要执行的任务,应该挂在哪儿?
403 mod 8 = 3,那么就是这样的:
我为什么要不厌其烦的给你说怎么计算,怎么挂到对应的下标中去呢?
因为我还需要引出一个东西:待分配任务的队列。
上面画 800 秒、 400 秒和 403 秒的任务的时候,我还省略了一步。
其实应该是这样的:

任务并不是实时挂到时间轮上去的,而是先放到一个待分配的队列中,等到特定的时间再把待分配队列中的任务挂到时间轮上去。
具体是什么时候呢?
下面讲源码的时候再说。
其实除了待分配队列外,还有一个任务取消的队列。
因为放入到时间轮的任务是可以被取消的。
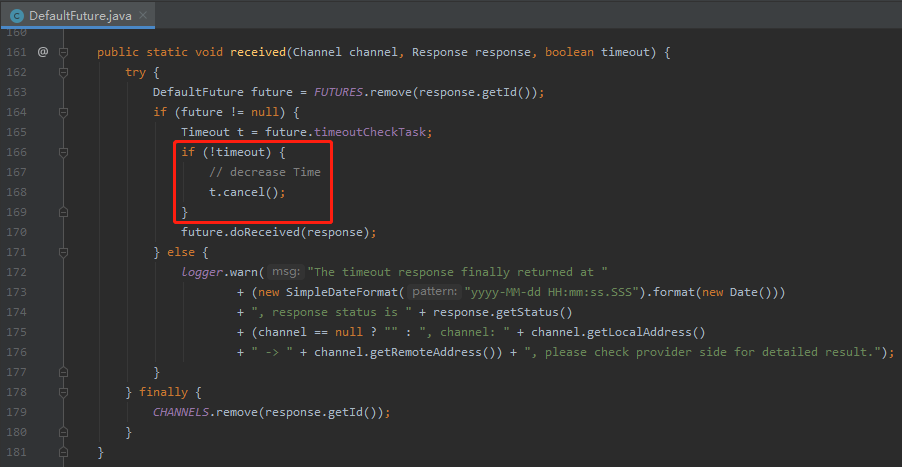
比如在 Dubbo 里面,检验调用是否超时也用的是时间轮机制。
假设一个调用的超时时间是 5s,5s 之后需要触发任务,抛出超时异常。
但是如果请求在 2s 的时候就收到了响应,没有超时,那么这个任务是需要被取消的。
对应的源码就是这块,看不明白没关系,看一眼就行了,我只是为了证明我没有骗你:
org.apache.dubbo.remoting.exchange.support.DefaultFuture#received
原理画图出来大概就是这样,然后我还差一张图。
把源码里面的字段的名称给你对应到上面的图中去。
主要把这几个对象给你对应上,后面看源码就不会太吃力了:

对应起来是这样的:
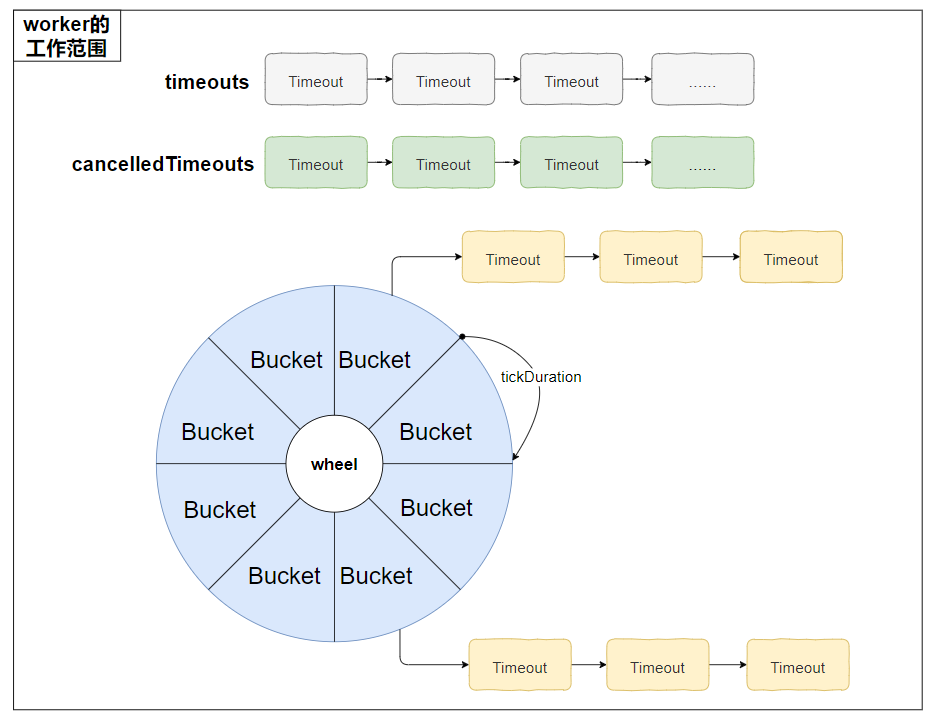
注意左上角的“worker的工作范围”把整个时间轮包裹了起来,后面看源码的时候你会发现其实整个时间轮的核心逻辑里面没有线程安全的问题,因为 worker 这个单线程把所有的活都干完了。
最后,再提一嘴:比如在前面 FailbackClusterInvoker 的场景下,时间轮触发了重试的任务,但是还是失败了,怎么办呢?
很简单,再次把任务放进去就行了,所以你看源码里面,有一个叫做 rePut 的方法,干的就是这事:
org.apache.dubbo.rpc.cluster.support.FailbackClusterInvoker.RetryTimerTask#run

这里的含义就是如果重试出现异常,且没有超过指定重试次数,那么就可以再次把任务仍回到时间轮里面。
等等,我这里知道“重试次数”之后,还能干什么事儿呢?
比如如果你对接过微信支付,它的回调通知有这样的一个时间间隔:
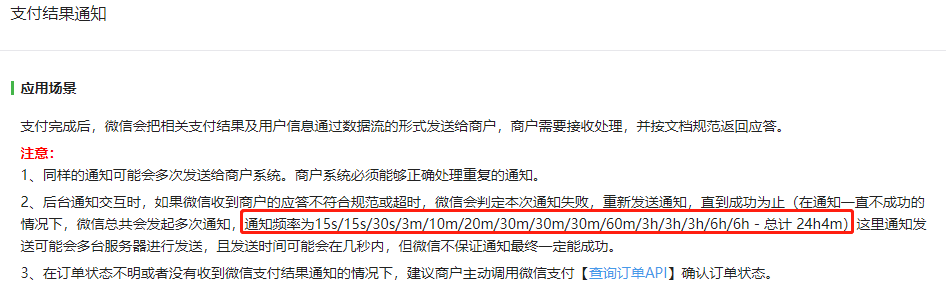
我知道当前重试的次数,那么我就可以在第 5 次重试的时候把时间设置为 10 分钟,扔到时间轮里面去。
时间轮就可以实现上面的需求。
当然了,MQ 的延迟队列也可以,但是不是本文的讨论范围。
但是用时间轮来做上面这个需求还有一个问题:那就是任务在内存中,如果服务挂了就没有了,这是一个需要注意的地方。
除了 FailbackClusterInvoker 外,其实我觉得时间轮更合适的地方是做心跳。
这可太合适了, Dubbo 的心跳就是用的时间轮来做。
org.apache.dubbo.remoting.exchange.support.header.HeartbeatTimerTask#doTask

从上图可以看到,doTask 方法就是发送心跳包,每次发送完成之后调用 reput 方法,然后再次把发送心跳包的任务仍回给时间轮。
好了,不再扩展应用场景了。
接下来,进入源码分析,跟上节奏,不要乱,大家都能学。
开卷!

时间轮源码
前面把原理理解到位了,接下来就可以看一下我们的源码了。
先说明一下,为了方便我截图,下面的部分截图我是移动了源码的位置,所以可能和你看源码的时候有点不一样。
我们再次审视 Dubbo 的 FailbackClusterInvoker 类中关于时间轮的用法。
首先 failTimer 这个对象,是一个很眼熟的双重检查的单例模式:

这里初始化的 failTimer 就是 HashedWheelTimer 对象关键的逻辑是调用了它的构造方法。
所以,我们先从它的构造方法入手,开始撕它。
先说一下它的几个入参分别是干啥的:
-
threadFactory:线程工厂,可以指定线程的名称和是否是守护进程。 -
tickDuration:两个 tick 之间的时间间隔。 -
unit:tickDuration 的时间单位。 -
ticksPerWheel:时间轮里面的 tick 的个数。 -
maxPendingTimeouts:时间轮中最大等待任务的个数。
所以,Dubbo 这个时间轮的含义就是这样的:
创建一个线程名称为 failback-cluster-timer 的守护线程,每隔一秒执行一次任务。这个时间轮的大小为 32,最大的等待处理任务个数是 failbackTasks,这个值是可以配置的,默认值是 100。
但是很多其他的使用场景下,比如 Dubbo 检查调用是否超时,就没有送 maxPendingTimeouts 这个值:
org.apache.dubbo.remoting.exchange.support.DefaultFuture#TIME_OUT_TIMER
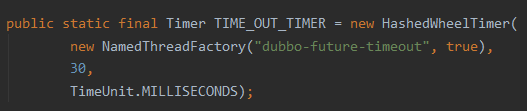
它甚至连 ticksPerWheel 都没有上送。
其实这两个参数都是有默认值的。ticksPerWheel 默认为 512。maxPendingTimeouts 默认为 -1,含义为对等待处理的任务个数不限制:

好了,现在我们整体看一下这个时间轮的构造方法,每一行的作用我都写上了注释:
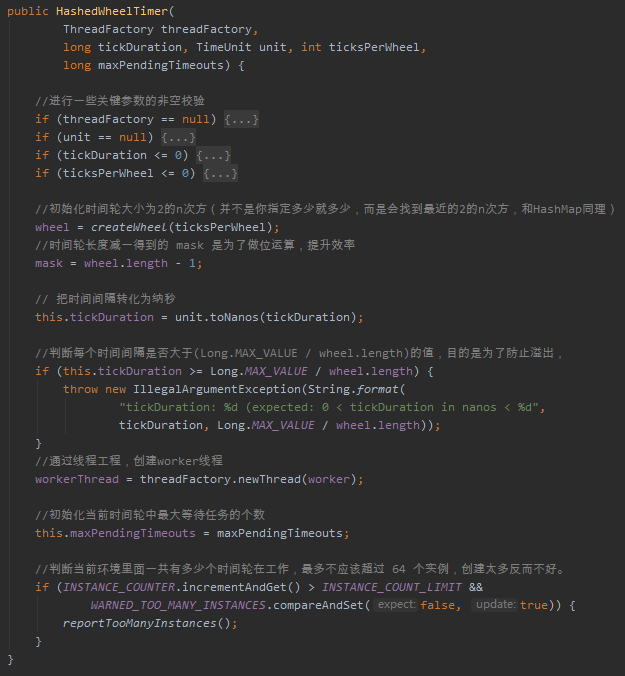
有几个地方,我也单独拿出来给你说一下。
比如 createWheel 这个方法,如果你八股文背的熟悉的话,你就知道这里和 HashMap 里面确认容量的核心代码是一样一样的。
这也是我在源码注释里面提到的,时间轮里面数组的大小必须是 2 的 n 次方。
为什么,你问我为什么?
别问,问就是为了后面做位运算,操作骚,速度快,逼格高。
我相信下面的这一个代码片段不需要我来解释了,你要是不理解,就再去翻一番 HashMap 的八股文:
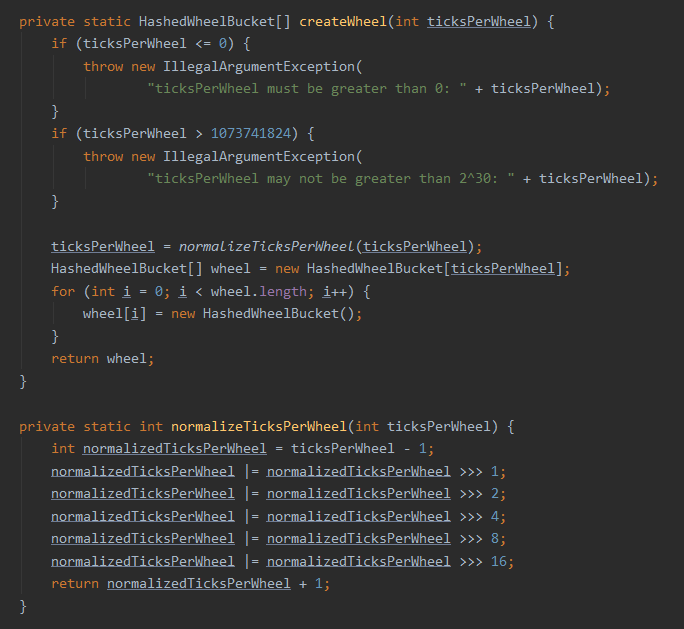
但是这一行代码我还是可以多说一句的 mask = wheel.length - 1。
因为我们已经知道 wheel.length 是 2 的 n 次方。
那么假设我们的定时任务的延迟执行时间是 x,那么它应该在时间轮的哪个格子里面呢?
是不是应该用 x 对长度取余,也就是这样计算: x % wheel.length。
但是,取余操作的效率其实不算高。
那么怎么能让这个操作快起来呢?
就是 wheel.length – 1。
wheel.length 是 2 的 n 次方,减一之后它的二级制的低位全部都是 1,举个例子就是这样式儿的:
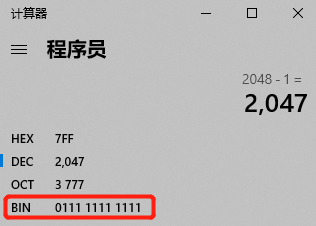
所以 x % wheel.length = x & (wheel.length – 1)。
在源码里面 mask =wheel.length – 1。
那么 mask 在哪用的呢?
其中的一个地方就是在 Worker 类的 run 方法里面:
org.apache.dubbo.common.timer.HashedWheelTimer.Worker
这里计算出来的 idx 就是当前需要处理的数组的下标。
我这里只是告诉你 mask 确实是参与了 & 位运算,所以你看不懂这块的代码也没有关系,因为我还没讲到这里来。
所以没跟上的同学不要慌,我们接着往下看。
前面我们已经有一个时间轮了,那么怎么调用这个时间呢?
其实就是调用它的 newTimeout 方法:

这个方法有三个入参:

含义很明确,即指定任务(task)在指定时间(delay,unit)之后开始触发。
接下来解读一下 newTimeout 方法:
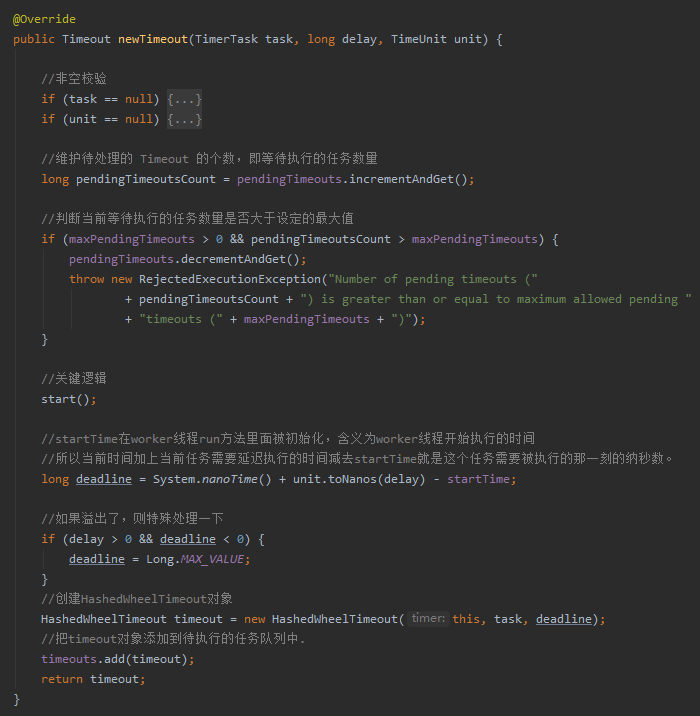
里面最关键的代码是 start 方法,我带大家看一下到底是在干啥:
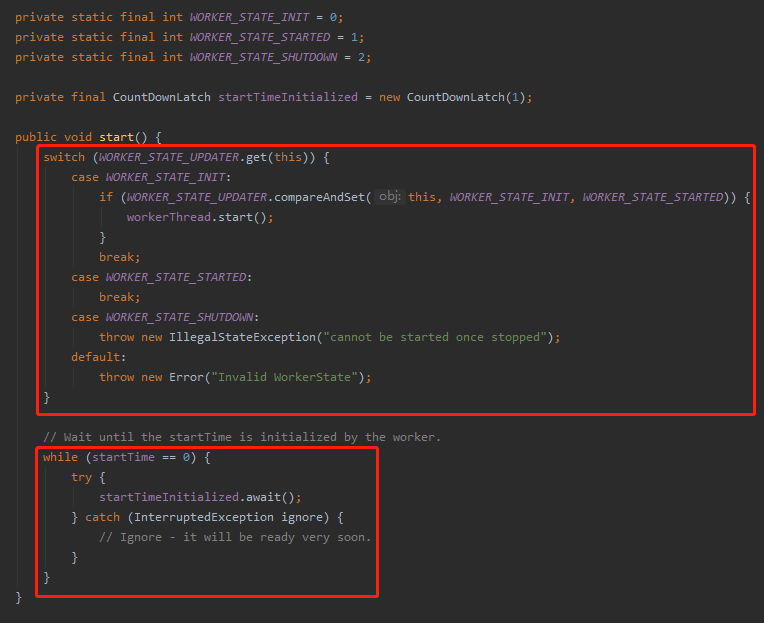
分成上下两部分讲。
上面其实就是维护或者判断当前 HashedWheelTimer 的状态,从源码中我们知道状态有三个取值:
-
0:初始化 -
1:已启动 -
2:已关闭
如果是初始化,那么通过一个 cas 操作,把状态更新为已启动,并执行 workerThread.start() 操作,启动 worker 线程。
下面这个部分就稍微有一点点费解了。
如果 startTime 等于 0,即没有被初始化的话,就调用 CountDownLatch 的 await 等待一下下。
而且这个 await 还是在主线程上的 await,主线程在这里等着 startTime 被初始化,这是个什么逻辑呢?
首先,我们要找一下 startTime 是在哪儿被初始化的。
就是在 Worker 的 run 方法里面,而这个方法就是在前面 workerThread.start() 的时候触发的:
org.apache.dubbo.common.timer.HashedWheelTimer.Worker
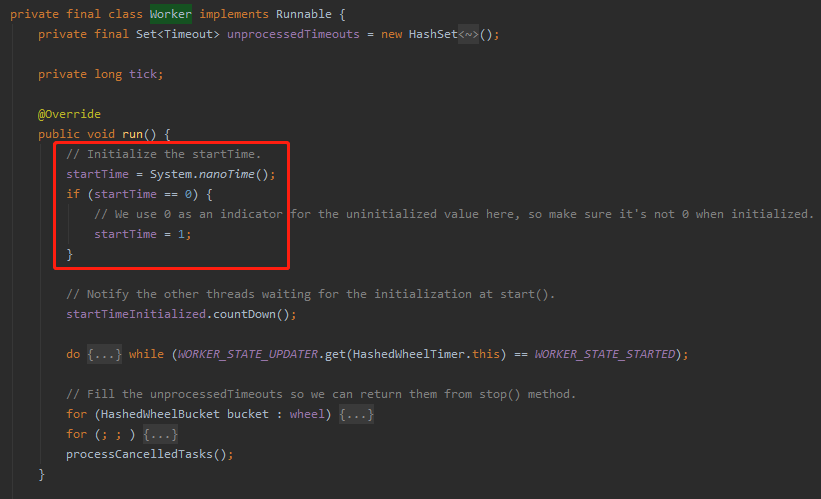
可以看到,对 startTime 初始化完成后,还判断了是否等于 0。也就是说 System.nanoTime() 方法是有可能返回为 0,一个小细节,如果你去要深究一下的话,也是很有趣的,我这里就不展开了。
startTime 初始化完成之后,立马执行了 startTimeInitialized.countDown() 操作。
这不就和这里呼应起来了吗?

主线程不马上就可以跑起来了吗?
那么问题就来了,这里大费周章的搞一个 startTime 初始化,搞不到主线程还不能继续往下执行是干啥呢?
当然是有用啦,回到 newTimeout 方法接着往下看:

我们分析一下上面这个等式哈。
首先 System.nanoTime() 是代码执行到这个地方的实时时间。
因为 delay 是一个固定值,所以 unit.toNanos(delay) 也是一个固定值。
那么 System.nanoTime()+unit.toNanos(delay) 就是这个任务需要被触发的纳秒数。
举个例子。
假设 System.nanoTime() = 1000,unit.toNanos(delay)=100。
那么这个任务被触发的时间点就是 1000+100=1100。
这个能跟上吧?
那么为什么要减去 startTime 呢?
startTime 我们前面分析了,其实初始化的时候也是 System.nanoTime(),初始化完成后就是一个固定值了。
那岂不是 System.nanoTime()-startTime 几乎趋近于 0?
这个等式 System.nanoTime()+unit.toNanos(delay)-startTime 的意义是什么呢?
是的,这就是我当时看源码的一个疑问。
但是后面我分析出来,其实整个等式里面只有 System.nanoTime() 是一个变量。
第一次计算的时候 System.nanoTime()-startTime 确实趋近于 0,但是当第二次触发的时候,即第二个任务来的时候,计算它的 deadline 的时候,System.nanoTime() 可是远大于 startTime 这个固定值的。
所以,第二次任务的执行时间点应该是当前时间加上指定的延迟时间减去 worker 线程的启动时间,后面的时间以此类推。
前面 newTimeout 方法就分析完了,也就是主线程在这个地方就执行完时间轮相关的逻辑了。
接下来该分析什么呢?
肯定是该轮到时间轮的 worker 线程上场发挥了啊。
worker 线程的逻辑都在 run 方法里面。
而核心逻辑就在一个 do-while 里面:

循环结束的条件是当前时间轮的状态不是启动状态。
也就是说,只要时间轮没有被调用 stop 逻辑,这个线程会一直在运行。
接下来我们逐行看一下循环里面的逻辑,这部分逻辑就是时间轮的核心逻辑。
首先是 final long deadline = waitForNextTick() 这一行,里面就很有故事:

首先你看这个方法名你就知道它是干啥的了。
是在这里面等待,直到下一个时刻的到来。
所以方法进来第一行就是计算下一个时刻的纳秒值是啥。
接着看 for 循环里面,前面部分都看的比较懵逼,只有标号为 ③ 的地方好理解的多,就是让当前线程睡眠指定时间。
所以前面的部分就是在算这个指定时间是什么。
怎么算的呢?
标号为 ① 的地方,前面部分还能看懂,
deadline – currentTime 算出来的就是还需要多长时间才会到下一个时间刻度。
后面直接就看不懂了。
里面的 1000000 好理解,单位是纳秒,换算一下就是 1 毫秒。
这个 999999 是啥玩意?
其实这里的 999999 是为了让算出来的值多 1 毫秒。
比如,deadline – currentTime 算出来是 1000123 纳秒,那么 1000123/1000000=1ms。
但是(1000123+999999)/1000000=2ms。
也就是说要让下面标号为 ③ 的地方,多睡 1ms。
这是为什么呢?
我也不知道,所以我先暂时不管了,留个坑嘛,问题不大,接着往下写。
下面就到了标号为 ② 的地方,看起来是对 windows 操作系统进行了特殊的处理,要把 sleepTimeMs 换算为 10 的倍数。
为啥?
这里我就得批评一下 Dubbo 了,把 Netty 的实现拿过来了,还把关键信息给隐藏了,这不合适吧。
这地方在 Netty 的源码中是这样的:

这里很清晰的指了个路:
//github.com/netty/netty/issues/356

而顺着这条路,一路往下跟,会找到这样一个地方:
//www.javamex.com/tutorials/threads/sleep_issues.shtml

没想到还有意外收获。
第一个划线的地方大概意思是说当线程调用 Thread.sleep 方法的时候,JVM 会进行一个特殊的调用,将中断周期设置为 1ms。
因为 Thread.sleep 方法的实现是依托于操作系统提供的中断检查,也就是操作系统会在每一个中断的时候去检查是否有线程需要唤醒并且提供 CPU 资源。所以我觉得前面多睡 1ms 的原因就可以用这个原因来解释了。
前面留的坑,这么快就填上了,舒服。
而第二个划线的地方说的是,如果是 windows 的话,中断周期可能是 10ms 或者 15ms,具体和硬件相关。
所以,如果是 windows 的话,需要把睡眠时间调整为 10 的倍数。
一个没啥卵用的知识,送给你。
前面几个问题了解清楚了,waitForNextTick 方法也就理解到位了,它干的事儿就是等,等一个时间刻度的时间,等一个 tick 长度的时间。
等到了之后呢?
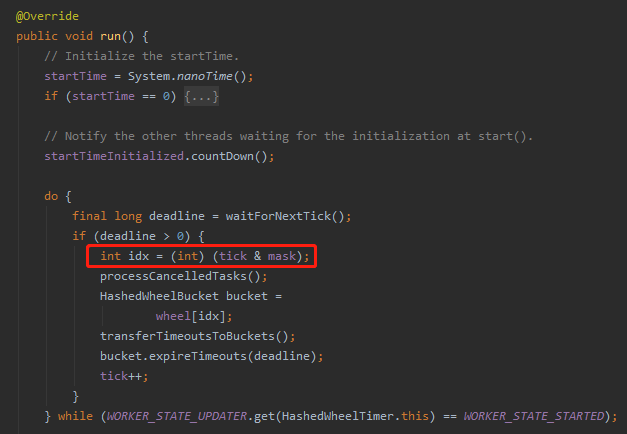
就来到了这一行代码 int idx = (int) (tick & mask)
我们前面分析过,计算当前时间对应的下标,位运算,操作骚,速度快,逼格高,不多说。
然后代码执行到这个方法 processCancelledTasks()
看方法名称就知道了,是处理被取消的任务的队列:
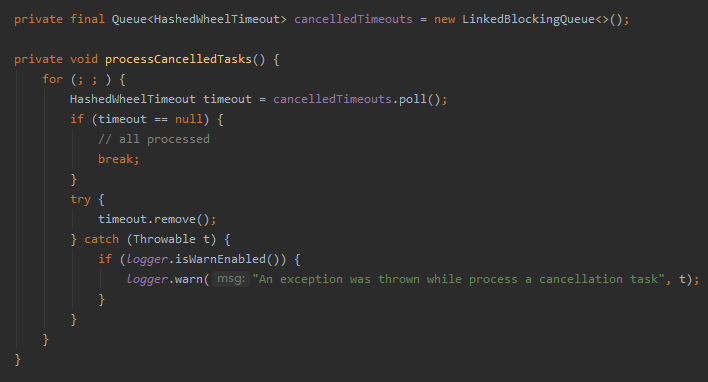
逻辑很简单,一目了然,就是把 cancelledTimeouts 队列给清空。
这里是在 remove,在清理。
那么哪里在 add,在添加呢?
就是在下面这个方法中:
org.apache.dubbo.common.timer.HashedWheelTimer.HashedWheelTimeout#cancel
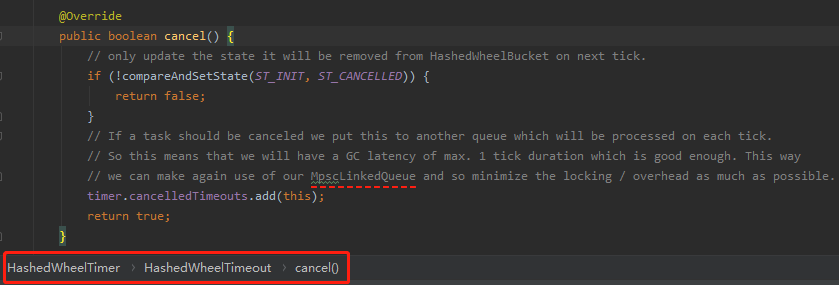
如果调用了 HashedWheelTimeout 的 cancel 方法,那么这个任务就算是被取消了。
前面画图的时候就提到了这个方法,逻辑也很清晰,所以不多解释了。
但是你注意我画了下划线的地方:MpscLinkedQueue。
这是个啥?
这是一个非常牛逼的无锁队列。
但是 Dubbo 这里的 cancelledTimeouts 队列的数据结构明明用的是 LinkedBlockingQueue 呀?
怎么回事呢?
因为这里的注释是 Netty 里面的,Netty 里面用的是 MpscLinkedQueue。
你看我给你对比一下 Netty 和 Dubbo 这里的区别:
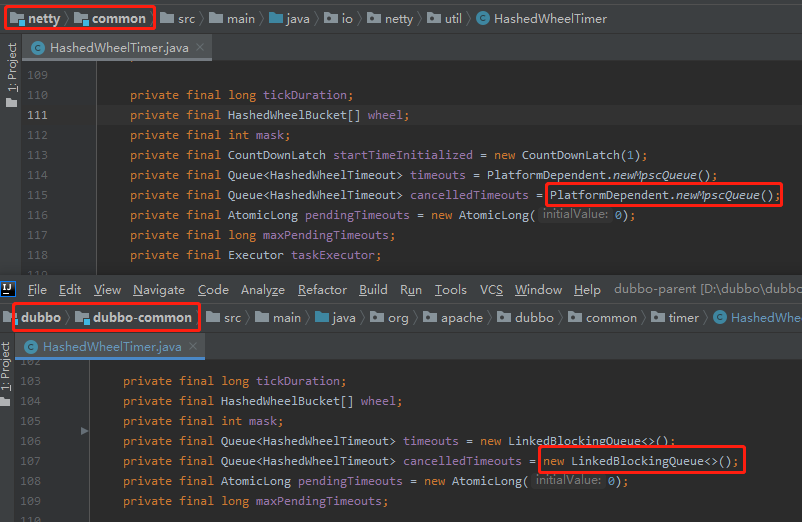
所以这里的注解是有误导的,你有时间的话可以给 Dubbo 提给 pr 修改一下。
又拿捏了一个小细节。

好了,我们接着往下卷,来到了这行代码 HashedWheelBucket bucket=wheel[idx]
一目了然,没啥说的。
从时间轮里面获取指定下标的 bucket。
主要看看它下面的这一行代码 transferTimeoutsToBuckets()
我还是每一行都加上注释:

所以这个方法的核心逻辑就是把等待分配的任务都发配到指定的 bucket 上去。
这里也就回答了我画图的时候留下的一个问题:什么时候把等待分配队列里面的任务挂到时间轮上去呢?
就是这个时候。
接下来分析 bucket.expireTimeouts(deadline) 这一行代码。
你看这个方法的调用方就是 bucket,它代表的含义就是准备开始处理这个 bucket 里面的这个链表中的任务了:

最后,还有一行代码 tick++
表示当前这个 tick 已经处理完成了,开始准备下一个时间刻度。
关键代码就分析完了。
一遍看不懂就多看一遍,但是我建议你自己也对照着源码一起看,很快就能搞懂。
相信以后面试官问到时间轮的时候你可以和他战斗上一个回合了。
为什么是一个回合呢?
因为得你回答完这个时间轮后,一般来说,面试官会追问一个:
嗯,说的很不错,那你再介绍一下层级时间轮吧?
当时你就懵逼了:什么,层级时间轮是什么鬼,歪歪没写啊?
是的,怪我,我没写,下次,下次一定。
但是我可以给你指条路,去看看 kafka 对于时间轮的优化。你会看的鼓起掌来。

几个相关的 issues
最后,关于 Dubbo 时间轮,在 issues 里面有一个讨论:
//github.com/apache/dubbo/issues/3324

大家有兴趣的可以去看看。
其中提到了一个有意思的问题:
Netty 在 3.x 中有大量使用 HashedWheelTimer,但是在 4.1 中,我们可以发现,Netty 保留了 HashedWheelTimer,但在其源码中并未使用它,而是选择了 ScheduledThreadPoolExecutor,不知道它的用意是什么。
这个问题得到了 Netty 的维护者的亲自答:
//github.com/netty/netty/issues/8774
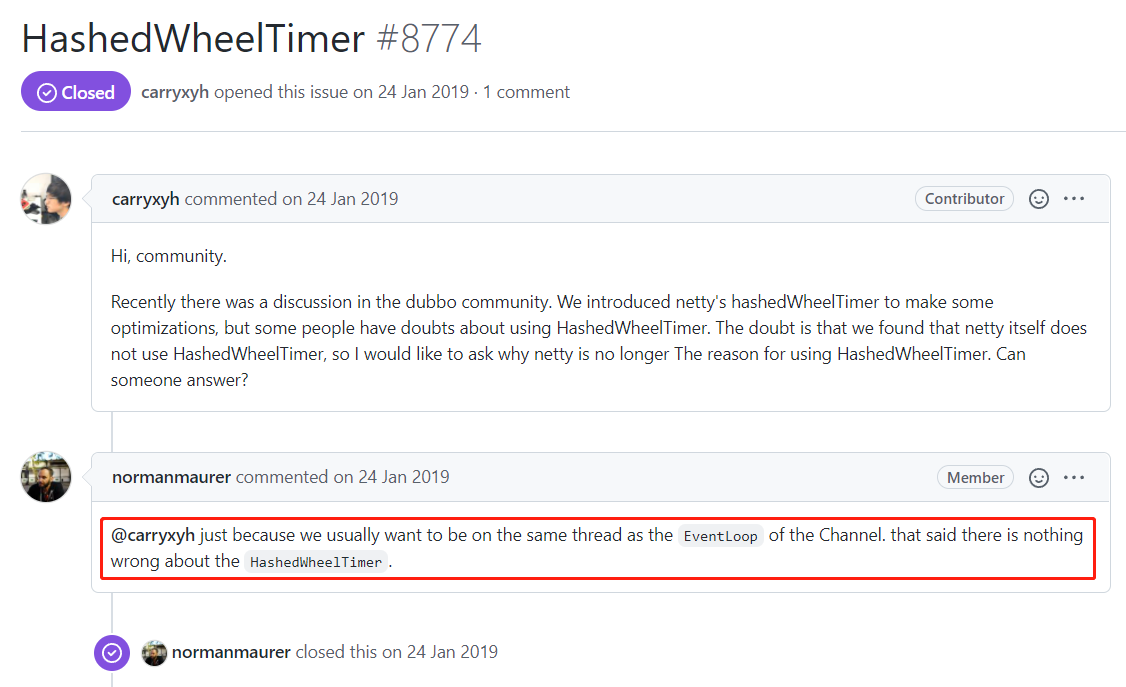
他的意思是时间轮其实没有任何毛病,我没有用只是因为我们希望与通道的EventLoop位于同一线程上。
在 Netty 里面,有个老哥发现时间轮并没有用上了,甚至想把它给干掉:
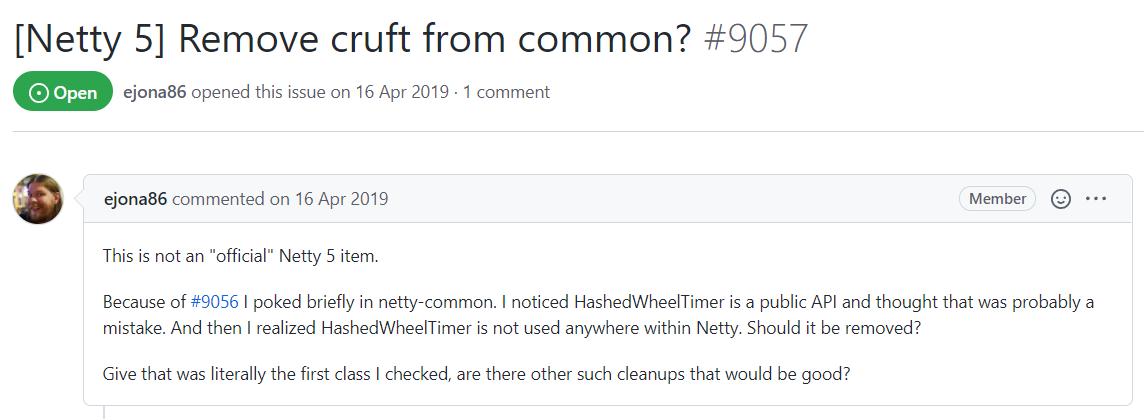
我寻思这属于工具类啊,你留着呗,总是会有用的。
另外,前面的 issue 还提到了另外一个问题:
//github.com/apache/dubbo/issues/1371
这也是 Dubbo 引入时间轮之后进行的优化。
带你看一眼,上面是优化之后的,下面是之前的写法:
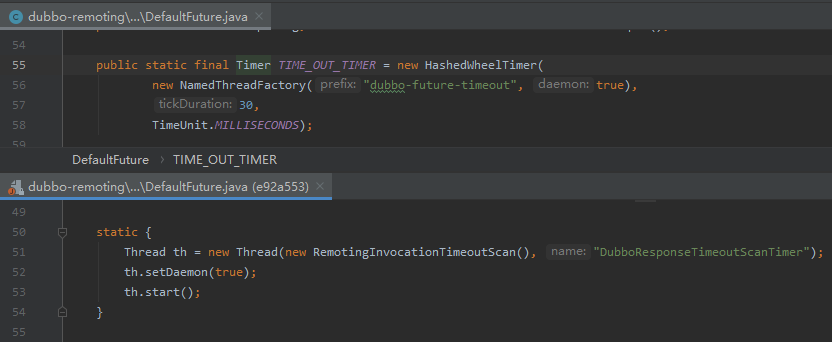
在之前的写法中,就是后台起一个线程,然后搞个死循环,一遍遍的去扫整个集合:
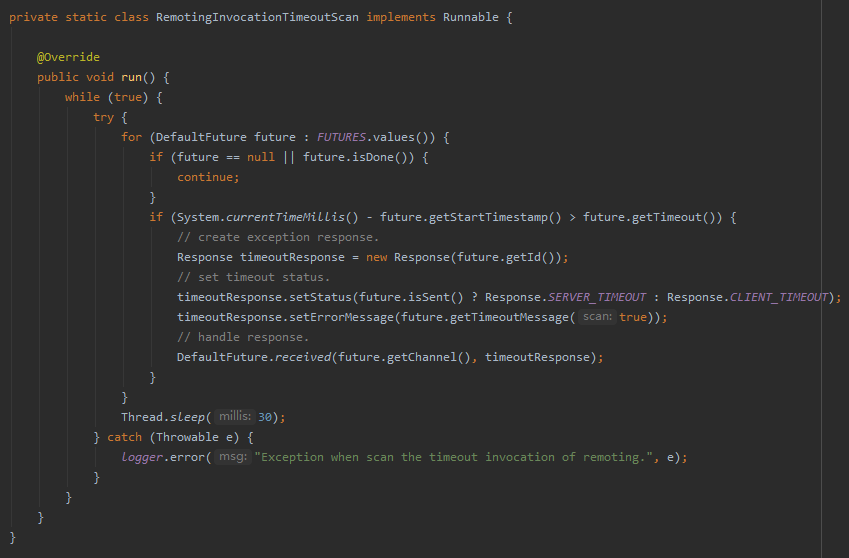
这种方案也能实现需求,但是和时间轮的写法比起来,高下立判。
操作骚,速度快,逼格高。

最后说一句
好了,看到了这里了,转发、在看、点赞随便安排一个吧,要是你都安排上我也不介意。写文章很累的,需要一点正反馈。
给各位读者朋友们磕一个了:




