scrapy-redis非多网址采集的使用
问题描述
默认RedisSpider在启动时,首先会读取redis中的spidername:start_urls,如果有值则根据url构建request对象。
现在的要求是,根据特定关键词采集。
例如:目标站点有一个接口,根据post请求参数来返回结果。
那么,在这种情况下,构建request主要的变换就是请求体(body),API接口是不变的。
对于原来通过url构建request的策略就不再适用了。
所以,此时我们需要对相应的方法进行重写。
重写方法
爬虫类需要继承至scrapy_redis.spiders.RedisSpider
start_requests
我需要从数据库拿到关键词数据,然后用关键词构建请求。
此时,我们将关键词看作start_url,将关键词push到redis中
首先,写一个将单个关键词push到redis的方法
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
self.redis_key如果没有做任何声明,则默认为 spidername:start_urls
接着重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上述代码中有一个self.isproducer,此方法用于检测当前程序是不是生产者,即向redis提供关键词
isproducer
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
关于scrapy命令行的更多参数,参考文档://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/shell.html
make_request_from_data
查看RedisMixin中的make_request_from_data
方法注释信息:
Returns a Request instance from data coming from Redis.
根据来源于redis的数据返回一个Request对象
By default,
datais an encoded URL. You can override this method to
provide your own message decoding.默认情况下,
data是已编码的URL链接。您可以将此方法重写为提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将data转为字符串(网站链接字符串),接着调用了 make_requests_from_url,通过url构建request对象
data从哪里来?
查看RedisMixin的next_request方法
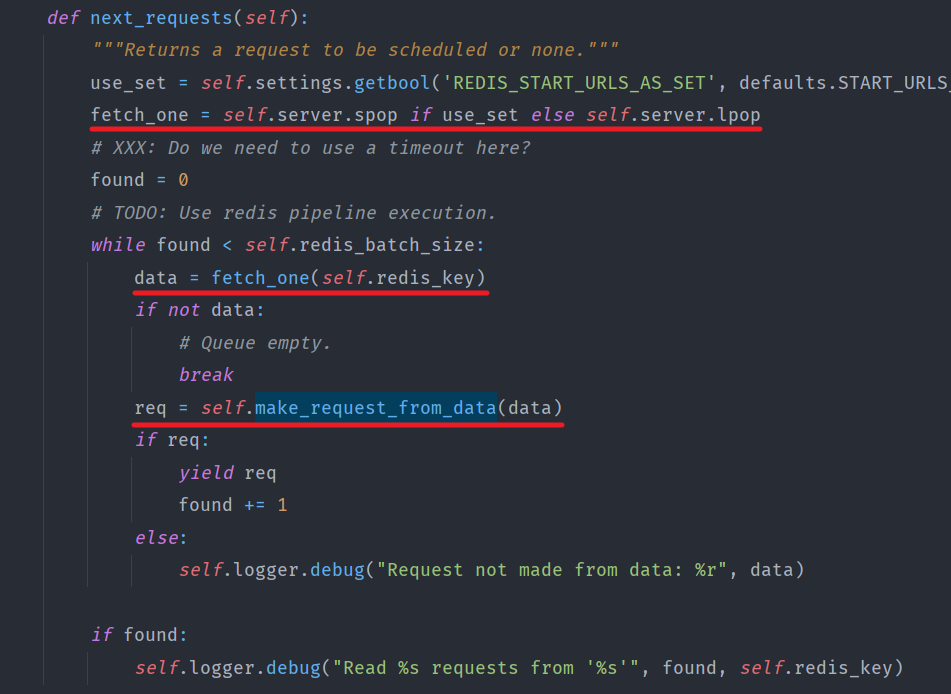
由此得知,data是从redis中pop出来的,在之前我们将data序列化后push进去,现在pop出来,我们将其反序列化并依靠它构建request对象
重写make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在本例中构建
request对象的方法是self.make_request_from_book_info,在实际开发中,根据目标站请求规则编写构建request的方法即可。
最终效果
启动一个生成者
scrapy crawl myspider -a producer=1
生成者将所有的关键词push完之后,会转为消费者开始消费
在多个节点上启动消费者
scrapy crawl myspider
一个爬虫的开始,总是根据现有数据采集新的数据,例如,根据列表页中的详情页链接采集详情页数据,根据关键词采集搜索结果等等。根据现有数据的不同,开始的方法也不同,大体仍是大同小异的。


