5. SOFAJRaft源码分析— RheaKV中如何存放数据?
- 2019 年 11 月 10 日
- 笔记
概述
上一篇讲了RheaKV是如何进行初始化的,因为RheaKV主要是用来做KV存储的,RheaKV读写的是相当的复杂,一起写会篇幅太长,所以这一篇主要来讲一下RheaKV中如何存放数据。
我们这里使用一个客户端的例子来开始本次的讲解:
public static void main(final String[] args) throws Exception { final Client client = new Client(); client.init(); //get(client.getRheaKVStore()); RheaKVStore rheaKVStore = client.getRheaKVStore(); final byte[] key = writeUtf8("hello"); final byte[] value = writeUtf8("world"); rheaKVStore.bPut(key, value); client.shutdown(); }我们从这个main方法中启动我们的实例,调用rheaKVStore.bPut(key, value)方法将数据放入到RheaKV中。
public class Client { private final RheaKVStore rheaKVStore = new DefaultRheaKVStore(); public void init() { final List<RegionRouteTableOptions> regionRouteTableOptionsList = MultiRegionRouteTableOptionsConfigured .newConfigured() // .withInitialServerList(-1L /* default id */, Configs.ALL_NODE_ADDRESSES) // .config(); final PlacementDriverOptions pdOpts = PlacementDriverOptionsConfigured.newConfigured() // .withFake(true) // .withRegionRouteTableOptionsList(regionRouteTableOptionsList) // .config(); final RheaKVStoreOptions opts = RheaKVStoreOptionsConfigured.newConfigured() // .withClusterName(Configs.CLUSTER_NAME) // .withPlacementDriverOptions(pdOpts) // .config(); System.out.println(opts); rheaKVStore.init(opts); } public void shutdown() { this.rheaKVStore.shutdown(); } public RheaKVStore getRheaKVStore() { return rheaKVStore; } } public class Configs { public static String ALL_NODE_ADDRESSES = "127.0.0.1:8181,127.0.0.1:8182,127.0.0.1:8183"; public static String CLUSTER_NAME = "rhea_example"; }Client在调用init方法初始化rheaKVStore的时候和我们上一节中讲的server例子很像,区别是少了StoreEngineOptions的设置和多配置了一个regionRouteTableOptionsList实例。
bPut存入数据
我们这里存入数据会调用DefaultRheaKVStore的bPut方法:
DefaultRheaKVStore#bPut
public Boolean bPut(final byte[] key, final byte[] value) { return FutureHelper.get(put(key, value), this.futureTimeoutMillis); }bPut方法里面主要的存放数据的操作在put方法里面做的,put方法会返回一个CompletableFuture给FutureHelper的get方法调用,并且在bPut方法里面会放入一个超时时间,在init方法中初始化的,默认是5秒。
接下来我们进入到put方法中:
DefaultRheaKVStore#put
public CompletableFuture<Boolean> put(final byte[] key, final byte[] value) { Requires.requireNonNull(key, "key"); Requires.requireNonNull(value, "value"); //是否尝试进行批量的put return put(key, value, new CompletableFuture<>(), true); }这里会调用put的重载的方法,第三个参数是表示传入一个空的回调函数,第四个参数表示采用Batch 批量存储
DefaultRheaKVStore#put
private CompletableFuture<Boolean> put(final byte[] key, final byte[] value, final CompletableFuture<Boolean> future, final boolean tryBatching) { //校验一下是否已经init初始化了 checkState(); if (tryBatching) { //putBatching实例在init方法中被初始化 final PutBatching putBatching = this.putBatching; if (putBatching != null && putBatching.apply(new KVEntry(key, value), future)) { //由于我们传入的是一个空的实例,所以这里直接返回 return future; } } //直接存入数据 internalPut(key, value, future, this.failoverRetries, null); return future; }checkState方法会去校验started这个属性有没有被设置,如果调用过DefaultRheaKVStore的init方法进行初始化过,那么会设置started为ture。
这里还会调用init方法里面初始化过的putBatching实例,我们下面看看putBatching实例做了什么。
putBatching批量存入数据
putBatching在init实例初始化的时候会传入一个PutBatchingHandler作为处理器:
this.putBatching = new PutBatching(KVEvent::new, "put_batching", new PutBatchingHandler("put"));我们下面看看PutBatching的构造方法:
public PutBatching(EventFactory<KVEvent> factory, String name, PutBatchingHandler handler) { super(factory, batchingOpts.getBufSize(), name, handler); }这里由于PutBatching继承了Batching这个抽象类,所以在实例化的时候直接调用父类的构造器实例化:
public Batching(EventFactory<T> factory, int bufSize, String name, EventHandler<T> handler) { this.name = name; this.disruptor = new Disruptor<>(factory, bufSize, new NamedThreadFactory(name, true)); this.disruptor.handleEventsWith(handler); this.disruptor.setDefaultExceptionHandler(new LogExceptionHandler<Object>(name)); this.ringBuffer = this.disruptor.start(); }在Batching构造器里面会初始化一个Disruptor实例,并将我们传入的PutBatchingHandler处理器作为Disruptor的处理器,所有传入PutBatching的数据都会经过PutBatchingHandler来处理。
我们下面看看PutBatchingHandler是怎么处理数据的:
PutBatchingHandler#onEvent
public void onEvent(final KVEvent event, final long sequence, final boolean endOfBatch) throws Exception { //1.把传入的时间加入到集合中 this.events.add(event); //加上key和value的长度 this.cachedBytes += event.kvEntry.length(); final int size = this.events.size(); //BatchSize等于100 ,并且maxWriteBytes字节数32768 //2. 如果不是最后一个event,也没有这么多数量的数据,那么就不发送 if (!endOfBatch && size < batchingOpts.getBatchSize() && this.cachedBytes < batchingOpts.getMaxWriteBytes()) { return; } //3.如果传入的size为1,那么就重新调用put方法放入到Batching里面 if (size == 1) { //重置events和cachedBytes reset(); final KVEntry kv = event.kvEntry; try { put(kv.getKey(), kv.getValue(), event.future, false); } catch (final Throwable t) { exceptionally(t, event.future); } // 4.如果size不为1,那么把数据遍历到集合里面批量处理 } else { //初始化一个长度为size的list final List<KVEntry> entries = Lists.newArrayListWithCapacity(size); final CompletableFuture<Boolean>[] futures = new CompletableFuture[size]; for (int i = 0; i < size; i++) { final KVEvent e = this.events.get(i); entries.add(e.kvEntry); //使用CompletableFuture构建异步应用 futures[i] = e.future; } //遍历完events数据到entries之后,重置 reset(); try { //当put方法完成后执行whenComplete中的内容 put(entries).whenComplete((result, throwable) -> { //如果没有抛出异常,那么通知所有future已经执行完毕了 if (throwable == null) { for (int i = 0; i < futures.length; i++) { futures[i].complete(result); } return; } exceptionally(throwable, futures); }); } catch (final Throwable t) { exceptionally(t, futures); } } } - 进入这个方法的时候会把这个event加入到events集合中,然后把汇总长度和events的size
- 由于所有的event都是发往Disruptor,然后分发到PutBatchingHandler进行处理,所以可以通过endOfBatch参数判断这个分发过来的event是不是最后一个,如果不是最后一个,并且总共的event数量没有超过默认的100,cachedBytes没有超过32768,那么就直接返回,等凑够了批次再处理
- 走到这个判断,说明只有一条数据过来,那么就重新调用put方法,设置tryBatching为false,那么会直接走internalPut方法
- 如果size不等于1,那么就会把所有的event都加入到集合里面,然后调用put方法批量处理,当处理完之后调用whenComplete方法对返回的结果进行一场或回调处理
往RheaKV中批量put设值
下面我来讲一下PutBatchingHandler#onEvent中的put(entries)这个方法是怎么处理批量数据的,这个方法会调用到DefaultRheaKVStore的put方法。
DefaultRheaKVStore#put
public CompletableFuture<Boolean> put(final List<KVEntry> entries) { //检查状态 checkState(); Requires.requireNonNull(entries, "entries"); Requires.requireTrue(!entries.isEmpty(), "entries empty"); //存放数据 final FutureGroup<Boolean> futureGroup = internalPut(entries, this.failoverRetries, null); //处理返回状态 return FutureHelper.joinBooleans(futureGroup); }该方法会调用internalPut进行设值操作。
DefaultRheaKVStore#internalPut
private FutureGroup<Boolean> internalPut(final List<KVEntry> entries, final int retriesLeft, final Throwable lastCause) { //组装Region和KVEntry的映射关系 final Map<Region, List<KVEntry>> regionMap = this.pdClient .findRegionsByKvEntries(entries, ApiExceptionHelper.isInvalidEpoch(lastCause)); final List<CompletableFuture<Boolean>> futures = Lists.newArrayListWithCapacity(regionMap.size()); final Errors lastError = lastCause == null ? null : Errors.forException(lastCause); for (final Map.Entry<Region, List<KVEntry>> entry : regionMap.entrySet()) { final Region region = entry.getKey(); final List<KVEntry> subEntries = entry.getValue(); //设置重试回调函数,并将重试次数减一 final RetryCallable<Boolean> retryCallable = retryCause -> internalPut(subEntries, retriesLeft - 1, retryCause); final BoolFailoverFuture future = new BoolFailoverFuture(retriesLeft, retryCallable); //把数据存放到region中 internalRegionPut(region, subEntries, future, retriesLeft, lastError); futures.add(future); } return new FutureGroup<>(futures); }因为一个Store里面会有很多的Region,所以这个方法首先会去组装Region和KVEntry的关系,确定这个KVEntry是属于哪个Region的。
然后设置好回调函数后调用internalRegionPut方法将subEntries存入到Region中。
组装Region和KVEntry的映射关系
我们下面看看是怎么组装的:
pdClient是FakePlacementDriverClient的实例,继承了AbstractPlacementDriverClient,所以调用的是父类的findRegionsByKvEntries方法
AbstractPlacementDriverClient#findRegionsByKvEntries
public Map<Region, List<KVEntry>> findRegionsByKvEntries(final List<KVEntry> kvEntries, final boolean forceRefresh) { if (forceRefresh) { refreshRouteTable(); } //regionRouteTable里面存了region的路由信息 return this.regionRouteTable.findRegionsByKvEntries(kvEntries); }因为我们这里是用的FakePlacementDriverClient,所以refreshRouteTable返回的是一个空方法,所以往下走是调用RegionRouteTable的findRegionsByKvEntries的方法
RegionRouteTable#findRegionsByKvEntries
public Map<Region, List<KVEntry>> findRegionsByKvEntries(final List<KVEntry> kvEntries) { Requires.requireNonNull(kvEntries, "kvEntries"); //实例化一个map final Map<Region, List<KVEntry>> regionMap = Maps.newHashMap(); final StampedLock stampedLock = this.stampedLock; final long stamp = stampedLock.readLock(); try { for (final KVEntry kvEntry : kvEntries) { //根据kvEntry的key去找和region的startKey最接近的region final Region region = findRegionByKeyWithoutLock(kvEntry.getKey()); //设置region和KVEntry的映射关系 regionMap.computeIfAbsent(region, k -> Lists.newArrayList()).add(kvEntry); } return regionMap; } finally { stampedLock.unlockRead(stamp); } } private Region findRegionByKeyWithoutLock(final byte[] key) { // return the greatest key less than or equal to the given key //rangeTable里面存的是region的startKey,value是regionId // 这里返回小于等于key的第一个元素 final Map.Entry<byte[], Long> entry = this.rangeTable.floorEntry(key); if (entry == null) { reportFail(key); throw reject(key, "fail to find region by key"); } //regionTable里面存的regionId,value是region return this.regionTable.get(entry.getValue()); }findRegionsByKvEntries方法会遍历所有的KVEntry集合,然后调用findRegionByKeyWithoutLock去rangeTable里面找合适的region,由于rangeTable是一个treemap,所以调用了floorEntry返回的是小于等于key的第一个region。
然后将region放入到regionMap里,key是regionMap,value是一个KVEntry集合。
regionRouteTable里面的数据是在DefaultRheaKVStore初始化的时候传入的,不记得的同学我给出了初始化路由表的过程:
DefaultRheaKVStore#init->FakePlacementDriverClient#init-> AbstractPlacementDriverClient#init->AbstractPlacementDriverClient#initRouteTableByRegion->regionRouteTable#addOrUpdateRegion数据存放到相应的region中
我们接着DefaultRheaKVStore的internalPut的方法往下看到internalRegionPut方法,这个方法是真正存储数据的地方:
DefaultRheaKVStore#internalRegionPut
private void internalRegionPut(final Region region, final List<KVEntry> subEntries, final CompletableFuture<Boolean> future, final int retriesLeft, final Errors lastCause) { //获取regionEngine final RegionEngine regionEngine = getRegionEngine(region.getId(), true); //重试函数,会回调当前的方法 final RetryRunner retryRunner = retryCause -> internalRegionPut(region, subEntries, future, retriesLeft - 1, retryCause); final FailoverClosure<Boolean> closure = new FailoverClosureImpl<>(future, false, retriesLeft, retryRunner); if (regionEngine != null) { if (ensureOnValidEpoch(region, regionEngine, closure)) { //获取MetricsRawKVStore final RawKVStore rawKVStore = getRawKVStore(regionEngine); //在init方法中根据useParallelKVExecutor属性决定是不是空 if (this.kvDispatcher == null) { //调用RockDB的api进行插入 rawKVStore.put(subEntries, closure); } else { //把put操作分发到kvDispatcher中异步执行 this.kvDispatcher.execute(() -> rawKVStore.put(subEntries, closure)); } } } else { //如果当前节点不是leader,那么则返回的regionEngine为null //那么发起rpc调用到leader节点中 final BatchPutRequest request = new BatchPutRequest(); request.setKvEntries(subEntries); request.setRegionId(region.getId()); request.setRegionEpoch(region.getRegionEpoch()); this.rheaKVRpcService.callAsyncWithRpc(request, closure, lastCause); } }这个方法首先调用getRegionEngine获取regionEngine,因为我们这里是client节点,没有初始化RegionEngine,所以这里获取的为空,会直接通过rpc请求发送,然后交由KVCommandProcessor进行处理。
如果当前的节点是server,并且该RegionEngine是leader,那么会调用rawKVStore然后调用put方法插入到RockDB中。
我们最后再看看rheaKVRpcService发送的rpc请求是怎么被处理的。
向服务端发送BatchPutRequest请求插入数据
向服务端发送put请求是通过调用DefaultRheaKVRpcService的callAsyncWithRpc方法发起的:
DefaultRheaKVRpcService#callAsyncWithRpc
public <V> CompletableFuture<V> callAsyncWithRpc(final BaseRequest request, final FailoverClosure<V> closure, final Errors lastCause) { return callAsyncWithRpc(request, closure, lastCause, true); } public <V> CompletableFuture<V> callAsyncWithRpc(final BaseRequest request, final FailoverClosure<V> closure, final Errors lastCause, final boolean requireLeader) { final boolean forceRefresh = ErrorsHelper.isInvalidPeer(lastCause); //获取leader的endpoint final Endpoint endpoint = getRpcEndpoint(request.getRegionId(), forceRefresh, this.rpcTimeoutMillis, requireLeader); //发起rpc调用 internalCallAsyncWithRpc(endpoint, request, closure); return closure.future(); }在这个方法里会调用getRpcEndpoint方法来获取region所对应server的endpoint,然后对这个节点调用rpc请求。调用rpc请求都是sofa的bolt框架进行调用的,所以下面我们重点看怎么获取endpoint
DefaultRheaKVRpcService#getRpcEndpoint
public Endpoint getRpcEndpoint(final long regionId, final boolean forceRefresh, final long timeoutMillis, final boolean requireLeader) { if (requireLeader) { //获取leader return getLeader(regionId, forceRefresh, timeoutMillis); } else { //轮询获取一个不是自己的节点 return getLuckyPeer(regionId, forceRefresh, timeoutMillis); } }这里有两个分支,一个是获取leader节点,一个是轮询获取节点。由于这两个方法挺有意思的,所以我们下面两个方法都讲一下
根据regionId获取leader节点
根据regionId获取leader节点是由getLeader方法触发的,在我们调用DefaultRheaKVStore的init方法实例化DefaultRheaKVRpcService的时候会重写getLeader方法:
DefaultRheaKVStore#init
this.rheaKVRpcService = new DefaultRheaKVRpcService(this.pdClient, selfEndpoint) { @Override public Endpoint getLeader(final long regionId, final boolean forceRefresh, final long timeoutMillis) { final Endpoint leader = getLeaderByRegionEngine(regionId); if (leader != null) { return leader; } return super.getLeader(regionId, forceRefresh, timeoutMillis); } };重写的getLeader方法会调用getLeaderByRegionEngine方法区根据regionId找Endpoint,如果找不到,那么会调用父类的getLeader方法。
DefaultRheaKVStore#getLeaderByRegionEngine
private Endpoint getLeaderByRegionEngine(final long regionId) { final RegionEngine regionEngine = getRegionEngine(regionId); if (regionEngine != null) { final PeerId leader = regionEngine.getLeaderId(); if (leader != null) { final String raftGroupId = JRaftHelper.getJRaftGroupId(this.pdClient.getClusterName(), regionId); RouteTable.getInstance().updateLeader(raftGroupId, leader); return leader.getEndpoint(); } } return null; }这个方法这里会获取RegionEngine,但是我们这里是client节点,是没有初始化RegionEngine的,所以这里就会返回null,接着返回到上一级中调用父类的getLeader方法。
DefaultRheaKVRpcService#getLeader
public Endpoint getLeader(final long regionId, final boolean forceRefresh, final long timeoutMillis) { return this.pdClient.getLeader(regionId, forceRefresh, timeoutMillis); }这里会调用pdClient的getLeader方法,这里我们传入的pdClient是FakePlacementDriverClient,它继承了AbstractPlacementDriverClient,所以会调用到父类的getLeader方法中。
AbstractPlacementDriverClient#getLeader
public Endpoint getLeader(final long regionId, final boolean forceRefresh, final long timeoutMillis) { //这里会根据clusterName和regionId拼接出raftGroupId final String raftGroupId = JRaftHelper.getJRaftGroupId(this.clusterName, regionId); //去路由表里找这个集群的leader PeerId leader = getLeader(raftGroupId, forceRefresh, timeoutMillis); if (leader == null && !forceRefresh) { // Could not found leader from cache, try again and force refresh cache // 如果第一次没有找到,那么执行强制刷新的方法再找一次 leader = getLeader(raftGroupId, true, timeoutMillis); } if (leader == null) { throw new RouteTableException("no leader in group: " + raftGroupId); } return leader.getEndpoint(); }这个方法里面会根据clusterName和regionId拼接raftGroupId,如果传入的clusterName为demo,regionId为1,那么拼接出来的raftGroupId就是:demo--1。
然后会去调用getLeader获取leader的PeerId,第一次调用这个方法传入的forceRefresh为false,表示不用刷新,如果返回的为null,那么会执行强制刷新再去找一次。
AbstractPlacementDriverClient#getLeader
protected PeerId getLeader(final String raftGroupId, final boolean forceRefresh, final long timeoutMillis) { final RouteTable routeTable = RouteTable.getInstance(); //是否要强制刷新路由表 if (forceRefresh) { final long deadline = System.currentTimeMillis() + timeoutMillis; final StringBuilder error = new StringBuilder(); // A newly launched raft group may not have been successful in the election, // or in the 'leader-transfer' state, it needs to be re-tried Throwable lastCause = null; for (;;) { try { //刷新节点路由表 final Status st = routeTable.refreshLeader(this.cliClientService, raftGroupId, 2000); if (st.isOk()) { break; } error.append(st.toString()); } catch (final InterruptedException e) { ThrowUtil.throwException(e); } catch (final Throwable t) { lastCause = t; error.append(t.getMessage()); } //如果还没有到截止时间,那么sleep10毫秒之后再刷新 if (System.currentTimeMillis() < deadline) { LOG.debug("Fail to find leader, retry again, {}.", error); error.append(", "); try { Thread.sleep(10); } catch (final InterruptedException e) { ThrowUtil.throwException(e); } // 到了截止时间,那么抛出异常 } else { throw lastCause != null ? new RouteTableException(error.toString(), lastCause) : new RouteTableException(error.toString()); } } } //返回路由表里面的leader return routeTable.selectLeader(raftGroupId); }如果要执行强制刷新,那么会计算一下超时时间,然后调用死循环,在循环体里面会去刷新路由表,如果没有刷新成功也没有超时,那么会sleep10毫秒重新再刷。
RouteTable#refreshLeader
public Status refreshLeader(final CliClientService cliClientService, final String groupId, final int timeoutMs) throws InterruptedException, TimeoutException { Requires.requireTrue(!StringUtils.isBlank(groupId), "Blank group id"); Requires.requireTrue(timeoutMs > 0, "Invalid timeout: " + timeoutMs); //根据集群的id去获取集群的配置信息,里面包括集群的ip和端口号 final Configuration conf = getConfiguration(groupId); if (conf == null) { return new Status(RaftError.ENOENT, "Group %s is not registered in RouteTable, forgot to call updateConfiguration?", groupId); } final Status st = Status.OK(); final CliRequests.GetLeaderRequest.Builder rb = CliRequests.GetLeaderRequest.newBuilder(); rb.setGroupId(groupId); //发送获取leader节点的请求 final CliRequests.GetLeaderRequest request = rb.build(); TimeoutException timeoutException = null; for (final PeerId peer : conf) { //如果连接不上,先设置状态为error,然后continue if (!cliClientService.connect(peer.getEndpoint())) { if (st.isOk()) { st.setError(-1, "Fail to init channel to %s", peer); } else { final String savedMsg = st.getErrorMsg(); st.setError(-1, "%s, Fail to init channel to %s", savedMsg, peer); } continue; } //向这个节点发送获取leader的GetLeaderRequest请求 final Future<Message> result = cliClientService.getLeader(peer.getEndpoint(), request, null); try { final Message msg = result.get(timeoutMs, TimeUnit.MILLISECONDS); //异常情况的处理 if (msg instanceof RpcRequests.ErrorResponse) { if (st.isOk()) { st.setError(-1, ((RpcRequests.ErrorResponse) msg).getErrorMsg()); } else { final String savedMsg = st.getErrorMsg(); st.setError(-1, "%s, %s", savedMsg, ((RpcRequests.ErrorResponse) msg).getErrorMsg()); } } else { final CliRequests.GetLeaderResponse response = (CliRequests.GetLeaderResponse) msg; //重置leader updateLeader(groupId, response.getLeaderId()); return Status.OK(); } } catch (final TimeoutException e) { timeoutException = e; } catch (final ExecutionException e) { if (st.isOk()) { st.setError(-1, e.getMessage()); } else { final String savedMsg = st.getErrorMsg(); st.setError(-1, "%s, %s", savedMsg, e.getMessage()); } } } if (timeoutException != null) { throw timeoutException; } return st; }大家不要一开始就被这样的长的方法给迷惑住了,这个方法实际上非常的简单:
- 根据groupId获取集群节点的配置信息,其中包括了其他节点的ip和端口号
- 遍历conf里面的集群节点
- 尝试连接被遍历的节点,如果连接不上直接continue换到下一个节点
- 向这个节点发送GetLeaderRequest请求,如果在超时时间内可以返回正常的响应,那么就调用updateLeader更新leader信息
updateLeader方法相当节点,里面就是更新一下路由表的leader属性,我们这里看看server是怎么处理GetLeaderRequest请求的
GetLeaderRequest由GetLeaderRequestProcessor处理器来进行处理。
GetLeaderRequestProcessor#processRequest
public Message processRequest(GetLeaderRequest request, RpcRequestClosure done) { List<Node> nodes = new ArrayList<>(); String groupId = getGroupId(request); //如果请求是指定某个PeerId //那么则则去集群里找到指定Peer所对应的node if (request.hasPeerId()) { String peerIdStr = getPeerId(request); PeerId peer = new PeerId(); if (peer.parse(peerIdStr)) { Status st = new Status(); nodes.add(getNode(groupId, peer, st)); if (!st.isOk()) { return RpcResponseFactory.newResponse(st); } } else { return RpcResponseFactory.newResponse(RaftError.EINVAL, "Fail to parse peer id %", peerIdStr); } } else { //获取集群所有的节点 nodes = NodeManager.getInstance().getNodesByGroupId(groupId); } if (nodes == null || nodes.isEmpty()) { return RpcResponseFactory.newResponse(RaftError.ENOENT, "No nodes in group %s", groupId); } //遍历集群node,获取leaderId for (Node node : nodes) { PeerId leader = node.getLeaderId(); if (leader != null && !leader.isEmpty()) { return GetLeaderResponse.newBuilder().setLeaderId(leader.toString()).build(); } } return RpcResponseFactory.newResponse(RaftError.EAGAIN, "Unknown leader"); }这里由于我们穿过来的request并没有携带PeerId,所以不会去获取指定的peer对应node节点的leaderId,而是会去找到集群groupId对应的所有节点,然后遍历节点找到对应的leaderId。
getLuckyPeer轮询获取一个节点
在上面我们讲完了getLeader是怎么实现的,下面我们讲一下getLuckyPeer这个方法里面是怎么操作的。
public Endpoint getLuckyPeer(final long regionId, final boolean forceRefresh, final long timeoutMillis) { return this.pdClient.getLuckyPeer(regionId, forceRefresh, timeoutMillis, this.selfEndpoint); }这里和getLeader方法一样会调用到AbstractPlacementDriverClient的getLuckyPeer方法中
AbstractPlacementDriverClient#getLuckyPeer
public Endpoint getLuckyPeer(final long regionId, final boolean forceRefresh, final long timeoutMillis, final Endpoint unExpect) { final String raftGroupId = JRaftHelper.getJRaftGroupId(this.clusterName, regionId); final RouteTable routeTable = RouteTable.getInstance(); //是否要强制刷新一下最新的集群节点信息 if (forceRefresh) { final long deadline = System.currentTimeMillis() + timeoutMillis; final StringBuilder error = new StringBuilder(); // A newly launched raft group may not have been successful in the election, // or in the 'leader-transfer' state, it needs to be re-tried for (;;) { try { final Status st = routeTable.refreshConfiguration(this.cliClientService, raftGroupId, 5000); if (st.isOk()) { break; } error.append(st.toString()); } catch (final InterruptedException e) { ThrowUtil.throwException(e); } catch (final TimeoutException e) { error.append(e.getMessage()); } if (System.currentTimeMillis() < deadline) { LOG.debug("Fail to get peers, retry again, {}.", error); error.append(", "); try { Thread.sleep(5); } catch (final InterruptedException e) { ThrowUtil.throwException(e); } } else { throw new RouteTableException(error.toString()); } } } final Configuration configs = routeTable.getConfiguration(raftGroupId); if (configs == null) { throw new RouteTableException("empty configs in group: " + raftGroupId); } final List<PeerId> peerList = configs.getPeers(); if (peerList == null || peerList.isEmpty()) { throw new RouteTableException("empty peers in group: " + raftGroupId); } //如果这个集群里只有一个节点了,那么直接返回就好了 final int size = peerList.size(); if (size == 1) { return peerList.get(0).getEndpoint(); } //获取负载均衡器,这里用的是轮询策略 final RoundRobinLoadBalancer balancer = RoundRobinLoadBalancer.getInstance(regionId); for (int i = 0; i < size; i++) { final PeerId candidate = balancer.select(peerList); final Endpoint luckyOne = candidate.getEndpoint(); if (!luckyOne.equals(unExpect)) { return luckyOne; } } throw new RouteTableException("have no choice in group(peers): " + raftGroupId); }这个方法里面也有一个是否要强制刷新的判断,和getLeader方法一样,不再赘述。然后会判断一下集群里面如果不止一个有效节点,那么会调用轮询策略来选取节点,这个轮询的操作十分简单,就是一个全局的index每次调用加一,然后和传入的peerList集合的size取模。
到这里DefaultRheaKVRpcService的callAsyncWithRpc方法就差不多讲解完毕了,然后会向server端发起请求,在KVCommandProcessor处理BatchPutRequest请求。
Server端处理BatchPutRequest请求
BatchPutRequest的请求在KVCommandProcessor中被处理。
KVCommandProcessor#handleRequest
public void handleRequest(final BizContext bizCtx, final AsyncContext asyncCtx, final T request) { Requires.requireNonNull(request, "request"); final RequestProcessClosure<BaseRequest, BaseResponse<?>> closure = new RequestProcessClosure<>(request, bizCtx, asyncCtx); //根据传入的RegionId去找到对应的RegionKVService //每个 RegionKVService 对应一个 Region,只处理本身 Region 范畴内的请求 final RegionKVService regionKVService = this.storeEngine.getRegionKVService(request.getRegionId()); if (regionKVService == null) { //如果不存在则返回空 final NoRegionFoundResponse noRegion = new NoRegionFoundResponse(); noRegion.setRegionId(request.getRegionId()); noRegion.setError(Errors.NO_REGION_FOUND); noRegion.setValue(false); closure.sendResponse(noRegion); return; } switch (request.magic()) { case BaseRequest.PUT: regionKVService.handlePutRequest((PutRequest) request, closure); break; case BaseRequest.BATCH_PUT: regionKVService.handleBatchPutRequest((BatchPutRequest) request, closure); break; ..... default: throw new RheaRuntimeException("Unsupported request type: " + request.getClass().getName()); } }handleRequest首先会根据RegionId去找RegionKVService,RegionKVService在初始化RegionEngine的时候会注册到regionKVServiceTable中。
然后根据请求的类型判断request是什么请求。这里我们省略其他请求,只看BATCH_PUT是怎么做的。
在往下讲代码之前,我先来给个流程调用指指路:
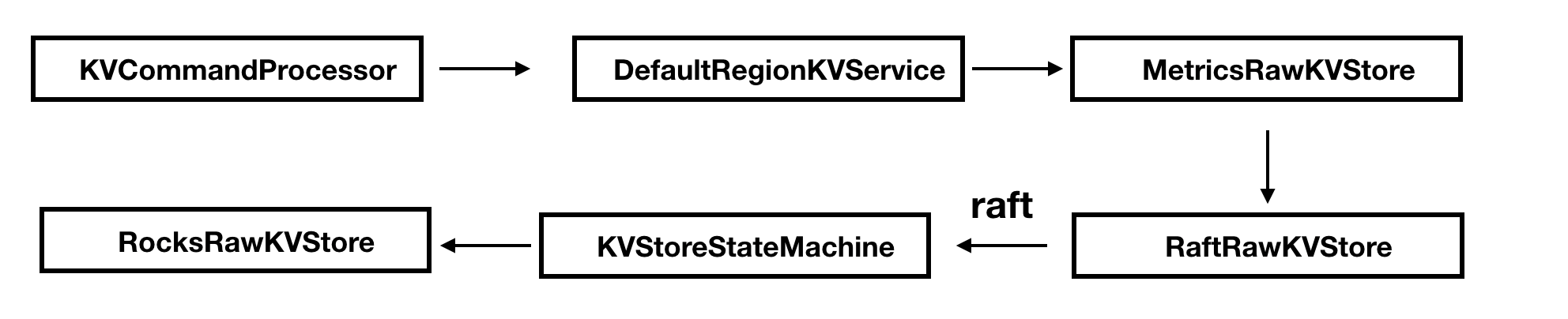
BATCH_PUT对应会调用到DefaultRegionKVService的handleBatchPutRequest方法中 。
DefaultRegionKVService#handleBatchPutRequest
public void handlePutRequest(final PutRequest request, final RequestProcessClosure<BaseRequest, BaseResponse<?>> closure) { //设置一个响应response final PutResponse response = new PutResponse(); response.setRegionId(getRegionId()); response.setRegionEpoch(getRegionEpoch()); try { KVParameterRequires.requireSameEpoch(request, getRegionEpoch()); final byte[] key = KVParameterRequires.requireNonNull(request.getKey(), "put.key"); final byte[] value = KVParameterRequires.requireNonNull(request.getValue(), "put.value"); //这个实例是MetricsRawKVStore this.rawKVStore.put(key, value, new BaseKVStoreClosure() { //设置回调函数 @Override public void run(final Status status) { if (status.isOk()) { response.setValue((Boolean) getData()); } else { setFailure(request, response, status, getError()); } closure.sendResponse(response); } }); } catch (final Throwable t) { LOG.error("Failed to handle: {}, {}.", request, StackTraceUtil.stackTrace(t)); response.setError(Errors.forException(t)); closure.sendResponse(response); } }handlePutRequest方法十分地简单,通过获取key和value之后调用MetricsRawKVStore的put方法,传入key和value并设置回调函数。
MetricsRawKVStore#put
public void put(final byte[] key, final byte[] value, final KVStoreClosure closure) { final KVStoreClosure c = metricsAdapter(closure, PUT, 1, value.length); //rawKVStore是RaftRawKVStore的实例 this.rawKVStore.put(key, value, c); }put方法会继续调用RaftRawKVStore的put方法。
RaftRawKVStore#put
public void put(final byte[] key, final byte[] value, final KVStoreClosure closure) { applyOperation(KVOperation.createPut(key, value), closure); }Put方法会调用KVOperation的静态方法创建一个类型为put的KVOperation实例,然后调用applyOperation方法。
RaftRawKVStore#applyOperation
private void applyOperation(final KVOperation op, final KVStoreClosure closure) { //这里必须保证 Leader 节点操作申请任务 if (!isLeader()) { closure.setError(Errors.NOT_LEADER); closure.run(new Status(RaftError.EPERM, "Not leader")); return; } final Task task = new Task(); //封装数据 task.setData(ByteBuffer.wrap(Serializers.getDefault().writeObject(op))); //封装回调方法 task.setDone(new KVClosureAdapter(closure, op)); //调用NodeImpl的apply方法 this.node.apply(task); }applyOperation方法里面会校验是不是leader,如果不是leader那么就不能执行任务申请的操作。然后实例化一个Task实例,设置数据和回调Adapter后调用NodeImple的apply发布任务。
NodeImpl#apply
public void apply(final Task task) { //检查Node是不是被关闭了 if (this.shutdownLatch != null) { Utils.runClosureInThread(task.getDone(), new Status(RaftError.ENODESHUTDOWN, "Node is shutting down.")); throw new IllegalStateException("Node is shutting down"); } //校验不能为空 Requires.requireNonNull(task, "Null task"); //将task里面的数据放入到LogEntry中 final LogEntry entry = new LogEntry(); entry.setData(task.getData()); //重试次数 int retryTimes = 0; try { //实例化一个Disruptor事件 final EventTranslator<LogEntryAndClosure> translator = (event, sequence) -> { event.reset(); event.done = task.getDone(); event.entry = entry; event.expectedTerm = task.getExpectedTerm(); }; while (true) { //发布事件后交给LogEntryAndClosureHandler事件处理器处理 if (this.applyQueue.tryPublishEvent(translator)) { break; } else { retryTimes++; //最多重试3次 if (retryTimes > MAX_APPLY_RETRY_TIMES) { //不成功则进行回调,通知处理状态 Utils.runClosureInThread(task.getDone(), new Status(RaftError.EBUSY, "Node is busy, has too many tasks.")); LOG.warn("Node {} applyQueue is overload.", getNodeId()); this.metrics.recordTimes("apply-task-overload-times", 1); return; } ThreadHelper.onSpinWait(); } } } catch (final Exception e) { Utils.runClosureInThread(task.getDone(), new Status(RaftError.EPERM, "Node is down.")); } }在apply方法里面会将数据封装到LogEntry实例中,然后将LogEntry打包成一个Disruptor事件发布到applyQueue队列里面去。applyQueue队列在NodeImpl的init方法里面初始化,并设置处理器为LogEntryAndClosureHandler。
LogEntryAndClosureHandler#onEvent
private final List<LogEntryAndClosure> tasks = new ArrayList<>(NodeImpl.this.raftOptions.getApplyBatch()); @Override public void onEvent(final LogEntryAndClosure event, final long sequence, final boolean endOfBatch) throws Exception { //如果接收到了要关闭的请求 if (event.shutdownLatch != null) { //tasks队列里面的任务又不为空,那么先处理队列里面的数据 if (!this.tasks.isEmpty()) { //处理tasks executeApplyingTasks(this.tasks); } final int num = GLOBAL_NUM_NODES.decrementAndGet(); LOG.info("The number of active nodes decrement to {}.", num); event.shutdownLatch.countDown(); return; } //将新的event加入到tasks中 this.tasks.add(event); //因为设置了32为一个批次,所以如果tasks里面的任务达到了32或者已经是最后一个event, // 那么就执行tasks集合里面的数据 if (this.tasks.size() >= NodeImpl.this.raftOptions.getApplyBatch() || endOfBatch) { executeApplyingTasks(this.tasks); this.tasks.clear(); } }onEvent方法会校验收到的事件是否是请求关闭队列,如果是的话,那么会先把tasks集合里面的数据执行完毕再返回。如果是正常的事件,那么校验一下tasks集合里面的个数是不是已经到达了32个,或者是不是已经是最后一个事件了,那么会执行executeApplyingTasks进行批量处理数据。
NodeImpl#executeApplyingTasks
private void executeApplyingTasks(final List<LogEntryAndClosure> tasks) { this.writeLock.lock(); try { final int size = tasks.size(); //如果当前节点不是leader,那么就不往下进行 if (this.state != State.STATE_LEADER) { final Status st = new Status(); if (this.state != State.STATE_TRANSFERRING) { st.setError(RaftError.EPERM, "Is not leader."); } else { st.setError(RaftError.EBUSY, "Is transferring leadership."); } LOG.debug("Node {} can't apply, status={}.", getNodeId(), st); //处理所有的LogEntryAndClosure,发送回调响应 for (int i = 0; i < size; i++) { Utils.runClosureInThread(tasks.get(i).done, st); } return; } final List<LogEntry> entries = new ArrayList<>(size); for (int i = 0; i < size; i++) { final LogEntryAndClosure task = tasks.get(i); //如果任其不对,那么直接调用回调函数发送Error if (task.expectedTerm != -1 && task.expectedTerm != this.currTerm) { LOG.debug("Node {} can't apply task whose expectedTerm={} doesn't match currTerm={}.", getNodeId(), task.expectedTerm, this.currTerm); if (task.done != null) { final Status st = new Status(RaftError.EPERM, "expected_term=%d doesn't match current_term=%d", task.expectedTerm, this.currTerm); Utils.runClosureInThread(task.done, st); } continue; } //保存应用上下文 if (!this.ballotBox.appendPendingTask(this.conf.getConf(), this.conf.isStable() ? null : this.conf.getOldConf(), task.done)) { Utils.runClosureInThread(task.done, new Status(RaftError.EINTERNAL, "Fail to append task.")); continue; } // set task entry info before adding to list. task.entry.getId().setTerm(this.currTerm); //设置entry的类型为ENTRY_TYPE_DATA task.entry.setType(EnumOutter.EntryType.ENTRY_TYPE_DATA); entries.add(task.entry); } //批量提交申请任务日志写入 RocksDB this.logManager.appendEntries(entries, new LeaderStableClosure(entries)); // update conf.first this.conf = this.logManager.checkAndSetConfiguration(this.conf); } finally { this.writeLock.unlock(); } }executeApplyingTasks中会校验当前的节点是不是leader,因为Raft 副本节点 Node 执行申请任务检查当前状态是否为 STATE_LEADER,必须保证 Leader 节点操作申请任务。
循环遍历节点服务事件判断任务的预估任期是否等于当前节点任期,Leader 没有发生变更的阶段内提交的日志拥有相同的 Term 编号,节点 Node 任期满足预期则 Raft 协议投票箱 BallotBox 调用 appendPendingTask(conf, oldConf, done) 日志复制之前保存应用上下文,即基于当前节点配置以及原始配置创建选票 Ballot 添加到选票双向队列 pendingMetaQueue。
然后日志管理器 LogManager 调用底层日志存储 LogStorage#appendEntries(entries) 批量提交申请任务日志写入 RocksDB。
接下来通过 Node#apply(task) 提交的申请任务最终将会复制应用到所有 Raft 节点上的状态机,RheaKV 状态机通过继承 StateMachineAdapter 状态机适配器的 KVStoreStateMachine 表示。
Raft 状态机 KVStoreStateMachine 调用 onApply(iterator) 方法按照提交顺序应用任务列表到状态机。
KVStoreStateMachine 状态机迭代状态输出列表积攒键值状态列表批量申请 RocksRawKVStore 调用 batch(kvStates) 方法运行相应键值操作存储到 RocksDB。
总结
这一篇是相当的长流程也是非常的复杂,里面的各个地方代码写的都非常的缜密。我们主要介绍了putBatching皮处理器是怎么使用Disruptor批量的处理数据,从而做到提升整体的吞吐量。还讲解了在发起请求的时候是如何获取server端的endpoint的。然后还了解了BatchPutRequest请求是怎么被server处理的,以及在代码中怎么体现通过Batch + 全异步机制大幅度提升吞吐的。

