第35次文章:数据库简单查询
- 2019 年 10 月 8 日
- 笔记
本周学习的数据库,有一种明显的感觉,语法简单,基本上不会有大段大段的代码出现,简简单单的几行代码就可以完成我们需要实现的任务,或许是因为我们的任务比较初级吧!嘻嘻!
所以本周主要分享的是一些语法结构,如果每个语法都给出一个例子的话,这篇文章将会出奇的长。所以,小白对于比较生疏的一些语法,会给出一个具体案例进行讲解,剩余比较简单的案例,各位小伙伴就自己摸索一下,很简单的哟!
遇到什么问题,想要和小白讨论的话,可以在文章下面留言,或者直接添加微信号:javaxiaobaizhushou,与小白面对面交流呀!下面进入正式的分享啦!
紧接上周的内容,补充一下常见的几款数据库管理系统:
mysql、oracle(甲骨文),db2(IBM)、sqlserver(微软)
sql 语言分类
DQL语言的学习:数据查询语言(date query language)
DML语言的学习:数据操作语言(data manipulation )
DDL语言:数据定义语言data define language
TCL语言:事务控制语言transaction control language
在下面使用到的案例中,我们都用下面的一张emp表进行查询,所以我就先把这张表截图放在这里,便于后续的查看

tips:这张表格仅仅是用作我们在后续的操作,并没有任何实际意义哈,不用纠结里面的每个值是不是符合现实逻辑。
进阶1:基础查询
一、语法
select 查询列表 from 表名;
二、特点
1、查询列表可以是字段、常量、表达式、函数,也可以是多个
2、查询结果是一个虚拟表
三、示例
1、查询单个字段
select 字段名 from 表名;
2、查询多个字段
select 字段名,字段名 from 表名;
3、查询所有的字段
select * from 表名;
4、查询常量值
select 常量值;
注意:字符型和日期型的常量值必须用单引号引起来,数值型不需要
5、查询函数
select 函数名(实参列表);
6、查询表达式
select 100/1234;
注意:可以使用正常的加减乘除,但是不能使用java中++ —
7、起别名
(1)as
(2)空格
8、去重
select distinct 字段名 from 表名;
注意:去重的时候,只能对一个字段名进行去重处理。
9、+
作用:做加法运算
select 数值+数值;直接运算
select 字符+数值;先试图将字符转换成数值,如果转换成功,则继续运算;否则将字符转换为0,再做运算。
select null+值;结果都为null
在这里我们给出一个字符串连接的案例,便于各位同学的理解吧~
/* java中的+号: (1)运算符,两个操作数都为数值型 (2)连接符,只要有一个操作数为字符型 mysql中的+号: 仅仅只有一个功能:运算符 select 100+90;两个操作数都为数值型,则做加法运算 SELECT '123'+90; 只要其中一方为字符型,试图将字符型数值转换为数值型 如果转化成功,则继续做加法运算 SELECT 'ans'+90; 如果转换失败,则将字符型数值转换为0 SELECT null+10; 只要其中一方为null,则其结果肯定为null */ #案例,查询员工名和姓连接成一个字段,并显示为 姓名,实现字符串的连接使用concat函数 SELECT CONCAT(empname, last_name) 全名 FROM emp;
结果图:

tips:mysql中的‘+’号不具备拼接字符串的特性,需要单独利用拼接字符串的函数concat(),来完成拼接功能。
10、【补充】concat函数
功能:拼接字符串
select concat(字符1,字符2,字符3,…..)
11、【补充】ifnull函数
功能:判断某字段或表达式是否为null,如果为null 返回指定的值,否则返回原本的值
select ifnull(bonus,0) from emp;
12、【补充】isnull
功能:判断某字段或表达式的值是否为null,如果是,则返回为1,如果不是,则返回为0
进阶2:条件查询
一、语法
select 查询列表 from 表名 where 筛选条件;
二、筛选条件的分类
1、简单条件运算符
> < = <>不等于 >= <= <=>安全等于
2、逻辑运算符
&& and
|| or
! not
3、模糊查询
我们着重对于模糊查询进行详细介绍,下面给出相应的案例:
(1)like:一般搭配通配符使用,可以判断字符型和数值型
通配符:%任意多个字符,_任意单个字符
/* LIKE 特点: 1.一般和通配符搭配使用 通配符: % 任意多个字符,包含0个字符 _ 任意单个字符 */ #案例1:查询员工名中带有字母a的员工 SELECT * FROM emp WHERE empname like '%a%'; #案例2:查询员工名中第三个字符为i,第五个字符为e的员工名和工资 SELECT empname,salary from emp WHERE empname LIKE '__i_e%'; #案例3:查询员工名中第二个字符为_的员工名,包含有特殊字符 SELECT empname FROM emp WHERE empname LIKE '_$_' ESCAPE '$';#可以使用任意字符与使用escape关键字一起使用,将此字符改变为转义字符;或者使用斜杠转义:empname LIKE '__'
查看一下结果图:
案例1结果:

案例2结果:

案例3结果:
tips:这里主要说明一下案例3结果,由于我们的数据集中,并没有员工名中包含有‘_’的员工。所以最后查询的结果为空,而案例3的意义在于说明对于转义字符的使用问题。我们除了使用斜杠之外,增加了一种使用escape关键字的方法。最后的结果中,并没有报语法错误,所以证明这个关键字是可以使用的。
(2)between and
#2.between and /* 1.使用between and 可以提高语句的简洁度 2.包含临界值 3.两个临界值不要调换顺序 */ #案例1.查询员工薪资在2000到5000之间的员工信息 select * FROM emp where salary>=2000 AND salary<=5000; #------------------- select * FROM emp WHERE salary between 2000 and 5000;
两个查询的结果集相同,如下所示:

tips:使用between and进行模糊查询的时候,我们需要注意两个数值之间的顺序,而且between and模糊查询最后代表的是一个范围内的结果。
(3)in
/* 含义:判断某字段的值是否属于in列表中的某一项 特点: (1)使用in提高语句的简洁度 (2)in列表的值类型必须一致或兼容 '123' 123 (3)列表中不支持通配符的使用 */ #查询:查询员工的姓名为tom1、tom、ceimeng的员工的名字和部门编号 SELECT empname,deptId FROM emp where empname = 'tom1' OR empname = 'tom' OR empname = 'ceimeng'; #------------------------------------------ SELECT empname,deptId FROM emp where empname IN('tom1','tom','ceimeng');
两个查询的结果集也相同:
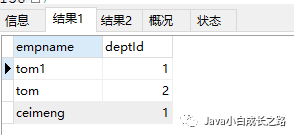
tips :关键字in的模糊查询更加类似于一种列表清单,在此列表清单内的数据都会被列举出来。
(4)is null 和 is not null:用于判断null值
/* =或<>不能用于判断null值 is null 或者 is not null 可以判断null值 #is null pk <=> is null :仅仅可以判断null值,可读性较高,建议使用 <=> :既可以判断null值,又可以判断普通的数值,可读性较低 */ #案列1:查询没有奖金的员工名和奖金 SELECT empname,bonus FROM emp WHERE bonus is NULL; #---------------- #安全等于 <=> SELECT empname,bonus FROM emp WHERE bonus <=> NULL;
查看一下结果集:

tips:案例中也给出了两种判断null方法,供各位同学选择~
进阶3:排序查询
基本的语法与上面的两种相同,主要是使用order by关键字
#进阶3:排序查询 /* 引入: select * FROM emp; 语法: select 查询列表 FROM 表 【where 筛选条件】 ORDER BY 排序列表 【asc|DESC】 特点: 1、asc代表的是升序,desc代表的是降序 如果不写,默认的是升序 2、order by字句中可以支持单个字段、多个字段、表达式、函数、别名 3、order by字句一般是放在查询语句的最后面,limit字句除外 */ #案列1:查询薪资>=2000的员工信息,按生日进行排序【添加筛选调价】 SELECT * from emp where salary >= 2000 ORDER BY birthday DESC; #案列2:按年薪的高低显示员工的信息和 年薪【按表达式排序】 SELECT *,salary+IFNULL(bonus,0) '年薪' FROM emp ORDER BY salary+IFNULL(bonus,0) DESC; #案例3:查询员工信息,要求先按照薪资升序,再按照员工编号降序【按多个字段进行排列】 SELECT * FROM emp ORDER BY salary ASC,id DESC;
在上面给出了3个案例,最后的结果如下所示:
案例1:

案例2:

案例3:

tips:上面的三个案例基本涵盖了我们经常使用到的几种排序情况,通过总结,我们可以发现,order by子句的使用方法与select子句的使用方法基本一致,主要差别在于使用的位置在整个语句的后面。
进阶4:常见函数
一、基本概念
类似于java的方法,将一组逻辑语句封装在方法体中,对外暴露方法名。
好处:
1、隐藏了实现细节
2、提高代码的重用型调用:select 函数名(实参列表)【from 表】;
特点:
1、叫什么(函数名)
2、干什么(函数功能)
分类:
1、单行函数 如 CONCAT、length、ifnull
2、分组函数 功能:做统计使用、聚合函数、组函数
二、单行函数
(1)字符函数
length:计算字符串长度
concat:拼接字符串
substr:截取从指定索引后面所有字符,或者,截取从指定索引处,指定字符长度的字符。注意:索引是从1开始的。
instr:返回子串第一次出现的索引,如果找不到返回0。
trim:去除子串前后的空格
upper、lower:将所有的字符串全部转换为大写或者小写
lpad、rpad:用指定的字符实现左(或右)填充指定长度
replace :替换指定的字符串
(2)数学函数
round:四舍五入,可以指定保留小数点后面多少位
ceil:向上取整,返回>=改参数的最小整数
floor:向下取整,返回<=该参数的最大整数
truncate:从小数点后面第几位开始截断
mod:取余函数
对于取余函数我们需要注意一下其内部的计算法则,以避免在负数取余的时候犯错。
/* 取余函数的底层运算 mod(a,b) : a-a/b*b MOD(-10,-3) :-10-(-10)/(-3)*(-3)=-10-3*(-3)=-1 */ select MOD(-10,-3); SELECT -10%(-3);
tips:正因为上述的取余运算的底层法则,使得负数取余的时候,余数依旧为负数。
(3)日期函数
NOW:显示当前年月日时分秒
curdate:仅仅显示当前的日期
curtime:仅仅显示当前的时间
year、month、day、hour、minute、second:分别显示相应的时间单位
str_to_date:将时间字符串通过指定的格式转换为日期
date_format:将时间按照指定的格式转化为字符串
(4)控制函数
if函数
#1.if函数:if else 的效果 SELECT empname,bonus, IF(bonus is NULL,'没奖金,呵呵','有奖金,嘻嘻') 备注 FROM emp;
我们查看一下结果集:

tips:通过上面的结果集,我们可以明显的看出,if函数类似于java中的三位运算符,当判断条件为真时,输出第一个结果,条件为假时,输出第二个结果。
case函数
#2.case函数的使用一:switch case 的效果 /* java 中 switch(变量或表达式){ case 常量1:语句1;break; ..... DEFAULT:语句n;break; } mysql 中 case 要判断的字段或表达式 when 常量1 then 要显示的值1或语句1; when 常量2 then 要显示的值2或语句2; ... ELSE 要显示的值n或语句n; END */ /*案例:查询员工的工资,要求 部门号=1,显示的工资为1.1倍 部门号=2,显示的工资为1.2倍 部门号=3,显示的工资为1.3倍 部门号=4,显示的工资为1.4倍 */ SELECT empname,salary 原始工资,deptId, CASE deptId WHEN 1 THEN salary*1.1 WHEN 2 THEN salary*1.2 WHEN 3 THEN salary*1.3 ELSE salary*1.4 END 新工资 FROM emp; #3.CASE 函数的使用二:类似于 多重if /* java中: if(条件1){ 语句1; }else if(条件2){ 语句2; } ... ELSE{ 语句n; } mysql 中: CASE WHEN 条件1 THEN 要显示的值1或语句1; WHEN 条件2 THEN 要显示的值2或语句2; ..... ELSE 要显示的值n或语句n; end */ #案例:查询员工的工资情况 /* 如果工资>10000,显示的A级别 如果工资>5000,显示的B级别 如果工资>1000,显示的C级别 否则,显示的D级别 */ SELECT empname,salary, CASE WHEN salary>10000 THEN 'A' WHEN salary>5000 THEN 'B' WHEN salary>1000 THEN 'C' ELSE 'D' END 工资等级 FROM emp;
用法一的结果:

用法二的结果:

tips:对于两种case的用法,全部都已经展示在了代码行中,各位同学自己查看即可哈!
三、分组函数
(1)基本功能
功能:用作统计使用,又称为聚合函数或统计函数或组函数。
(2)分类
sum 求和、avg 平均值、max 最大值、min 最小值、count 计算个数
下面对这几个函数进行简单的介绍
/* 特点: 1、sum avg 一般用于处理数值型 max min count 可以处理任何类型 2、以上分组函数都忽略null值 3、可以和关键字distinct搭配使用,实现去重的运算 4、count函数的单独介绍 一般使用count(*)用作统计行数 5、和分组函数一同查询的字段要求是group by 后的字段 */ #1、和distinct搭配 SELECT COUNT(DISTINCT deptId) from emp; #2、count函数的详细介绍 SELECT COUNT(*) from emp;#统计整张表中的所有行数,也可以通过在添加常量的方法来统计:SELECT COUNT(1) from emp; #效率: #MYISAM 存储引擎下 , count(*)的效率高 #INNODB 存储引擎下 , count(*)和COUNT(1)的效率差不多,比count(字段)要高一些
案例1结果图:

案例2结果图:

tips:通过案例1,我们主要说明一下去重关键字与统计函数的搭配使用。在对deptId进行计数的时候,可以计算有多少个部门id。
进阶5:分组查询
一、基本思想
在前面的进阶过程中,我们一直是针对整张表格的数据进行。分组查询主要是根据用户的需求,对自己设定的类别进行单独的统计计算。在分组查询中主要使用group by关键字。
二、语法
SELECT 分组函数,列(要求出现在group by的后面)
FROM 表 【where 筛选条件】
GROUP BY 分组的列表
【order by 子句】
注意点:查询列表必须特殊,要求是分组函数和group by 后出现的字段
三、特点
#进阶5:分组查询 /* 特点: 1、分组查询中的筛选条件分为两类 数据源 位置 关键字 分组前筛选 原始表 GROUP BY子句的前面 WHERE 分组后筛选 分组后的结果集 GROUP BY子句的后面 HAVING (1)分组函数做条件肯定是放在having子句中 (2)能用分组前筛选的,就优先考虑使用分组前筛选 2、group by子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开,没有顺序要求),表达式(使用的较少) 3、也可以添加排序(排序放在整个分组查询的最后) */ #案例1:查询每个部门的平均工资 SELECT round(avg(salary),2),deptId FROM emp GROUP BY deptId; #添加分组后复杂的筛选条件 #案例2:查询部门编号>1的每个部门中,最低工资大于1000的部门编号是哪个,以及其部门的最低工资 SELECT deptId,MIN(salary) 部门最低工资 FROM emp WHERE deptId>1 GROUP BY deptId HAVING 部门最低工资>5000;
案例1结果:

案例2结果:

tips:
案例2中,首先要求部门编号大于1,这个筛选条件我们可以直接在原始表中进行,所以使用的是where关键字,得到了第一步筛选之后的表格——部门编号大于1的各个部门的最低工资。
但是根据案例中的要求,每个部门的最低工资需要大于1000,这个筛选是基于我们第一次筛选之后表格进行的,所以此时我们不能够继续使用where关键字,需要使用having关键字,表示我们对第一次筛选得到的表格进行第二次筛选。同时根据我们的代码也可以发现,在使用having关键字的时候,我们还可以使用别名进行二次筛选。
Related Posts
- 2022 年 11 月 16 日
数据驱动!精细化运营!用机器学习做客户生命周期与价值预估!
 作者:韩信子@ShowMeAI
作者:韩信子@ShowMeAI  机器学习实战系列://www.showmeai.tech/tutorials/ ..
机器学习实战系列://www.showmeai.tech/tutorials/ ..
