【真相揭秘】requests获取网页编码乱码本质
- 2020 年 5 月 28 日
- 笔记
有没有被网页编码抓狂,怎么转都是乱码。
通过查看requests源代码,才发现是库本身历史原因造成的。
作者是严格http协议标准写这个库的,《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是’ISO-8859-1’编码。
这处理英文页面当然没有问题,但是中文页面,特别是那些不规范的页面,就会有乱码了!
比如分析jd.com 页面为gbk编码,问题就出在这里。
chardet库监测编码却是GB2312,两种编码虽然兼容的,但用GB2312解码gbk编码的网页字节串会运行错误!
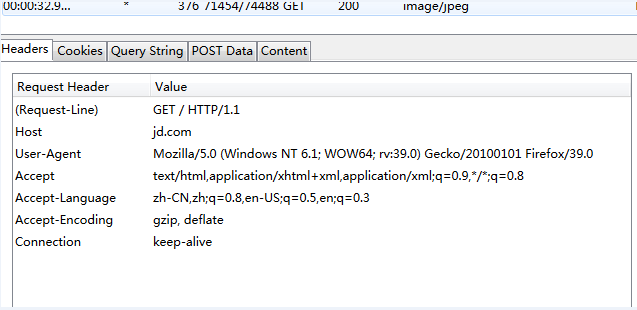

reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中)。所有该函数就直接返回’ISO-8859-1’。
# test1
In [1]: r = requests.get('//www.baidu.com/') In [2]: r.encoding Out[2]: 'ISO-8859-1' In [3]: type(r.text) Out[3]: unicode In [4]: type(r.content) Out[4]: str In [5]: r.apparent_encoding Out[5]: 'utf-8' In [6]: chardet.detect(r.content) Out[6]: {'confidence': 0.99, 'encoding': 'utf-8'}
在requests获取网页的编码格式时,有两种方式encoding和apparent_encoding,结果也不同,
推荐apparent_encoding,常规写法
url='xxx' req =requests.get(url) req.encoding=req.apparent_encoding print(req.text)
总之一句话,遇到乱码加上apparent_encoding就完事了。
参考
//www.cnblogs.com/emmm/p/9792832.html
//www.cnblogs.com/bitpeng/p/4748872.html

