基於Hive進行數倉建設的資源元數據信息統計:Spark篇
- 2021 年 4 月 8 日
- 筆記
在數據倉庫建設中,元數據管理是非常重要的環節之一。根據Kimball的數據倉庫理論,可以將元數據分為這三類: 技術元數據 …
Continue Reading在數據倉庫建設中,元數據管理是非常重要的環節之一。根據Kimball的數據倉庫理論,可以將元數據分為這三類: 技術元數據 …
Continue Reading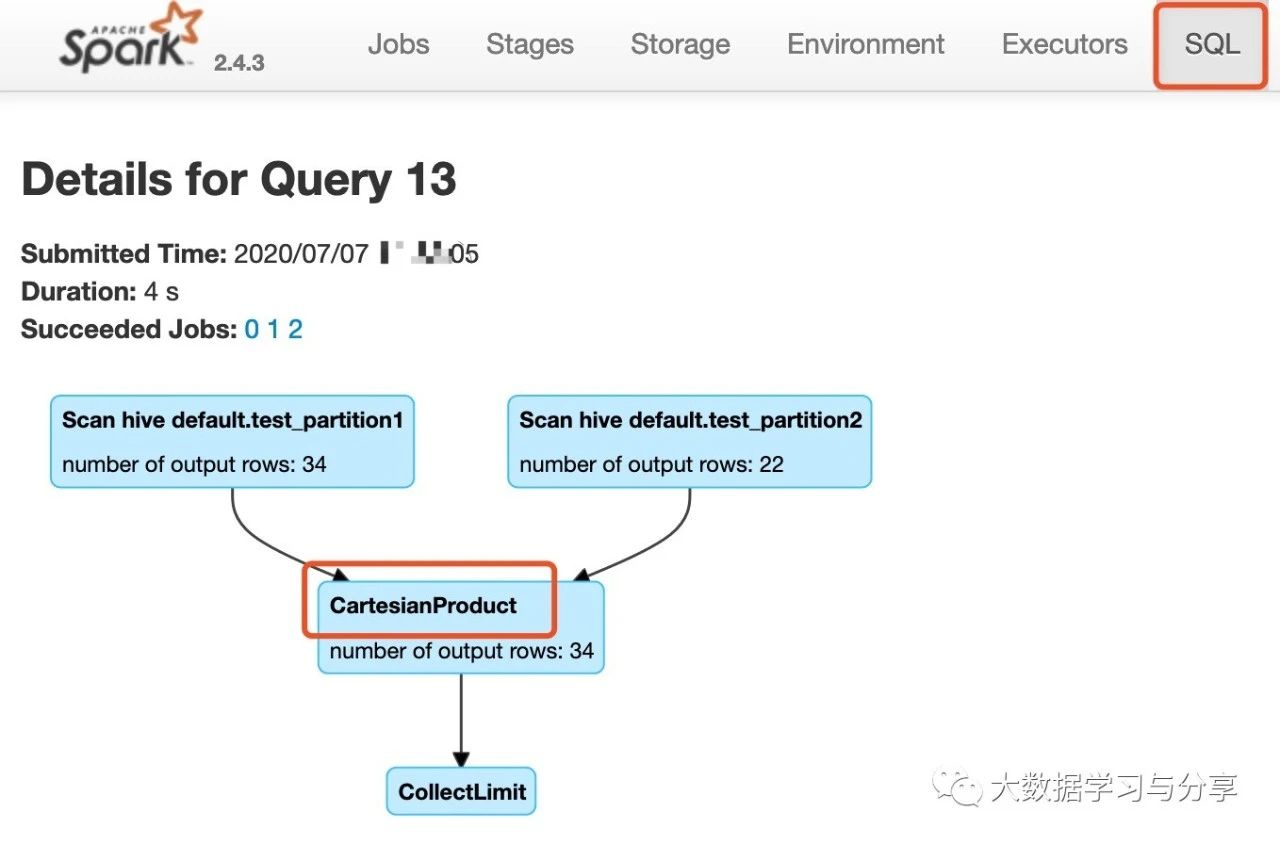
【前言:如果你經常使用Spark SQL進行數據的處理分析,那麼對笛卡爾積的危害性一定不陌生,比如大量佔用集群資源導致其 …
Continue Reading首先看個Not in Subquery的SQL: // test_partition1 和 test_partition …
Continue Reading如果你比較熟悉JavaWeb應用開發,那麼對Spring框架一定不陌生,並且JavaWeb通常是基於SSM搭起的架構,主 …
Continue Reading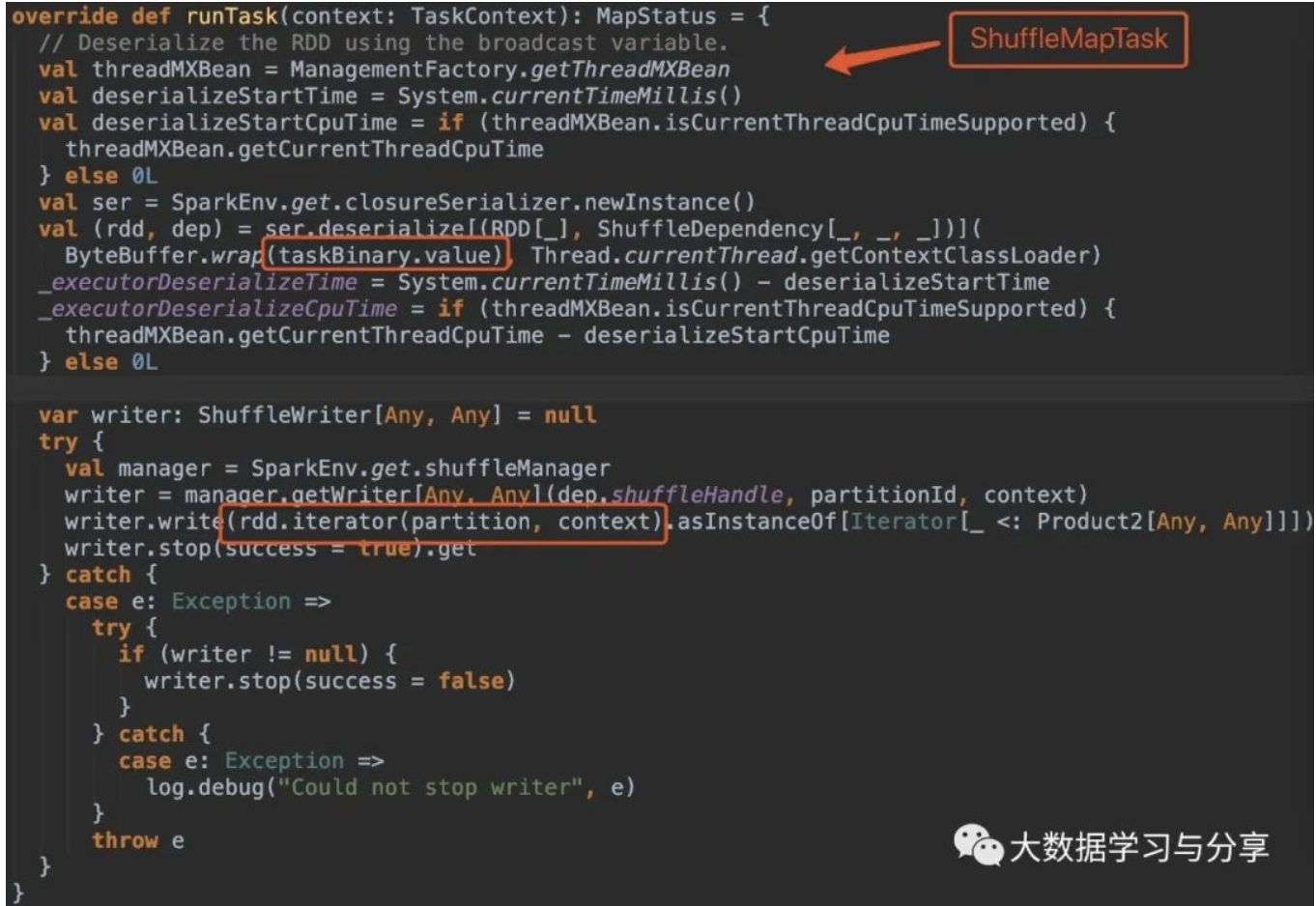
對於Spark的初學者,往往會有一個疑問:Spark(如SparkRDD、SparkSQL)在處理數據的時候,會將數據都 …
Continue Reading
幾年前,包括最近,我看了各種書籍、教程、官網。但是真正能夠把RDD、DataFrame、DataSet解釋得清楚一點的、 …
Continue Reading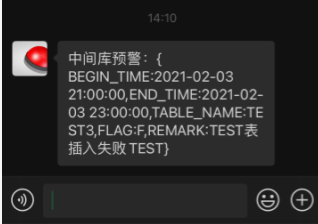
目標: 監控Oracle某張記錄表,有新增數據則獲取表數據,並推送到微信企業。 流程: Kafka實時監控Oracle指 …
Continue Reading前言 眾所周知,Catalyst Optimizer是Spark SQL的核心,它主要負責將SQL語句轉換成最終的物理執 …
Continue Reading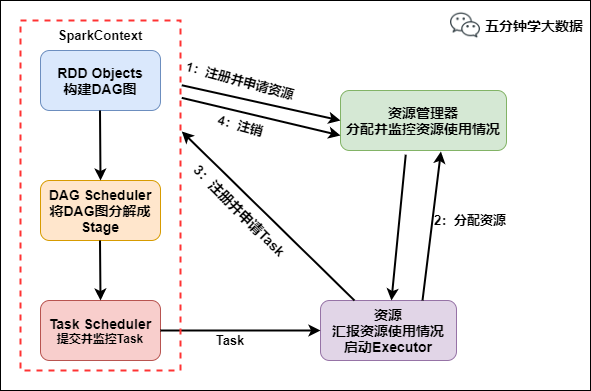
Spark簡介 Apache Spark是用於大規模數據處理的統一分析引擎,基於內存計算,提高了在大數據環境下數據處理的 …
Continue Reading
在之前的文章《解析SparkStreaming和Kafka集成的兩種方式》中已詳細介紹SparkStreaming和Ka …
Continue Reading