
Spark的兩種核心Shuffle詳解
- 2021 年 8 月 16 日
- 筆記
在 MapReduce 框架中, Shuffle 階段是連接 Map 與 Reduce 之間的橋樑, Map 階段通過 …
Continue Reading在 MapReduce 框架中, Shuffle 階段是連接 Map 與 Reduce 之間的橋樑, Map 階段通過 …
Continue Reading
Spark概述 Spark定義 spark是一種基於內存的快速、通用、可擴展S的大數據分析計算引擎 Spark Core …
Continue Reading
摘要:CarbonData 在 Apache Spark 和存儲系統之間起到中介服務的作用,為 Spark 提供的4個重 …
Continue Reading
1.概述 離線數據處理生態系統包含許多關鍵任務,最大限度的提高數據管道基礎設施的穩定性和效率是至關重要的。這邊博客將分享 …
Continue Reading
數據處理的過程 數據處理的過程一般如下: 數據質量管理(DATA Quality Managenment)是指對上述過程 …
Continue Reading經常有同學問我,基於Hadoop生態圈的大數據組件有很多,怎麼學的過來呢,畢竟精力有限,我們需要有側重點,我覺得下面這幾 …
Continue Reading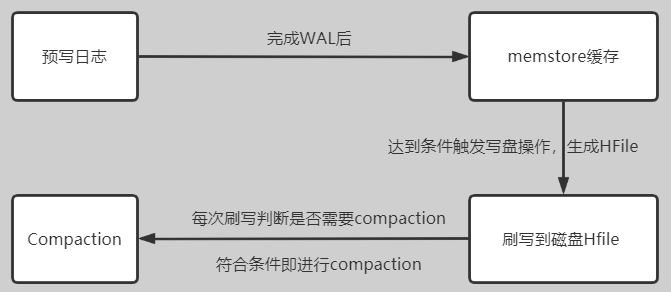
1. Hbase讀寫優化 寫: 批量寫、異步批量提交、多線程並發寫、使用BulkLoad寫入、表優化(壓縮算法、預分區、 …
Continue Reading
一、Flink概述 1、基礎簡介 Flink是一個框架和分佈式處理引擎,用於對無界和有界數據流進行有狀態計算。Flink …
Continue Reading
一、Spark概述 1、Spark簡介 Spark是專為大規模數據處理而設計的,基於內存快速通用,可擴展的集群計算引擎, …
Continue Reading
前言 當我在測試SparkStreaming的狀態操作mapWithState算子時,當我們設置timeout(3s)的 …
Continue Reading