Spark面試題(五)——數據傾斜調優
- 2021 年 11 月 15 日
- 筆記
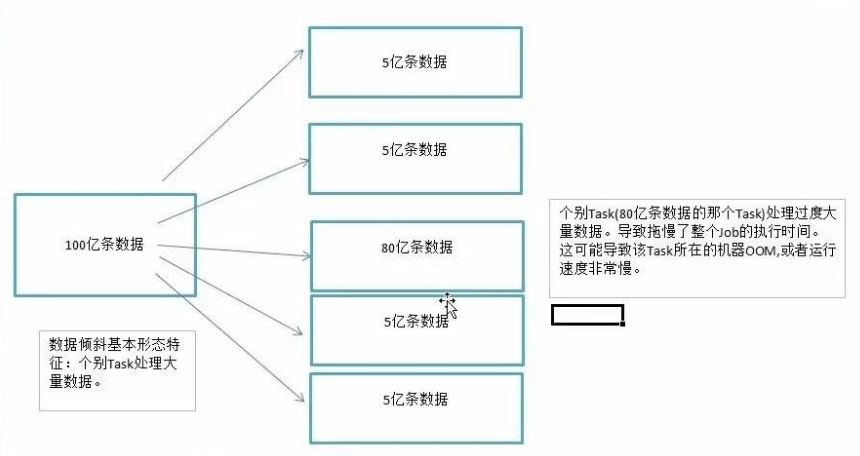
1、數據傾斜 數據傾斜指的是,並行處理的數據集中,某一部分(如Spark或Kafka的一個Partition)的數據顯著 …
Continue Reading1、數據傾斜 數據傾斜指的是,並行處理的數據集中,某一部分(如Spark或Kafka的一個Partition)的數據顯著 …
Continue Readingspark-sql 寫代碼方式 1、idea裏面將代碼編寫好打包上傳到集群中運行,上線使用 spark-submit提交 …
Continue Reading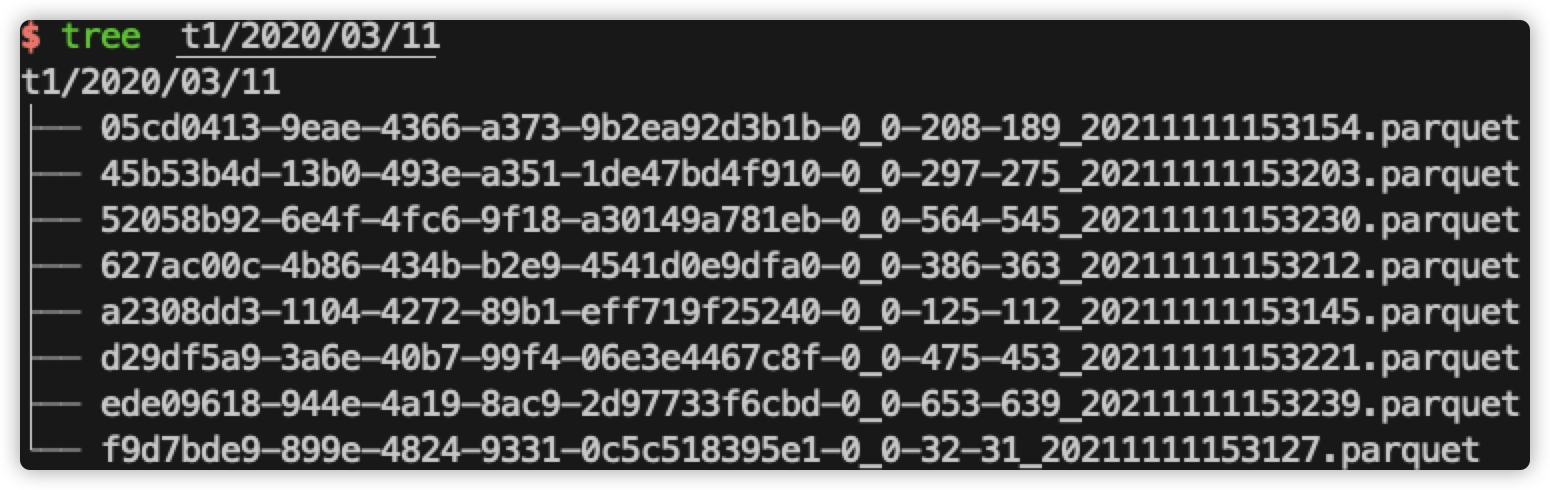
目前最新的 hudi 版本為 0.9,暫時還不支持 zorder 功能,但 master 分支已經合入了(RFC-28) …
Continue Reading
Spark比MR快的原因 1、Spark基於內存的計算 2、粗粒度資源調度 3、DAG有向無環圖:可以根據寬窄依賴劃分出 …
Continue Reading
小文件合併解析 執行代碼: import org.apache.hudi.QuickstartUtils._ impor …
Continue Reading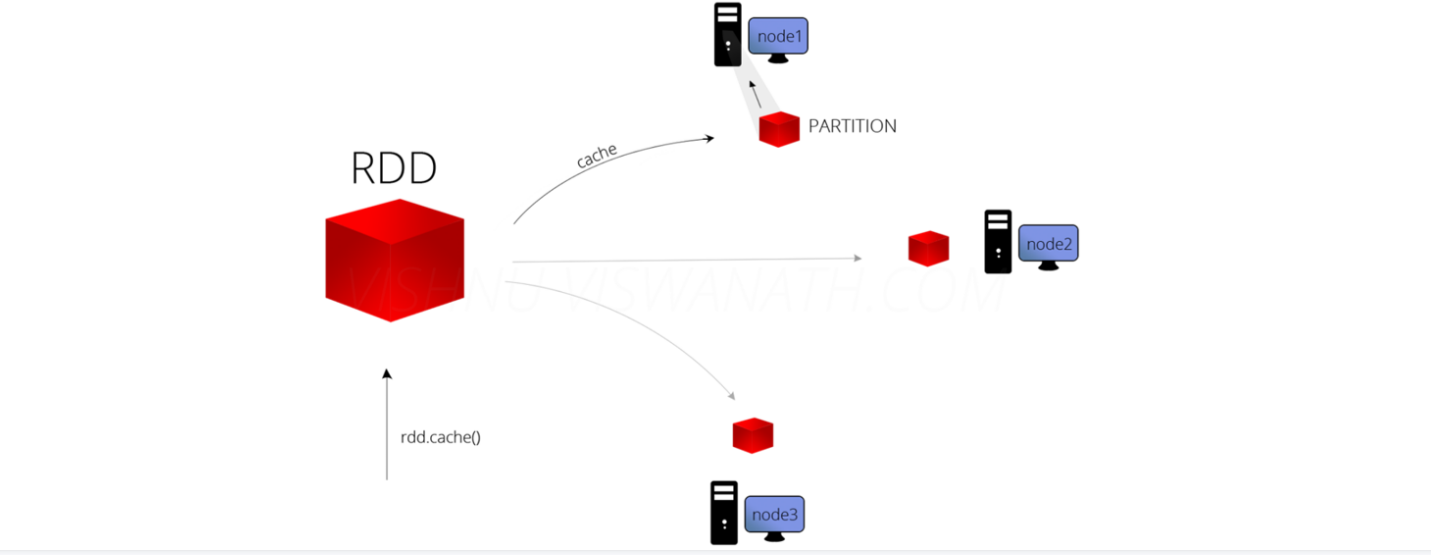
RDD的緩存/持久化 緩存解決的問題 緩存解決什麼問題?-解決的是熱點數據頻繁訪問的效率問題 在Spark開發中某些RD …
Continue Reading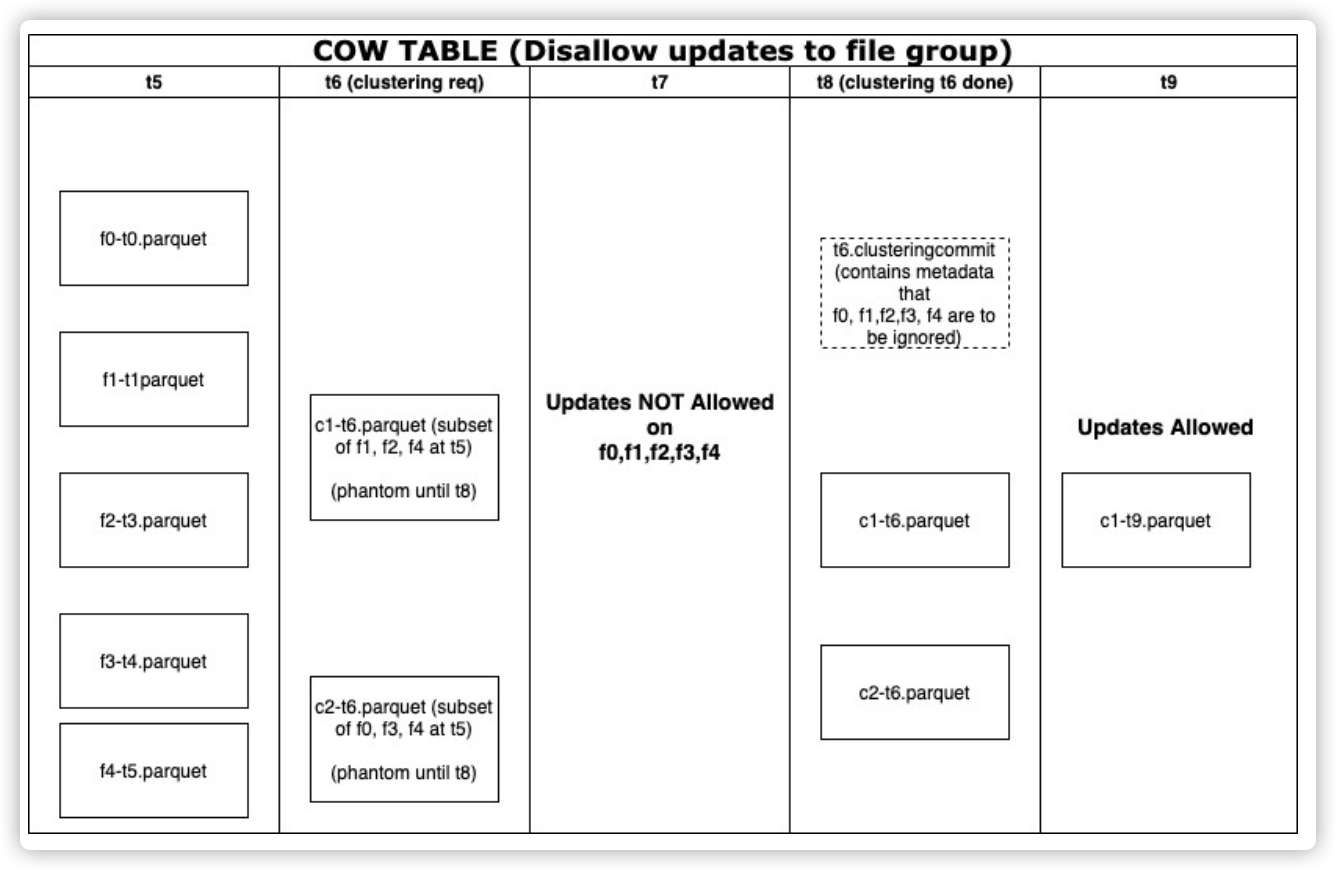
概要 數據湖的業務場景主要包括對數據庫、日誌、文件的分析,而管理數據湖有兩點比較重要:寫入的吞吐量和查詢性能,這裡主要說 …
Continue Reading
RDD的詳解 RDD:彈性分佈式數據集,是Spark中最基本的數據抽象,用來表示分佈式集合,支持分佈式操作! RDD的創 …
Continue Reading
目錄 算子分類 轉換(Transformations)算子 Map FlatMap MapPartitions Filt …
Continue Reading
1.Spark下載 //archive.apache.org/dist/spark/ 2.上傳解壓,配置環境變量 配 …
Continue Reading