
Flink集群部署
- 2022 年 10 月 31 日
- 筆記
集群 standalone 安裝部署 下載安裝包 下載頁面://archive.apache.org/dist/flin …
Continue Reading集群 standalone 安裝部署 下載安裝包 下載頁面://archive.apache.org/dist/flin …
Continue Reading
下面通過一個單詞統計的案例,快速上手應用 Flink,進行流處理(Streaming)和批處理(Batch) 單詞統計( …
Continue Reading
Flink 概述 什麼是 Flink Apache Apache Flink 是一個開源的流處理框架,應用於分佈 …
Continue Reading
HBase 讀寫數據流程 Hbase 讀數據流程 首先從 zk 找到 meta 表的 region 位置,然後讀取 me …
Continue Reading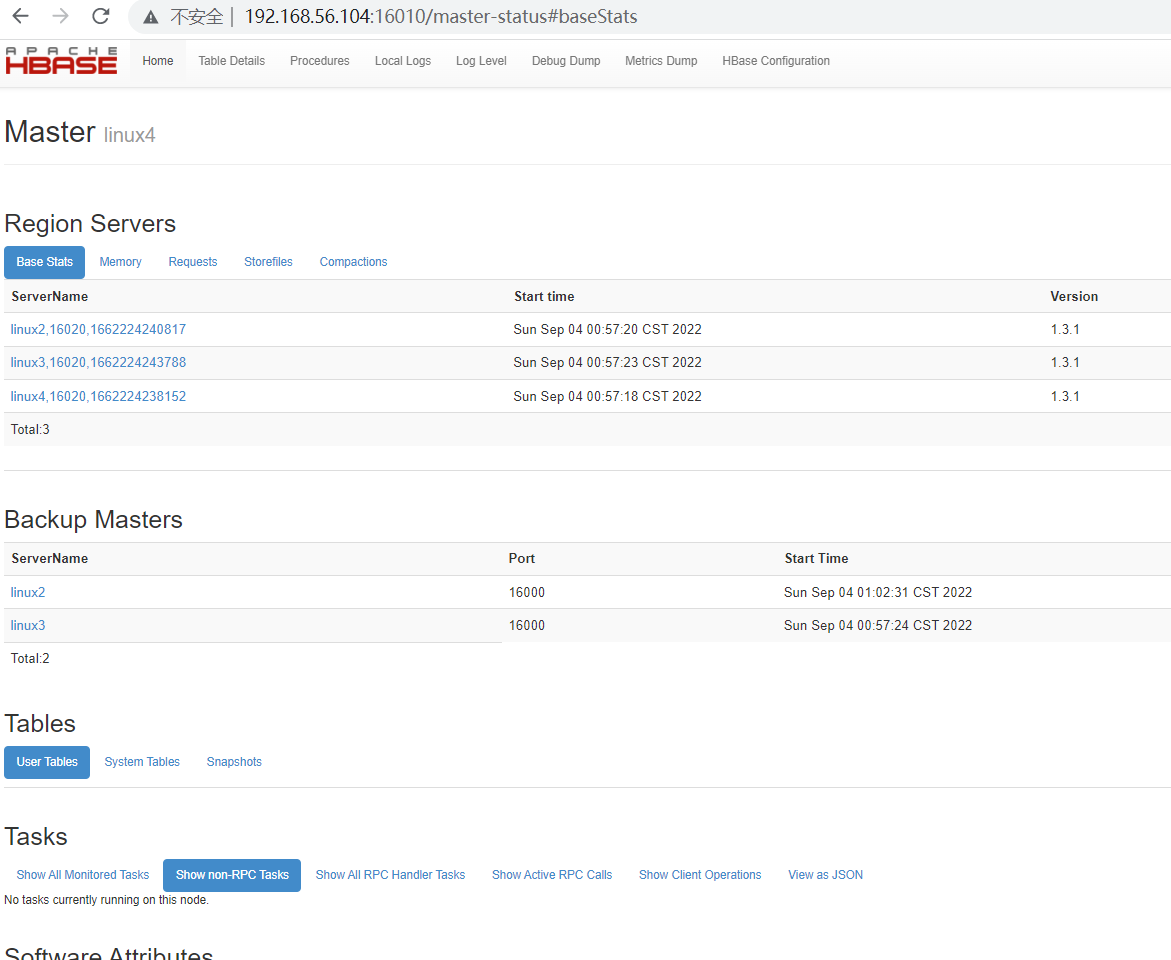
HBase 集群部署 安裝 hbase 之前需要先搭建好 hadoop 集群和 zookeeper 集群。hadoop …
Continue Reading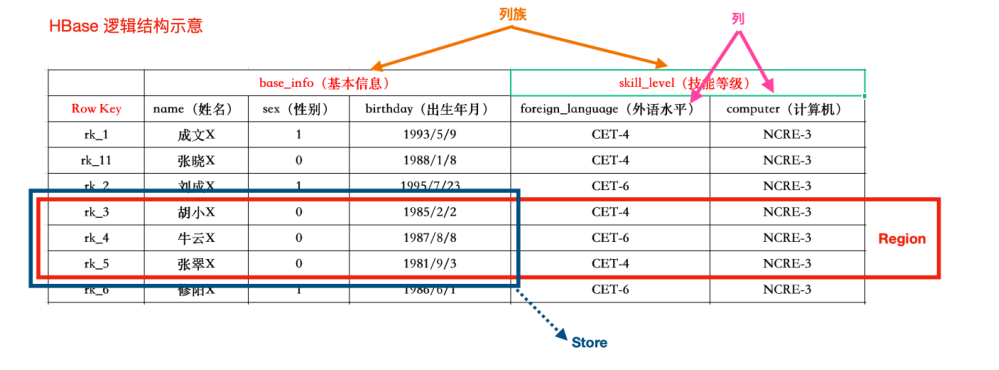
HBase簡介 HBase基於Google的BigTable論文而來,是一個分佈式海量列式非關係型數據庫系統,可以提供大 …
Continue Reading
MapReduce 中的排序 MapTask 和 ReduceTask 都會對數據按key進行排序。該操作是 Hadoo …
Continue Reading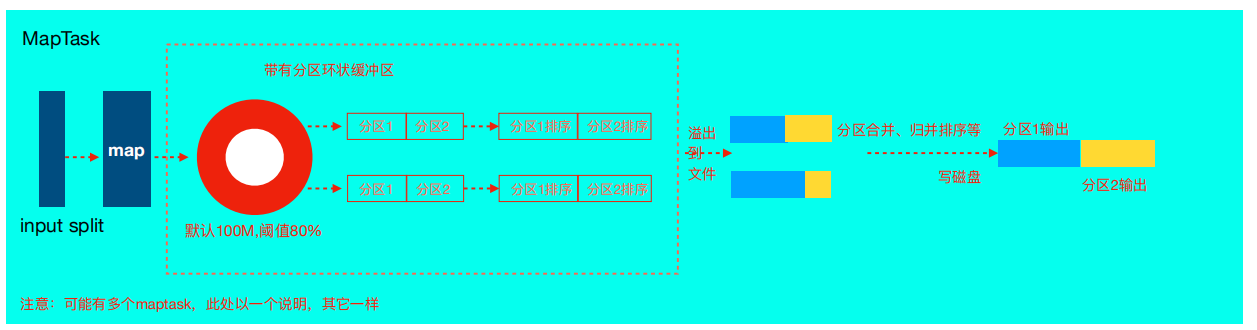
MapTask 運行機制詳解 MapTask 流程 詳細步驟: 讀取數據的組件 InputFormat 會通過 getS …
Continue Reading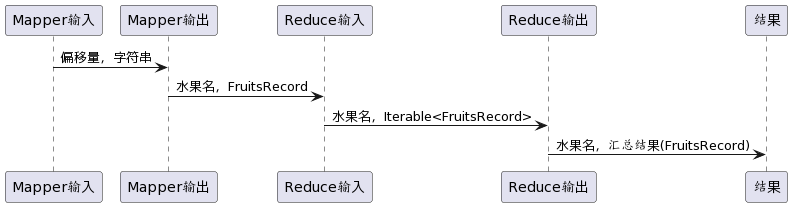
MapReduce 思想 MapReduce 是 Google 提出的一個軟件架構,用於大規模數據集的並行運算。概率「M …
Continue Reading
HDFS 讀寫解析 HDFS 讀數據流程 客戶端通過 FileSystem 向 NameNode 發起請求下載文件,Na …
Continue Reading