【翻譯】藉助 NeoCPU 在 CPU 上進行 CNN 模型推理優化
- 2020 年 4 月 23 日
- 筆記
- Machine Learning, 計算機網絡
本文翻譯自 Yizhi Liu, Yao Wang, Ruofei Yu..
翻譯:coneypo,working in Intel for IoT
這篇文章介紹了基於 TVM 改進的 NeoCPU 方案,在 CPU 上進行 CNN 模型推理優化;
與之對比是 Intel 的 OpenVINO 版本(2018.5 ,最新的是 2020.2),也是做模型推理優化工作;
TVM 深度學習編譯棧希望針對不同的深度學習框架和硬件平台如 CPUs, GPUs 和 專用加速器 提供一個通用的軟件棧(OpenVINO 針對於 Intel CPU,TensorRT 針對於 NV GPU)
儘可能高效率的將不同深度學習框架可以輕鬆的部署到不同的硬件平台上:
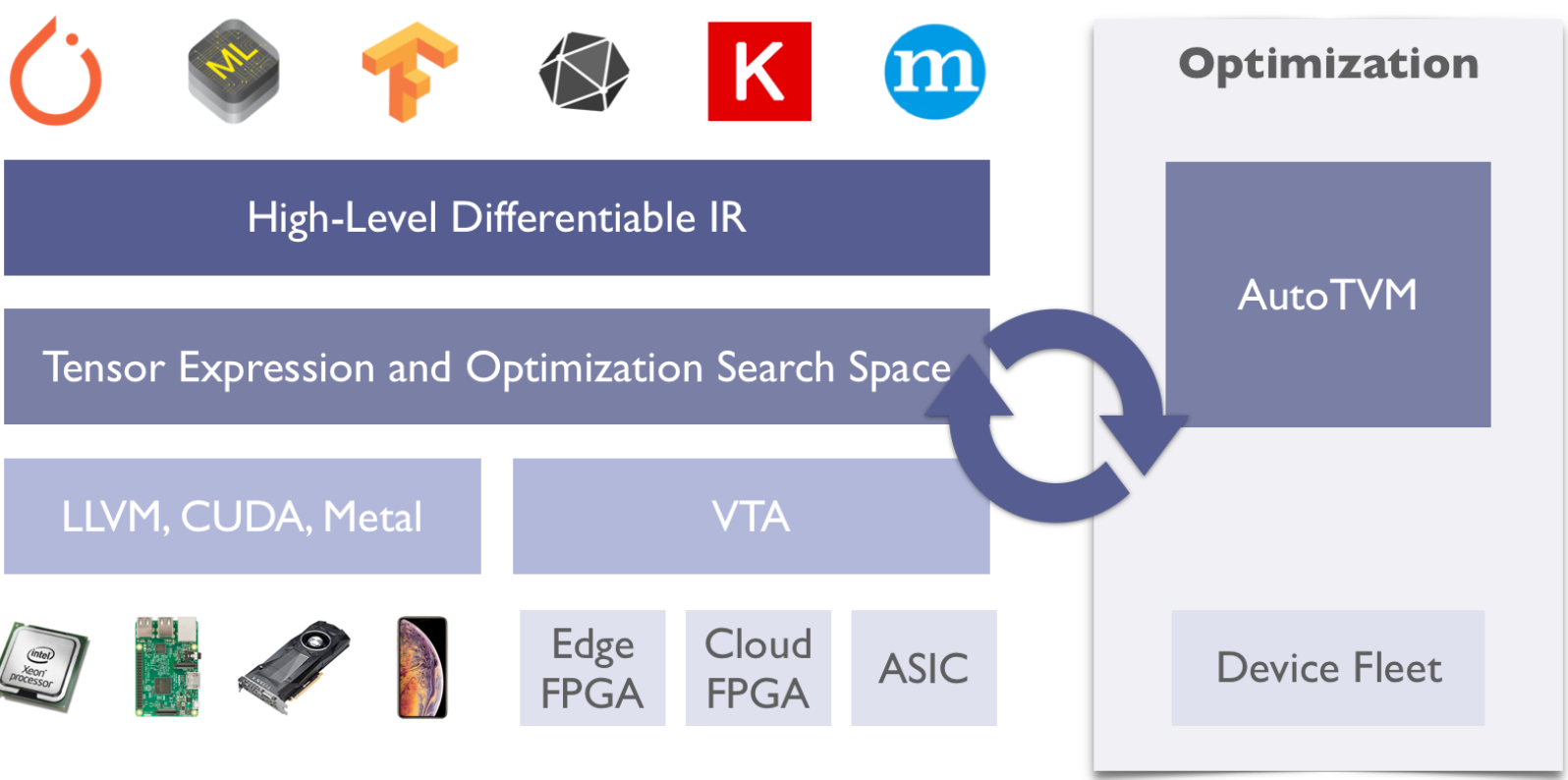
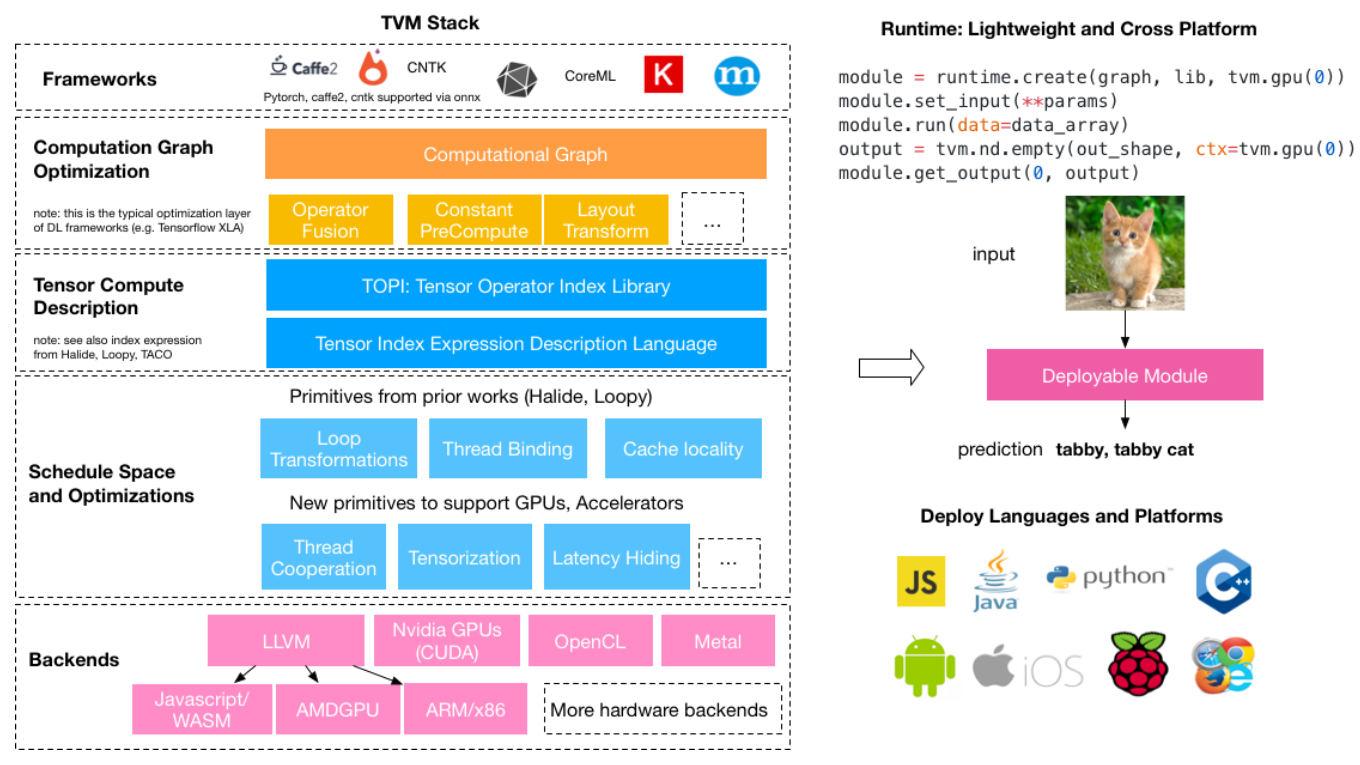
通過下面這張圖,我們可以更好的看到 TVM Stack 做了什麼工作:
Amazon 基於 TVM stack 中提出的一些計算圖優化方式,加上一些自己提出的卷積過程優化方式,來對 CPU 上推理過程進行加速,提出了 NeoCPU ,並且在主流的 CNN 模型上獲得了不錯的加速效果;
摘要
CNN 的流行普及和 CPU 的大規模使用部署,使得如果我們能夠提高 CPU 上進行 CNN 模型推演的性能,這將意義重大;
為了提高 CPU 上面的 CNN 推理性能,現有的方法比如: 在 MXNet 和 Intel OpenVINO,通常把模型視為一個計算圖,然後使用高性能的庫比如 Intel MKL-DNN 來實現圖的優化操作;
儘管通過這些現有的庫可以提高性能,但是由於 Local operation-level / 局部操作級別 的優化已經被預先定義,所以很難在圖級別進行優化;
因此,整體上進行端對端的推理優化很受限制;
這篇文章介紹了 NeoCPU, 一種對 CPU 進行 CNN 模型推斷的綜合方法,採用了全棧式的系統優化方案;
NeoCPU 無需藉助於第三方的庫將操作優化為模板,通過操作和圖像級別的聯合進一步進行性能優化;
實驗表明針對於 CNN 模型推理,相比於其他實現方法, NeoCPU 能夠達到 3.45x 更低延遲;
1 介紹
CNN 模型在計算機視覺領域大規模使用,使得模型架構優化成為關鍵;
相似的,大規模在服務器端,客戶端,邊緣端部署 CPU,也使得 CPU 上進行優化意義重大;
所以如何在 CPU 上進行 CNN 模型推演的優化成為很多用戶研究的重點;
CPU 上 CNN 模型性能的推演還有很大提升空間;
CNN 模型推演本質上就是進行執行 a computation graph consisting of operations / 一張由一系列操作構成的計算圖;
在實際應用時,大家經常高性能的 kernel 庫(比如 Intel MKL-DNN 和 OpenBlas)來提高 CNN 操作性能;
這些庫一般輸入目標數據形狀(比如 2D 卷積),然後進行常規調用操作,但是這些庫大多數情況下只關注於(大多數情況下是卷積)操作,而錯過了在圖級別進行進一步端對端模型推理的優化機會;
圖級別的優化往往是交給深度學習框架,比如 TensorFlow 和 MXNet;
然而,圖級別的優化,比如 operation fusion / 操作融合 和 data layout planning / 數據布局規劃,往往因為已經在第三方庫中被預先定義而被限制;
因此框架中的優化工作和 kernel 庫中的優化相衝突,這使得有性能提升空間但是沒有被發掘;
此外,不同的 CPU 架構會依賴不同的高性能庫,把庫和深度學習框架整合很容易出錯,而且很耗費開發時間;
而且儘管這些庫被高度優化過,它們是作為第三方的 plug-ins,這使得可能會和框架中其他的庫引起衝突;
比如說 TensorFlow 原本使用 Eigen 庫來處理 CPU 的計算,後來引入 MKL-DNN,所以運行 MKL-DNN 線程會和 Eigen 的線程導致資源爭用,引起衝突;
所以這種 framwork-specific / 依賴框架 的方法,用於 CPU 上進行 CNN 模型推算是不靈活,麻煩而且效果不好的;
由於框架的限制,如何不引入框架(比如 framework-agnostic / 框架無關 method),來進行 CNN 模型推理性能的優化成為了很多人想要解決的問題;
最近,Intel 發佈了一款通用的 CNN 模型推理引擎,稱之為 OpenVINO 開發套件;
這款開發套件在 x86 平台的 CPU 進行計算機視覺任務的 CNN 模型優化,而且相比於單獨使用深度學習框架,能夠獲得更好的性能;
由於 OpenVINO 也是基於 MKL-DNN 來進行調用操作,所以只能提供有限的 Graph-level / 圖級別 的優化(比如 ngraph 中的操作融合);
因此 OpenVINO 進行優化對於大多數 CNN 模型意義不大;
基於之前的研究觀察,我們得出這樣的結論——「flexible end-to-end optimization / 靈活的端對端優化」 是進一步提高 CNN 模型推理能力的關鍵;
這篇文章中,我們建議使用 NeoCPU 方式進行 CPU 上 CNN 模型的優化;
NeoCPU 是全棧的和系統性的,其中包括操作界別和圖像級別的聯合優化,而不是依靠第三方高性能庫;
在操作級別,我們利用成熟的技術來優化計算量最大的操作,比如模板中的卷積操作,適用於在不同 CPU 架構上跑不同負載,而且讓我們可以在圖級別靈活操作;
在圖級別,除了常規的比如操作融合和推理簡化,我們通過操縱數據布局流程來協調各個操作的優化,貫穿整個模型以獲得最佳的性能表現;
總而言之,NeoCPU 通過一種靈活和高效的方式,進行端到端的優化,而現有的其他方式往往依賴於第三方庫,需要進行性能調優;
NeoCPU 基於深度學習編譯棧 TVM 進行一系列改進;TVM 讓我們可以進行操作級別的優化,而不是依賴於第三方庫,這使得我們很靈活的可以進行 operation-level / 操作級別 和 graph-level / 圖級別 的整合;
然而,在 ARM CPU 上,只有一種對於特定類型數據,進行定製化的 operation-level / 操作級別 的優化;
在此之前,TVM 沒有提供 operation-level / 操作級別 和 graph-level / 圖級別 的聯合優化功能;
除此之外,一些其他深度學習編譯器比如 Tensor Comprehensions 和 Glow,它們都不是專註於在 CPU 上進行優化,或者對於 CPU 上優化的性能提升沒有那麼顯著;
比如基於文章描述以及我們自己的實驗,Glow 僅僅優化 CPU 中的單核性能,因此我們不建議採用這種方式;
表 1 總結了 NeoCPU 和其他優化方式的對比,在幾種主流的 CPU 上優化性能結果表現不錯;
| Op-level opt | Graph-level opt | Joint opt | Open-source | |
| NeoCPU | 支持 | 支持 | 支持 | 支持 |
| MXNet / TensorFLow | 第三方 | 有限的 | 不支持 | 支持 |
| OpenVINO | 第三方 | 有限的 | 未知 | 不支持 |
| Original TVM | 不完善 | 支持 | 不支持 | 支持 |
| Glow | 支持單核 | 支持 | 不支持 | 支持 |
這篇文章會介紹以下幾點:
- 提供一種在不同主流 CPU (Intel, AMD 和 ARM)上的 operation- and graph-level joint optimization scheme / 操作級別和圖級別的聯合優化方案 來獲取高性能的 CNN 模型推演性能,表現要好過目前的其他方案;
- 構建一種模板可以進行高效率的卷積,通過這種方式,可以靈活的在不同架構 CPU (x86 和 ARM)上進行卷積操作的優化,而不需要依賴於第三方高性能內核庫;
- 設計一種全局的方案,在一個 CNN 模型中的不同操作組合中,尋找最優布局方式,在保證高性能的同時,減少操作之間數據布局轉換帶來的開銷;
值得注意的是,本文主要考慮 direct convolution computation / 直接卷積運算,NeoCPU 也兼容在其他計算密集型內核上的優化工作,比如通過 Winograd 和 FFT 進行卷積;
用 15 種主流的神經網絡進行測試,我們在 x86 和 ARM 架構的 CPU 上進行了 NeoCPU 的評估,NeoCPU 的表現出色:
- 在 Intel Skylake CPU 上,15 種中 13 種最優;
- 在 AMD EYPC CPU 上,15 種中 14 種最優;
- 在 ARM Cortex A72 CPU 上,15 種中 15 種最優;
值得注意的是,在 x86 CPU 上,Intel 利用 Intel MKL-DNN 進行調優,而對於 AMD 的 CPU 優化程度很低;
選擇 framework-specific / 指定框架(比如 MXNet 和 TensorFlow)和 framework-agnostic / 框架無關(OpenVINO)的解決方案,往往在某一種情況下表現突出,而在另一種情況下表現較差;
而 NeoCPU 在不同架構的 CPU 上的表現十分的均衡高效;
除此之外,NeoCPU 提供一個小尺寸的獨立模塊,不依賴於框架或者高性能內核庫,可以在不同平台上輕鬆部署;
NeoCPU 在 Amazon 的 SageMaker Neo Service 上部署使用,使得模型開發者可以在基於 CPU 的雲端服務器和邊緣端設備進行推算優化;
已經有很多應用開發者在藉助 NeoCPU 在不同平台上進行 CNN 模型的部署推算優化;
所有的源碼都在 TVM 的開源項目中進行發佈;
這篇文章剩下部分介紹如下內容:
- 第二章介紹了現代 CPU 的背景和典型的 CNN 模型;
- 第三章介紹了我們提出的優化思路以及如何實施;
- 第四章介紹了對於該方案的評估;
- 第五章介紹了相關工作;
- 第六章總結;
2 背景
2.1 現代 CPU
儘管加速器比如 GPU 和 TPU 在深度學習中表示出色,但是很多深度學習的計算工作,尤其是 model Inference / 模型推理,是在 CPU 上進行的;
如今,大多數 CPU 都是 Intel 或者 AMD 的 x86 架構,與此同時 ARM 的 ARM CPU 佔據了嵌入式和移動設備市場;
製程工藝的提升,晶體管尺寸不斷變小,使得我們可以製造出更大規模和更複雜的處理器,藉此 CPU 通過增加核心數來實現和提高並行計算能力;
在一個多核處理器上,要避免不同線程之間的干擾至關重要,最小化線程間的 synchronization cost / 同步損耗;
在處理器內部,一個單個物理核通過 SIMD (single-instruction-multiple-data,單指令多數據流) 技術來達到最高性能;
SIMD 將多個值加載到 wide vector registers / 寬向量寄存器,然後一起處理;
(* SIMD 是一種採用一個控制器來控制多個處理器,同時對一組數據(數據向量)中的每一個分別執行相同的操作,從而實現空間上的並行性的技術;)
比如 Intel 提出了 512-bit Advanced Vector Extension instrcution set (AVX-512),在每個 CPU 循環周期,處理 16 個 32 位單精度浮點數(總共 512 位);
AVX2 在 256 位的寄存器中處理數據;
除此之外,這些指令集利用 Fused-Multiply-Add (FMA) 技術來執行向量化的乘法,然後在同一個 CPU 循環周期中,將累加結果存儲到另一個向量寄存器中;
類似於 SIMD 的技術也被集成在 ARM CPU 和 NEON 上;
我們希望能夠找到一種在 x86 和 ARM 的架構 CPU 上通用的優化方式;
除此之外,值得注意的是,如今大多數服務器端的 CPU 通過 simultaneous multi-threading (SMT) 技術,支持 hyper-threading / 超線程 技術;
這樣的話在一個物理核上可以有兩個虛擬核,用來提高系統吞吐量;
然而超線程對於性能的提升取決於應用程序;
在我們的案例中,我們不使用超線程,因為一個線程會佔用對應物理核心的資源,如果在同一個物理核上再開一個線程,會造成性能下降;
我們還會通過共享內存模式 (典型 CNN 模型推理中的系統設置)來限制我們的優化在處理器內;
Non-Uniformed Memory Access (NUMA) / 非統一內存訪問 不在本文討論範圍之內;
2.2 Convolutional neural networks / 卷積神經網絡
Convolutional neural networks (CNNs)/ 卷積神經網絡 在計算機視覺任務中大規模使用;一個 CNN 模型經常被抽形成一個 computation graph / 計算圖;
本質上計算圖就是 Directed Acyclic Graph (DAG) / 有向無環圖 ,一個節點代表一個操作,一個從 X 連到 Y 的線表示操作 X 輸出,然後輸入到操作 Y);
執行一個模型推理實際上就是在計算圖中輸入數據,然後得到輸出;
進行圖的優化(比如 prune unnecessary nodes and edges / 刪除多餘節點,pre-compute values independent to input data / 預計算值獨立於輸入數據)可以提高模型推算性能;
CNN 模型推理中的中的絕大多數計算工作,是在 convolutions (CONVs) / 卷積;
這些操作本質上完全可以利用 CPU 中的並行化,矢量化和 FMA 特性;
已有的研究表明,通過對數據布局的優化調整,完全可以在 CPU 上進行卷積操作的優化;
剩下的挑戰就是如何有效的管理數據流程,來讓 CNN 模型推理獲的高性能;
CNN 其餘工作大多數都是卷積中和內存相關的操作(比如 batch normalization / 批量歸一化,pooling / 池化,activation / 激活,element-wise addition / 逐元素添加 等等);
常規做法是將它們融入卷積操作,提高整體的算法複雜度,來提高性能;
CNN 模型的計算圖訓練本質上和推理沒有區別,僅僅更大規模(加入了 backwards 運算)和一些計算上的瑣碎運算(比如損失函數);
因此針對於 CNN 模型推理時的優化工作也可以用於訓練;
3 Optimizations / 優化
這章我們會介紹我們的優化思路以及如何實現;
這篇文章中介紹的 CNN 模型推算優化方法是針對於 end-to-end / 端對端 情況;
我們的給出的方案,適用於大多數常見的 CNN 模型;
基本思路是把優化視為一個端對端的問題,然後尋找全局的最佳優化,也就是說,我們不關注於對於單個操作的優化;
為此,我們首先介紹如何利用可配置的模板,來進行 low-level computationally intensive convolution operations / 低層密集型卷積運算 的優化;
通過選擇運算間適當的數據布局,來減少不必要開銷,使得在一個特定 CPU 架構上,針對一個特定的卷積任務,找到最優實現方式更加靈活;
我們基於 TVM stack,在 compiling pass / 編譯過程, operation scheduling / 操作調度 和 runtime components / 運行組件 加入了一些新特性來實現優化;
原生的 TVM stack 已經實現了一些圖級別的優化(包括 operation fusion / 運算融合,pre-computing / 預運算 和 simplifying interfence for batch-norm and dropout / 歸一化和丟棄的簡化),這些在我們的項目中也進行了採用,但是在此不會去介紹;
3.1 Operation optimization / 運算優化
卷積運算的優化對於整個 CNN 任務性能的提升至關重要,因為卷積運算佔據了整個運算過程中的大多數;
這是一個已經深入研究過的問題,但是以往的解決方法往往是在彙編代碼層面去研究;
在這一節,我們會利用利用 CPU 的特性(SIMD,FMA,並行化等等)來針對單個 CONV 進行優化,而無需考慮繁瑣的彙編代碼和 C++ 代碼;
通過全局的管理實現,會很容易的把我們的優化方式從單個運算拓展到整個計算圖;
3.1.1 Single thread optimization / 單個線程優化
我們首先在一個線程中進行 CONV 優化;
CONV 操作計算量大,需要多次遍歷操作數來進行運算; 因此管理輸入到 CONV 的數據布局至關重要,是減少內存訪問開銷的關鍵;
我們首先回歸到 CONV 運算本身來說明內存管理機制;
CNN 中一個 2D 的 CONV 輸入 一個 3D 特徵(高度 x 寬度 x 通道數)和 多個 3D 卷積核(通常比高度和寬度小,但是和通道數一樣),輸出另一個 3D 的 tensor / 張量;
計算過程在圖 1 中進行說明(六個參數:in_channel, kernel_height, kernel_width, out_channel, out_height 和 out_width):
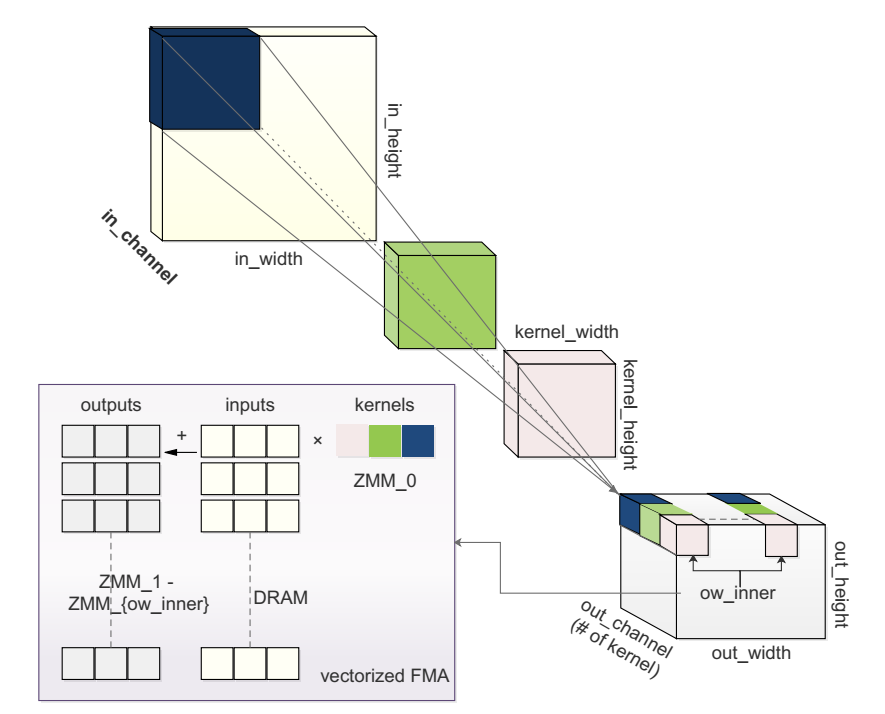
圖 1 CONV 和 AVX-512 指令集中高效實現的例子;有三種分別塗成深藍,綠色和粉色的核;為了能夠高效的 FMA(Fused multiply-add),不同核的值被打包成一個 ZMM 寄存器,和不同輸入值相乘,然後累加到不同的 ZMM 寄存器的輸出值中;
卷積核在輸入特徵圖上滑動,對應位置相乘求和,產生輸出特徵圖中相應的元素,可以利用到 FMA;
卷積核的數目構成了 out_channel;
注意 in_channel,kernel_height 和 kernel_width 相互約束,不能被 embarrassingly parallelized / 高度並行化處理 ;
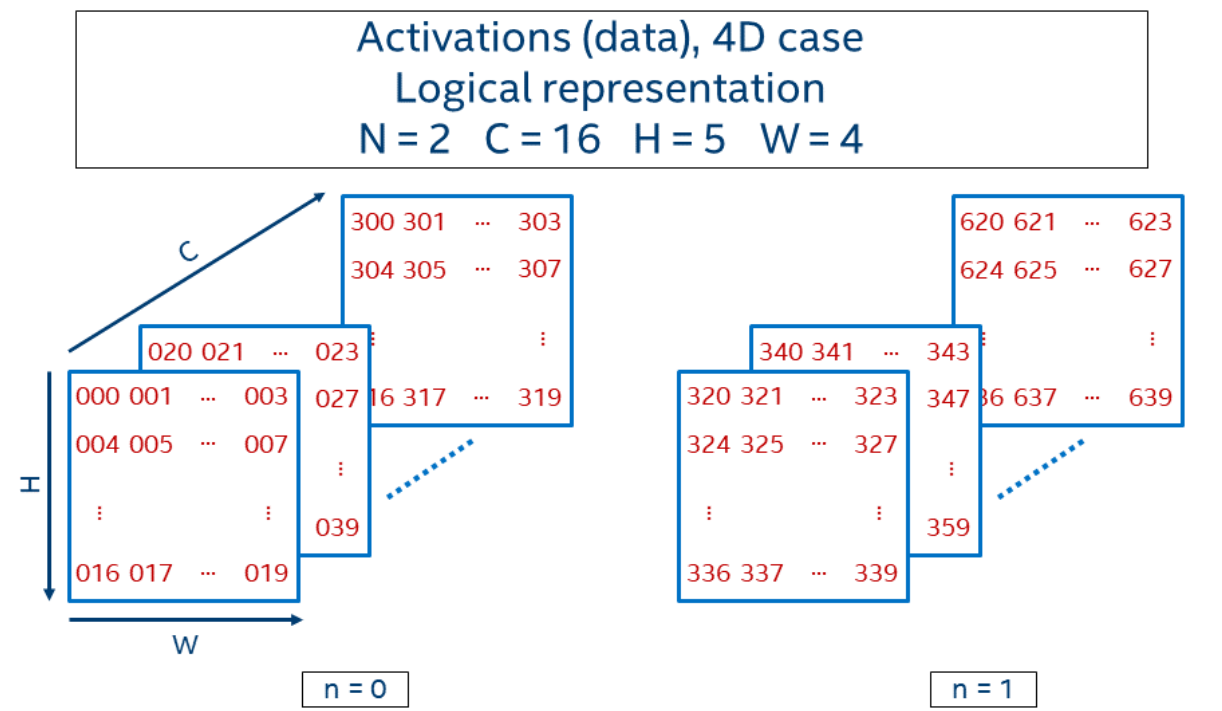
*補充圖 NCHW 介紹://oneapi-src.github.io/oneDNN/understanding_memory_formats.html
我們使用傳統的輸入方式 NCHW (輸入和輸出是 4D 的張量,N:批次大小, C:通道數,H:特徵圖高度,W:特徵圖寬度)來描述我們默認的數據布局;
相關的卷積核是 KCRS(K:輸出通道,C:輸入通道,R:核高度,S:核寬度);
根據經驗,我們將特徵圖的格式設置為 NHCW[x]c (c 是通道數 C 拆分出來的子維度,x 是子維度的分割大小);
比如 sizeof(c) = x,通道數 C = sizeof(C)x sizeof(c) 大小;
輸出和輸入一樣格式: NCHW[y]c,這裡分割因子可以不同;
對應地,卷積核是 KCRS[x]c[y]k,分割尺寸為 x 的 c 和分割尺寸為 y 的 k,是輸入通道 C 和 輸出通道 K 的子維度;
值得注意的是為了得到理想的布局,需要有大量數據轉換的資源開銷;
除了尺寸地重新排序,為了更好利用最新的向量指令集(比如 AVX-512,AVX2,NEON 等等),我們藉助算數因子 reg_n 把 out_width 分成了 ow_outer 和 ow_inner,然後把 ow_inner 的循環移動到 register blocking 內部;
比如在一塊支持 AVX-512 的 CPU 上,我們可以利用 32 x 512 位寬度的寄存器 ZMM0 – ZMM31 ;
我們保持這樣的循環機制:一個 ZMM 寄存器存儲 kernel 數據的同時,其他的寄存器存儲特徵圖;
通過 AVX-512F 指令集,一個 ZMM 寄存器 中存儲的 kernel 值(最高 512 bits,float32 x 16 個輸出通道)被用來和 多個 DRAM 中連續不斷的輸入特徵圖 相乘,這些結果之後又會被累加存儲到別的 ZMM 寄存器中;
圖 1 說明了這種方法思路;
針對於其他向量化的指令,我們也可以用這種思路,但是需要改變 out_width (比如 reg_n)的 split factor / 分割因子;
算法 1 總結了我們在單線程中 CONV 的優化方式,本質上是:
- Dimension ordering for friendly memory locality / 優化布局格式來優化內存訪問
- Register blocking for good vectorization instruction utilization / 寄存器阻塞以實現良好的矢量化指令利用率
然而不同於其他方式,我們在高級編程語言中,我們定義了一個 template,其中 block 尺寸(x,y),使用寄存器的數目(reg_n),和 loop-unroll strategy(unroll_key)很容易就可以配置;
所以根據不同的 CPU 架構(緩存大小,向量寬度等等)或者不同的任務(特徵圖大小,卷積核大小等等),我們可以進行計算邏輯的調整;
這樣的話很靈活,也使得我們下一步進行圖級別的優化成為可能;
算法1 :通過 FMA 實現 CONV 操作算法
PARAM: x > 0 s.t. in_channel mod x = 0
PARAM: y > 0 s.t. out_channel mod y = 0
PARAM: reg_n > 0 s.t. out_width mod reg_n = 0
PARAM: unroll_ker from {True, False}
INPUT: IFMAP in NCHW[x]c
INPUT: KERNEL in KCRS[x]c[y]k
OUTPUT: OFMAP in NCHW[y]c
for each disjoint chunk of OFMAP do > parallel
for ow.outer:=0 -> out_width/reg_n do
Initialize V_REG1 to V_REGreg_n by 0
for ic.outer:=0 -> in_channel / x do
for each entry of KERNEL do > (opt) unroll
for ic.inner:=0 -> x do
vload(KERNEL, V_REG0) > y floats
for i:=1 -> reg_n + 1 do > unroll
vfmadd(IFMAP, V_REG0, V_REGi)
end for
end for
end for
end for
for i:=1 -> reg_n + 1 do
vstrore(V_REGi, OFMAP)
end for
end for
end for
3.1.2 Thread-level parallelization / 線程級別並行化
通常我們把 CONV 任務分割成幾塊,然後在 CPU 不同核上進行並行運行;
內核庫比如 Intel 的 MKL-DNN 經常使用現成的多線程方案,比如 OpenMP;
然而我們發現利用這種現成並行方案的可拓展性並不理想;
因此我們定製化了一個 thread pool / 線程池 來高效的處理這種尷尬的並行問題;
在一個有 N 個物理核心的系統中,我們將操作的的最外層循環分成 N 份,然後分給 N 個線程;
然後我們在並發期間,通過 C++ 11 atomics 來協調線程,然後在調度程序和每個工作線程之間,通過 an single-producer-single-consumer / 單生產者單消費者模式 的 lock-free queue / 無鎖隊列 ;
活躍的線程在不同的物理核上運行,來保證最小化的硬件衝突,正如之前所提到,我們沒有打開超線程;
對於可以被多個線程訪問的全局數據結構(比如 lock-free queues / 無鎖隊列),我們根據需要來插入緩存進行填充,來避免線程之間的錯誤共享;
總而言之,這個定製化的線程池,通過這種機制,來減少資源爭奪衝突,並減少線程啟動開銷,這使得這種方式的性能要好於 OpenMP;
3.2 Layout transformation elimination / 布局轉換(開銷)消除
在這一節,我們把 CNN 模型中的 單個操作優化 拓展到 整個計算圖的優化;
主要的思路來源於 3.1 節介紹的從圖級別減少數據布局轉化開銷;
之前的操作關注於單步的操作優化,而沒有考慮高度優化的操作之間,數據布局轉換要帶來的開銷;
在 CNN 模型計算中,大多數的工作量是 CONVs,而輸入一般都是 NCHW[x]c ,所以我們應該確保每個 CONV 都在布局裏面執行;
然而,有些 CONVs 之間的操作可能只和默認布局兼容,導致每一個 CONV 在計算之前需要將輸入數據布局(NCHW 或者 NHWC)轉換成 NCHW[x]c,並在最後將其轉換回去;
這種轉換會帶來明顯的性能開銷;
幸運的是,從圖級別去看,我們可以把 CONV 之外的布局視為一個獨立的節點,僅在必要的時候去插入;
也就是說,我們消除了 CONV 計算時候發生的轉換,並儘可能地通過圖保持轉換後的布局流程;
為了判斷一個數據轉換是否有必要,我們首先根據操作和數據的接觸方式來分為三類:
1. Layout-oblivious operations / 布局無關操作:
這些操作不需要考慮 layout,可以在任意布局中處理數據,比如 ReLU,Softmax 等等;
2. Layout-tolerant operations / 布局半依賴操作:
這些操作需要知道處理的 data layout,比如 CONV,對於我們來說,要處理 NCHW,NHWC 和NCHW[x]c 布局; 還有其他一些操作比如 Batch_Norm, Pooling 等等;
3. Layout-dependent operations / 布局依賴操作:
這些操作只在特定 layout 裏面進行,它們不接受數據轉換,因此在進行這種操作之前,要事先轉換好特定格式;比如 Flatten, Reshape 等等;
典型 CNN 模型中 CONVs 之間操作是布局無關的(比如 ReLU,SoftMax, Concat 和 ElemwiseAdd)或者 layout-tolerant (比如 Batch_Norm 和 Pooling)類型的,使得數據格式可以保持 NCHW[x]c 來跨越卷積層;
從 NCHW 到 NCHW[x]c 的格式轉換髮生在第一次 CONV 之前;CONVs 之間的的數據布局可以維持相同格式而不進行轉換(比如 NCHW[x]c 的 x 值相同);
只有依賴布局的操作,比如 Flatten ,數據布局要從 NCHW[x]c 轉換回 NCHW;
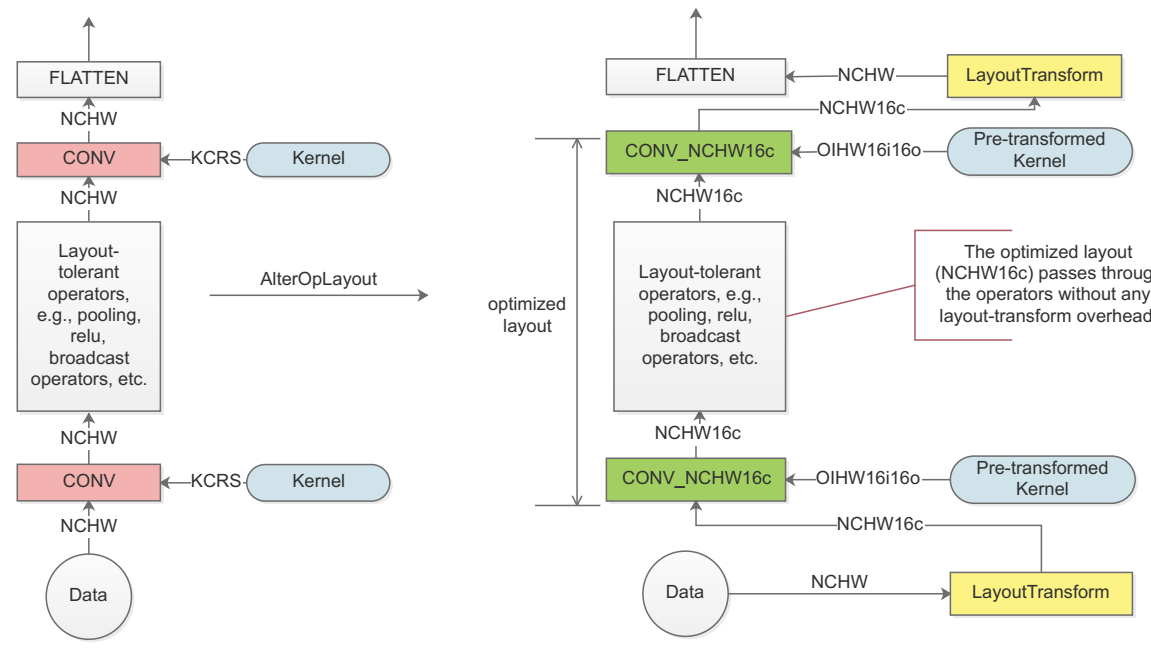
圖 2:一個簡單 CNN 模型的布局優化;左邊的流程是默認的數據布局,每一個粉色的 CONV 節點需要額外的開銷來進行數據轉換,以獲得好的性能表現,然後再轉換成默認布局;
右邊的流程在圖級別進行優化,最小化數據布局轉化開銷;綠色的 CONV 節點在計算前後不需要進行任何數據轉換;
實際操作中,我們首先遍歷我們的計算圖,來推斷所有節點的數據格式,正如圖 2 左邊的流程圖所示,然後我們將 CONVs 的布局從默認轉換為 NCHW[x]c 來獲得更好性能表現;
注意到為了避免進一步轉換,我們把 x 定義為 a constant number / 常量;
然而為了優化性能, x 的值在不同的 CONVs 層可能不一樣,所以需要進行布局轉換;我們將會在 3.3 節進一步說明;
最後,將 LayoutTransform 節點相應地插入到計算圖中;
因此我們仍然具有網絡的 NCHW 輸入輸出,但是 CONV 層之間內部布局,是以優化過的 NCHW[x]c 格式存在的,正如圖 2 右邊所示;
值得注意的是,模型參數的布局(比如卷積核權重 ,Batch_Norm 的均值和方差)是不變的,所以可以在編譯期間進行預先轉換;
我們通過向 TVM stack 引入多個圖級別的優化過程來實現這個方法;
通過儘可能保持 CONV 層之間,轉換後的格式布局不變,和編譯時候對卷積核權重的預轉換,我們進一步提高了 CNN 模型推理的端到端性能;
3.3 Optimization Scheme search / 優化方案搜索
我們提出了上述的優化方案,尤其根據硬件的特點,比如 cache-size, vectorization unit width, memory access pattern 等等,對數據進行布局;
然而手動嘗試所有可能的優化方式既繁瑣又不切實際;
所以 3.2 節 假設通道分離出來的參數比如 NCHW[x]c 中的 x,在整個網絡中不變,雖然在不同 CONVs 選取不同的 x 值會帶來更好的性能;
除此之外,分離出來 output width 的參數比如 reg_n,也需要針對不同的矢量化指令集進行調整;
因此自動的最優方案尋找來進一步提升性能;
我們應該讓領域專家來幫忙構建一個搜索空間(在最短的時間內,針對某種平台設備找到最佳方案);
搜索分為兩步,第一步局部搜索,找到各個計算密集型操作的優化方案,然後是全局搜索,選取組合各個方案以獲得最佳的端到端性能;
在 3.1 節中提出的優化模板,證明了這種方式是可行的;
3.3.1 Local Search / 局部搜索
第一步為每個 computationally-intensive operations / 計算密集型操作(比如 CNN 模型中的 CONVs)找出優化方式;
我們用一個 tuple / 組 :(ic_bn, oc_bn, reg_n, unroll_ker)來代表一個卷積過程,這些參數來代表在不同架構 CPU上進行不同卷積任務;
前兩個參數 ic_bn 和 oc_bn 代表輸入和輸出通道分離出來的參數(比如 NCHW[x]c 中的 x),針對於某種 CPU,和 cache size / 緩存大小 有關;
第三個參數 reg_n 代表 Innder Loop 中要使用的 SIMD 寄存器數目,和 CPU 架構和代數有關;我們也觀察到,在一個線程中使用所有的 SIMD 寄存器往往並不能帶來最佳性能表現;
最後一個參數 unroll_ker 是一個布爾值 ,用來來決定是否展開對卷積核計算的循環(算法 1 中 12 行),因為有時候展開循環會通過減少 branch penaltiles / 分支轉移損失 來提高性能;
局部搜索使用 3.1.1 節提到的 template 來找出這些值的最佳組合方式,來最小化 CONV 執行時間;
按照以下步驟進行局部搜索:
- 定義 ic_bn 和 oc_bn 的候選列表;為了嘗試出所有的可能,我們列出通道數的所有參數;比如,如果通道數是 64,我們選取 [32, 16, 8, 4, 2, 1] 作為備選;
- 定義 reg_n 的候選列表,實際操作中,我們從 [32, 16, 8, 4, 2] 選取 reg_n 的值;
- 定義 unroll_ker 的候選列表:[True, False];
- 遍歷定義的空間來獲得所有組合的執行時間,每個組合運行多次以獲取平均時間;最終會生成一個按照執行時間升序排列的列表;
值得注意的是,我們通過這種配置的方法來設計這樣一個 tuple,意味着我們可以根據需要去修改這個 tuple(比如加減參數,修改值);
根據經驗,在一台機器上進行一次 CNN 模型的局部搜索,需要花費幾個小時,這是可以接收的;
比如在一台 18 核 Intel Skylake 處理器機器上,需要花費 6 個小時來進行 ResNet-50 中 20 個不同 CONV 任務搜索;
除此之外,我們維護了一個數據庫,裏面存儲着每種 CPU 上每種卷積工作量(由特徵圖核卷積核尺寸定義)的結果,以防止在不同模型中重複搜索;
局部搜索針對於每個單獨的操作的優化效果都很好,而且確實是比手動搜索更高效的方法;
然而對每個操作進行局部最優搜索,可能導致並不是全局最優;
比如兩個連續 CONV 操作 conv_0 和 conv_1,如果 conv_0 的 輸出分割因子(oc_bn)和 conv_1 的 輸入分割因子(ic_bn)不同,我們需要進行額外的布局轉換工作;
這個額外的轉換帶來的開銷要大於局部搜索所帶來的性能提高,尤其網絡很大的時候;
換句話說,如果我們在整個網絡中選取一個常量作為分割因子(正如 3.2 節所述),我們會在有些 CONVs 沒有進行優化;
因此,我們接下來會用全局搜索來做權衡;
3.3.2 Global search / 全局搜索
在這一節,我們會將優化搜索拓展到整個計算圖中;
想法是允許每個 CONV 自由的選擇分割因子 x (即 ic_bn 和 oc_bn),並考慮相應的數據布局轉換所帶來的時間開銷;
根據 3.2 節所述,CONVs 之間的操作要麼是 layout-oblivious 要麼是 layout-tolerant,所以它們可以使用 CONV 操作所決定的 x 值;
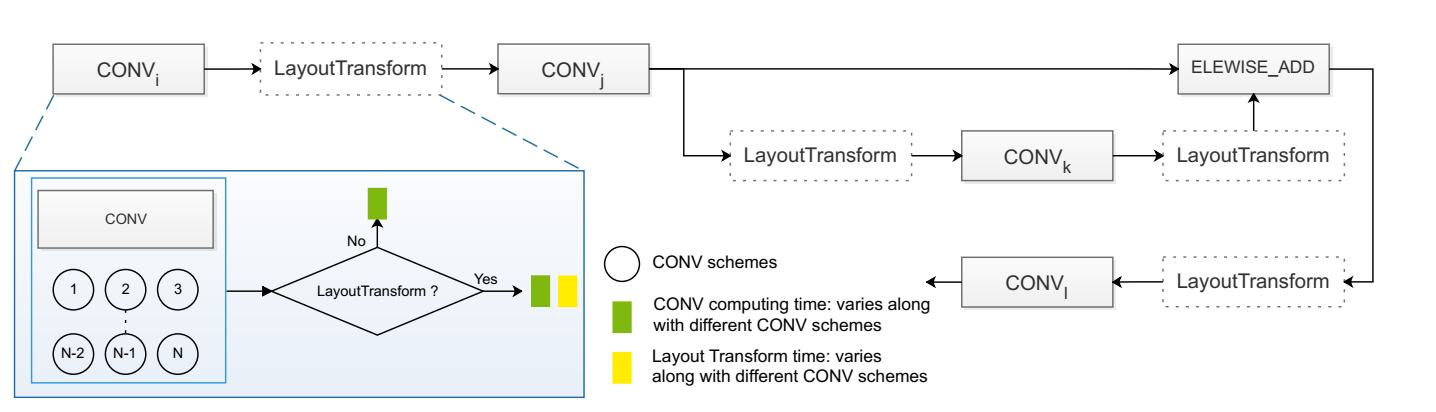
圖 3:CNN 模型推理全局搜索:LayoutTransform 可選,如果,加入 LayoutTransform,帶來的數據轉換額外開銷如黃色塊所示;
我們在以圖 3 中模型舉例來說明我們的想法;從圖中可以看到每個 CONV 有一些候選的方案(由不同的 ic_bn 和 oc_bn 組合指定);
通過局部搜索可以得到每個組合的最短執行時間;
由於 ic_bn 和 oc_bn 的選擇經常小於 10,所以組合總數一般小於 100;
選擇不同的方案會帶來不同的數據轉化開銷(CONVs 之間虛線框表示)或者不需要轉換(如果某個 CONV 的 oc_bn 等於後續 CONV 的 ic_bn);
為了簡化起見,我們在圖中省略了一些不影響全局搜索的操作(比如兩個 CONVs 之間的 ReLu,Batch_Norm);
但是,例如 Elementwis_Add 這種操作不能被省略,因為它需要它的兩個輸入操作數(CONVj 和 CONVk 的 輸出)的格式是一樣的;
也就是說,一個 有着 n 個 CONVs (每個 CONV 由 ki 個可選方案,總數是 k1 x k2 x .. x kn)的 CNN 模型,隨着層數 n 增大,很容易變得很難處理;
幸運的是實際上我們可以使用一個 dynamic programming(DP)algorithm / 動態規划算法 來有效的解決這個問題;
為一個 CONV 選擇方案的時候,只要記住目前的全局最優方案,考慮它自己和它的直接前向連接的 data layout / 數據布局 ,而不需要任何其他前向的 CONV;
算法 2 中介紹了這種方法;
實際上許多 CNN 模型結構很簡單,可以簡化成一個列表(列表中每個 CONV 只有一個前向處理);
這種情況下,一個 CONV 完成之後,可以安全的刪除掉前面處理所產生的中間狀態;
對於更複雜點的結構,比如使用 Elementwise_Add 來將兩個 CONV 的輸出輸入到下一個 CONV 就會很棘手,因為一個 CONV 的 schemes 可能需要保存下來,以後還要使用(比如圖 3 中通過 Elementwise_Add 方式,CONVl 需要 CONVj 的 schemes)
算法 2 全局搜索算法
以拓撲結構將計算圖中節點進行排序;
使用候選方案的執行時間
for CONVi in topological order do
for each canidate scheme CSIj of CONi do > j is the jth scheme of CONVi
t = execution_time(CSIj)
GSIj = MAX // 在方案 j 下初始化 CONVj 的全局優化方案
for each so-far globally optimal scheme GSXk of predecessor x do // k 是 CONVx 的 kth 方案
cur_opt = t + transform_time(k,j) + GSXk
if cur_opt < GSIj then
GSIj = cur_opt
end if
end for
end for
end for
return 最後節點的最短方案
然而,如果模型結構過於複雜,CONV 之間存在很多數據依賴關係,那麼 DP 算法也會變得不好用;
比如,由於很多 concatenation blocks / 級聯塊 的出現,SSD 中目標檢測模型的狀態數可以達到萬億數量級;
這種情況下,我們介紹相似的解決方法來加速搜索;
我們將全局搜索問題,簡化成編譯器領域中,稍加修改的寄存器分配問題;
將寄存器分配問題模型化,每一個 node 有一個候選列表(包含所有可能寄存器選項),每個 edge 和一個 cost matrix / 開銷矩陣 關聯,這個矩陣描述了兩個 node 之間寄存器的可用情況;
和我們全局搜索中類似,每個 CONV 有一系列的備選方案,每個 edge 和 兩個 CONVs 的方案列表,所生成的 layout transformation cost matrix / 布局轉換開銷矩陣 相關聯;
對於別的 non-CONV 的節點,比如 Elementwise_Add,會要求所有的輸入必須是相同格式,我們需要把一個輸入格式進行修改,然後其他的輸入格式都轉換過去;
因此,我們定義 non-CONV 的節點的候選列表定義為和第一個 CONV 的輸入相同,並且將這兩個節點之間的 cost martix 定義為相同,因為對角元素都為0,所以其他元素都無窮大;
由於我們本質上沒有對網絡進行更改,所以模型輸出結果不變;
為了驗證,我們將 NeoCPU 結果和其他結果(圖像分類模型預測精度和目標檢測模型預測準確度)進行比較;
4.1 Overall Performance / 整體性能表現
表 2 中,我們在不同的 CPU 平台上,測試不同優化方式對 15 種主流的 CNN 模型的性能提升影響;
1000 次採樣來獲取平均執行時間,每次進行一張圖像推理(batch_size=1);
總體來說,在不同的 CPU 平台使用不同的模型,NeoCPU 方法的性能表現要比其他方法好(忽略 OpenVINO 中的一些異常結果,NeoCPU 最高可以帶來 11x 性能提升);
和每個模型的最佳基準結果比較,NeoCPU的表現如下:
- 在 Intel Skylake CPU 上得到 0.94-1.15x 性能提升;
- 在 AMD EYPC CPU 上得到 0.92-1.72 性能提升;
- 在 ARM Cortex A72 CPU 上得到 2.05-3.45 性能提升;
對於 Framework-specific / 依賴框架 的方案,MXNet 和 TensorFlow 並不是在 CPU 上進行 CNN 模型推理的最佳選擇;
因為缺少在 graph-level / 圖級別 進行優化(比如靈活數據布局管理)的靈活性;
MXNet 支持 Intel MKL-DNN,所以在 x86 CPU 上面性能不錯;
但是 MXNet 在 ARM 上比 TensorFlow 性能差,因為 Scalability Issue / 擴展性問題(圖 4c 所示);
TensorFlow 在 SSD 模型表現明顯不行,因為 SSD 進行推理的時候要進行 Dynamic Decisions / 動態決策;
相比之下,OpenVINO 中框架無關的方案希望通過移除框架限制來加速性能,然而 OpenVINO 在各個模型中的性能測試結果都不穩定;
儘管一些場景下性能不錯,但是有時候在一些特定的模型很慢(比 NeoCPU 在 AMD CPU 上優化 ResNet-152 慢了 45 倍);
在進行結果分析的時候,我們沒有考慮這些異常情況;
值得注意的是 OpenVINO 測量 SSD 的執行時間時候,沒有把很多操作(比如 multibox detection)時間算進去;
由於 OpenVINO 不是開源的,所以無法進行內部修改來獲取 SSD 模型的真實執行時間;
因為 OpenVINO 依賴於 MKL-DNN(針對於 x86 架構),所以不適用於 ARM CPU;
NeoCPU 方案的性能表現突出,因為基於我們第三章所提出的高性能優化技術;
除此之外,所有的基準優化方式很大程度依賴於第三方庫(MKL-DNN,OpenBlas,Eigen);
NeoCPU 不依賴於這些庫,所以有很大的性能提升空間;
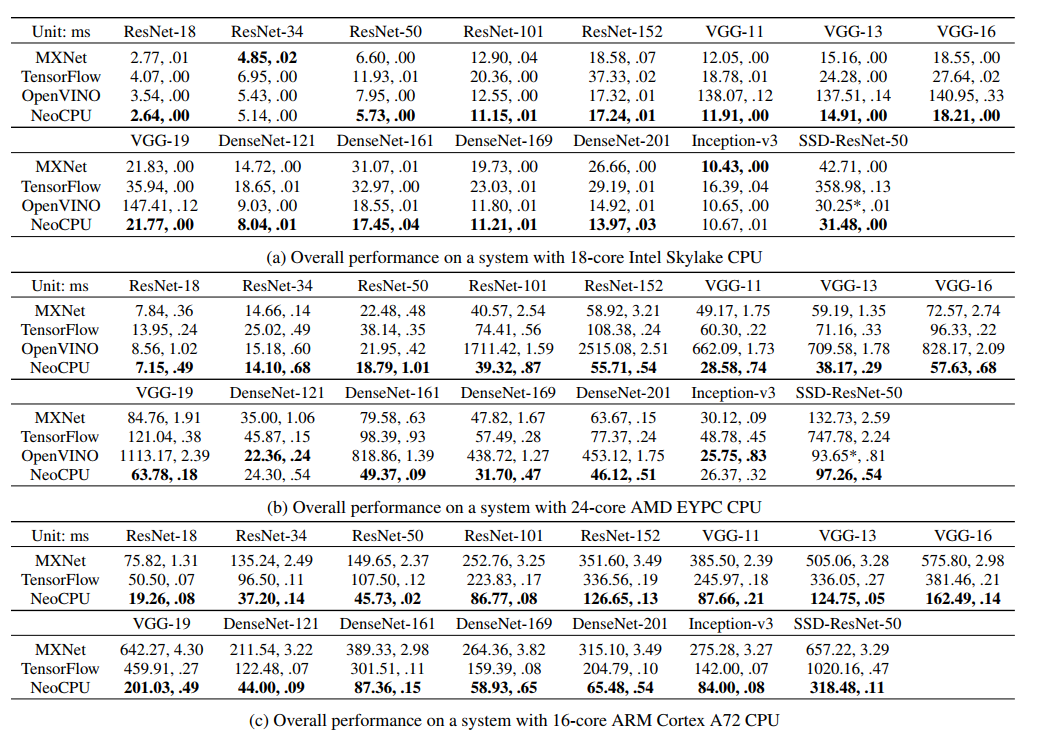
表 2 :NeoCPU 和其他基準方案的對比;每個結果是進行了 1000 次測試的平均執行時間;每種模型的最優方案被 加粗顯示;(OpenVINO 的 SSD 執行時間是不精確的)
4.2 Optimization Implications / 優化意義
這一節我們會將詳細介紹第三節描述的優化方案;
為了方便起見,我們在每一個 network family 分別只選取一個網絡作比較;
相同 network family 的其他網絡優化思路類似;
在 4.2.1 – 4.2.3 節,我們只討論在 Intel CPU 的性能表現(優化效果也適用於 AMD 和 ARM CPU 上);
4.2.1 節介紹 operation-level 優化,4.2.2 和 4.2.3 節介紹了 operation-level and graph-level joint optimization / 聯合優化;
4.2.1 Layout optimization of CONV /
首先,我們比較了表 3 第二行中的 CONV 操作,在有無 organizing the data in a memory access / 內存訪問 和 vectorized instruction utilization 向量化指令利用布局組織數據;
這是 4.1 節中大量使用的 Operation-level 優化,
我們將其複製到一個模板,然後在不更改彙編代碼或者內部代碼的前提下,使用 TVM 調度機制來在不同 CPU 平台上進行 CNN 模型優化;
從表 3 第二行我們可以看到,與默認數據布局(NCHW)比較有着顯著提升;
兩種實現方式都配置正確的矢量化,和線程級別的並行化,
也有 TVM stack 中介紹的基本圖級別優化方法,比如 operation fusion / 操作融合, pre-computing / 預計算,inference simplification / 推理簡化 等等;
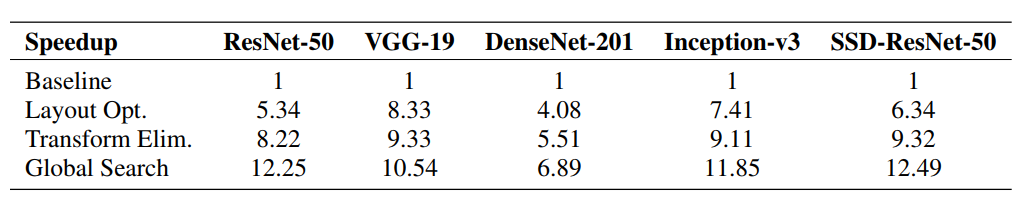
表3:與 NCHW 基準相比我們的優化方式帶來的性能提升;
4.2.2 Layout transformation elimination / 布局轉換評估
其次,我們評估了 3.2 節介紹的,通過消除數據布局轉換開銷帶來的性能提升;
結果如表 3 第三行所示,可以看到減少了布局轉換的開銷,性能提升了 1.1-1.5x;
NeoCPU 使用系統的方法來消除不必要的數據布局轉換,通過推斷全局的數據布局,並僅在需要的時候插入格式轉換節點;
4.2.3 Optimization scheme search / 優化機制搜索
接下來,我們比較我們搜索算法產生的優化機制,和手動篩選結果的性能表現;
根據表 3 中的第三和第四行,我們可以看到 3.3 節中介紹的算法能夠找到數據布局的接近最優組合;
比我們手動找出的結果性能要好 1.1-1.5 倍;
全局搜索加速了 ResNet-50(和它的 variants)獲得了加速,因為網絡結構更加複雜所以有更多優化空間;
作為對比,VGG-19(和它的 variants)加速效果沒那麼好,因為結果比較簡單;
SSD 利用相似算法,獲得了顯著的加速效果;
結果驗證了自動搜索,可以讓我們不需要手動進行調參,還可以獲得更好的性能;
據我們所知,NeoCPU 是唯一種目前可以達到這種程度優化的方案;
4.2.4 Multi-thread parallelization / 多線程並行化
最後,我們用 3.1.2 節提到的線程池(通常在 GCC 編譯器中通過 OpenMP API 實現)實現的多線程,來進行拓展性的測試;
我們對使用了 Intel MKL-DNN,OpenBlas 和 Eigen(所有通過 OpenMP 實現多線程)的 MXNet,TensorFlow 和 OpenVINO 的結果進行對比;
我們通過環境變量來配置 OpenMP,來確保線程的分配(每個線程會在一個互不相干的核心上運行),類似於線程池的操作;
按照一張接一張的順序(batch size=1)處理,一秒內一個模型能夠處理的數目在圖 4 中給出;
為了方便展示,圖 4 按照 CPU 平台劃分成 3 張圖(Intel / AMD / ARM);
圖 4 表明我們的線程池的性能,要比 OpenMP 在 NeoCPU 或者其他方案更好;
OpenMP 啟動關閉線程的開銷要大於我們的線程池,而且拓展性也不好;
此外,我們觀察到,有時候在添加線程時,性能表現會有波動甚至下降;
OpenMP 的性能也有可能根據實現方式不同而不同;
總結來說,我們的評估方法適用於我們的場景,但是針對於不同場景最好有自己定製化的線程池;

圖 4:不同線程數下不同優化方案的處理速度;Standard errors / 標準誤(< 0.4)太小在圖中看不到
5 Related Works / 相關工作
深度學習在我們日常生活中應用越來越廣泛,但是仍然還有很多的工作要做(在不同的硬件平台上,CPU / GPU / FPGA / 加速器 上去進行加速深度學習過程);
如今深度學習框架經常要在不同硬件平台上,利用這些優化的實現方式來運行深度學習訓練和推理;
對於一些對於推理性能有特殊要求(比如要求 低延遲 / low- latency 或者 small-binary-size )的硬件平台,我們也需要對其進行優化工作;
NeoCPU 更加的靈活,高效的把 operation-level 和 graph-level 優化相結合;
儘管本文專註於如何在 CPU 平台上進行優化,但是這些思路也可以應用到其他硬件平台上;
NeoCPU 基於 TVM stack( 啟發於 Halide 的一個端到端的框架),TVM stack 中介紹了如何將一個深度學習網絡轉為 Intermediate Representations (IRs) / 中間文件 ;
也有幾種其他類似的深度學習編譯器比如 TensorFLow XLA,Tensor Comprehensions,Glow 和 DLVM;
然而,這幾種編譯器都沒有類似於我們這種,在 CPU 推理優化過程的研究結果(比如 Glow 僅僅在 CPU 進行單核優化);
我們相信我們提出的這種方案可以整合到這些框架中;
我們利用其他高性能庫中,成熟的方法來優化計算密集型的 CONV 操作;
除了這些庫,對於 convolutions / 卷積操作 和 matrix multiplications / 矩陣乘法 ,在 Intel CPU 上也有一些高度定製的優化;
這些工作大多數關注於單個 operation-level 的優化,根據卷積過程和 CPU 資源來進行微調,而不考慮整個網絡;
這種優化可以在目標 CPU 上最大化卷積的性能,但是拓展到其他平台上做聯合優化就很不方便;
和其他優化不同,我們有一個可以配置的模板來進行優化配置,這樣的話對於不同架構 CPU 就可以進行很靈活的配置,在 operation-level 和 graph-level 進行聯合優化也會變得很容易;
我們利用自動搜索來尋找最佳優化方式;
相似的 auto-tuning 思路在其他地方也被介紹過;
然而他們都關注於對於單個操作,進行性能調整,而我們是對於整個 CNN 模型進行全局優化考慮;
最近我們也在關注在 graph-level 進行 DNN 任務的優化,優化任務犧牲一些局部的優化性能來提高整體的優化性能;
這種非貪婪的想法和我們的思路很相似,也運用在我們的方案中;
我們受啟發於 Register Allocation Problem 中的 PBQP,利用相似算法來對複雜結構模型(比如 SSD)進行全局搜索;
這篇文章利用已有的方案思路,稍加修改然後運用到新的領域;
6 Conlusion / 總結
這篇文章中,我們提出了一種端到端的解決方案,在 CPU 上用來編譯和優化 CNN,來進行高效的模型推理;
實驗表明,在不同種類的 CPU 上(Intel Skylake,AMD EPYC 和 ARM Cortex A72),針對 15 種主流的 CNN 模型中,和其他最先進的方案相比,我們能夠達到 3.45X 性能提升;
未來我們會關注於:
- 拓展其他卷積計算算法,比如 Winograd 和 FFT;
- 支持處理量化(比如 INT8)模型推理;
- 在別的硬件平台(比如在 Nvidia 的 GPU 上和 TensorRT 比較)拓展我們 operation-level 和 graph-level 聯合優化方案;


