在小尺寸人臉檢測上發力的S3FD
1. 前言
人臉檢測領域目前主要的難點集中在小尺寸,模糊人臉,以及遮擋人臉的檢測,這篇 ICCV2017 的 S3FD(全稱:Single Shot Scale-invariant Face Detector)即是在小尺寸人臉檢測上發力。
2. 出發點&貢獻
S3FD 這篇論文的出發點是當人臉尺寸比較小的時候,Anchor-Based 的人臉檢測算法效果下降明顯,因此作者提出了這個不受人臉變化影響的 S3FD 算法。這一算整體上可以看做是基於 SSD 的改進,它的主要貢獻可以概括為:
- 改進檢測網絡並設置更加合理的 Anchor,改進檢測網絡主要是增加
Stride=4的預測層,Anchor 尺寸的設置參考有效感受野,另外不同預測層的 Anchor 間隔採用等比例設置。 - 引入尺度補償的 Anchor 匹配策略增加正樣本 Anchor 的數量,從而提高人臉的召回率。
- 引入
max-out background label降低誤檢。
3. 小尺寸人臉檢測效果不好的原因研究
下面的 Figure1 展示了論文對 Anchor-Based 的人臉檢測算法在小人臉檢測中效果下降明顯的原因分析。
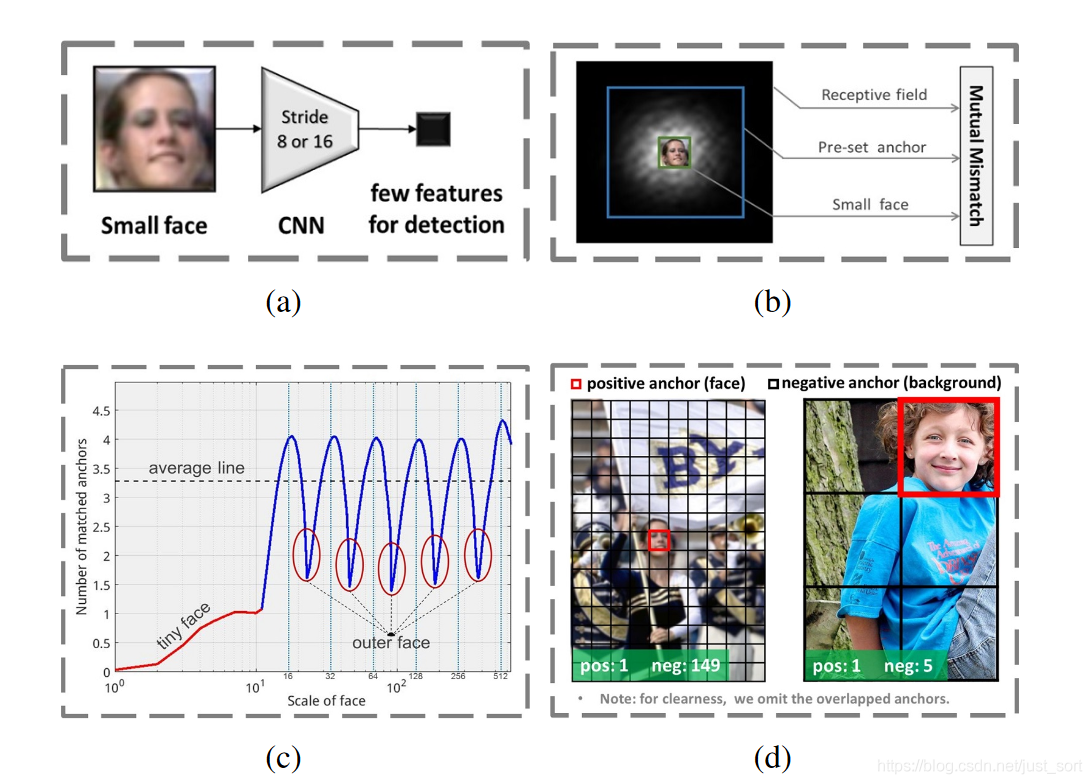
Figure1(a)中展示的是網絡結構本身設計的問題。了解過 SSD 的同學知道在網絡結構中有多個特徵層被用於檢測目標,這些特徵層中stride最小的是8,這樣原圖中8\times 8大小的區域在該預測層中就僅有 1 個像素點,這對小人臉的檢測是非常不利的,因為有效的特徵太少了。同樣,對於 Faster-RCNN 來講,用於檢測目標的特徵層的stride是16,這樣用於人臉檢測的有效特徵範圍就更小,這對小臉檢測是致命打擊。Figure1(b)中展示了 Anchor 的尺寸,感受野和人臉的尺寸不匹配的問題。Figure1(c)中展示了由於一般設置的 Anchor 尺寸都是離散的,例如[16,32,64,128,256,512], 而人臉的尺寸是連續的,因此當人臉的尺寸在設定的 Anchor 值之間時可以用於檢測的 Anchor 數量就會很少,如圖中的紅色圓圈部分所示,這樣就會導致人臉檢測的召回率低。Figure1(d)指出為了提高小人臉的檢測召回率,很多檢測算法都會通過設置較多的小尺寸 Anchor 實現,這樣容易導致較多的小尺寸負樣本 Anchor,最終導致誤檢率的增加。這裡兩張圖的分辨率是一樣的,左圖中的人臉區域較小,因此主要通過淺層特徵來進行檢測,因此這裡 Anchor 尺寸設置較小,而右圖中的人臉區域較大,因此主要是通過高層特徵進行檢測,此時 Anchor 尺寸設置較大。可以看出左圖中標籤為背景的 Anchor 數量遠遠多於標籤為目標的 Anchor,而在右圖中數量比例還是相對較均衡的。
4. S3FD 原理
論文針對第三節的問題進行了分析並提出了解決方案,也就有了這篇 S3FD。
首先針對FIgure1(a),(b)的問題,論文對檢測網絡的設計以及 Anchor 的鋪設做了改進,提出了不受人臉尺寸影響的檢測網絡,改進的主要內容包括:
- 預測層的最小
stride降低到4(具體而言預測層的stride範圍為4到128,一共6個預測層),這樣就保證了小人臉在淺層進行檢測時能夠有足夠的特徵信息。 - Anchor 的尺寸根據每個預測層的有效感受野和等比例間隔原理進行設置,設置為16到512,前者保證了每個預測層的 Anchor 和有效感受野大小匹配,後者保證了不同預測層的 Anchor 再輸入圖像中的密度基本類似。
下面的 Figure3 展示了 Anchor 尺寸和數量設置的依據。

-
Figure3(a)展示了有效感受野effective receptive field和理論感受野theoretical receptive field的區別,其中整個(a)代表的就是理論感受野,一般都是矩形,而(a)中的白色點狀區域就是有效感受野。這一點可以看我們更詳細的文章:目標檢測和感受野的總結和想法 -
Figure3(b)以預測層conv3_3(stride=4)為例介紹理論感受野、有效感受野和 Anchor 尺寸的關係。首先黑色點組成的方形框就是理論感受野,對於conv3_3預測層來說是48\times 48,而有效感受野是藍色點組成的圓形框,而紅色實線組成的方形框是該預測層設置的 Anchor,尺寸是16\times 16,可以看到這裡 Anchor 的尺寸和有效感受野是匹配的。 -
Figure3(c)是關於 Anchor 的等比例間隔設置。假設n是 Anchor 的尺寸,那麼將 Anchor 的間隔設置為n/4。例如對於stride=4的conv3_3預測層而言,Anchor 的尺寸為16\times 16,那麼相當於在輸入圖像中每隔4個像素點就有一個16\times 16大小的 Anchor。可以看出這部分和 SSD 中關於 Anchor 尺寸的設置是類似的,只是相同 Stride 層的 Anchor 數量比 SSD 少,因為這裡設置的 Anchor 寬高比為1:1,因為人臉一般是正方形的,另外 SSD 是對特徵圖每個像素點都設置 Anchor。
下面的 Table1 展示了預測層的stride,anchor尺寸和感受野之間的關係。
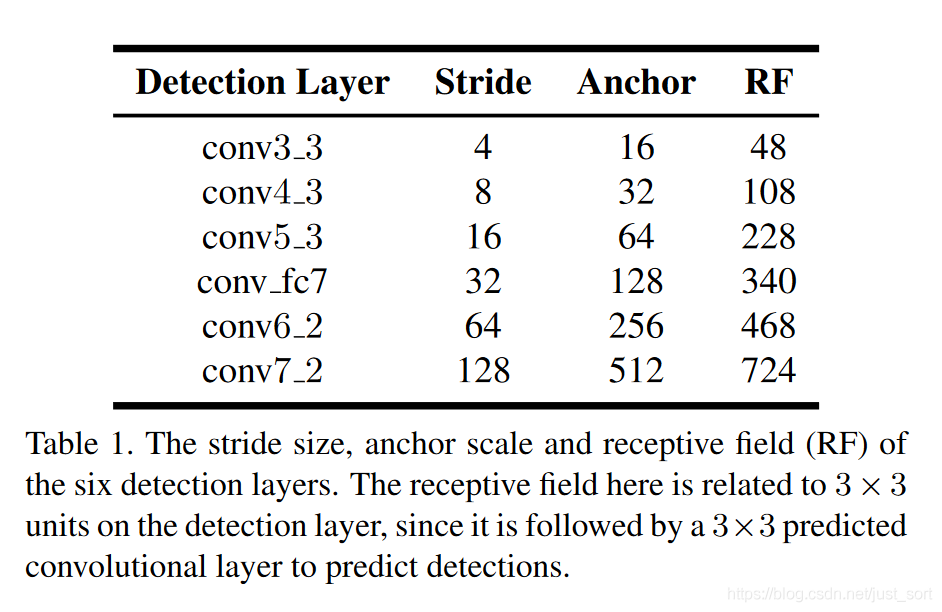
S3FD 的 Anchor 尺寸設置和 SSD 最主要的區別在於 S3FD 中的 Anchor 大小是只和stride相關的,而 SSD 的 Anchor 大小不僅和stride有關,還和輸入大小有關。
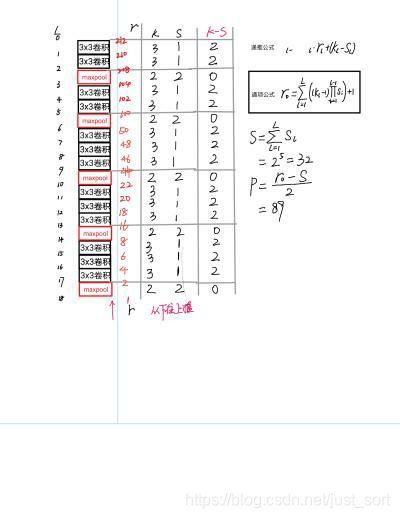
這裡以conv3_3為例子,來手算一下理論感受野,注意這裡說的理論感受野是基於預測層計算的,比如第一行的conv3_3,是指在conv3_3後接的預測層的感受野,不是conv3_3的感受野。
conv3_3的預測層採用的是3\times 3且步長為1的卷積,所以預測層中的一個點映射到預測層的輸入就是3\times 3的區域,預測層的輸入是conv3_3的輸出,所以conv3_3輸出3\times 3區域映射到conv3_3的輸入就是5\times 5的區域,conv3_3的輸入又是conv3_2的輸出,因此conv3_2輸出的5\times 5區域映射到conv3_2的輸入就是7\times 7區域,conv3_2的輸入是conv3_1的輸出,因此conv3_1輸出的7\times 7區域映射到conv3_1的輸入就是9\times 9的區域,conv3_1的輸入是pool2的輸出,因此pool2輸出的9\times 9區域映射到pool2的輸入就是18\times 18的區域,然後映射到conv2_2的輸入是20\times 20的區域,映射到conv2_1的輸入是22\times 22的區域,映射到pool1的輸入是44\times 44的區域,映射到conv1_2的輸入是46\times 46的區域,映射到conv1_1的輸入是48\times 48的區域,因為conv1_1的輸入就是輸入圖像,所以conv3_3預測層的感受野就是48,這個層就計算完了,其它層同理,注意這裡計算的方法是從網絡頂端算到底端,下面用一張 pprp 的圖來看一下整個 VGG16 各層的感受野。
接下來的是針對Figure1(c)中的問題,論文提出了尺度補償的 Anchor 匹配策略。這部分主要分兩步,第一步和常規確定 Anchor 的正負標籤類似,只不過將 IOU 閾值從0.5降到0.35,這樣可以保證每個目標有足夠的 Anchor 來檢測,這樣相當於間接解決了原本處於不同 Anchor 尺寸之間的人臉的可用 Anchor 數量少的問題。經過這一步之後,仍然會有較多的小人臉沒有足夠的正樣本 Anchor 來檢測,因此第二部的目的就是提高小人臉的正樣本 Anchor 數量,具體而言是對所有和 Ground Truth 的 IOU 大於 0.1 的 Anchor 做排序,選擇前 N 個 Anchor 作為正樣本,這個 N 是第一步的 Anchor 數量均值。
最後獲得的 Anchor 尺寸和人臉尺寸的匹配數量曲線如Figure4(a)所示,相比Figure1(c)相比有較大提升。雖然降低 IOU 閾值能夠提高人臉的召回率,但同時也會帶來一些誤檢,之所以採用這種方式,可能時因為召回率的增加遠遠大於誤檢率並且後面還有減少誤檢的操作。
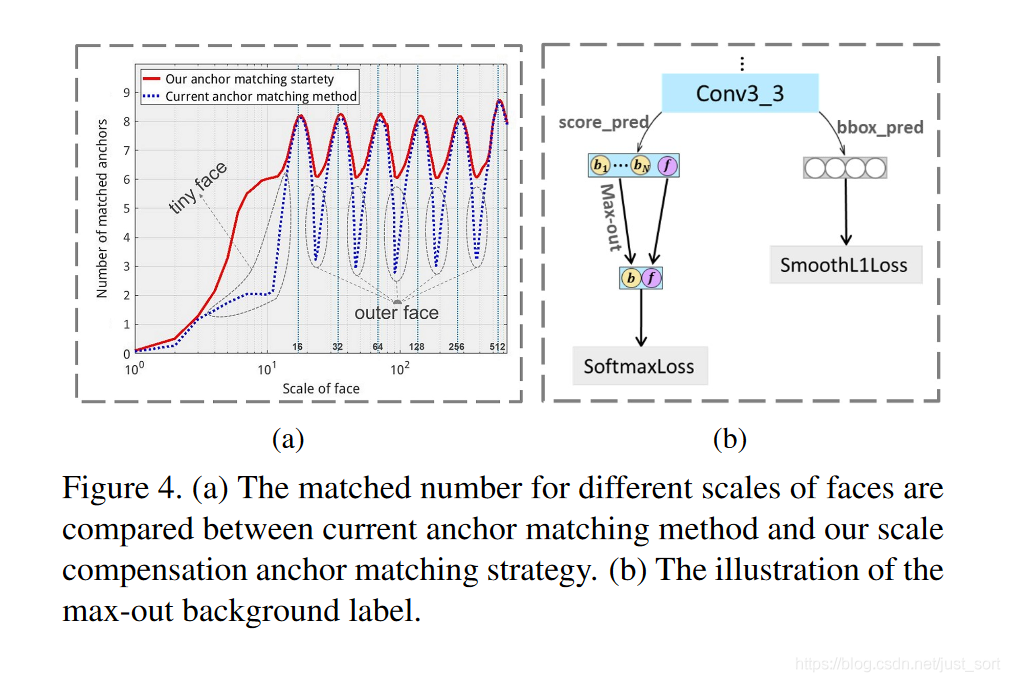
最後針對Figure1(d)的問題,作者提出了針對stride=4的預測層(conv3_3)的max-out background label操作,從而減少誤檢。具體如Figure4(b)所示,左邊支路是分類支路,右邊支路是回歸支路。左邊支路中一共預測N_m個背景概率和一個目標概率,選擇N_m個背景概率中最高的概率作為最終的背景概率。這部分其實就相當於集成了N_m個分類器,有效削弱了負樣本的預測概率,從而降低誤檢率,這種做法在目前不平衡的圖像分類任務中也比較常用。
對 max-out background label 一個直觀的解釋就是對於每一個小尺寸 anchor,進行 N 次人臉和背景分類,選擇其中某個背景 Acore 最高的一個作為該 Anchor 的 score。 其實就是對 Anchor 進行多次預測,然後取其最大背景概率結果,以此降低誤檢為人臉的 anchor 數量,從而降低假陽性率。
5. S3FD 網絡結構
最後,S3FD 的網絡結構如 Figure2 所示:
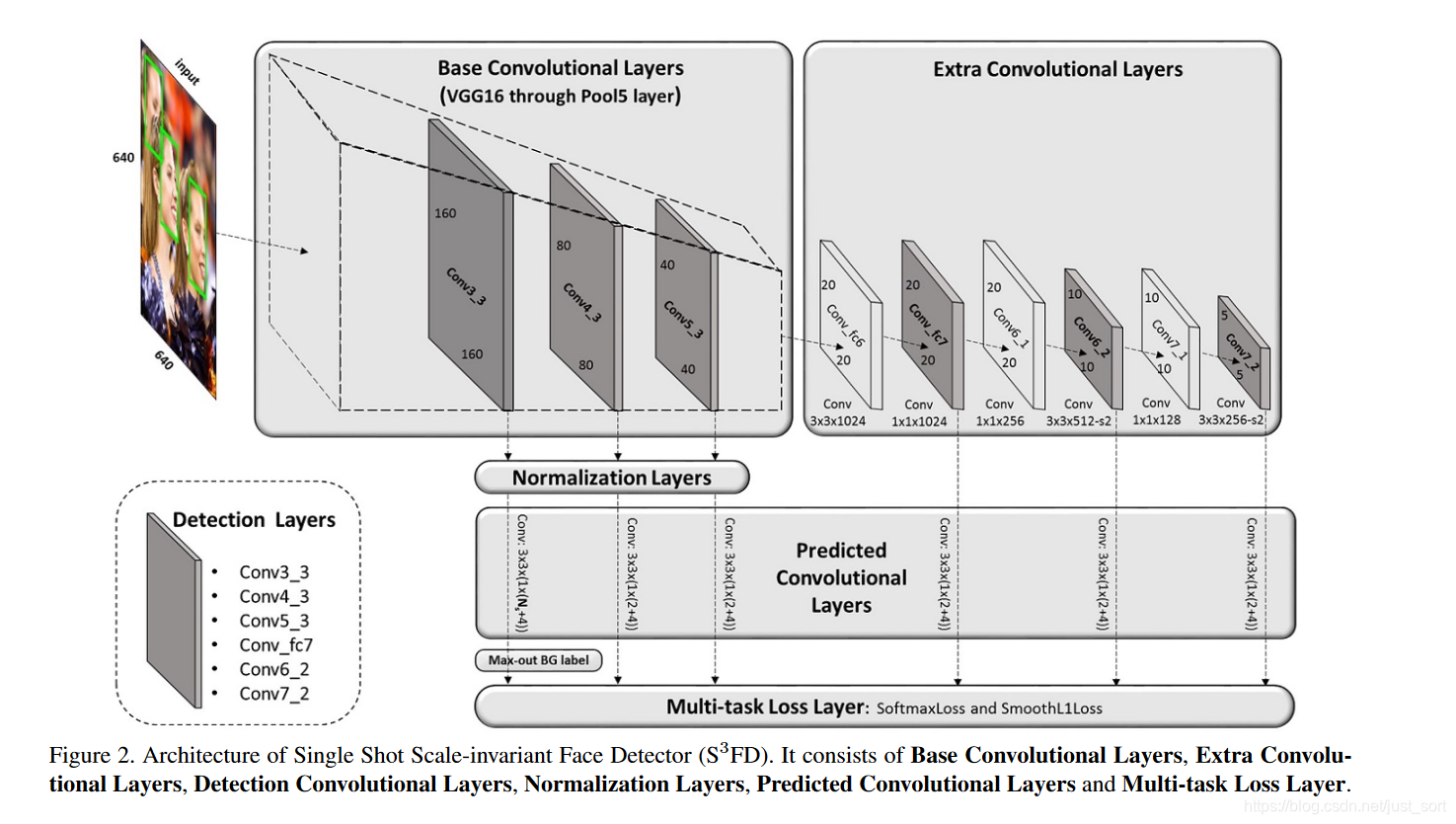
可以看到它和 SSD 網絡結構差不多,不過預測層(predicted convolutional layers)部分和 SSD 的區別在於:
- 預測層整體前移了,也就是
stride=4到stride=128共6個預測層。 stride=4的預測層通道數和其他stride的預測層通道數不同,stride=4的預測層通道數是1\times (Ns+4),其它stride的預測層通道數是1 \times(2+4),這裡的2其實也可以用Ns表示,不過對其它stride的預測層來說Ns為2,表示1個前景(人臉)和1個背景(非人臉)共2個類別。而對於stride=4的預測層,N_s=N_m+1,其中1表示前景(人臉),N_m表示 max-out background label 數量。
另外,網絡的輸入大小為640\times 640。
6. 模型訓練
6.1 數據增強方法
模型是在 WIDER FACE 的 12880 張人臉數據上進行訓練的。其數據增強方法如下:
- 顏色擾動。
- 隨機裁剪:對小尺寸人臉放大,隨機裁剪 5 塊,最大的為原圖上裁剪,其他 4 張為原圖短邊縮放至原圖[0.3,1]的圖像上裁剪得到。
- 裁剪圖像縮放為640\times 640後,並以 0.5 的概率隨機左右翻轉。
6.2 損失函數
損失函數包括兩部分,一部分為 Anchor 是否為人臉的分類損失函數,還有一部分是 Anchor 為人臉的檢測框坐標修正值的回歸損失函數。最後得到總損失函數如下所示:
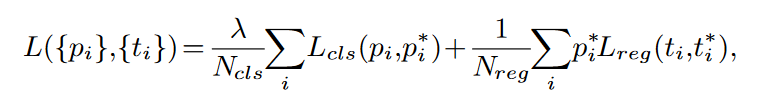
其中,i表示 Anchor 的索引,而p_i表示 Anchor 是人臉的概率,p_i^*為 ground-truth,即實際情況當該 anchor 為人臉時,其值為 1,而不為人臉時,其值為 0;t_i為預測的 4 個檢測框坐標修正值向量,t_i^*為檢測框實際坐標。分類損失採用 softmax 損失函數,回歸損失採用 smooth-L1 損失函數。p_i^*L_{reg}表示僅對正樣本的 anchor 計算回歸損失。N_{cls}和N_{reg}分別表示分類時正負 anchor 的數量和回歸的正 Anchor 數量,\lambda表示平衡參數,用於平衡分類損失和回歸損失。
6.3 難樣例挖掘
經過 Anchor 匹配過程後,會存在嚴重的正負樣本不平衡的問題,為了模型訓練時穩定及更快收斂。對於負樣本,選擇 loss 值逆序排序的 top N ,使得正負樣本比例為 3:1,並且設定N_m=3,\lambda=4以平衡分類和回歸損失。
7. 實驗結果
下面的 Table3 展示了 S3FD 的消融實驗結果,Baseline 是 Faster RCNN 和 SSD。S3FD(F)表示只改進檢測網絡和 Anchor 設置,S3FD(F+S)表示改進檢測網絡、Anchor 設置和尺度補償的 Anchor 匹配策略,S3FD(F+S+M)是最終的算法。
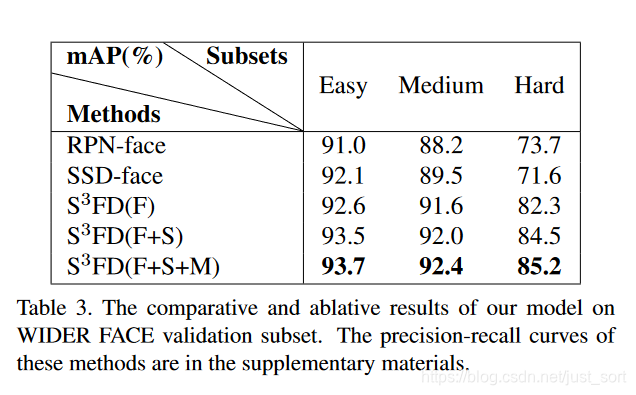
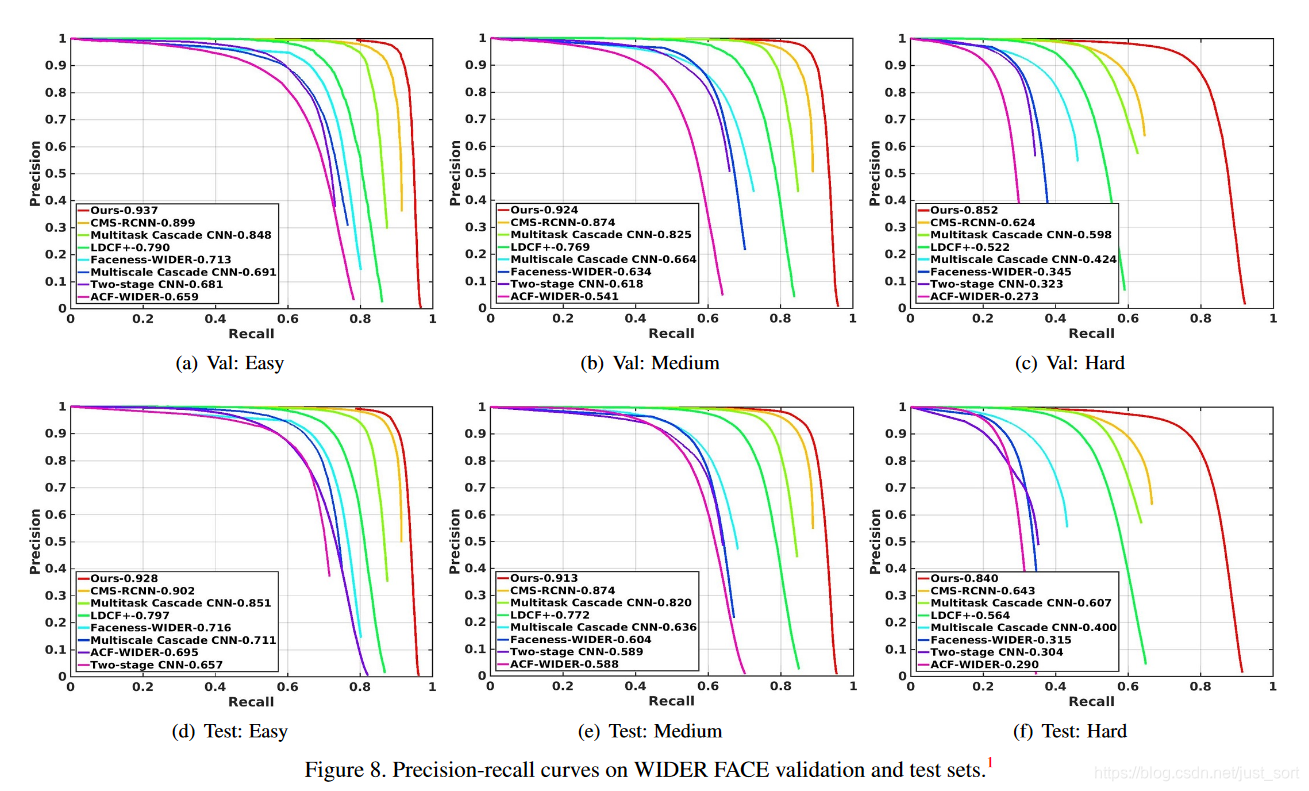
Figure8 是 S3FD 和其它人臉檢測算法在 WIDER FACE 數據集上的對比。
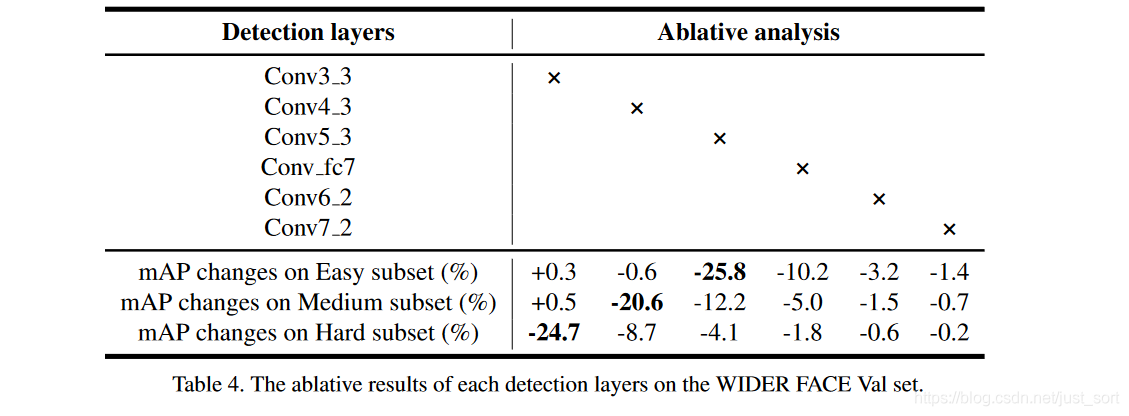
下面的 Table4 展示了關於選擇不同預測層對最終模型效果(mAP 值)的影響。
8. 結論
這篇論文在小尺寸人臉檢測上發力,提出了一些非常有用的 Trick 大大提升了在小尺寸人臉上的召回率以及效果,我覺得
9. 參考
- 論文原文://arxiv.org/pdf/1708.05237.pdf
- 源碼://github.com/sfzhang15/SFD
- //blog.csdn.net/u014380165/article/details/83477516
歡迎關注 GiantPandaCV, 在這裡你將看到獨家的深度學習分享,堅持原創,每天分享我們學習到的新鮮知識。( • ̀ ω•́ )✧
有對文章相關的問題,或者想要加入交流群,歡迎添加 BBuf 微信:


