帶你走進神一樣的Elasticsearch索引機制
- 2020 年 4 月 20 日
- 筆記
- elasticsearch, 索引
更多精彩內容請看我的個人博客
前言
相比於大多數人熟悉的MySQL數據庫的索引,Elasticsearch的索引機制是完全不同於MySQL的B+Tree結構。索引會被壓縮放入內存用於加速搜索過程,這一點在效率上是完爆MySQL數據庫的。但是Elasticsearch會對全部text字段進行索引,必然會消耗巨大的內存,為此Elasticsearch針對索引進行了深度的優化。在保證執行效率的同時,盡量縮減內存空間的佔用。這篇文章就深度解析了Elasticsearch索引原理,揭開搜索的神秘面紗。
簡介
Elasticsearch是一個基於Lucene庫的開源搜索引擎,它提供分佈式的實時文件存儲和搜索,可擴展性好,並且支持通過HTTP網絡接口交互,數據以JSON格式展示。
Elasticsearch因為其極快的搜索和聚合速度通常被應用在各種搜索應用中,比如在自己的app裏面加一個搜索框或者分析實時日誌(ELK系統)。
Elasticsearch會對所有輸入的文本進行處理,建立索引放入內存中,從而提高搜索效率。在這一點上ES要優於MySQL的B+樹的結構,MySQL需要將索引放入磁盤,每次讀取需要先從磁盤讀取索引然後尋找對應的數據節點,但是ES能夠直接在內存中就找到目標文檔對應的大致位置,最大化提高效率。並且在進行組合查詢的時候MySQL的劣勢更加明顯,它不支持複雜的組合查詢比如聚合操作,即使要組合查詢也要事先建好索引,但是ES就可以完成這種複雜的操作,默認每個字段都是有索引的,在查詢的時候可以各種互相組合。
為了省事,以下統一用ES來代替Elasticsearch,其實我們在公司裏面也基本都說ES,全稱比較難讀。還有一點,因為ES使用了Lucene的庫,下面說的很多優化思路都是Lucene裏面的,但是為了講解方便,我就用ES來代替Lucene。
索引
首先需要申明的是在ES中索引的概念和MySQL裏面的概念不太一樣,這裡列出一下ES和MySQL的對應的概念,方便大家理解。
| MySQL | ES |
|---|---|
| 庫(database) | 索引(index) |
| 表(table) | 類型(type) |
| 行(row) | 文檔(doc) |
| 列(column) | 字段(field) |
在ES中每個字段都是被索引的,所以不會像MySQL中那樣需要對字段進行手動的建立索引。
ES在建立索引的時候採用了一種叫做倒排索引的機制,保證每次在搜索關鍵詞的時候能夠快速定位到這個關鍵詞所屬的文檔。
Inverted Index
比如有三句話在數據庫中:
- Winter is coming
- Ours is fury
- Ths choice is yours
如果沒有倒排索引(Inverted Index),想要去找其中的choice,需要遍歷整個文檔,才能找到對應的文檔的id,這樣做效率是十分低的,所以為了提高效率,我們就給輸入的所有數據的都建立索引,並且把這樣的索引和對應的文檔建立一個關聯關係,相當於一個詞典。當我們在尋找choice的時候就可以直接像查字典一樣,直接找到所有包含這個數據的文檔的id,然後找到數據。
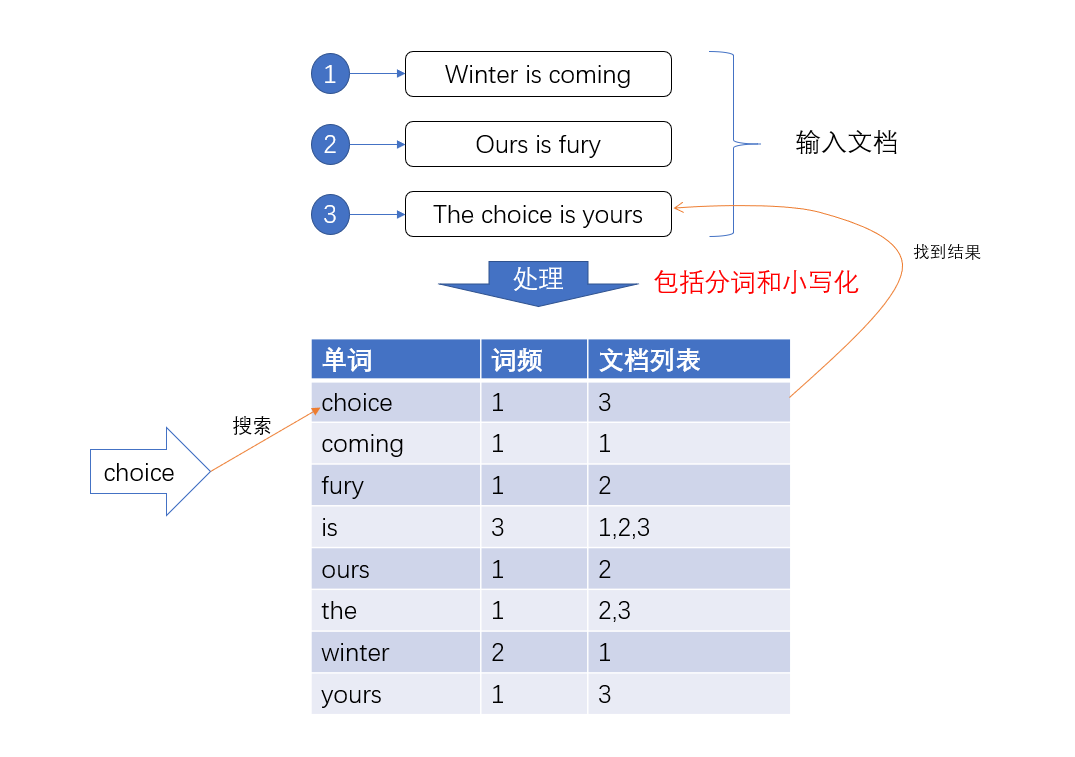
Lucene在對文檔建立索引的時候,會給詞典的所有的元素排好序,在搜索的時候直接根據二分查找的方法進行篩選就能夠快速找到數據。不過是不是感覺有點眼熟,這不就是MySQL的索引方式的,直接用B+樹建立索引詞典指向被索引的文檔。
ES做的要更深一點,ES希望把這個詞典「搬進」內存,直接從內存讀取數據不就比從磁盤讀數據要快很多嗎!問題在於對於海量的數據,索引的空間消耗十分巨大,直接搬進來肯定不合適,所以需要進一步的處理,建立詞典索引(term index)。通過詞典索引可以直接找到搜索詞在詞典中的大致位置,然後從磁盤中取出詞典數據再進行查找。所以大致的結構圖就變成了這樣:
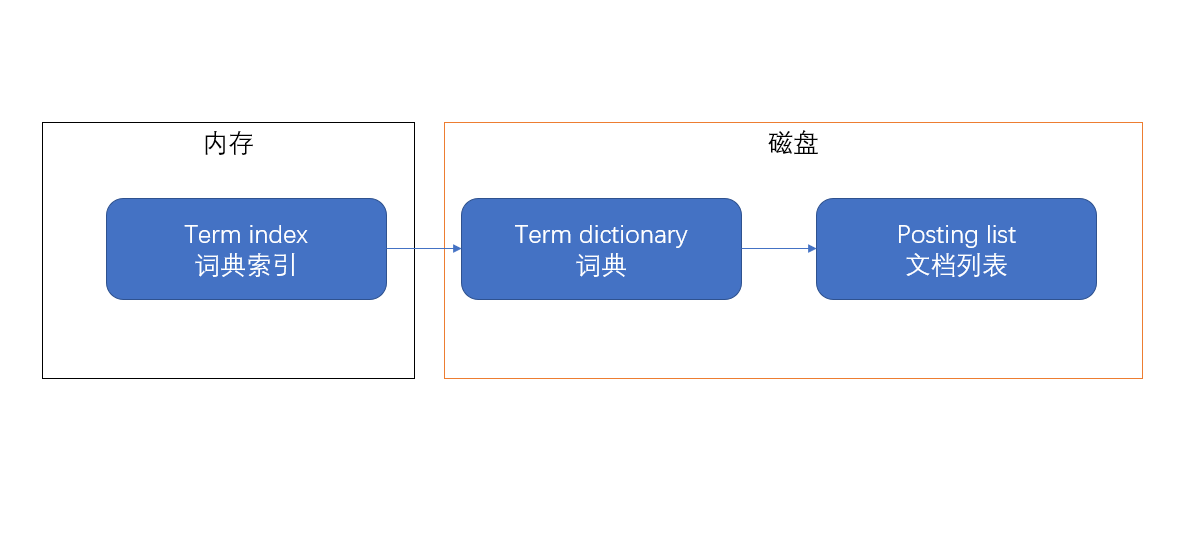
ES通過有限狀態轉化器,把term dictionary變成了term index,放進了內存,所以這個term index到底長什麼樣呢?
Finite State Transducers
有限狀態轉換器(Finite State Transducers)相當於是一個Trie前綴樹,可以直接根據前綴就找到對應的term在詞典中的位置。
比如我們現在有已經排序好的單詞mop、moth、pop、star、stop和top以及他們的順序編號0..5,可以生成一個下面的狀態轉換圖
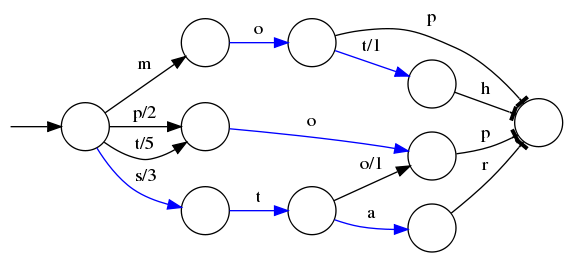
當遍歷上面的每一條邊的時候,都會加上這條邊的輸出,比如當輸入是stop的時候會經過s/3和o/1,相加得到的排序的順序是4;而對於mop,得到的排序的結果是0
但是這個樹並不會包含所有的term,而是很多term的前綴,通過這些前綴快速定位到這個前綴所屬的磁盤的block,再從這個block去找文檔列表。為了壓縮詞典的空間,實際上每個block都只會保存block內不同的部分,比如mop和moth在同一個以mo開頭的block,那麼在對應的詞典裏面只會保存p和th,這樣空間利用率提高了一倍。
使用有限狀態轉換器在內存消耗上面要比遠比SortedMap要少,但是在查詢的時候需要更多的CPU資源。維基百科的索引就是使用的FST,只使用了69MB的空間,花了大約8秒鐘,就為接近一千萬個詞條建立了索引,使用的堆空間不到256MB。
順帶提一句,在ES中有一種查詢叫模糊查詢(fuzzy query),根據搜索詞和字段之間的編輯距離來判斷是否匹配。在ES4.0之前,模糊查詢會先讓檢索詞和所有的term計算編輯距離篩選出所有編輯距離內的字段;在ES4.0之後,採用了由Robert開發的,直接通過有限狀態轉換器就可以搜索指定編輯距離內的單詞的方法,將模糊查詢的效率提高了超過100倍。
現在已經把詞典壓縮成了詞條索引,尺寸已經足夠小到放入內存,通過索引能夠快速找到文檔列表。現在又有另外一個問題,把所有的文檔的id放入磁盤中會不會佔用了太多空間?如果有一億個文檔,每個文檔有10個字段,為了保存這個posting list就需要消耗十億個integer的空間,磁盤空間的消耗也是巨大的,ES採用了一個更加巧妙的方式來保存所有的id。
Posting Lists
所謂的posting list,就是所有包含特定term文檔的id的集合,需要從詞典映射到這個集合。由於整型數字integer可以被高效壓縮的特質,integer是最適合放在posting list作為文檔的唯一標識的,ES會對這些存入的文檔進行處理,轉化成一個唯一的整型id
在存儲數據的時候,在每一個shard裏面,ES會將數據存入不同的segment,這是一個比shard更小的分片單位,這些segment會定期合併。在每一個segment裏面都會保存最多\(2^{31}\)個文檔,每個文檔被分配一個唯一的id,從\(0\)到\(2^{31}-1\)。
Frame of Reference
在進行查詢的時候經常會進行組合查詢,比如查詢同時包含choice和the的文檔,那麼就需要分別查出包含這兩個單詞的文檔的id,然後取這兩個id列表的交集;如果是查包含choice或者the的文檔,那麼就需要分別查出posting list然後取並集。為了能夠高效的進行交集和並集的操作,posting list裏面的id都是有序的。同時為了減小存儲空間,所有的id都會進行delta編碼(delta-encoding,我覺得可以翻譯成增量編碼)
比如現在有id列表[73, 300, 302, 332, 343, 372],轉化成每一個id相對於前一個id的增量值(第一個id的前一個id默認是0,增量就是它自己)列表是[73, 227, 2, 30, 11, 29]。在這個新的列表裏面,所有的id都是小於255的,所以每個id只需要一個位元組存儲。
實際上ES會做的更加精細,它會把所有的文檔分成很多個block,每個block正好包含256個文檔,然後單獨對每個文檔進行增量編碼,計算出存儲這個block裏面所有文檔最多需要多少位來保存每個id,並且把這個位數作為頭信息(header)放在每個block 的前面。這個技術叫Frame of Reference,我翻譯成索引幀。
比如對上面的數據進行壓縮(假設每個block只有3個文件而不是256),壓縮過程如下
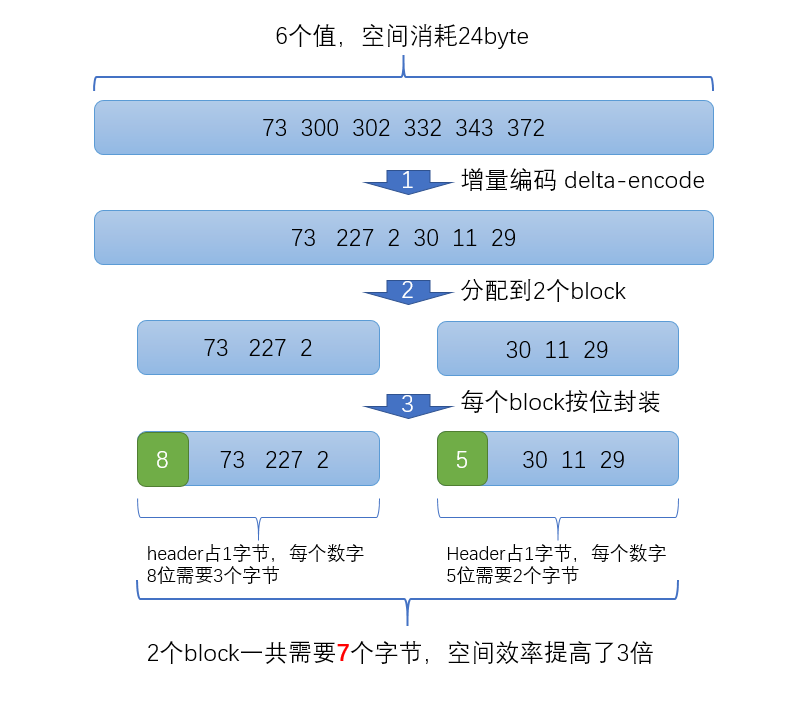
在返回結果的時候,其實也並不需要把所有的數據直接解壓然後一股腦全部返回,可以直接返回一個迭代器iterator,直接通過迭代器的next方法逐一取出壓縮的id,這樣也可以極大的節省計算和內存開銷。
通過以上的方式可以極大的節省posting list的空間消耗,提高查詢性能。不過ES為了提高filter過濾器查詢的性能,還做了更多的工作,那就是緩存。
Roaring Bitmaps
ES會緩存頻率比較高的filter查詢,其中的原理也比較簡單,即生成(fitler, segment)和id列表的映射,但是和倒排索引不同,我們只把常用的filter緩存下來而倒排索引是保存所有的,並且filter緩存應該足夠快,不然直接查詢不就可以了。ES直接把緩存的filter放到內存裏面,映射的posting list放入磁盤中。
ES在filter緩存使用的壓縮方式和倒排索引的壓縮方式並不相同,filter緩存使用了roaring bitmap的數據結構,在查詢的時候相對於上面的Frame of Reference方式CPU消耗要小,查詢效率更高,代價就是需要的存儲空間(磁盤)更多。
Roaring Bitmap是由int數組和bitmap這兩個數據結構改良過的成果——int數組速度快但是空間消耗大,bitmap相對來說空間消耗小但是不管包含多少文檔都需要12.5MB的空間,即使只有一個文件也要12.5MB的空間,這樣實在不划算,所以權衡之後就有了下面的Roaring Bitmap。
- Roaring Bitmap首先會根據每個id的高16位分配id到對應的block裏面,比如第一個block裏面id應該都是在0到65535之間,第二個block的id在65536和131071之間
- 對於每一個block裏面的數據,根據id數量分成兩類
- 如果數量小於4096,就是用short數組保存
- 數量大於等於4096,就使用bitmap保存
在每一個block裏面,一個數字實際上只需要2個位元組來保存就行了,因為高16位在這個block裏面都是相同的,高16位就是block的id,block id和文檔的id都用short保存。
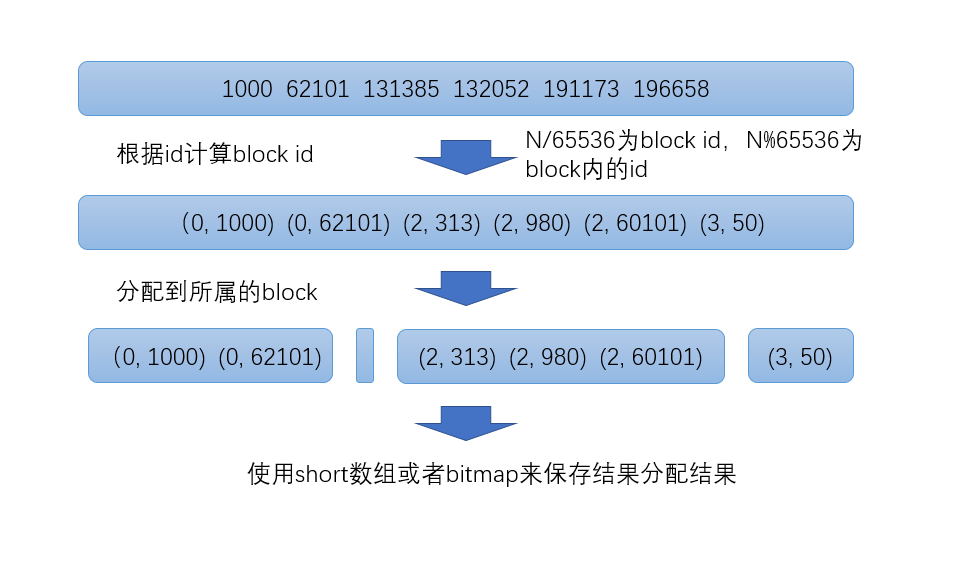
至於4096這個分界線,因為當數量小於4096的時候,如果用bitmap就需要8kB的空間,而使用2個位元組的數組空間消耗就要少一點。比如只有2048個值,每個值2位元組,一共只需要4kB就能保存,但是bitmap需要8kB。
總結
ES為了提高搜索效率、優化存儲空間做了很多工作。
為了能夠快速定位到目標文檔,ES使用倒排索引技術來優化搜索速度,雖然空間消耗比較大,但是搜索性能提高十分顯著。
由於索引數量巨大,ES無法直接把全部索引放入內存,轉而建立詞典索引,構建有限狀態轉換器(FST)放入內存,進一步提高搜索效率。
數據文檔的id在詞典內的空間消耗也是巨大的,ES使用了索引幀(Frame of Reference)技術壓縮posting list,帶來的壓縮效果十分明顯。
ES的filter語句採用了Roaring Bitmap技術來緩存搜索結果,保證高頻filter查詢速度的同時降低存儲空間消耗。
參考
MySQL和Lucene(Elasticsearch)索引對比分析
Elasticsearch from the Bottom Up, Part 1
時間序列數據庫的秘密 (2)——索引
Frame of Reference and Roaring Bitmaps
Using Finite State Transducers in Lucene
Lucene’s FuzzyQuery is 100 times faster in 4.0

