分享幾種論文寫作神器,提高你的寫作效率
- 2020 年 4 月 20 日
- AI
本人在寫論文的時候,用到了很多工具,可用說這些工具可以大大提高寫論文的效率,本文分享下我常用的論文神器。
本文介紹以下幾種工具:
- 論文管理神器Zotero
- OCR神器(公式識別等)
- Latex工具
- 語法校對工具
- 論文繪圖工具
論文管理神器Zotero
一、Zotero簡介
Zotero作為一款協助科研工作者收集、管理以及引用研究資源的免費軟件,如今已被廣泛使用。此篇使用說明主要分享引用研究資源功能,其中研究資源可以包括期刊、書籍等各類文獻和網頁、圖片等。歡迎所有共同學習使用的朋友提供批評意見或補充使用經驗。
下載地址://www.zotero.org/download/
ubuntu下安裝zotero:
sudo apt-add-repository ppa:smathot/cogscinl
# Say yes/press enter to accept any requests.
$ sudo apt-get update
# Wait for it to complete, then:
$ sudo apt-get install zotero-standalone二、新建分類
步驟:我的文庫→右鍵→新建分類→輸入名稱→鼠標右鍵我的文庫→出現新建文件夾

三、英文文獻信息導入
步驟(非常簡單):
在新建目錄下→鼠標拖入英文文獻→右鍵重新抓取PDF文件的元數據→獲取文獻基本信息
備註:一些時間久遠的英文論文也不能直接抓取數據,具體信息抓取方法參照第四部分中文文獻的信息導入。



四、中文文獻信息導入
步驟(稍複雜):
1. 在Text目錄下→鼠標拖入中文文獻
2. 在百度學術搜索文獻→點擊批量引用→導出到BibTex→下載


3. 用記事本打開下載好的.bib文件→複製全部內容

4. Zotero界面文件一欄→選擇從剪貼板導入

5. 將PDF文件鼠標拖至剛導入文件成為其子文件→完成中文文獻的信息抓取
五、插入文獻
步驟:
1. Word中點擊菜單欄中的「Zotero」工具欄→選擇要引用的方式(默認選項沒有的引用方式參見第六部分)


2. 鼠標光標置於要插入上角標處(即下圖2處)→點擊下圖1處所示圖標→2處出現紅框內文字,3處出現Zotero快速格式化引文→點擊快速格式化引文左邊圖標選擇經典視圖

3. 出現「添加/編輯引文」對話框→選擇要引入的文獻,點擊OK
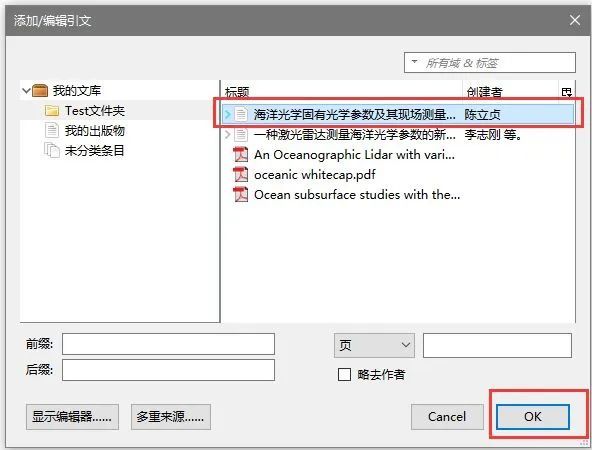
4. 下圖1處出現上角標→光標置於參考文獻3處→點擊2處→3處引入參考文獻成功


5. 其他文獻可依次插入。Zotero有個特彆強大的功能,如果中間一部分引文被刪除,點擊工具欄的Refresh,上角標以及參考文獻會自動更新。
六、尋找非默認引文格式
步驟:
點擊左上角Add/Edit Citation工具→選擇右下角管理樣式→在 Zotero Style Repository對話框尋找想要的引文格式


七、使用堅果雲同步文獻
zotero只給了300m的空間,大概只能放80來篇文獻的全文文件,如果文獻較多就不能同步全文。注意:使用同步功能要先註冊zotero賬號。
解決方法:使用堅果云:
堅果雲官網://www.jianguoyun.com/
注意關閉手機驗證,設置如圖:

八、使用插件
Zotero還有不少插件,比較有名的是zotfile,Zotero DOl Manager,它們可以自動下載pdf,或者獲取論文的DOI。
具體使用方法可以網上搜索獲取。
OCR神器(公式識別等)
我發現了一個神奇的OCR工具:天若OCR,功能真的很好很強大。
免費版本可以識別圖片文本,收費版本也不貴,59元一次性買個專業版,可以定義接口。
軟件具有文本識別、翻譯等功能,這些通用功能我就不展開說明了,我着重推薦兩個功能:公式識別和表格識別。
公式識別
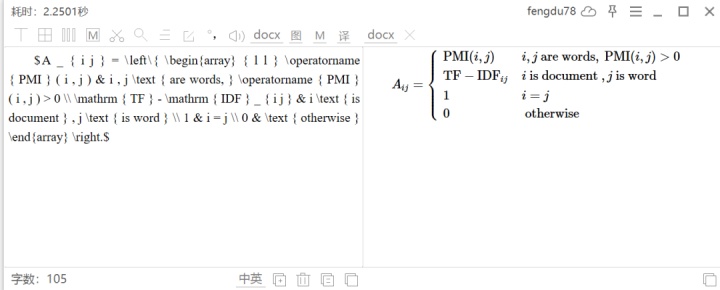
我之前推薦過公式的識別神器mathpix,真的很好用,但是免費的只有每個月50次,不夠。
天若OCR可以設置mathpix的接口,mathpix接口一個月免費1000次識別,應該夠了,註冊的時候要綁定信用卡(註冊過程要科學上網),識別效果:

表格識別
一般的OCR軟件識別文字都問題不大,但是表格識別卻是個問題,解決這個問題,這裡推薦下騰訊優圖的接口,目前每天200次識別免費。在天若OCR里配置好表格識別的接口為騰訊優圖後,識別效果如下:
Period#Node#EdgeDiameter#WCCAPLOver one week11653921183620011Over two weeks9904407727373724Over four weeks6900146461814334
原始表格圖片

識別後的表格,可以直接導入到word:

天若還可以對三線表添加網格後進行識別,非常方便。
在線的latex編輯和編譯工具:overleaf
論文最終展現出來的就是一個PDF格式的文檔。
當然可以使用word,但光排版這件事情,就能耗費你一半的精力。
正確的答案是,使用latex,它是一個專業的排版工具,按照latex的語法進行寫作,執行編譯就能夠得到PDF文件。它的語法包含了如何排版,雖然相比word上手要慢,但在排版這件事情上,入門級別的latex語法,你要達到精通word的水平。
latex如何使用呢?當然,要安裝編譯器,再安裝編輯器,本地一通配置,偶爾會遇到些問題,憑着強大的谷歌搜索,倒也不是什麼難事。配置本地環境,不如直接使用在線編輯器。
- 註冊即用,免去本地latex環境安裝的痛苦。
- 多人合作,共同編輯。
- 富文本編輯模式,比寫latex源碼舒服些。
- 隨時可以完成在線編譯,查看PDF。

按照overleaf的開始流程,有選擇模板的過程,模板怎麼選,還是要看投稿的期刊或者會議的要求。以KDD為例,在它的KDD 2019 Call for Research Papers頁面上,給出了模板格式,看看能不能在overleaf上找到,即使沒有,一會提供下載,自己上傳到overleaf。

走過這一步,已經可以編譯出模板PDF了,可以照貓畫虎地寫起來了。
grammarly:語法糾錯神器
在這編輯文章的一句或一段話,語法出錯了會有提示,低級的語法錯誤都能夠避免。

語法糾錯
除了語法糾錯之外,還有同意替換功能,我的塑料英語能想到的詞彙都太過常見,不夠精準(逼格不足),選中詞就可以同義替換了。

同意替換
建議在word軟件中安裝grammarly插件,直接可用在word中進行語法校對和糾正。
論文繪圖工具
本人在寫機器學習相關論文的時候,很多圖片是用matplotlib和seaborn畫的,但是,我還有一個神器,Scikit-plot,通過這個神器,畫出了更加高大上的機器學習圖,本文對Scikit-plot做下簡單介紹。
安裝說明
安裝Scikit-plot非常簡單,直接用命令:
- ounter(line
pip install scikit-plot即可完成安裝。
倉庫地址:
//github.com/reiinakano/scikit-plot
裏面有使用說明和樣例(py和ipynb格式)。
使用說明
簡單舉幾個例子:
- 比如畫出分類評級指標的ROC曲線的完整代碼:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
nb = GaussianNB()
nb.fit(X_train, y_train)
predicted_probas = nb.predict_proba(X_test)
# The magic happens here
import matplotlib.pyplot as plt
import scikitplot as skplt
skplt.metrics.plot_roc(y_test, predicted_probas)
plt.show()效果如圖(相當高大上!)

- P-R曲線就是精確率precision vs 召回率recall 曲線,以recall作為橫坐標軸,precision作為縱坐標軸。首先解釋一下精確率和召回率。
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits as load_data
import scikitplot as skplt
# Load dataset
X, y = load_data(return_X_y=True)
# Create classifier instance then fit
nb = GaussianNB()
nb.fit(X,y)
# Get predicted probabilities
y_probas = nb.predict_proba(X)
skplt.metrics.plot_precision_recall_curve(y, y_probas, cmap='nipy_spectral')
plt.show()
- 混淆矩陣是分類的重要評價標準,下面代碼是用隨機森林對鳶尾花數據集進行分類,分類結果畫一個歸一化的混淆矩陣。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits as load_data
from sklearn.model_selection import cross_val_predict
import matplotlib.pyplot as plt
import scikitplot as skplt
X, y = load_data(return_X_y=True)
# Create an instance of the RandomForestClassifier
classifier = RandomForestClassifier()
# Perform predictions
predictions = cross_val_predict(classifier, X, y)
plot = skplt.metrics.plot_confusion_matrix(y, predictions, normalize=True)
plt.show()
其他圖如學習曲線、特徵重要性、聚類的肘點等等,都可以用幾行代碼搞定。

本章對Scikit-plot做下簡單介紹,這是一個機器學習的畫圖神器,幾行代碼就能畫出高大上的機器學習圖,作者當年的博士論文也是靠這個畫圖的。倉庫地址:
//github.com/reiinakano/scikit-plot
裏面有使用說明和樣例。
參考
[1]:知乎:九老師
[2]://www.zotero.org
[3]://github.com/reiinakano/scikit-plot
總結
本文分享下我常用的論文工具,希望對讀者寫論文有所幫助,祝各位讀者都能寫出高大上的論文。

