如何在億級數據中判斷一個元素是否存在?
前言
在日常工作中,經常要判斷一個元素是否在一個集合中。假設你要向瀏覽器添加一項功能,該功能可以通知用戶輸入的網址是否是惡意網址,此時你手上有大約 1000 萬個惡意 URL 的數據集,你該如何實現該功能。按我之前的思維,要判斷一個元素在不在當前的數據集中,首先想到的就是使用 hash table,通過哈希函數運行所有的惡意網址以獲取其哈希值,然後創建出一個哈希表(數組)。這個方案有個明顯的缺點,就是需要存儲原始元素本身,內存佔用大,而我們其實主要是關注 當前輸入的網址在不在我們的惡意 URL 數據集中,也就是之前的惡意 URL 數據集的具體值是什麼並不重要,通過吳軍老師的《數學之美》了解到,對於這種場景大數據領域有個用於在海量數據情況下判斷某個元素是否已經存在的算法很適合,關鍵的一點是該算法並不存儲元素本身,這個算法就是 — 布隆過濾器(Bloom filter)。
原理
布隆過濾器是由巴頓.布隆於一九七零年提出的,在 維基百科 中的描述如下:
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set.
布隆過濾器是一個數據結構,它可以用來判斷某個元素是否在集合內,具有運行快速,內存佔用小的特點,它由一個很長的二進制向量和一系列隨機映射函數組成。而高效插入和查詢的代價就是,它是一個基於概率的數據結構,只能告訴我們一個元素絕對不在集合內,布隆過濾器的好處在於快速,省空間,但是有一定的誤判率。布隆過濾器的基礎數據結構是一個比特向量,假設有一個長度為 16 的比特向量,下面我們通過一個簡單的示例來看看其工作原理,:

上圖比特向量中的每一個空格表示一個比特, 空格下面的數字表示當前位置的索引。只需要簡單的對輸入進行多次哈希操作,並把對應於其結果的比特置為 1,就完成了向 Bloom filter 添加一個元素的操作。下圖表示向布隆過濾器中添加元素 //www.mghio.cn 和 //www.abc.com 的過程,它使用了 func1 和 func2 兩個簡單的哈希函數。
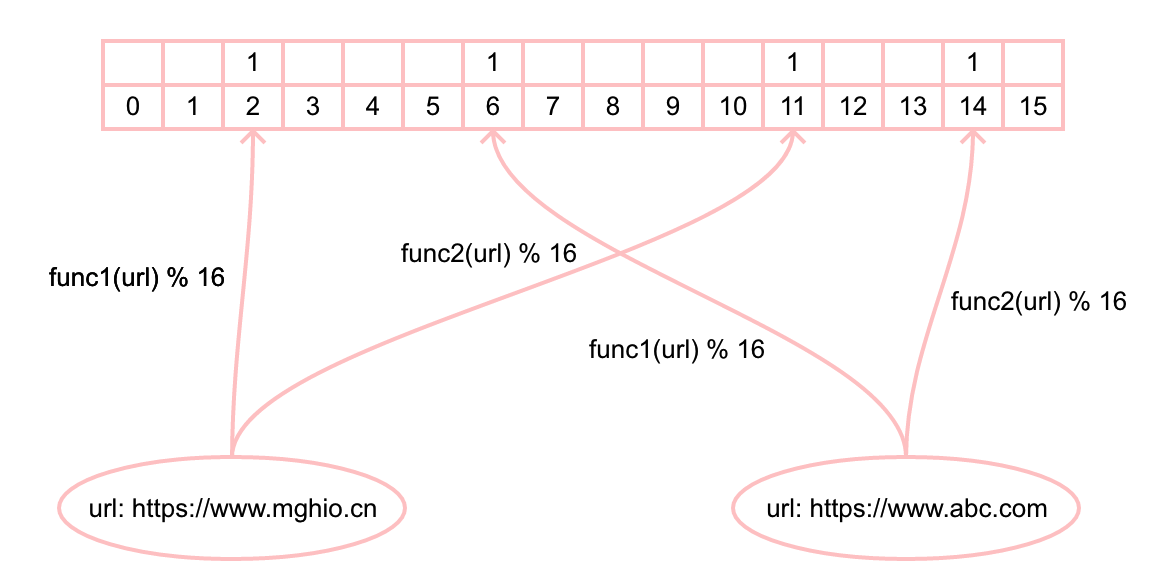
當我們往集合里添加一個元素的時候, 可以檢查該元素在應用對應哈希函數後的哈希值對比特向量的長度取余後的位置是否為 1,圖中用 1 表示最新添加的元素對應位置。然後當我們要判斷添加元素是否存在集合中的話,只需要簡單的通過對該元素應用同樣的哈希函數,然後看比特向量里對應的位置是否為 1 的方式來判斷一個元素是否在集合里。如果不是,則該元素一定不再集合中,但是需要注意的是,如果是,你只知道元素可能在裏面, 因為這些對應位置有可能恰巧是由其它元素或者其它元素的組合所引起的。以上就是布隆過濾器的實現原理。
如何自己實現
布隆過濾器的思想比較簡單,首先在構造方法中初始化了一個指定長度的 int 數組,在添加元素的時候通過哈希函數 func1 和 func2 計算出對應的哈希值,對數組長度取余後將對應位置置為 1,判斷元素是否存在於集合中時,同樣也是對元素用同樣的哈希函數進行兩次計算,取到對應位置的哈希值,只要存在位置的值為 0,則認為元素不存在。下面使用 Java 語言實現了上面示例中簡單版的布隆過濾器:
public class BloomFilter {
/**
* 數組長度
*/
private int size;
/**
* 數組
*/
private int[] array;
public BloomFilter(int size) {
this.size = size;
this.array = new int[size];
}
/**
* 添加數據
*/
public void add(String item) {
int firstIndex = func1(item);
int secondIndex = func2(item);
array[firstIndex % size] = 1;
array[secondIndex % size] = 1;
}
/**
* 判斷數據 item 是否存在集合中
*/
public boolean contains(String item) {
int firstIndex = func1(item);
int secondIndex = func2(item);
int firstValue = array[firstIndex % size];
int secondValue = array[secondIndex % size];
return firstValue != 0 && secondValue != 0;
}
/**
* hash 算法 func1
*/
private int func1(String key) {
int hash = 7;
hash += 61 * hash + key.hashCode();
hash ^= hash >> 15;
hash += hash << 3;
hash ^= hash >> 7;
hash += hash << 11;
return Math.abs(hash);
}
/**
* hash 算法 func2
*/
private int func2(String key) {
int hash = 7;
for (int i = 0, len = key.length(); i < len; i++) {
hash += key.charAt(i);
hash += (hash << 7);
hash ^= (hash >> 17);
hash += (hash << 5);
hash ^= (hash >> 13);
}
return Math.abs(hash);
}
}
自己實現雖然簡單但是有一個問題就是檢測的誤判率比較高,通過其原理可以知道,可我們可以提高數組長度以及 hash 計算次數來降低誤報率,但是相應的 CPU、內存的消耗也會相應的提高;這需要我們根據自己的業務需要去權衡選擇。
扎心一問
哈希函數該如何設計?
布隆過濾器里的哈希函數最理想的情況就是需要盡量的彼此獨立且均勻分佈,同時,它們也需要儘可能的快 (雖然 sha1 之類的加密哈希算法被廣泛應用,但是在這一點上考慮並不是一個很好的選擇)。
布隆過濾器應該設計為多大?
個人認為布隆過濾器的一個比較好特性就是我們可以修改過濾器的錯誤率。一個大的過濾器會擁有比一個小的過濾器更低的錯誤率。假設在布隆過濾器裏面有 k 個哈希函數,m 個比特位(也就是位數組長度),以及 n 個已插入元素,錯誤率會近似於 (1-ekn/m)k,所以你只需要先確定可能插入的數據集的容量大小 n,然後再調整 k 和 m 來為你的應用配置過濾器。
應該使用多少個哈希函數?
顯然,布隆過濾器使用的哈希函數越多其運行速度就會越慢,但是如果哈希函數過少,又會遇到誤判率高的問題。所以這個問題上需要認真考慮,在創建一個布隆過濾器的時候需要確定哈希函數的個數,也就是說你需要提前預估集合中元素的變動範圍。然而你這樣做了之後,你依然需要確定比特位個數和哈希函數的個數的值。看起來這似乎這是一個十分困難的優化問題,但幸運的是,對於給定的 m(比特位個數)和 n(集合元素個數),最優的 k(哈希函數個數)值為: (m/n)ln(2)(PS:需要了解具體的推導過程的朋友可以參考維基百科)。也就是我們可以通過以下步驟來確定布隆過濾器的哈希函數個數:
- 確定 n(集合元素個數)的變動範圍。
- 選定 m(比特位個數)的值。
- 計算 k(哈希函數個數)的最優值
對於給定的 n、m 和 k 計算錯誤率,如果這個錯誤率不能接受的話,可以繼續回到第二步。
布隆過濾器的時間複雜度和空間複雜度?
對於一個 m(比特位個數)和 k(哈希函數個數)值確定的布隆過濾器,添加和判斷操作的時間複雜度都是 O(k),這意味着每次你想要插入一個元素或者查詢一個元素是否在集合中,只需要使用 k 個哈希函數對該元素求值,然後將對應的比特位標記或者檢查對應的比特位即可。
總結
布隆過濾器的實際應用很廣泛,特別是那些要在大量數據中判斷一個元素是否存在的場景。可以看到,布隆過濾器的算法原理比較簡單,但要實際做一個生產級別的布隆過濾器還是很複雜的,谷歌的開源庫 Guava 的 BloomFilter 提供了 Java 版的實現,用法很簡單。最後留給大家一個問題:布隆過濾器支持元素刪除嗎?


