實戰|使用Spark Streaming寫入Hudi
- 2020 年 4 月 18 日
- 筆記
1. 項目背景
傳統數倉的組織架構是針對離線數據的OLAP(聯機事務分析)需求設計的,常用的導入數據方式為採用sqoop或spark定時作業逐批將業務庫數據導入數倉。隨着數據分析對實時性要求的不斷提高,按小時、甚至分鐘級的數據同步越來越普遍。由此展開了基於spark/flink流處理機制的(准)實時同步系統的開發。
然而實時同步數倉從一開始就面臨如下幾個挑戰:
- 小文件問題。不論是spark的microbatch模式,還是flink的逐條處理模式,每次寫入HDFS時都是幾M甚至幾十KB的文件。長時間下來產生的大量小文件,會對HDFS namenode產生巨大的壓力。
- 對update操作的支持。HDFS系統本身不支持數據的修改,無法實現同步過程中對記錄進行修改。
- 事務性。不論是追加數據還是修改數據,如何保證事務性。即數據只在流處理程序commit操作時一次性寫入HDFS,當程序rollback時,已寫入或部分寫入的數據能隨之刪除。
Hudi是針對以上問題的解決方案之一。以下是對Hudi的簡單介紹,主要內容翻譯自官網。
2. Hudi簡介
2.1 時間線(Timeline)
Hudi內部按照操作時刻(instant)對錶的所有操作維護了一條時間線,由此可以提供表在某一時刻的視圖,還能夠高效的提取出延後到達的數據。每一個時刻包含:
- 時刻行為:對錶操作的類型,包含:
commit:提交,將批次的數據原子性的寫入表;
clean: 清除,後台作業,不斷清除不需要的舊得版本的數據;
delta_commit:delta 提交是將批次記錄原子性的寫入MergeOnRead表中,數據寫入的目的地是delta日誌文件;
compacttion:壓縮,後台作業,將不同結構的數據,例如記錄更新操作的行式存儲的日誌文件合併到列式存儲的文件中。壓縮本身是一個特殊的commit操作;
rollback:回滾,一些不成功時,刪除所有部分寫入的文件;
savepoint:保存點,標誌某些文件組為「保存的「,這樣cleaner就不會刪除這些文件;
- 時刻時間:操作開始的時間戳;
- 狀態:時刻的當前狀態,包含:
requested 某個操作被安排執行,但尚未初始化
inflight 某個操作正在執行
completed 某一個操作在時間線上已經完成
Hudi保證按照時間線執行的操作按照時刻時間具有原子性及時間線一致性。
2.2 文件管理
Hudi表存在在DFS系統的 base path(用戶寫入Hudi時自定義) 目錄下,在該目錄下被分成不同的分區。每一個分區以 partition path 作為唯一的標識,組織形式與Hive相同。
每一個分區內,文件通過唯一的 FileId 文件id 劃分到 FileGroup 文件組。每一個FileGroup包含多個 FileSlice 文件切片,每一個切片包含一個由commit或compaction操作形成的base file 基礎文件(parquet文件),以及包含對基礎文件進行inserts/update操作的log files 日誌文件(log文件)。Hudi採用了MVCC設計,compaction操作會將日誌文件和對應的基礎文件合併成新的文件切片,clean操作則刪除無效的或老版本的文件。
2.3 索引
Hudi通過映射Hoodie鍵(記錄鍵+ 分區路徑)到文件id,提供了高效的upsert操作。當第一個版本的記錄寫入文件時,這個記錄鍵值和文件的映射關係就不會發生任何改變。換言之,映射的文件組始終包含一組記錄的所有版本。
2.4 表類型&查詢
Hudi表類型定義了數據是如何被索引、分佈到DFS系統,以及以上基本屬性和時間線事件如何施加在這個組織上。查詢類型定義了底層數據如何暴露給查詢。
| 表類型 | 支持的查詢類型 |
|---|---|
| Copy On Write寫時複製 | 快照查詢 + 增量查詢 |
| Merge On Read讀時合併 | 快照查詢 + 增量查詢 + 讀取優化 |
2.4.1 表類型
Copy On Write:僅採用列式存儲文件(parquet)存儲文件。更新數據時,在寫入的同時同步合併文件,僅僅修改文件的版次並重寫。
Merge On Read:採用列式存儲文件(parquet)+行式存儲文件(avro)存儲數據。更新數據時,新數據被寫入delta文件並隨後以異步或同步的方式合併成新版本的列式存儲文件。
| 取捨 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 數據延遲 | 高 | 低 |
| Update cost (I/O)更新操作開銷(I/O) | 高(重寫整個parquet) | 低(追加到delta記錄) |
| Parquet文件大小 | 小(高更新(I/O)開銷) | 大(低更新開銷) |
| 寫入頻率 | 高 | 低(取決於合併策略) |
2.4.2 查詢類型
- 快照查詢:查詢會看到以後的提交操作和合併操作的最新的錶快照。對於merge on read表,會將最新的基礎文件和delta文件進行合併,從而會看到近實時的數據(幾分鐘的延遲)。對於copy on write表,當存在更新/刪除操作時或其他寫操作時,會直接代替已有的parquet表。
- 增量查詢:查詢只會看到給定提交/合併操作之後新寫入的數據。由此有效的提供了變更流,從而實現了增量數據管道。
- 讀優化查詢:查詢會看到給定提交/合併操作之後表的最新快照。只會查看到最新的文件切片中的基礎/列式存儲文件,並且保證和非hudi列式存儲表相同的查詢效率。
| 取捨 | 快照 | 讀取優化 |
|---|---|---|
| 數據延遲 | 低 | 高 |
| 查詢延遲 | 高(合併基礎/列式存儲文件 + 行式存儲delta / 日誌 文件) | 低(原有的基礎/列式存儲文件查詢性能) |
3. Spark結構化流寫入Hudi
以下是整合spark結構化流+hudi的示意代碼,由於Hudi OutputFormat目前只支持在spark rdd對象中調用,因此寫入HDFS操作採用了spark structured streaming的forEachBatch算子。具體說明見注釋。
package pers.machi.sparkhudi
import org.apache.log4j.Logger
import org.apache.spark.sql.catalyst.encoders.RowEncoder
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
object SparkHudi {
val logger = Logger.getLogger(SparkHudi.getClass)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkHudi")
//.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.default.parallelism", 9)
.config("spark.sql.shuffle.partitions", 9)
.enableHiveSupport()
.getOrCreate()
// 添加監聽器,每一批次處理完成,將該批次的相關信息,如起始offset,抓取記錄數量,處理時間打印到控制台
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
// 定義kafka流
val dataStreamReader = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "testTopic")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", false)
// 加載流數據,這裡因為只是測試使用,直接讀取kafka消息而不做其他處理,是spark結構化流會自動生成每一套消息對應的kafka元數據,如消息所在主題,分區,消息對應offset等。
val df = dataStreamReader.load()
.selectExpr(
"topic as kafka_topic"
"CAST(partition AS STRING) kafka_partition",
"cast(timestamp as String) kafka_timestamp",
"CAST(offset AS STRING) kafka_offset",
"CAST(key AS STRING) kafka_key",
"CAST(value AS STRING) kafka_value",
"current_timestamp() current_time",
)
.selectExpr(
"kafka_topic"
"concat(kafka_partition,'-',kafka_offset) kafka_partition_offset",
"kafka_offset",
"kafka_timestamp",
"kafka_key",
"kafka_value",
"substr(current_time,1,10) partition_date")
// 創建並啟動query
val query = df
.writeStream
.queryName("demo").
.foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist()
println(LocalDateTime.now() + "start writing cow table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
// 以kafka分區和偏移量作為組合主鍵
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
// 以當前日期作為分區
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "copy_on_write_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/COPY_ON_WRITE")
println(LocalDateTime.now() + "start writing mor table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "MERGE_ON_READ")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "merge_on_read_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/MERGE_ON_READ")
println(LocalDateTime.now() + "finish")
batchDF.unpersist()
}
}
.option("checkpointLocation", "/tmp/sparkHudi/checkpoint/")
.start()
query.awaitTermination()
}
}
4. 測試結果
受限於測試條件,這次測試沒有考慮update操作,而僅僅是測試hudi對追加新數據的性能。
數據程序一共運行5天,期間未發生報錯導致程序退出。
kafka每天讀取數據約1500萬條,被消費的topic共有9個分區。
幾點說明如下
1 是否有數據丟失及重複
由於每條記錄的分區+偏移量具有唯一性,通過檢查同一分區下是否有偏移量重複及不連續的情況,可以斷定數據不存丟失及重複消費的情況。
2 最小可支持的單日寫入數據條數
數據寫入效率,對於cow及mor表,不存在更新操作時,寫入速率接近。這本次測試中,spark每秒處理約170條記錄。單日可處理1500萬條記錄。
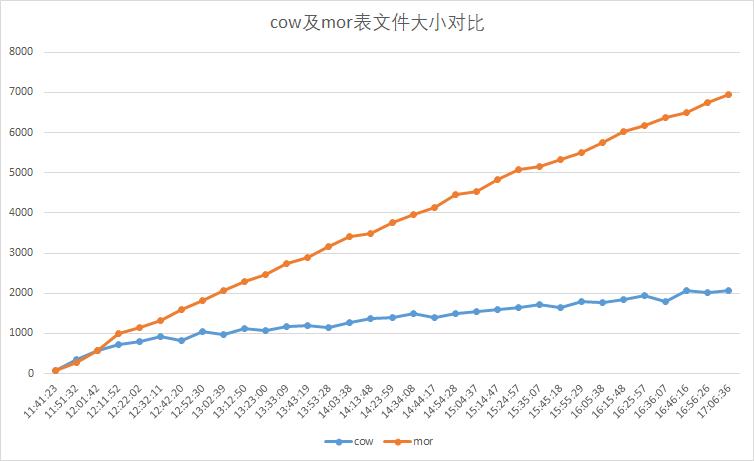
3 cow和mor表文件大小對比
每十分鐘讀取兩種表同一分區小文件大小,單位M。結果如下圖,mor表文件大小增加較大,佔用磁盤資源較多。不存在更新操作時,儘可能使用cow表。