ML-Agents(六)Tennis
- 2020 年 4 月 11 日
- 筆記
ML-Agents(六)Tennis
喜歡的童靴希望大家多多點贊收藏哦~
這次Tennis示例研究費了我不少勁,倒不是因為示例的難度有多大,而重點是這個示例的訓練過程中遇到了許多問題值得記錄下來,其次這個訓練是一個對抗訓練,也是比較有意思的示例。
一、Tennis介紹
首先來看看效果~
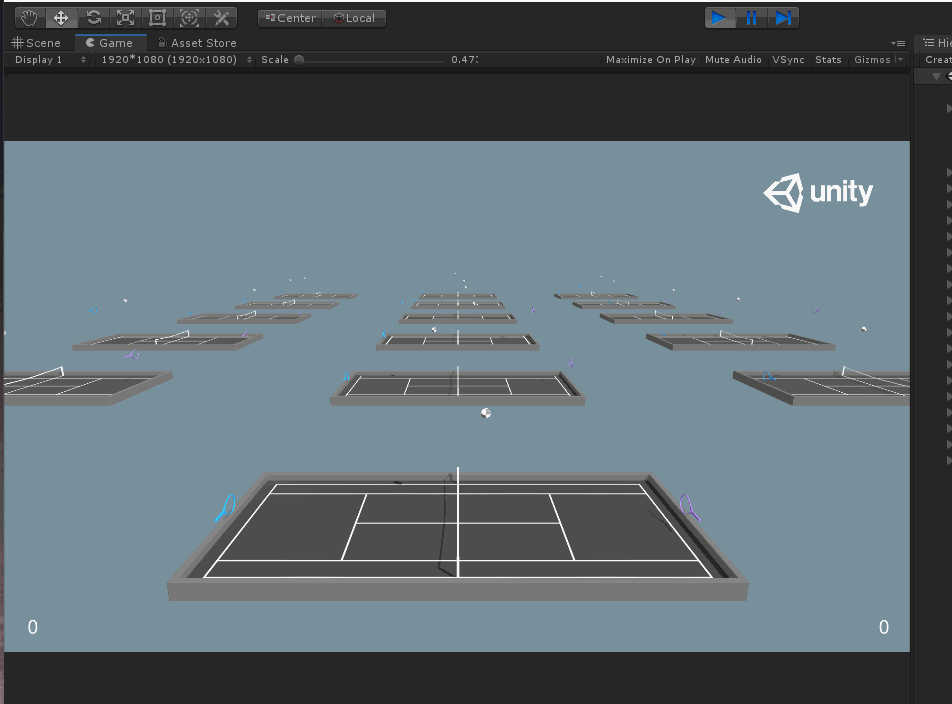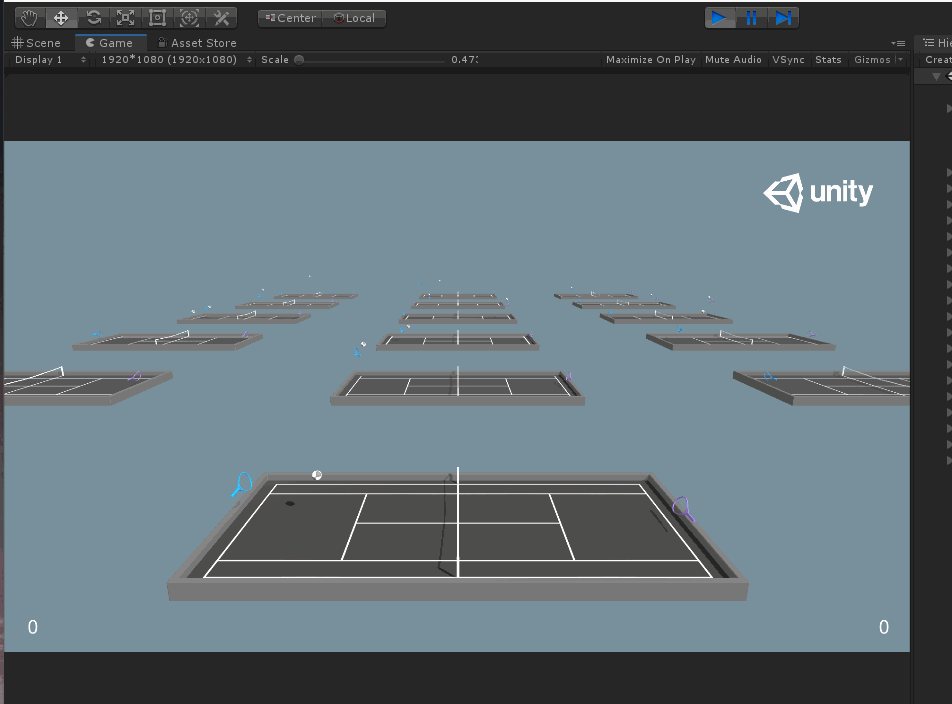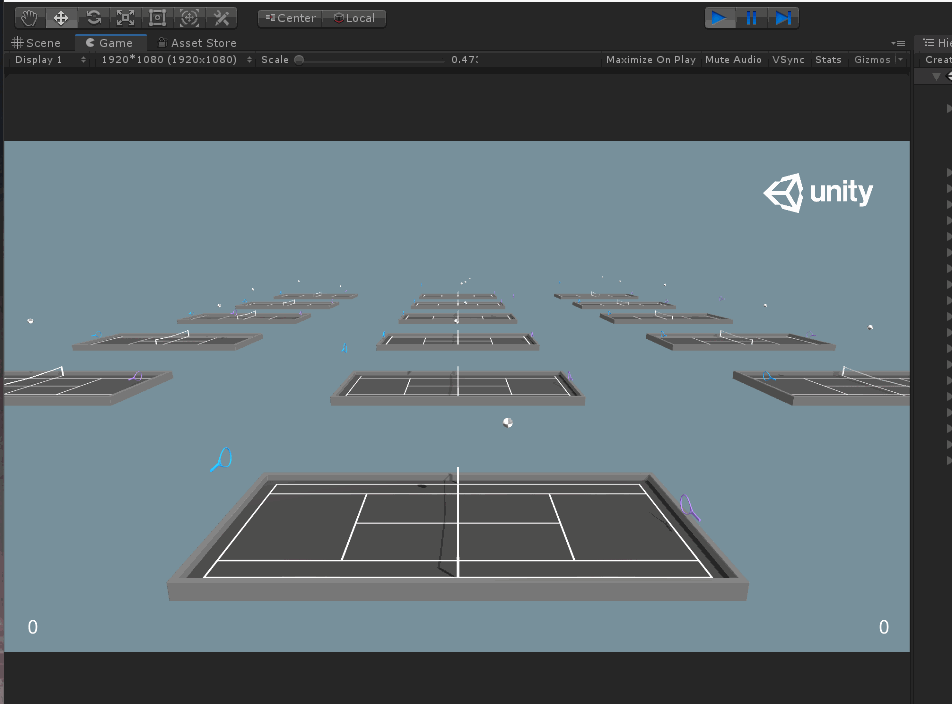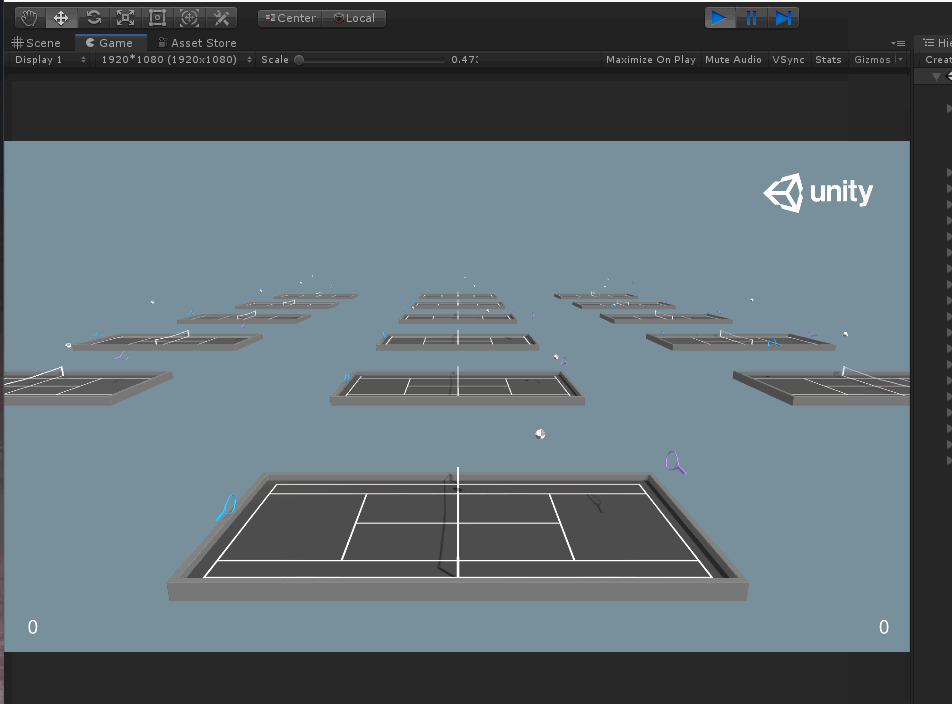
OK,可以看到畫面中有18個網球場,然後藍色的球拍和紫色的球拍互相對打。這裡注意一下,場景雖然都是3D的,但實際上球拍和球只在球場的中軸線上上下左右移動,也就是說其實換個相機位置的話,這裡其實是個二維打球模擬。
當然了,這樣算是簡化了訓練的過程,這個示例大部分所用到的內容和3D Ball差不多,主要有一個可以深化學習的就是對抗訓練。下面我們來先看一下官方對該示例的參數。
二、環境與訓練參數
老規矩,先來看一下官方文檔參數:
-
設定:兩個agents控制球拍進行雙人遊戲,來回擊打球過球網
-
目標:一方agent必須打擊球,以使對手無法擊回球
-
Agent:在這個環境中,包含兩個擁有相同行為參數(Behavior Parameters)的Agent。官方還建議,當你訓練好你的球拍Agent後,可以把其中一個球拍調整為
Heuristic Only手動操作,嘗試一下被電腦虐的快感(當然官方不是這麼說的,但是確實有點困難= =)。這裡要設置成手動模式,還需要修改一下代碼,後面會提到 -
Agent獎勵設定:
- 如果agent贏下一球,則+1。當然由於是對抗訓練,所以一方agent要通過防止另一方agent贏球來贏取獎勵
- 如果agent輸掉一球,則-1
-
行為參數:
- 矢量觀測空間:一共9個變量,分別對應球和球拍的位置、速度以及方向
- 矢量動作空間:
Continuous類型,一共3個變量,對應球拍向網、遠離網的運動,跳躍和旋轉。這裡通俗點講就是球拍的x、y方向運動,以及球拍繞自身z軸的旋轉 - 視覺觀測值:None
-
可變參數:3個
- 重力加速度:
- Default:9.81
- 推薦最小值:6
- 推薦最大值:20
- 網球比例:球三個維度上的比例(即x、y、z比例相同)
- Default:5
- 推薦最小值:0.2
- 推薦最大值:5
球拍初始角度:Default:55(源碼里這麼寫了)
最後一個「球拍初始角度」官方漏寫了,我說為啥明明寫了3個參數,卻只有兩個參數寫出來。但是!!!凡事有個但是,實際上通過源碼會發現,最後這個參數無論怎麼改,並不會改變訓練時的效果,因為訓練時會讓Agent自動調整球拍的旋轉角度。其實這個參數的唯一作用就是你在手動操作和你訓練出來的agent找虐時,會使球拍固定在一個角度來打球,當然,如果你還有餘力可以調整球拍角度,那你很sei li~對於agent沒啥大影響,對於手動來說,那就是天差地別了。
- 重力加速度:
三、場景基本結構
場景中包含18個球場,如下圖:
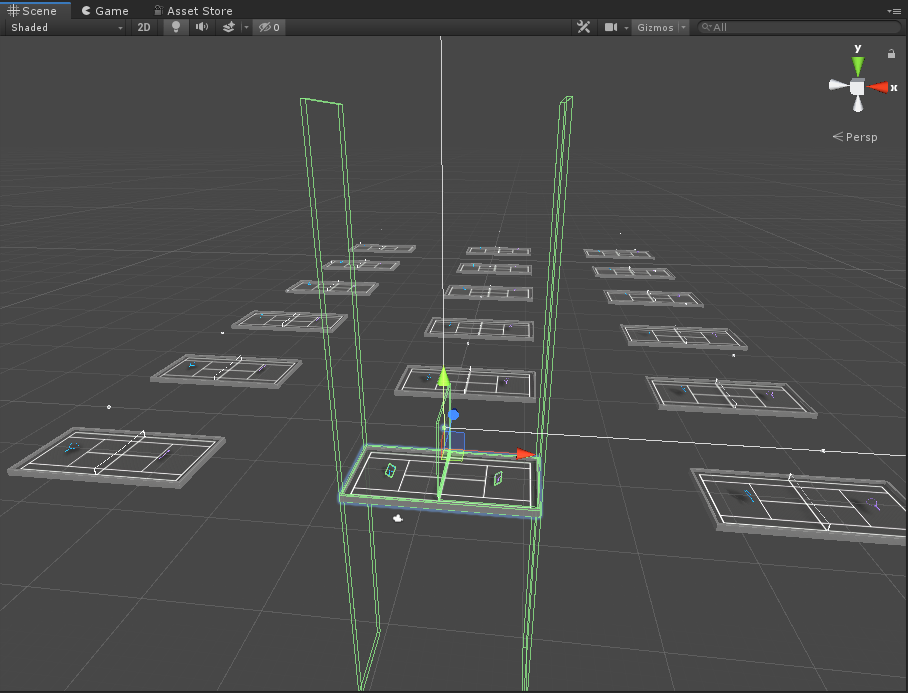
相應的Hierarchy層級:
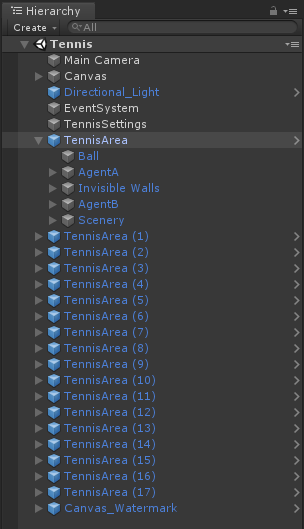
場景中Camera、Canvas啥的都不用太多去介紹,TennisSettings可以設置環境一些高級物理設置,例如Unity中的Physics.gravity、Time.fixedDeltaTime、Physics.defaultSolverIterations等。
TennisArea是作為一個訓練的基本單位。其中:
-
TennisArea
父物體上本來就帶有一個
TennisArea.cs腳本,這個腳本主要是重置比賽環境,例如每次開始球的位置、比例等,但是我認為在這裡初始化球的比例有問題,這個我們後面說。 -
Ball
球,帶有剛體,存在
HitWall.cs腳本,你會發現有意思的是,原來我們看的示例agent的獎懲基本都在AgentAction()函數中,即隨時判斷agent是否獎懲,但是這裡將agent獎勵或失敗設置放到了球上,由球來決定到底是agentA贏還是agentB贏,然後重置agent。當然這也比較好理解,因為規則都在球上,球當然知道到底誰贏了(感覺有點邪惡。。。。2333)。
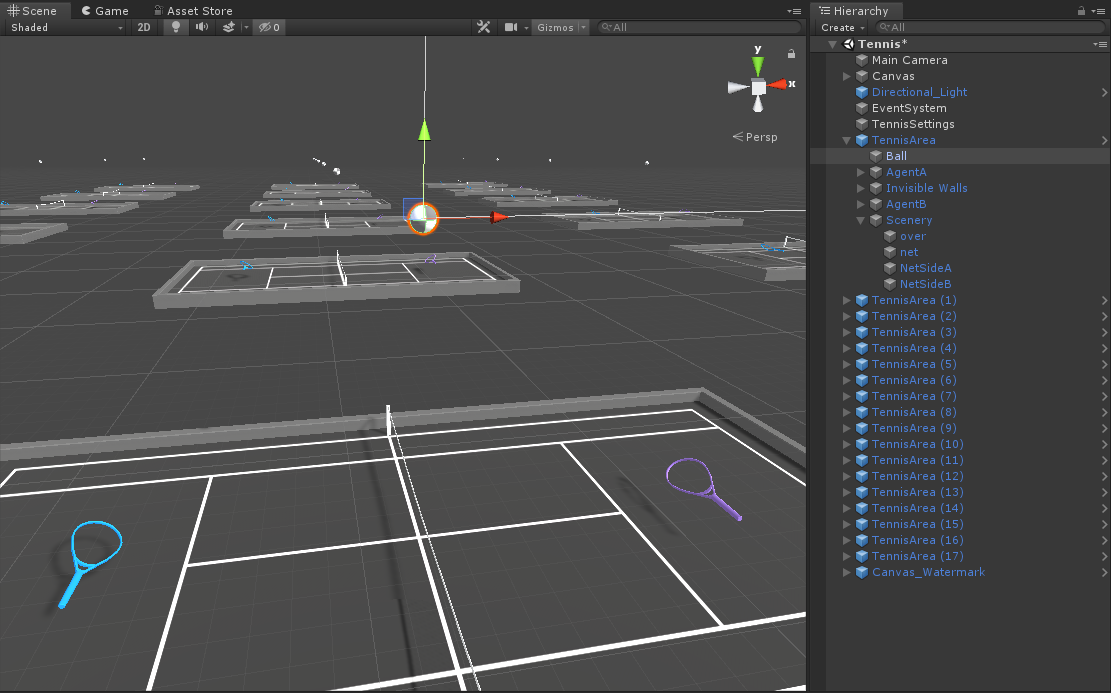
-
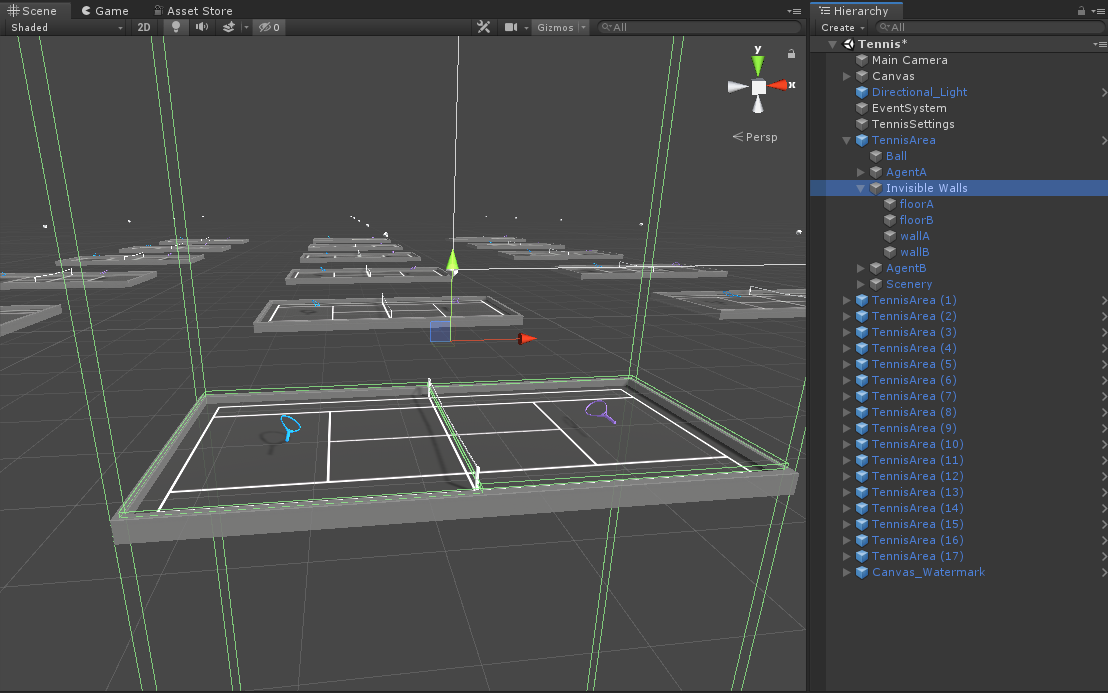
Invisible Walls
如英文注釋,就是透明碰撞體,場地兩邊地面各一個,場後各一個,就是為了防止球掉落。當然我想吐槽一下這個碰撞體,設置的太粗曠了= =,兩邊的牆巨長無比。
-
Scenery
球場四周的碰撞體,網的碰撞體以及網上的碰撞體。
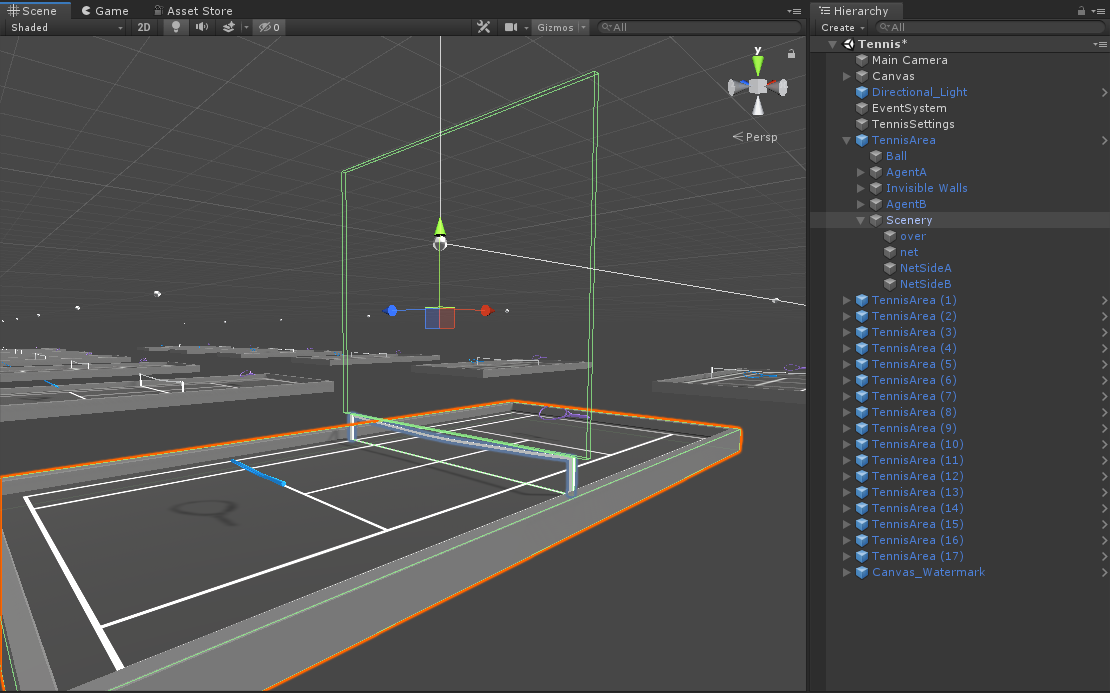
-
AgentA和AgentB
兩個agent,分別代表兩對抗方,公用一套訓練參數進行訓練。
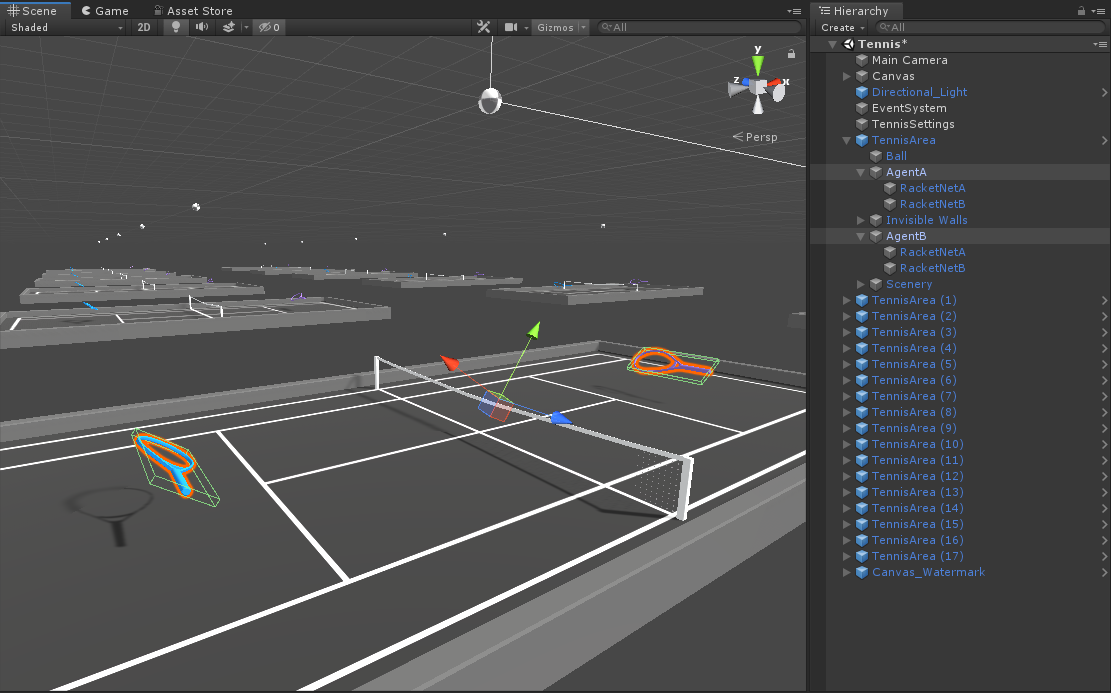
這裡兩個agent大家注意,看一下有啥不一樣,首先看Behavior Parameters組件:
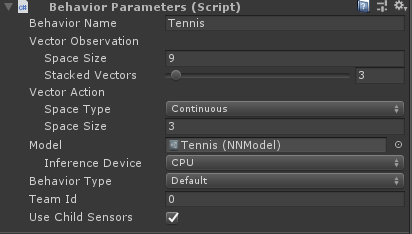
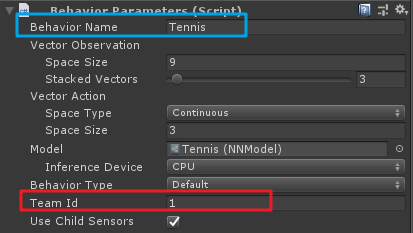
可以看到兩個球拍的行為參數,Team Id是不同的,表示了兩個不同的陣營,猜測如果有多方陣營也可以訓練,還有這裡應該是使用Behavior Name來保證訓練的Brain一致,在前幾面的文章中也有提及。
再來看一下兩個球拍的Tennis Agent:
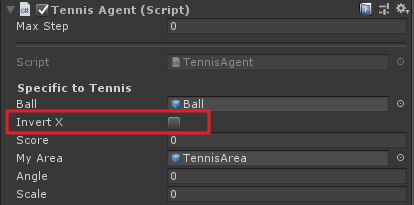
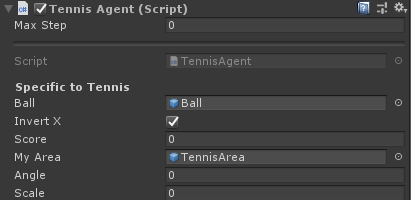
會發現一個Invert X勾選,另一個未勾選,這裡先賣個關子,一會兒講為什麼這麼設置。
下面直接開始分析代碼,走起。
四、代碼分析
環境初始化腳本
這個示例中環境初始化分為兩個部分,一個部分是處於父節點的TennisArea腳本,另一個是球上的HitWall腳本。前者主要在環境重置時初始化球的位置,以及限制球的速度;後者則是包含了打球規則以及初始化球拍、調用TennisArea來初始化比賽。
先來看一下TennisArea.cs腳本。
using UnityEngine; public class TennisArea : MonoBehaviour { public GameObject ball;//球 public GameObject agentA;//球拍agentA public GameObject agentB;//球拍agentB Rigidbody m_BallRb;//球的剛體 void Start() { m_BallRb = ball.GetComponent<Rigidbody>(); MatchReset();//一開始重置比賽,注意這裡運行的順序後於Agent的InitializeAgent() } /// <summary> /// 重置比賽 /// </summary> public void MatchReset() { var ballOut = Random.Range(6f, 8f);//球隨機x值 var flip = Random.Range(0, 2);//隨機球出現在左邊還是右邊 if (flip == 0) {//令球在場地左邊隨機出現 ball.transform.position = new Vector3(-ballOut, 6f, 0f) + transform.position; } else {//令球在場地右邊隨機出現 ball.transform.position = new Vector3(ballOut, 6f, 0f) + transform.position; } m_BallRb.velocity = new Vector3(0f, 0f, 0f);//使球的速度變為0,然後令其自由落體 //注意:這裡修改小球的比例,我認為在這裡修改球的比例是不合適的 //ball.transform.localScale = new Vector3(.5f, .5f, .5f); ball.GetComponent<HitWall>().lastAgentHit = -1;//重置HitWall中判斷勝利參數 } void FixedUpdate() { //這裡主要是控制球的速度不要太快 var rgV = m_BallRb.velocity; m_BallRb.velocity = new Vector3(Mathf.Clamp(rgV.x, -9f, 9f), Mathf.Clamp(rgV.y, -9f, 9f), rgV.z); //Debug.Log(m_BallRb.velocity); } } 這個腳本有幾個點來說一下:
-
首先,一開始運行時,以上的Start()函數是晚於球拍Agent的初始化方法InitializeAgent()的,即MatchReset()方法是在InitializeAgent()之後的。在源碼里,TennisArea腳本第32行設置了球的比例,而注意球的比例是可變參數(現在官方改成Parameter Randomization了,即隨機化參數,原來是Generalized Reinforcement,即可變強化訓練,叫法改了用法一樣,就是可變參數)。因此,不管在Agent的InitializeAgent()里如何設置球的比例,在後執行的MatchReset()方法里都會將球的比例重新設置回(0.5f,0.5f,0.5f)。
以上還只是列舉了訓練一開始情況,蛋疼的是在訓練過程中,也會出現MatchReset()在Agent的SetBall()之後的情況,也就是如果你在訓練引入了可變參數球的size,在訓練過程中應該是要一定步驟後改變球的比例來訓練,但是如果在MatchReset()中設置球的比例,會使得球的比例一直被固定為0.5,因此應該是要去掉這一行的。
當然,以上推測只是我初看代碼理解的,後面我們可以分別注釋這一句和加上這一句來進行可變size參數訓練,觀察tensorboard的曲線就立馬能看出來了。
-
第二點是FixedUpdate()函數,這裡將網球的x方向速度和y方向速度限制到了-9到9,當然我們可以把這裡注釋掉,看看是什麼效果。

這裡會發現球的速度過快,下面的Debug也會發現速度很容易就在十幾、二十幾,球太容易飛出場外。
OK,TennisArea腳本應該沒什麼問題了,我們來分析一下網球上的HitWall腳本。
HitWall.cs
using UnityEngine; public class HitWall : MonoBehaviour { public GameObject areaObject;//父節點 public int lastAgentHit;//最後一次哪個agent擊球,0代表agentA擊球,1代表agentB擊球 public bool net;//判斷是否過網 public enum FloorHit { Service,//從空中發球 FloorHitUnset,//成功回擊球之後,使用該標誌位 FloorAHit,//在A地面彈起 FloorBHit//在B地面彈起 } public FloorHit lastFloorHit;//最後一次地板擊中狀態 TennisArea m_Area; TennisAgent m_AgentA;//代理A TennisAgent m_AgentB;//代理B void Start() { m_Area = areaObject.GetComponent<TennisArea>(); m_AgentA = m_Area.agentA.GetComponent<TennisAgent>(); m_AgentB = m_Area.agentB.GetComponent<TennisAgent>(); } /// <summary> /// 比賽重置,包括agentA、agentB、網球置位等 /// </summary> void Reset() { m_AgentA.Done(); m_AgentB.Done(); m_Area.MatchReset(); lastFloorHit = FloorHit.Service; net = false; } /// <summary> /// agentA贏 /// </summary> void AgentAWins() { m_AgentA.SetReward(1); m_AgentB.SetReward(-1); m_AgentA.score += 1; Reset(); } /// <summary> /// agentB贏 /// </summary> void AgentBWins() { m_AgentA.SetReward(-1); m_AgentB.SetReward(1); m_AgentB.score += 1; Reset(); } void OnCollisionEnter(Collision collision) { if (collision.gameObject.CompareTag("iWall")) {//如果球碰到牆(Tag=="iWall"),主要是"InvisibleWalls"和"Scenery"物體下的透明碰撞體 if (collision.gameObject.name == "wallA") {//如果球碰到A這邊的牆 if (lastAgentHit == 0 || lastFloorHit == FloorHit.FloorAHit) {//A自己擊球碰到A牆出界||球經過A這邊的地面彈起碰到A牆出界(A沒有接到球),則B贏 AgentBWins(); } else {//B擊球的情況下:若在發球時,B第一球未碰到A地面直接出界||回球時球碰到了B自己邊的地面||回球時,球出A邊界,則A贏 AgentAWins(); } } else if (collision.gameObject.name == "wallB") {//同上 if (lastAgentHit == 1 || lastFloorHit == FloorHit.FloorBHit) { AgentAWins(); } else { AgentBWins(); } } else if (collision.gameObject.name == "floorA") {//如果球碰到A這邊的地面 if (lastAgentHit == 0 || lastFloorHit == FloorHit.FloorAHit || lastFloorHit == FloorHit.Service) {//A擊球碰到自己的地面||最後一次也是在A地面彈起,即球在A地面彈了兩次||最後一次是B從空中發的球,A未接到球,則B贏 AgentBWins(); } else {//以上情況都不是,則A接到球並成功回擊 lastFloorHit = FloorHit.FloorAHit; if (!net) {//A成功接球並回擊 net = true; } } } else if (collision.gameObject.name == "floorB") {//同上 if (lastAgentHit == 1 || lastFloorHit == FloorHit.FloorBHit || lastFloorHit == FloorHit.Service) { AgentAWins(); } else { lastFloorHit = FloorHit.FloorBHit; if (!net) { net = true; } } } else if (collision.gameObject.name == "net" && !net) {//如果球碰到網,且未判定過網(即net=false) if (lastAgentHit == 0) {//如果上次擊球為A,則B贏 AgentBWins(); } else if (lastAgentHit == 1) {//如果上次擊球為B,則A贏 AgentAWins(); } } } else if (collision.gameObject.name == "AgentA") {//球碰到球拍A if (lastAgentHit == 0) {//如果上一次A已經擊打過,即A擊球兩次,則B贏 AgentBWins(); } else {//A成功回球 if (lastFloorHit != FloorHit.Service && !net) {//A在空中直接回球||球在A地面彈起後A回球(即lastFloorHit=FloorAHit||FloorHitUnset) //則判定過網 net = true; } lastAgentHit = 0;//使最後一次擊球為A lastFloorHit = FloorHit.FloorHitUnset;//重置擊球過程 } } else if (collision.gameObject.name == "AgentB") {//同上 if (lastAgentHit == 1) { AgentAWins(); } else { if (lastFloorHit != FloorHit.Service && !net) { net = true; } lastAgentHit = 1; lastFloorHit = FloorHit.FloorHitUnset; } } } } 這個腳本,比較複雜的部分就是判斷誰贏的邏輯,其實就是將網球的規則編程代碼了,熟悉網球規則的童靴應該看一下再想想邏輯就明白了。當然這裡也可以做了解,畢竟屬於業務部分的東西。
Agent腳本
Agent初始化與重置
首先來看一下Agent腳本中對於agent的初始化、重置部分以及變量參數。
public class TennisAgent : Agent { [Header("Specific to Tennis")] public GameObject ball;//網球對象 public bool invertX;//鏡像標誌位 public int score;//得分 public GameObject myArea;//平台 public float angle;//球拍角度 public float scale;//網球比例 Text m_TextComponent;//得分板Text Rigidbody m_AgentRb;//球拍剛體 Rigidbody m_BallRb;//網球剛體 float m_InvertMult;//鏡像翻轉乘數 IFloatProperties m_ResetParams;//可變參數(可變參數) const string k_CanvasName = "Canvas"; const string k_ScoreBoardAName = "ScoreA"; const string k_ScoreBoardBName = "ScoreB"; public override void InitializeAgent() { m_AgentRb = GetComponent<Rigidbody>(); m_BallRb = ball.GetComponent<Rigidbody>(); //找球拍自己對應的得分板,不贅述 var canvas = GameObject.Find(k_CanvasName); GameObject scoreBoard; m_ResetParams = Academy.Instance.FloatProperties; if (invertX) { scoreBoard = canvas.transform.Find(k_ScoreBoardBName).gameObject; } else { scoreBoard = canvas.transform.Find(k_ScoreBoardAName).gameObject; } m_TextComponent = scoreBoard.GetComponent<Text>(); SetResetParameters();//設置可變參數 } /// <summary> /// 設置球拍角度 /// </summary> public void SetRacket() { angle = m_ResetParams.GetPropertyWithDefault("angle", 55f); gameObject.transform.eulerAngles = new Vector3( gameObject.transform.eulerAngles.x, gameObject.transform.eulerAngles.y, m_InvertMult * angle ); } /// <summary> /// 設置網球比例 /// </summary> public void SetBall() { scale = m_ResetParams.GetPropertyWithDefault("scale", .5f); ball.transform.localScale = new Vector3(scale, scale, scale); } /// <summary> /// 設置可變參數 /// </summary> public void SetResetParameters() { SetRacket(); SetBall(); } /// <summary> /// Agent重置 /// </summary> public override void AgentReset() { //根據inverX值來將m_InverMul置為1或-1 m_InvertMult = invertX ? -1f : 1f; //球拍位置重置,X隨機(前後),Y(高度)與Z(左右)位置固定 transform.position = new Vector3(-m_InvertMult * Random.Range(6f, 8f), -1.5f, -1.8f) + transform.parent.transform.position; //球拍速度置0 m_AgentRb.velocity = new Vector3(0f, 0f, 0f); //設置可變參數 SetResetParameters(); } } OK,以上代碼其實大部分都很簡單,但是關於兩個變量invertX和m_InvertMult,我給它們分別取名為「鏡像標誌位」和「鏡像翻轉乘數」。從名字上也可以看出些許貓膩,簡單來講,invertX區分了兩個球拍,且決定了m_InvertMult的值是1還是-1,而m_InvertMult則是一個使得兩個對立的球拍方向統一化的乘數,這樣就可以使得兩個球拍雖然是對手,但是經過鏡像翻轉乘數,實際上轉換後,可以看成兩個球拍都是向同一個方向訓練。
當然在球拍位置初始化、角度初始化時,m_InvertMult也有作用,如下圖:
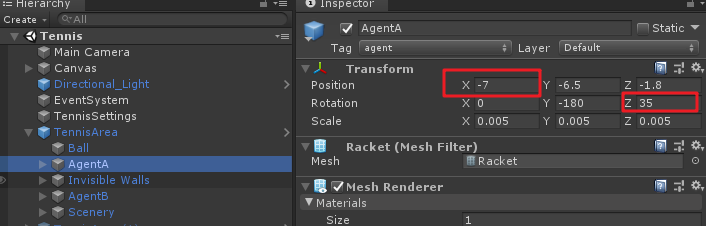
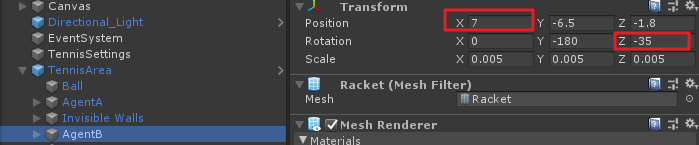
可以看到兩個球拍的TransformX與RotationZ為正負相反,這也是為什麼在上述代碼中,對於球拍初始化位置和角度要乘以m_InvertMult。
矢量觀測空間
我們在之前知道了該示例的觀測空間是Continous類型的,且變量有9個,下面來看一下。
/// <summary> /// 矢量觀測空間 /// </summary> /// <param name="sensor"></param> public override void CollectObservations(VectorSensor sensor) { //球拍與場地的x值相對位置(前後) sensor.AddObservation(m_InvertMult * (transform.position.x - myArea.transform.position.x)); //球拍與場地的y值相對位置(高低) sensor.AddObservation(transform.position.y - myArea.transform.position.y); //球拍x方向的速度 sensor.AddObservation(m_InvertMult * m_AgentRb.velocity.x); //球拍y方向的速度 sensor.AddObservation(m_AgentRb.velocity.y); //球與場地的x值相對位置 sensor.AddObservation(m_InvertMult * (ball.transform.position.x - myArea.transform.position.x)); //球與場地的y值相對位置 sensor.AddObservation(ball.transform.position.y - myArea.transform.position.y); //球x方向的速度 sensor.AddObservation(m_InvertMult * m_BallRb.velocity.x); //球y方向的速度 sensor.AddObservation(m_BallRb.velocity.y); //球拍的旋轉角度 sensor.AddObservation(m_InvertMult * gameObject.transform.rotation.z); } 總體來說,這裡收集了球拍和場地、球和場地的相對位置以及它們各自的速度信息,這裡再利用圖來講一下鏡像翻轉乘數。
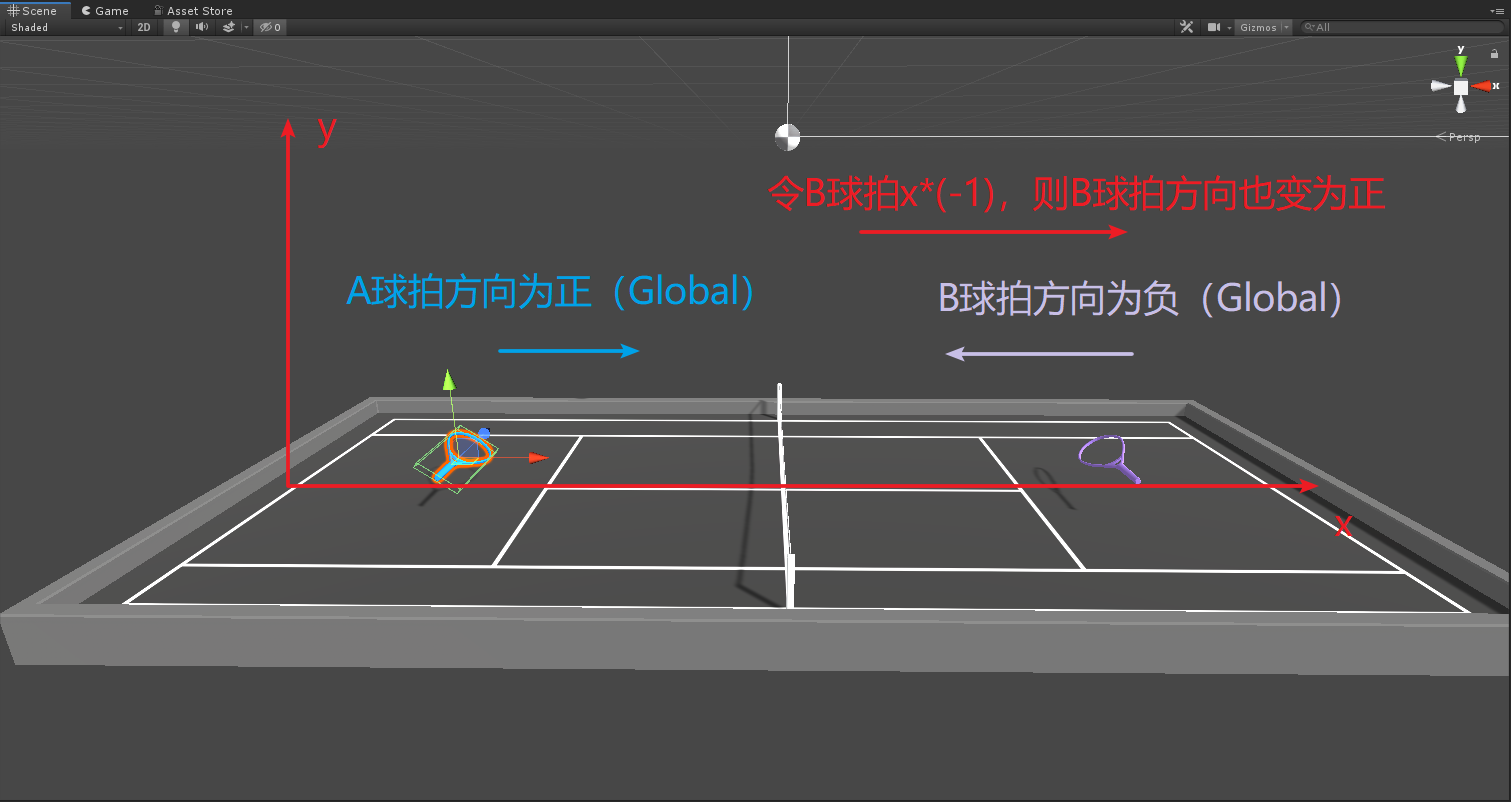
這樣通過m_InverMult,則可以使得兩個球拍輸出的觀察參數變為同向,使得對抗訓練對於一個訓練單元的訓練效果變為double。對於球拍的旋轉角度也是同樣的道理。
Agent動作反饋
下面我們來看代理的AgentAction()方法。
/// <summary> /// agent動作反饋 /// </summary> /// <param name="vectorAction"></param> public override void AgentAction(float[] vectorAction) { //限制球拍x、y方向(左右、上下)乘積係數為-1到1 var moveX = Mathf.Clamp(vectorAction[0], -1f, 1f) * m_InvertMult; var moveY = Mathf.Clamp(vectorAction[1], -1f, 1f); //限制球拍每次旋轉角度乘積係數為-1到1 var rotate = Mathf.Clamp(vectorAction[2], -1f, 1f) * m_InvertMult; //當球拍在較低位置時,且moveY>0.5,則改變球拍向上的速度 if (moveY > 0.5 && transform.position.y - transform.parent.transform.position.y < -1.5f) { m_AgentRb.velocity = new Vector3(m_AgentRb.velocity.x, 7f, 0f); } //改變球拍x(左、右)方向上的速度 m_AgentRb.velocity = new Vector3(moveX * 30f, m_AgentRb.velocity.y, 0f); //改變球拍角度 m_AgentRb.transform.rotation = Quaternion.Euler(0f, -180f, 55f * rotate + m_InvertMult * 90f); //限制球拍向前移動時不要越過網 if (invertX && transform.position.x - transform.parent.transform.position.x < -m_InvertMult || !invertX && transform.position.x - transform.parent.transform.position.x > -m_InvertMult) { transform.position = new Vector3(-m_InvertMult + transform.parent.transform.position.x, transform.position.y, transform.position.z); } m_TextComponent.text = score.ToString();//計分牌刷新 } AgentAction()代碼內容也不算太難,主要還是注意對於對抗的兩方,通過invertX和m_InvertMult來使得對抗兩方同向化。
小小提一下,在最後「限制球拍向前移動時不要越過網」部分,如果以agentA為例,此時invertX=false,m_InvertMult=1,則當滿足
(!invertX && transform.position.x - transform.parent.transform.position.x > -m_InvertMult)時,有如下情況:
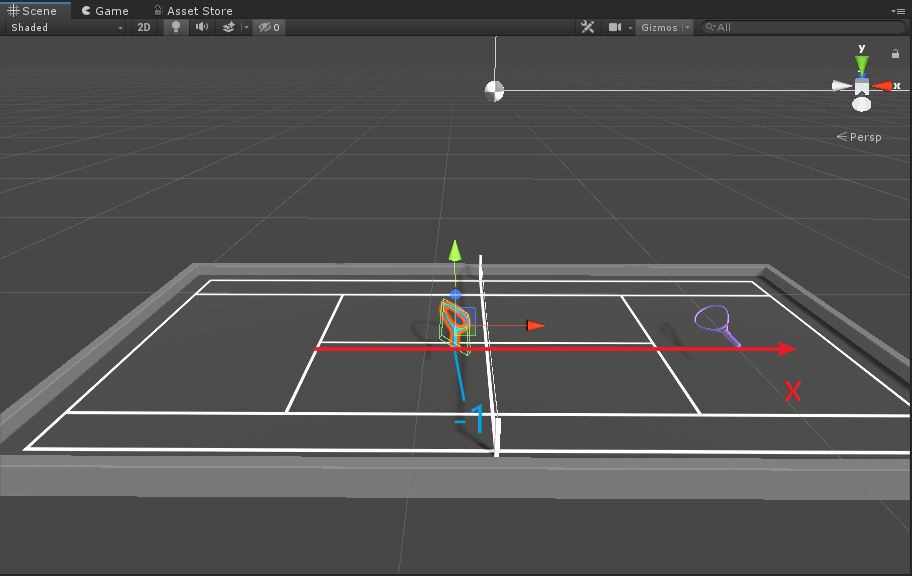
可以看到,當球拍再向前的話,就會碰到網上,因此需要限制球拍不能越過網。agentB紫色球拍也是一樣的情況,只是數值相反。
在這裡深入思考一下,為什麼只有限制球拍向前移動,而不用去限制球拍向後移動?可能大家也有相應的疑問,其實這裡利用兩個碰撞體就可以限制球拍的移動了,即網的碰撞體以及場地後方碰撞體:
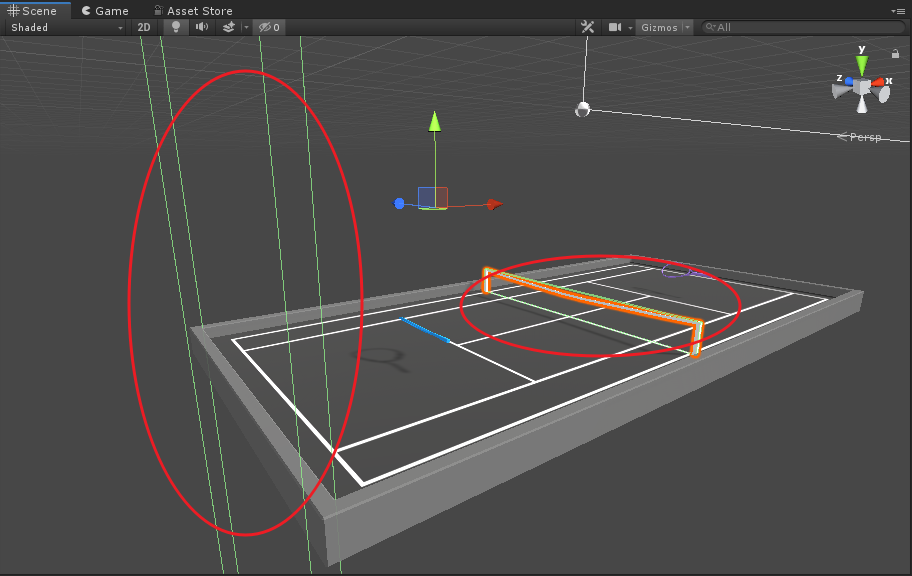
但是你會發現網的碰撞體只有在球拍在低處時才能限制球拍向前移動,而將代碼注釋之後,球拍在空中時就會發生:
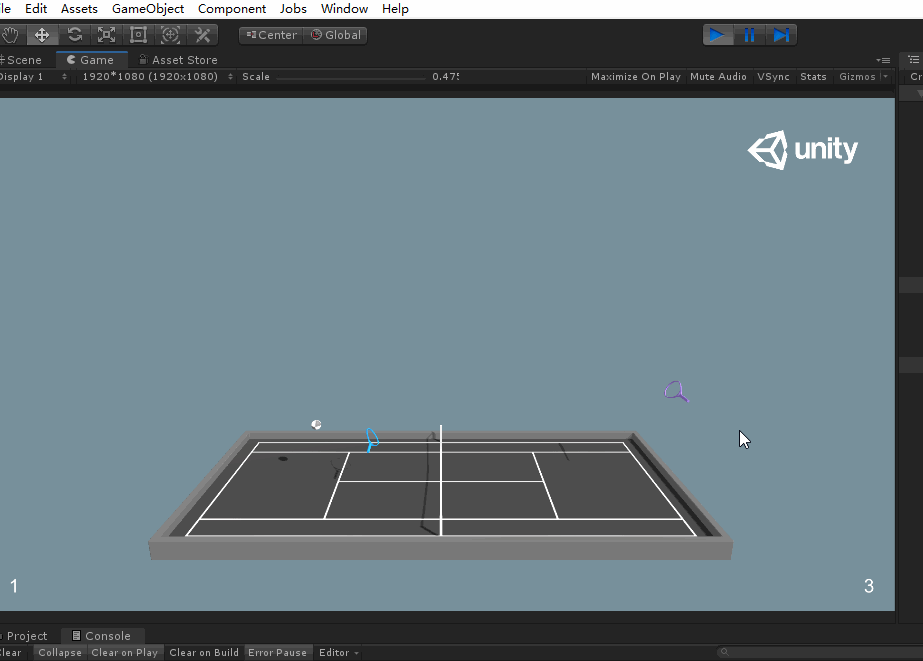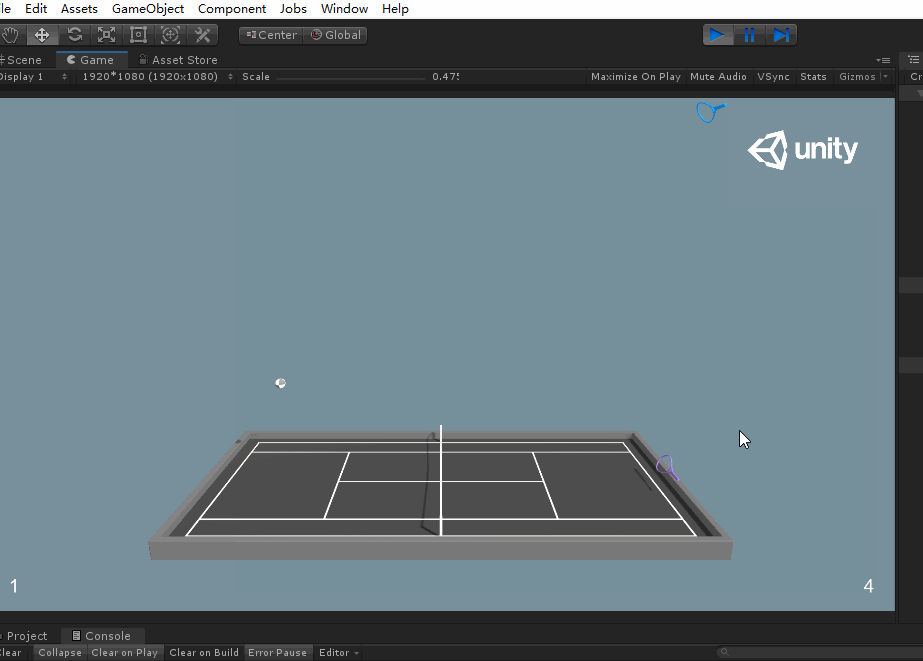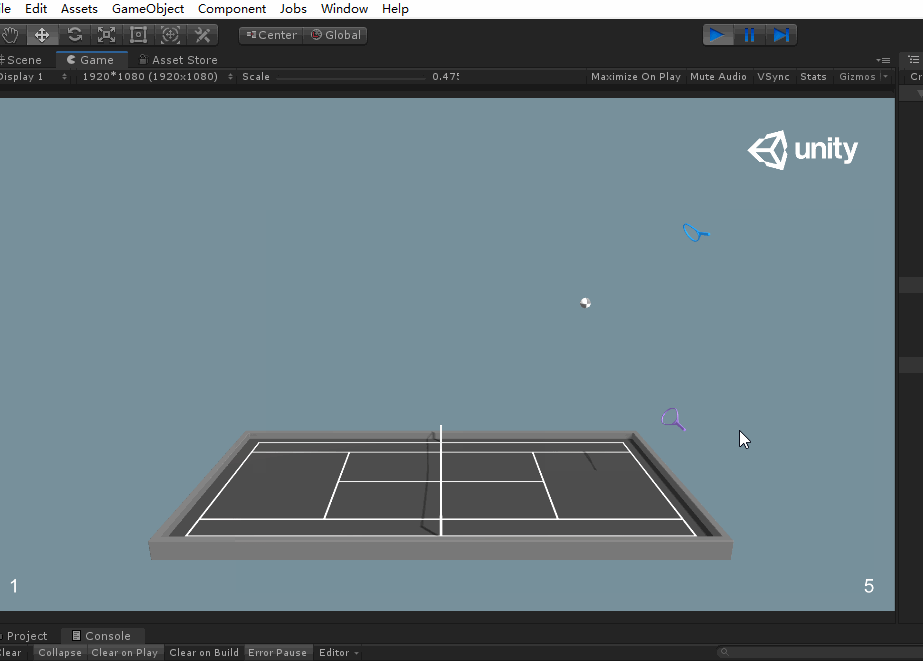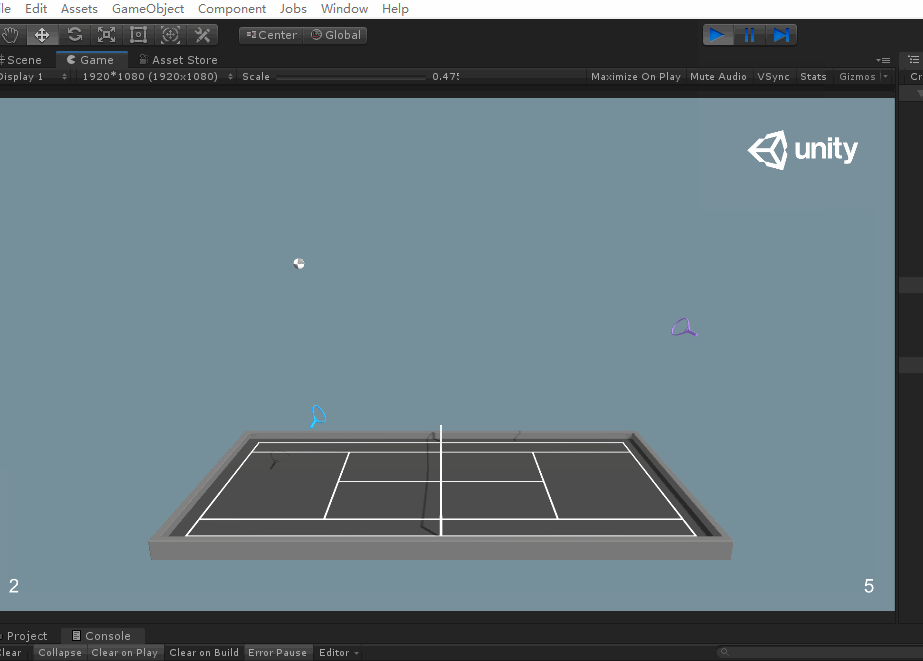
可以看到,你可以控制球拍去對面胖揍對手= =||||。所以這裡只用對球拍在自身向前的方向進行限制即可。
Agent手動操控
下面來看一下Heristic()函數:
/// <summary> /// 手動操控 /// </summary> /// <returns></returns> public override float[] Heuristic() { var action = new float[2]; action[0] = Input.GetAxis("Horizontal");//左右移動控制 action[1] = Input.GetKey(KeyCode.Space) ? 1f : 0f;//空格使球拍飛起 return action; } OK,以上代碼很簡單,但是有一個問題,當你想操作球拍和電腦對打時,將一個球拍的Behavior Type置為Heuristic Only後,開始遊戲,你會發現以下錯誤:

這裡是說agent的返回的矢量動作空間數量有問題,如果你比較熟悉ML-Agents之後,你會發現在AgentAction(float[] vectorAction)中,vectorAction[]數組有三個元素,分別控制了球拍的x、y方向移動以及球拍的繞z軸的旋轉。而在以上Huristic()代碼中,action[]數組只有兩個元素,只控制了球拍的x、y方向移動,缺少繞z軸的旋轉的行為參數。
因此,這裡只需要將AgentAction()方法中的兩句代碼注釋:
var rotate = Mathf.Clamp(vectorAction[2], -1f, 1f) * m_InvertMult;
以及
m_AgentRb.transform.rotation = Quaternion.Euler(0f, -180f, 55f * rotate + m_InvertMult * 90f);
注釋後,就可以進行手動操作了,當然如果你也相同時操作球拍旋轉,也不是不可以,你可修改手動操控代碼如下:
/// <summary> /// 手動操控 /// </summary> /// <returns></returns> public override float[] Heuristic() { var action = new float[3]; action[0] = Input.GetAxis("Horizontal");//左右移動控制 action[1] = Input.GetKey(KeyCode.Space) ? 1f : 0f;//空格使球拍飛起 action[2] = Input.GetAxis("Vertical");//控制球拍旋轉 return action; } 五、訓練
我們這次訓練Tennis的模型,主要包含以下幾種:正常訓練(不帶可變參數)、帶兩個可變參數(scale、gravity)訓練、只帶一個可變參數(scale)不注釋代碼、只帶一個可變參數(scale)注釋代碼。
大家應該還記得我們在上述四、代碼分析中的環境初始化腳本一小節,提到在MatchReset()函數中重置小球比例是不合適的,因此我們來驗證一下這個想法是否正確。
接下來,我們先進行一組正常訓練;然後在利用兩個可變參數訓練之前,先驗證MatchReset()中設置小球比例會不會使得小球比例的可變參數設置失效;最後,我們再進行帶兩個可變參數的訓練。
普通訓練(不帶可變參數)
我們先來普通訓練一次,之前已經重複過很多次的操作~我們cd到ml-agent的目錄,然後輸入以下命令(當然這裏面有一些配置文件、訓練結果的路徑,可以自行修改):
mlagents-learn config/trainer_config.yaml --run-id=Tennis_Normal --train
因為在訓練配置文件trainer_config.yaml中可以看到Tennis的max_steps為5.0e7,即五千萬步,是所有例子中訓練最大步數最大的。而之前我們的3D Ball才五十萬步,前者是後者的100倍,所以訓練時間相當長。
實際我訓練過程中,大概到100萬步的時候的效果就很不錯了,因此我將Tennis的max_steps改成了5.0e6。
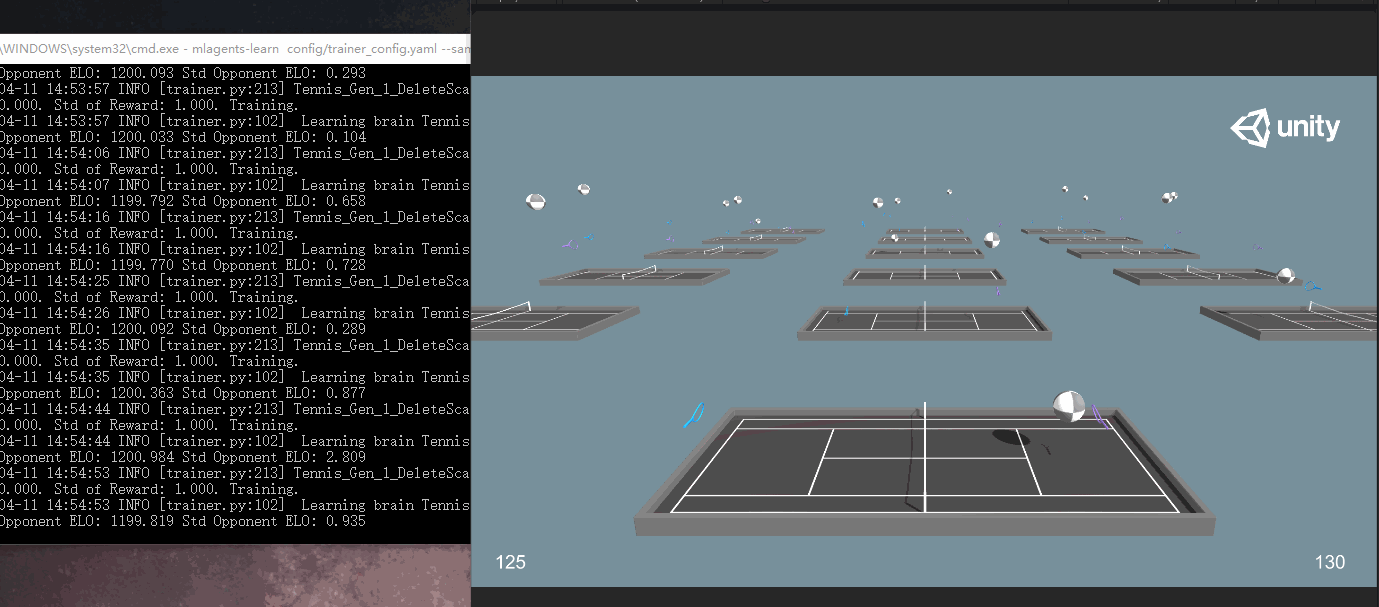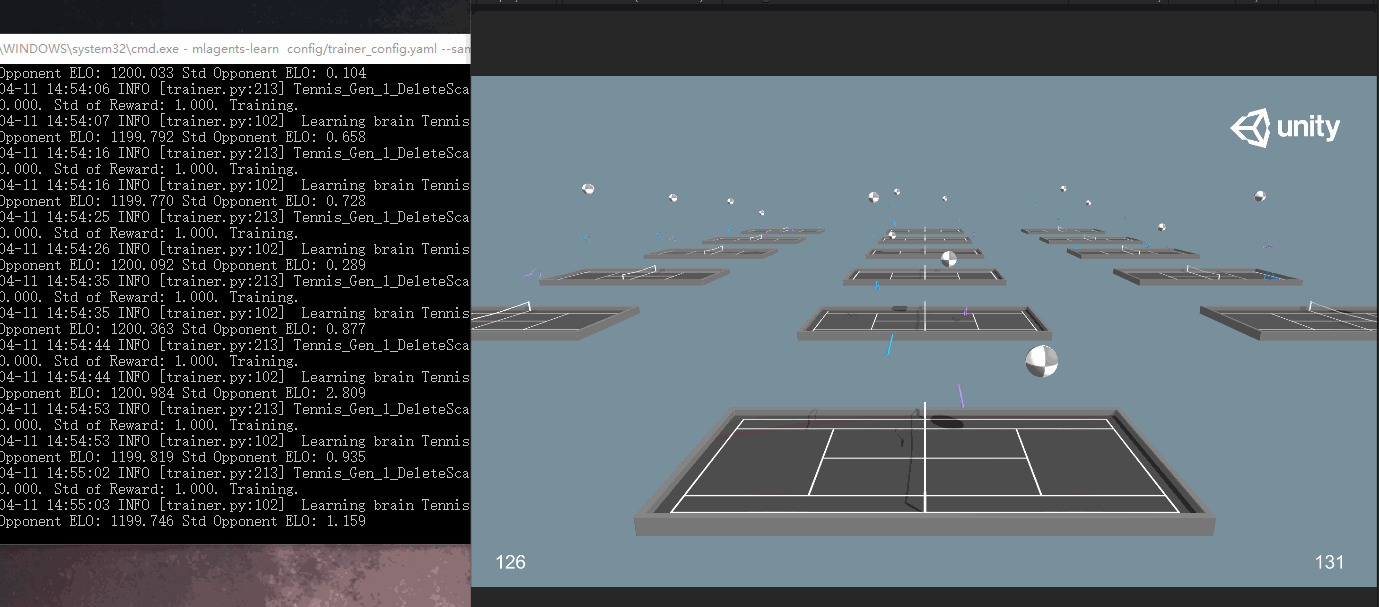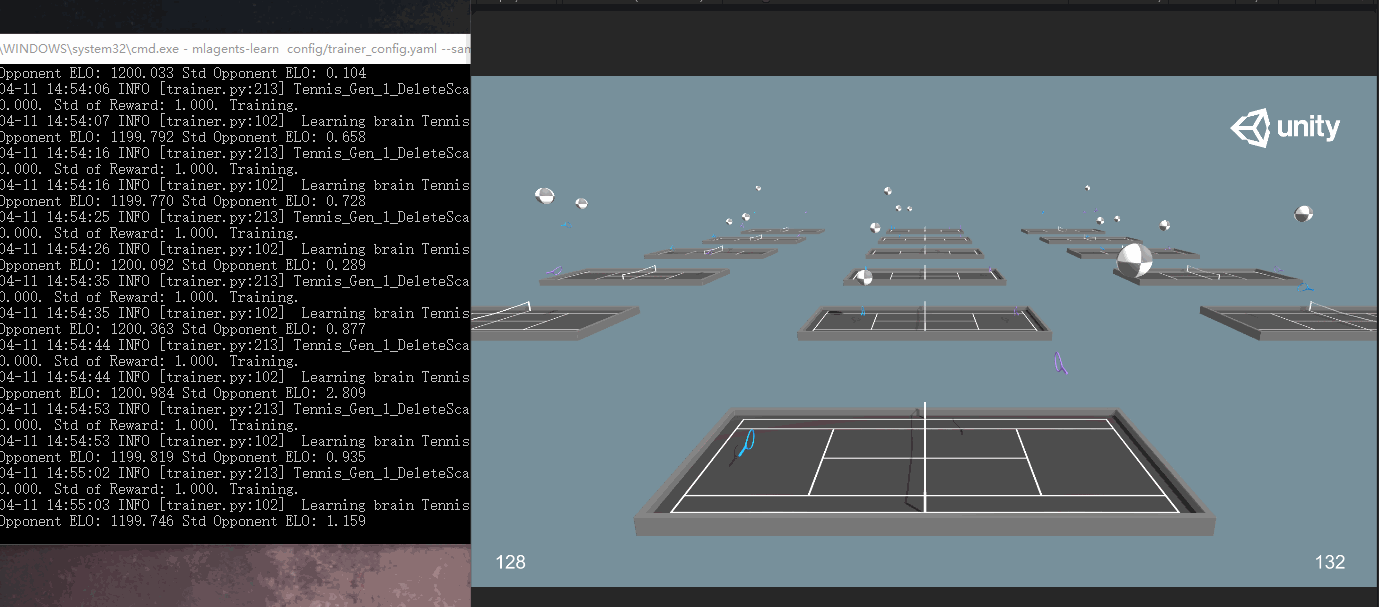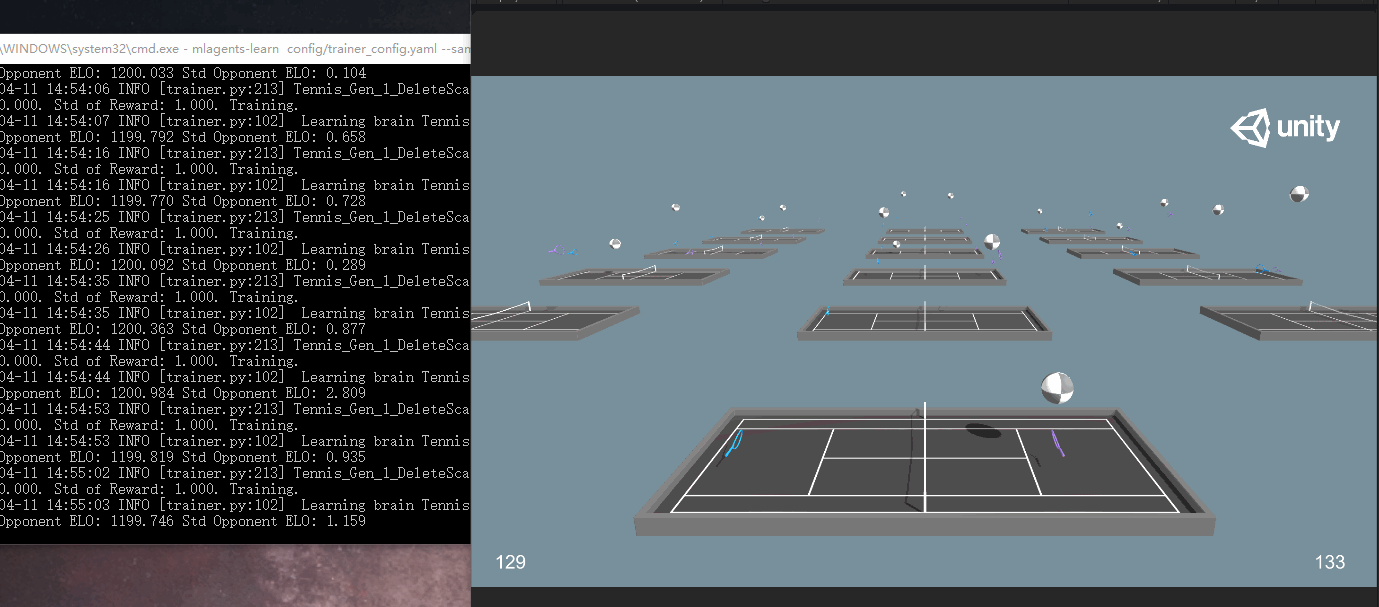
此次訓練次數較多,訓練時間比較長,放一張訓練的過程截圖:
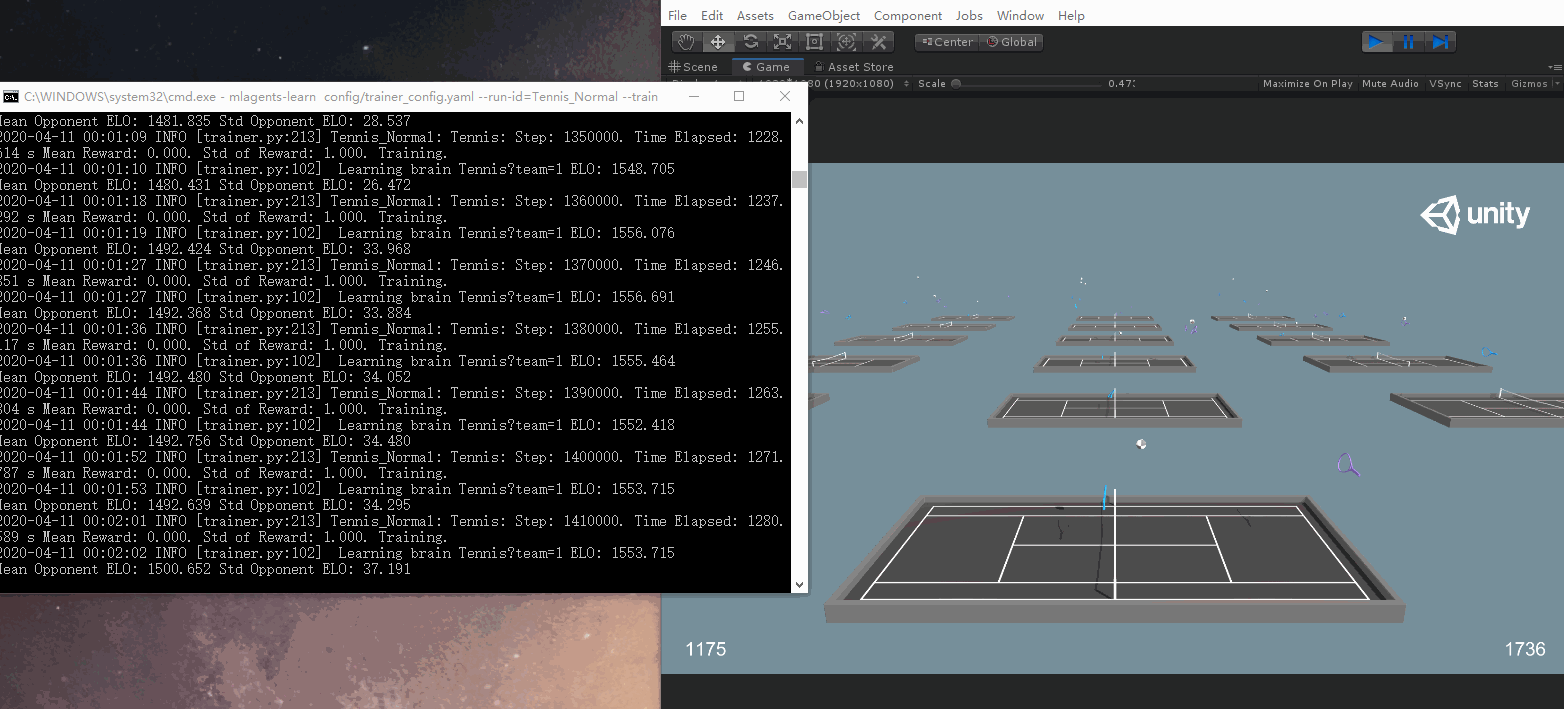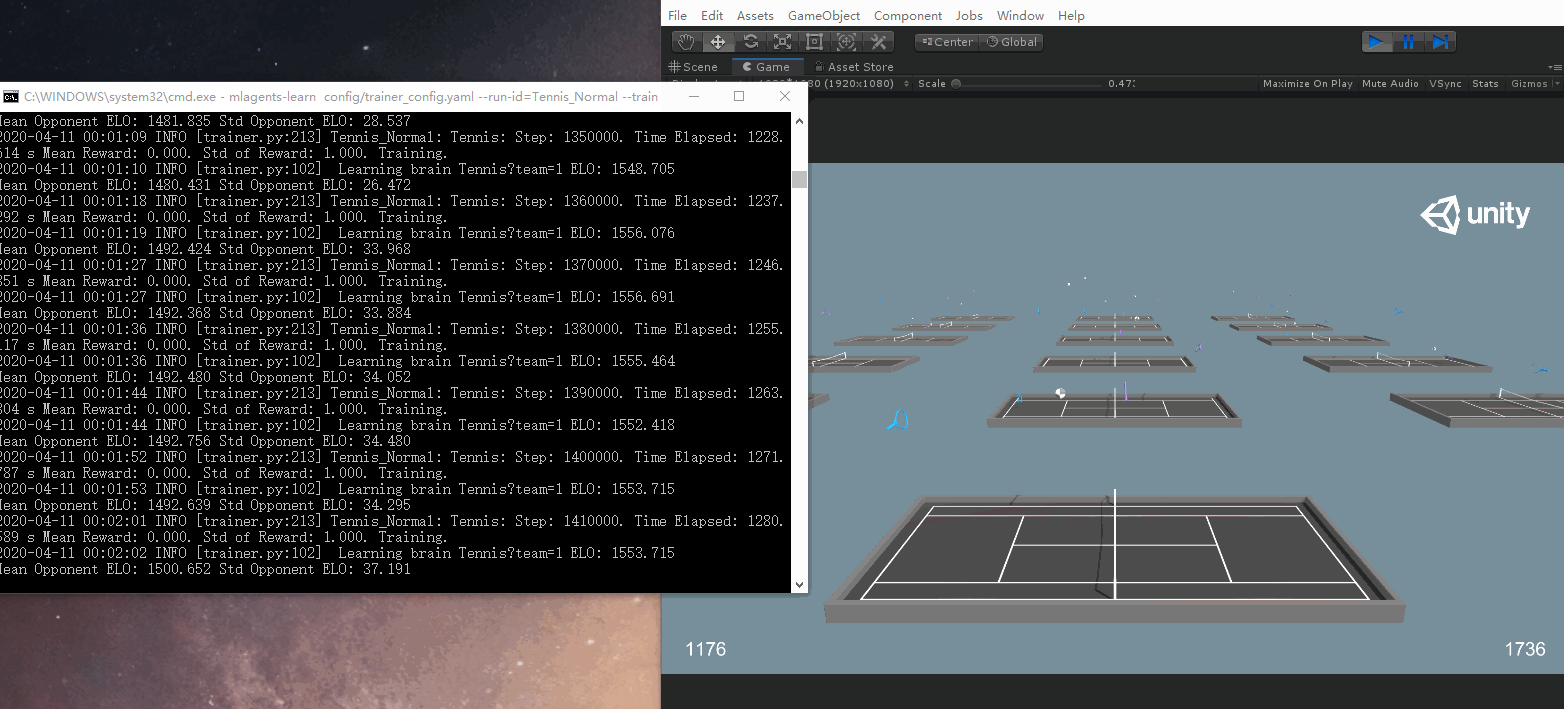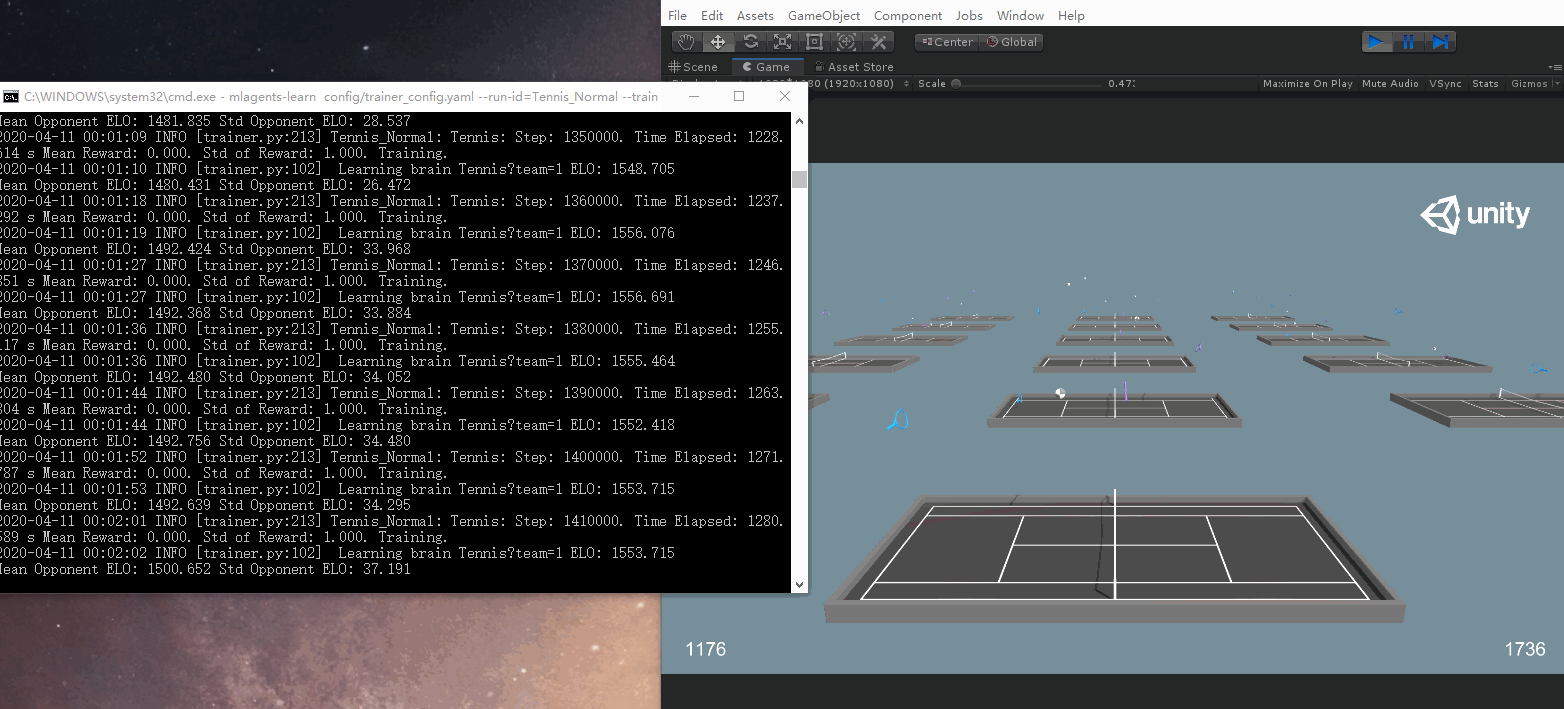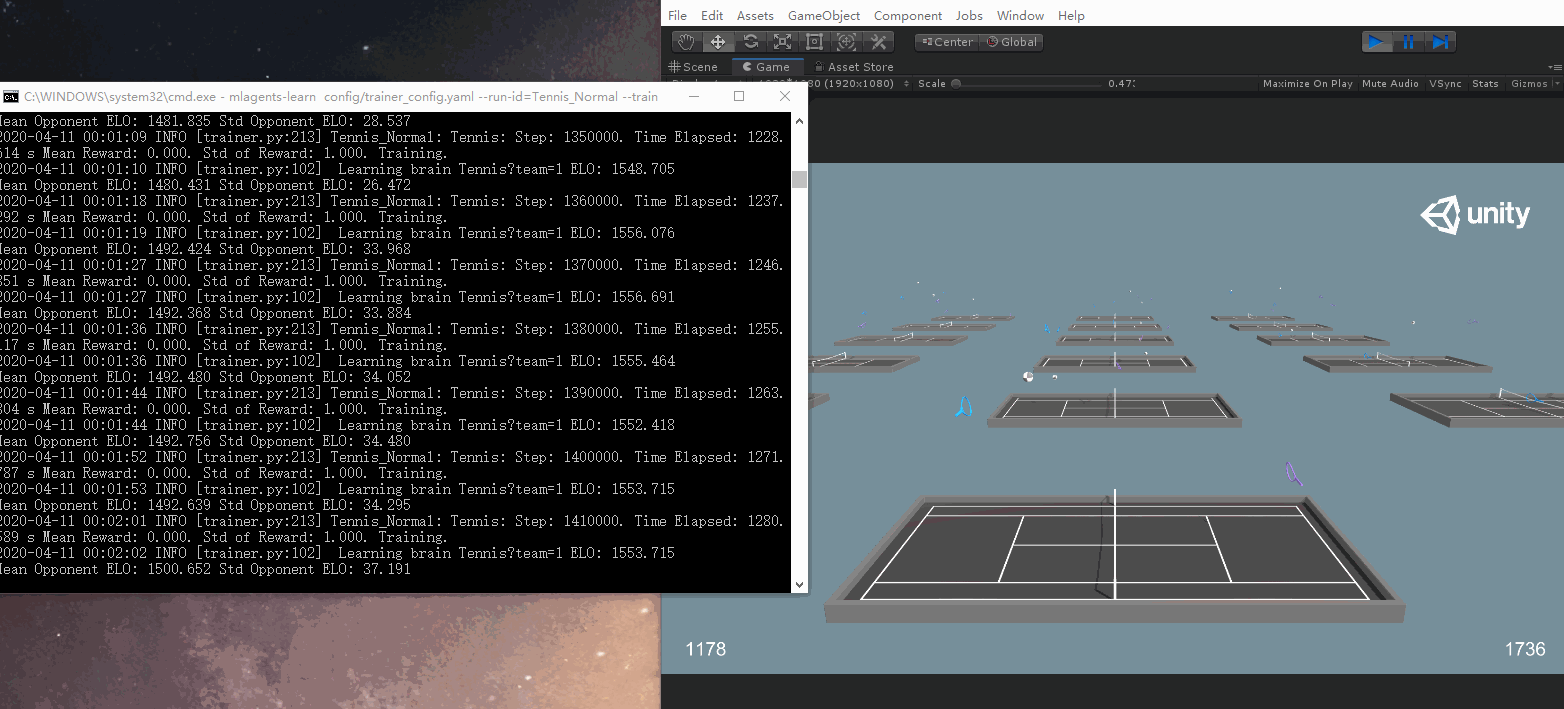
可以大概看到兩邊打的有來有回,同時可以在屏幕下方看到雙方的得分。
同時觀察命令行輸出:
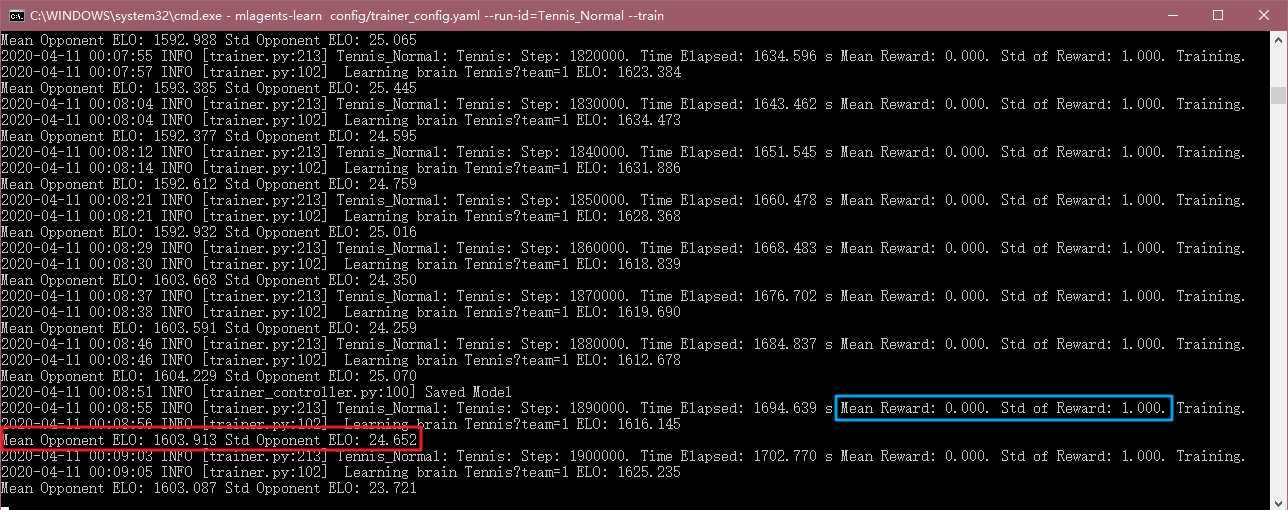
在之前訓練中,Mean Reward和Std of Reward是衡量訓練效果的很重要的兩個標準,一般來講是逐漸上升的,而這裡一直是0和1,相應的有兩個其他的參數代替:Mean Opponent ELO和Std Opponent ELO。
經過查閱資料,首先了解一下ELO是什麼:ELO等級分制度是指由匈牙利裔美國物理學家Elo創建的一個衡量各類對弈活動水平的評價方法,是當今對弈水平評估的公認的權威方法。
其實我們用簡單的話來講,例如早先英雄聯盟有排位分,你的排位分就是利用ELO計算出來的。如果你贏了比你分數更高的對手,你的排位分就會增加更多;如果輸給比你分數更少的對少,那你排位分就會減少的更多。更詳細的計算方法大家可以去查資料,這個知識點還挺有意思的,可以了解排位分大概是怎麼算出來的。
通過對ELO的了解,也可以發現,這裡因為用到了對抗訓練,所以採用Mean Opponent ELO和Std Opponent ELO來看訓練的效果,其中我們會發現命令行中有一行是Tennis?team=1 ELO:1615.145,這裡其實就代表了team為1的agent(即球拍B),現在它的ELO(可以簡單理解為排位分)是1615.145,你會發現它的ELO會隨着訓練的進行逐漸升高,相當於一直打排位,訓練自己上王者。
【Warning】等待了大約48分鐘,訓練到大概三百萬步時,突然發現如下情況:兩個球拍不對打了,罷工了!大概的情形就是兩個球拍一開始就一起移動到網前,讓球直接落地,然後立馬開始新的一局,可以之後的截圖。此時立馬Ctrl+C停止訓練。我們可以看一下tensorboard的情況:
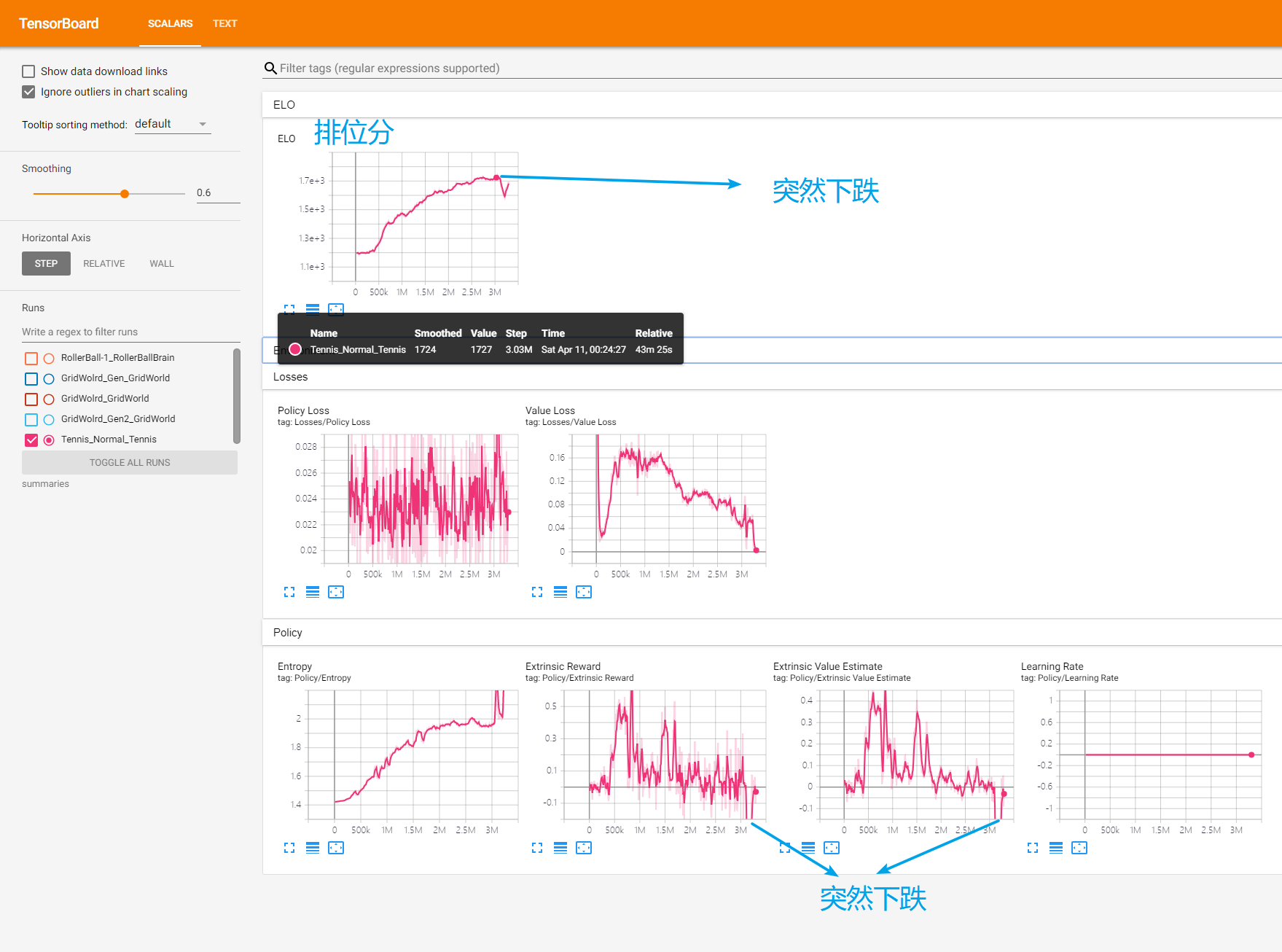
首先是對抗訓練中會存在ELO圖表,其實你就可以看成是排位分的變化趨勢,可以明顯觀察ELO在大概在3百萬步時突然下跌,包括Reawd也是,在3百萬步處有異常數據。將訓練到一半的Tennis_Normal.nn文件放到Unity中:
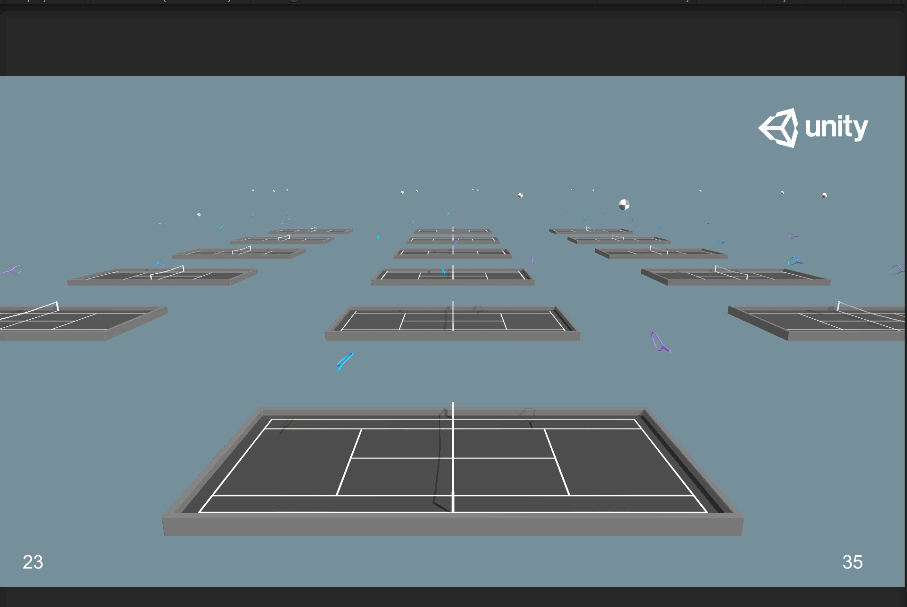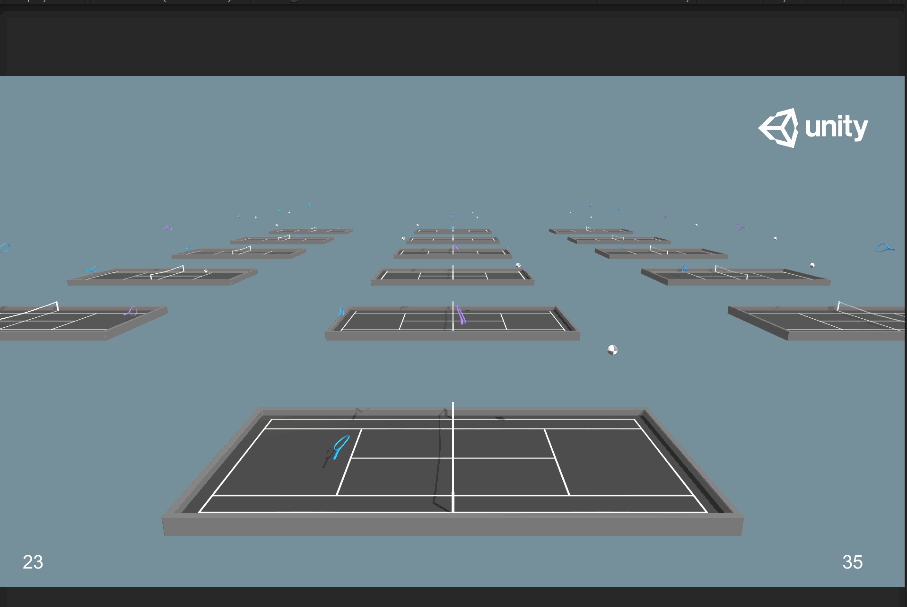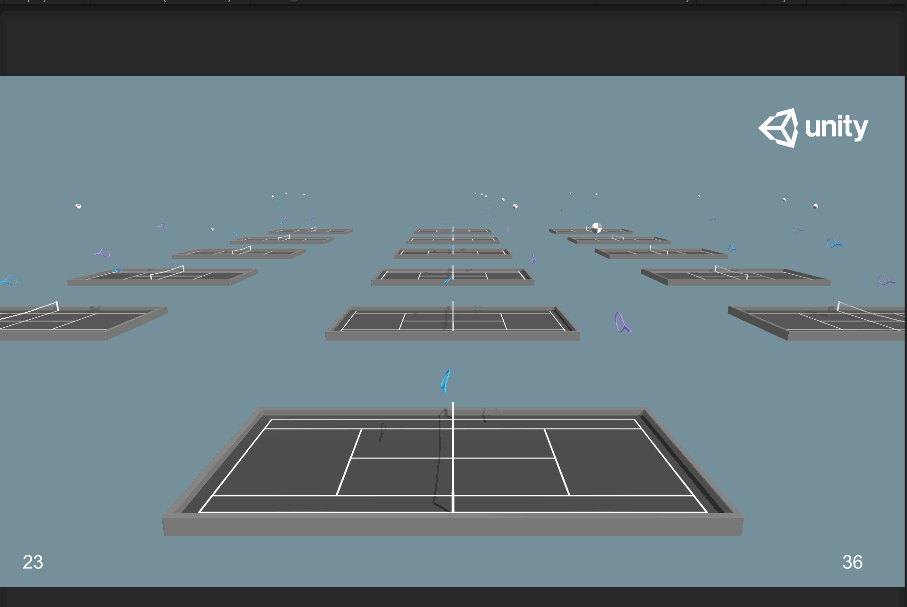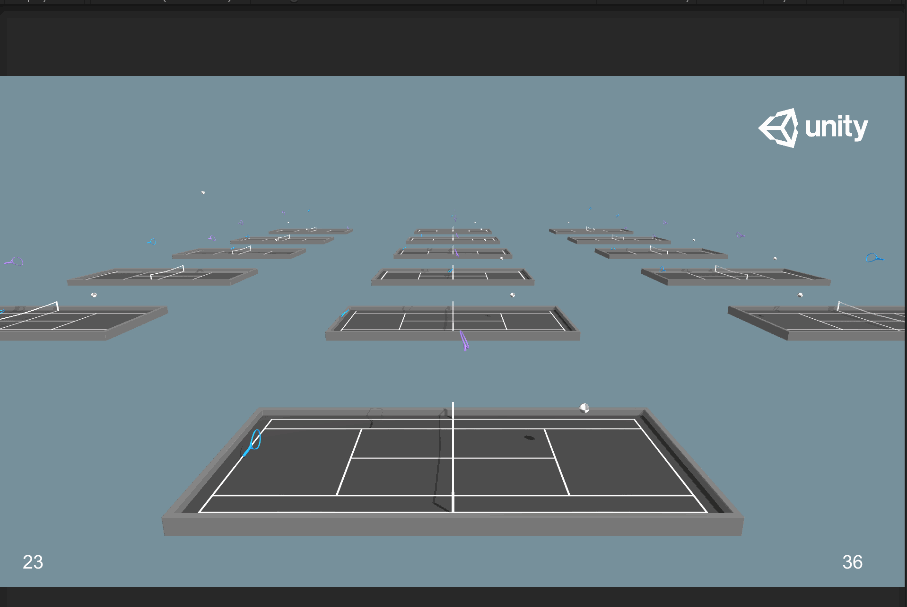
發現兩個球拍在一開始就往網前跑,給對手送分。看來利用Ctrl+C還是沒能將上一次的訓練模型拯救下來= =。
這裡我懷疑是這樣的,因為在代碼中,沒有設計在訓練過程中,如果對抗雙方在一局裡長時間來回打球,而給雙方同時獎勵的機制。當接近3百萬時,雙方的球技都挺好了,能打的有來有回的時間越來越長,導致長時間Brain沒有收到獎勵,使得Brain發現如果一直打可能一直都不能得分,自己的排位也上不去,但是如果丟球,還有機會拿獎勵分,致使Brain產生消極比賽送分的決策= =||||,這裡也是很逗了。所以我將tennis的訓練最大步驟設置為2.5e6差不多到達此時情況下ELO的最大值,正所謂是實踐出真知啊。
從這也可以看到,訓練的最大步數並不是越大越好,還要基於你考慮的是否周全。而且在訓練前,應該竟可能設置好矢量觀測空間以及其他條件,運行一段時間後及時查看訓練效果,不要訓練太長時間發現沒有效果還硬着頭皮訓練,也不要一開始訓練只訓練較少步數沒有效果就換參數。
再次訓練一次最大訓練步數為2.5e6的:
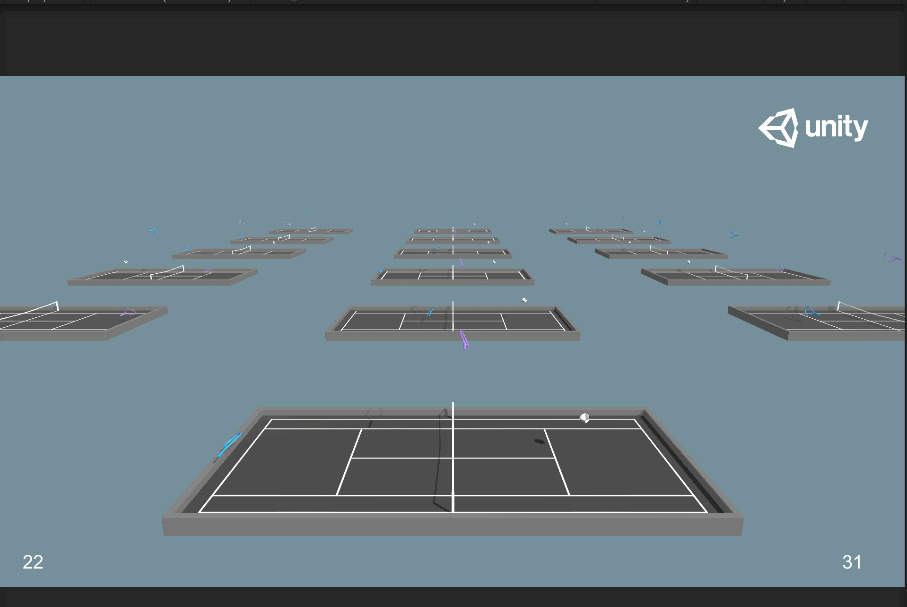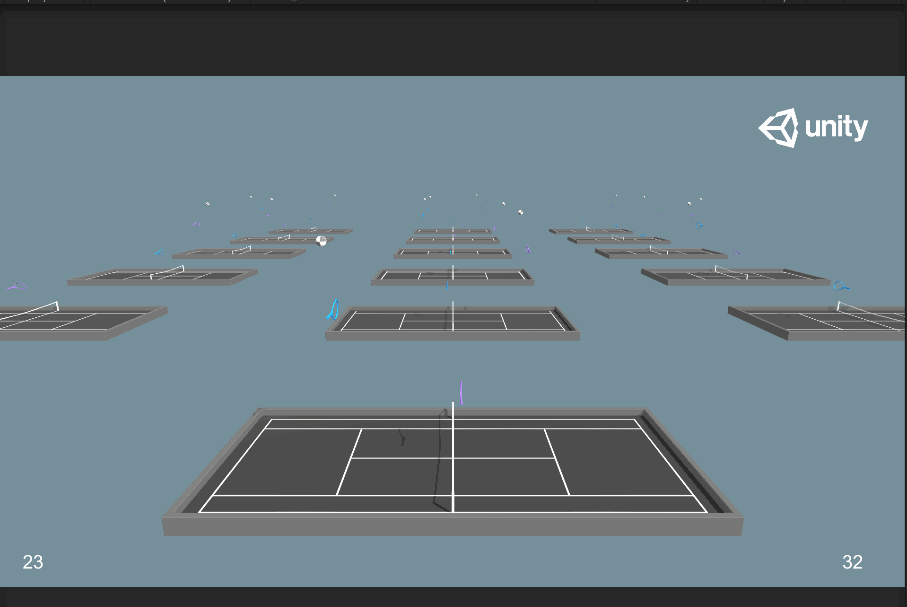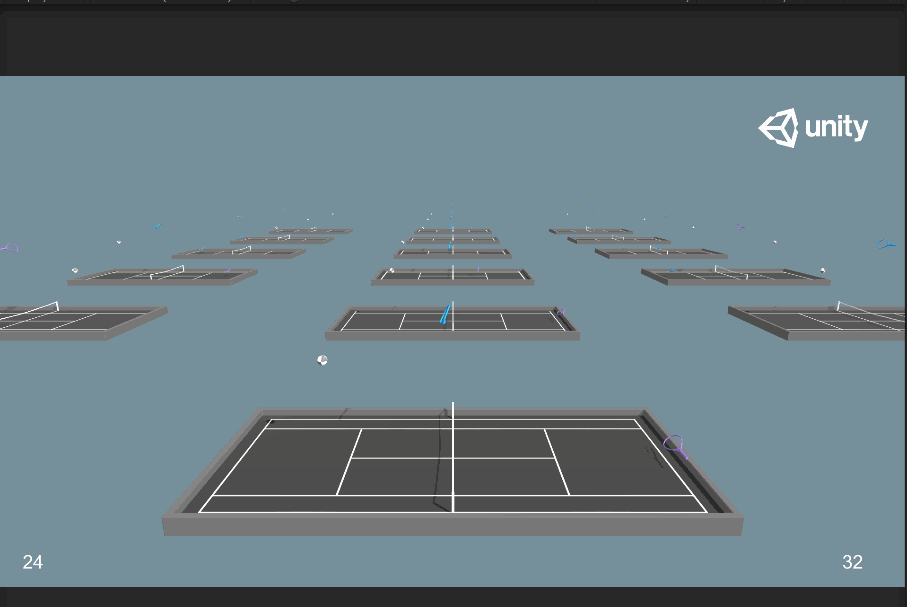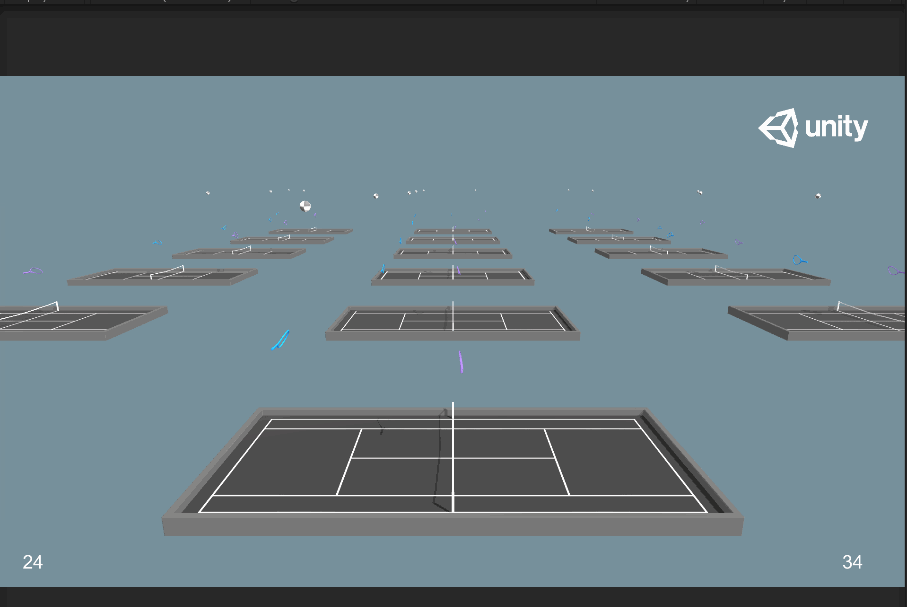
會發現訓練出來的模型還是有問題,然後我繼續調整最大訓練步數為2.0e6,對比一下tensorboard:
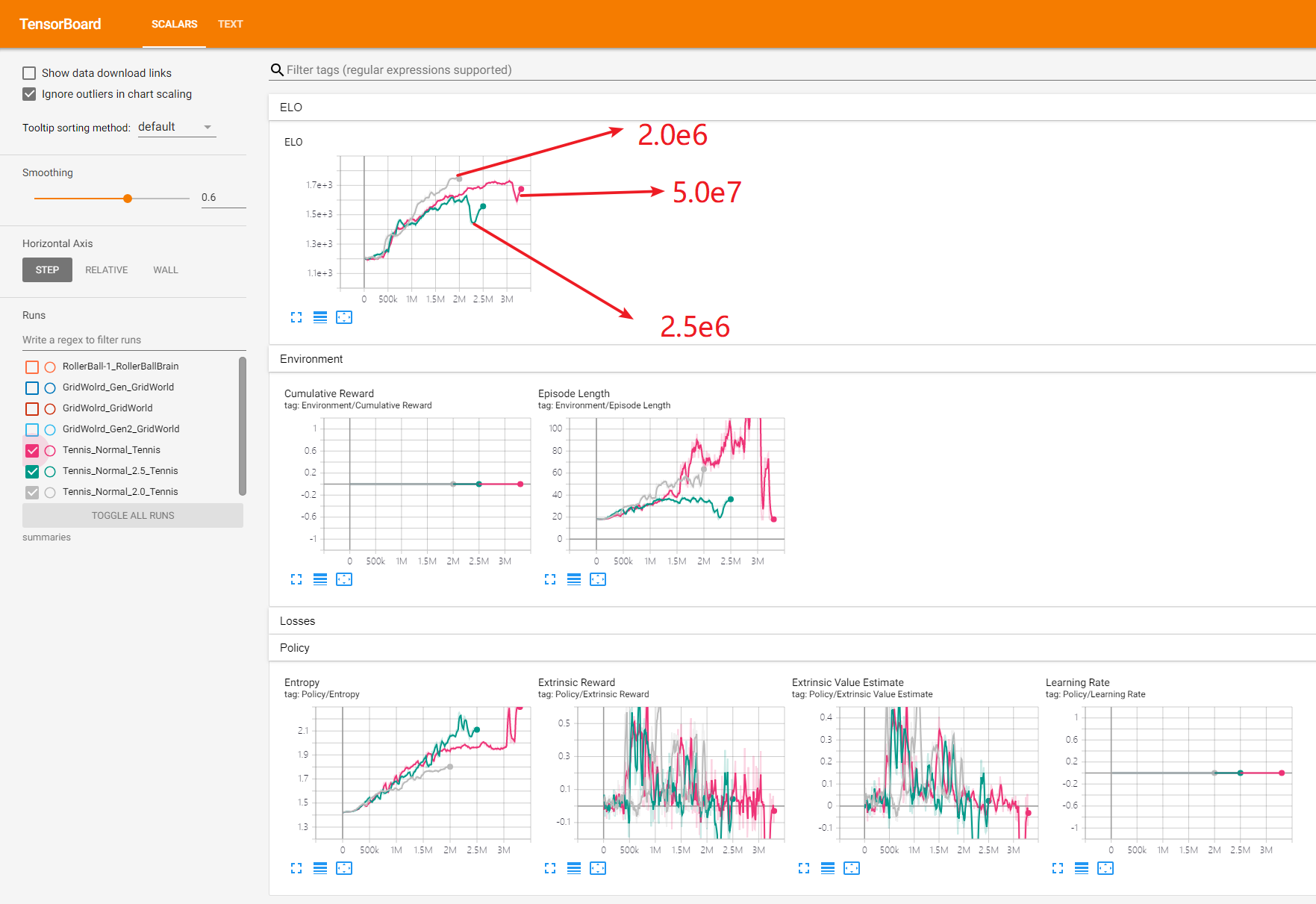
我們從圖表裡發現,2.5e6s的訓練模型在大概2.1M步驟的時候Brian又罷工了,訓練的隨機性還是比較大,在最大訓練步驟5.0e7時明明在3M左右才開始罷工。。。。
我們把2.0e6的訓練模型放到Unity中去,訓練效果如下:
其實還蠻奇怪的,從訓練效果來看,2.0e6是比5.0e7及2.5e6正常一些,但是如果訓練步驟太長又會出現Brain罷工的情況,所以我也比較好奇官方Tennis給出的訓練模型是如何訓練出來的,是不是有一些什麼設置我們漏了。這裡要是有人知道的話也可以留言討論交流~下面我們還是繼續別的訓練。
可變參數設置
以前的文章里我們稱可變參數為泛化參數,是因為ml-agents官方改了,因此我們以後就把「泛化參數」統一稱作「可變參數」。可變參數我們這次按官方推薦的來設置,先來看一下Tennis的可變參數配置:
tennis_generalize.yaml
resampling-interval: 20000 scale: sampler-type: "uniform" min_value: 0.2 max_value: 5 gravity: sampler-type: "uniform" min_value: 6 max_value: 20 注意gravity參數的設置是在ProjectSettingOverrides.cs腳本里的:Academy.Instance.FloatProperties.RegisterCallback("gravity", f => { Physics.gravity = new Vector3(0, -f, 0); });來設置的。
此外,我們將resampling-interval設置為20000,是由於在trainer_config.yaml配置文件中,Tennis的訓練步驟我們設置的是2.0e6步,參照3D Ball,5.0e5次,可變訓練間隔為5000,依此參照,設置Tennis的這個參數為20000。當然這樣參照設置不一定適合,在訓練過程中如果想將某參數改變引入可變,那麼在改變前的參數對應的訓練效果應該是基本成型的,如果訓練還么有成型就改變參數,有可能造成因為一直改參數使得訓練效果一直不佳。就和做軟件一樣,如果軟件需求一直更改,那麼等到軟件成型出產品基本就等到猴年馬月了。
一個可變參數訓練
為了驗證MatchReset()中是否需要設置小球比例的問題,我們新增可變參數配置文件:
tennis_generalize_1.yaml
resampling-interval: 20000 scale: sampler-type: "uniform" min_value: 0.2 max_value: 5 將gravity參數去掉,用來消除gravity改變帶來的影響。我們先試驗注釋代碼後的效果,在命令行中輸入:
mlagents-learn config/trainer_config.yaml --sampler=config/tennis_generalize_1.yaml --run-id=Tennis_Gen_1_DeleteScale --train
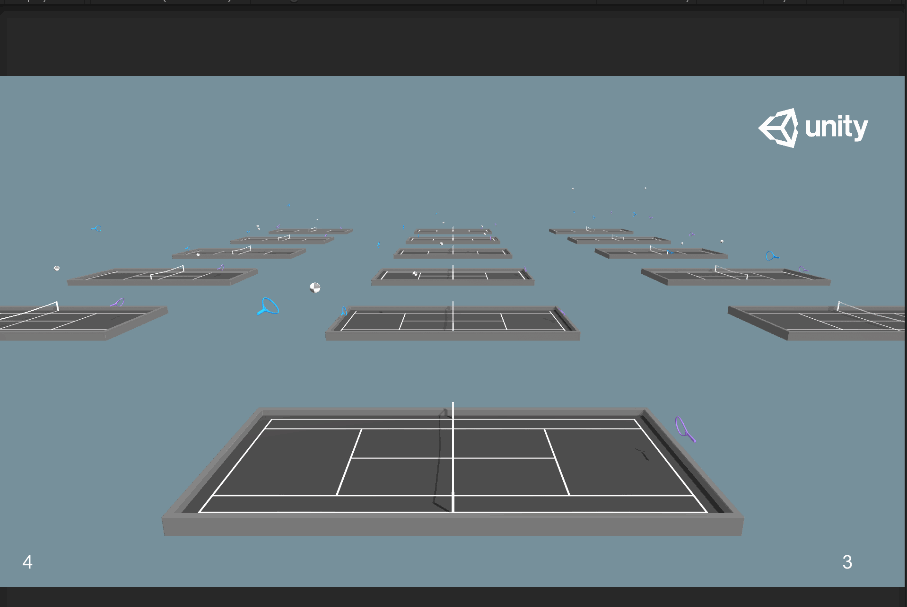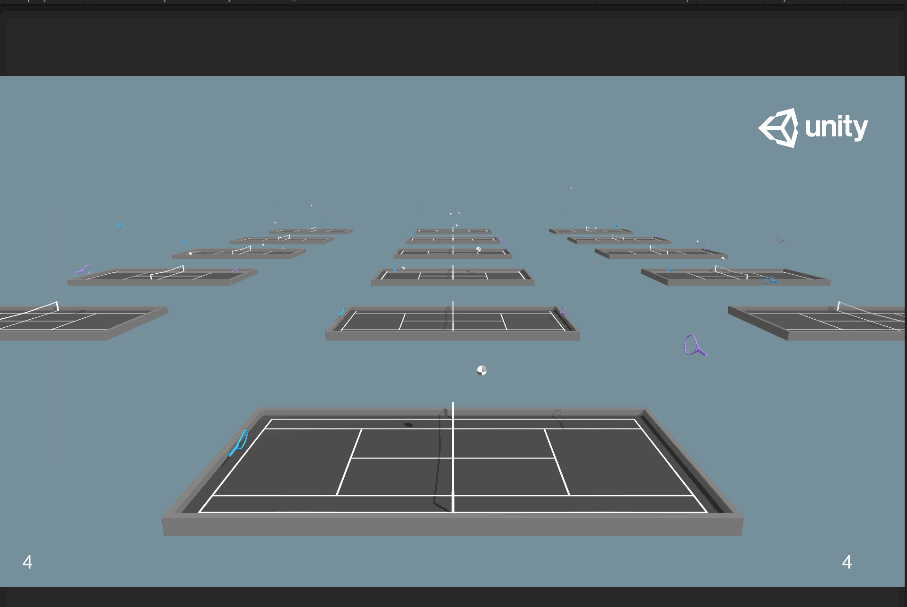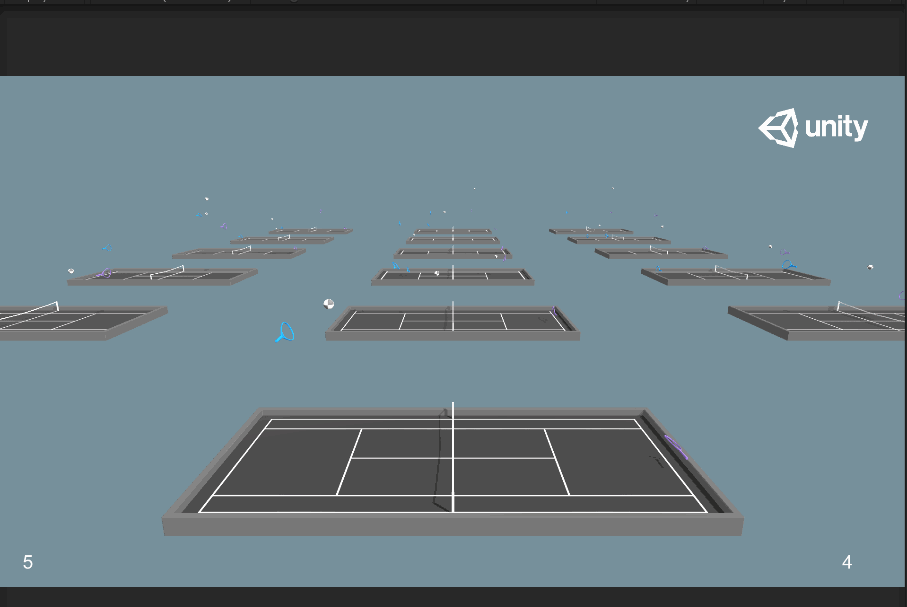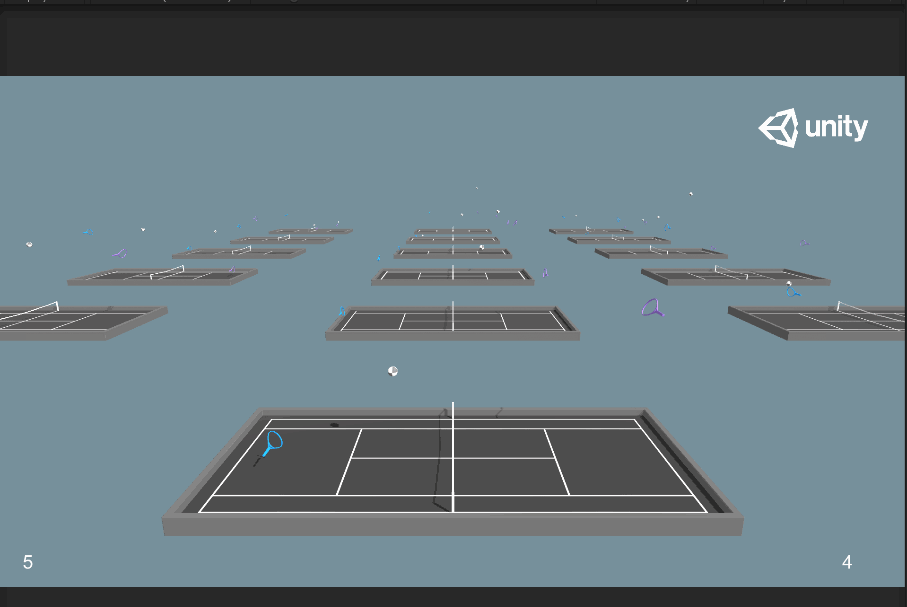
訓練截圖如下:
可以明顯看到一開始球的大小有改變。訓練結束後,再將代碼取消注釋,命令行中輸入如下命令進行訓練:
mlagents-learn config/trainer_config.yaml --sampler=config/tennis_generalize_1.yaml --run-id=Tennis_Gen_1_ModifyScale --train
會發現小球的大小在訓練過程中,有時候一開始會變大或者變小,但是會立馬變為正常大小進行訓練,這也符合我的想法,即MatchReset()會在SetResetParameters()之後將小球的比例複位成0.5。在相同訓練配置下,代碼注釋後的訓練相比代碼注釋前的訓練,會使得小球比例改變,從而也就證明了MatchReset()中設置小球比例在可變參數訓練中是不應該的的。
兩個可變參數訓練
我們利用兩個可變參數的配置文件,輸入以下命令(當然這裏面有一些配置文件、訓練結果的路徑,可以自行修改):
mlagents-learn config/trainer_config.yaml --sampler=config/tennis_generalize.yaml --run-id=Tennis_Gen --train
等待訓練完成後,查看tensorboard圖表:
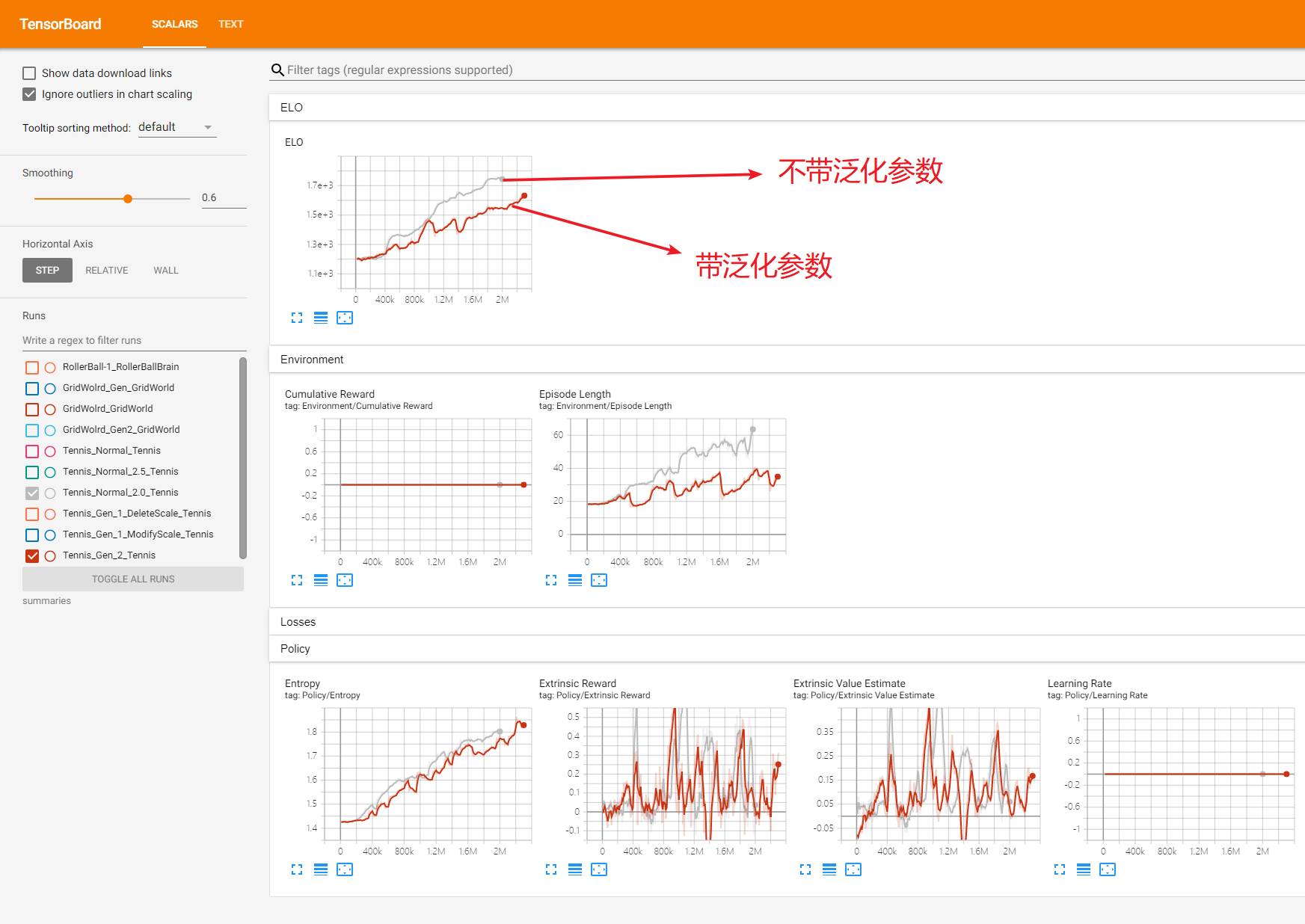
可以看出,與不帶可變參數的訓練,帶可變參數的訓練其中還是有一些波折的,波折基本就代表了參數改變使得agent的ELO下降,這裡的訓練數據僅僅作為一個參考吧。把訓練模型放到Unity中效果依然不是很好,這裡就不展示了。
總結
這次的Tennis示例研究,主要時間都消耗到訓練上,最終也沒有訓練出和官方一樣的效果,這點還是有點遺憾,我認為應該是獎勵規則有漏洞的原因,具體在第五節已經寫了,當然也有可能是我哪裡設置錯了。不過在這個過程中已經有挺多經驗值得學習和記錄了,過程還是比較有意思,因此這個示例的研究先到這,說不定後面研究更多的示例就會豁然開朗了。
寫文不易~因此做以下申明:
1.博客中標註原創的文章,版權歸原作者 煦陽(本博博主) 所有;
2.未經原作者允許不得轉載本文內容,否則將視為侵權;
3.轉載或者引用本文內容請註明來源及原作者;
4.對於不遵守此聲明或者其他違法使用本文內容者,本人依法保留追究權等。

