鏈表的簡單理解
- 2020 年 4 月 10 日
- 筆記
鏈表
通過與數組相對比來理解鏈表,數組是一組連續的地址可以通過順移來遍歷,相對的鏈表是一組不連續的地址塊,每個地址塊都存儲了下一個地址塊的地址,可以通過這個存儲的地址來進行迭代,就像很多個連起來的數組,這樣解決了數組的擴容問題,用鏈表擴容的時候再也不需要,重新找一大塊位置了,只需要找到一個地址塊(Node)的大小就夠了,這也就帶來了一個缺點,因為這些Node不是連續的,想要直接讀取其中一個Node就要從頭節點(Head)開始一個一個迭代,這就不如數組可以直接通過對地址進行增加操作直接訪問,而且增加了存儲下一個節點地址數據的位置,使得存儲同樣的數據,鏈表佔用內存更大。
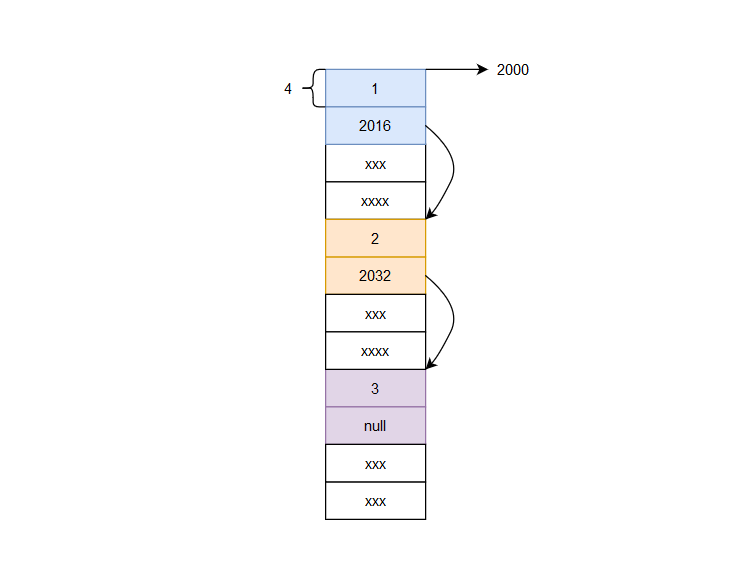
我們從鏈表頭指針一個一個向下,就可以遍歷整個鏈表,但是有一個缺點,只能前進,不能後退,這缺點有點太大了吧, 用指向下一個Node的指針來訪問下一個Node,那麼我們要訪問前一個Node,怎麼辦,自然是需要一個指向前一個Node的指針了,這就是雙(向)鏈表
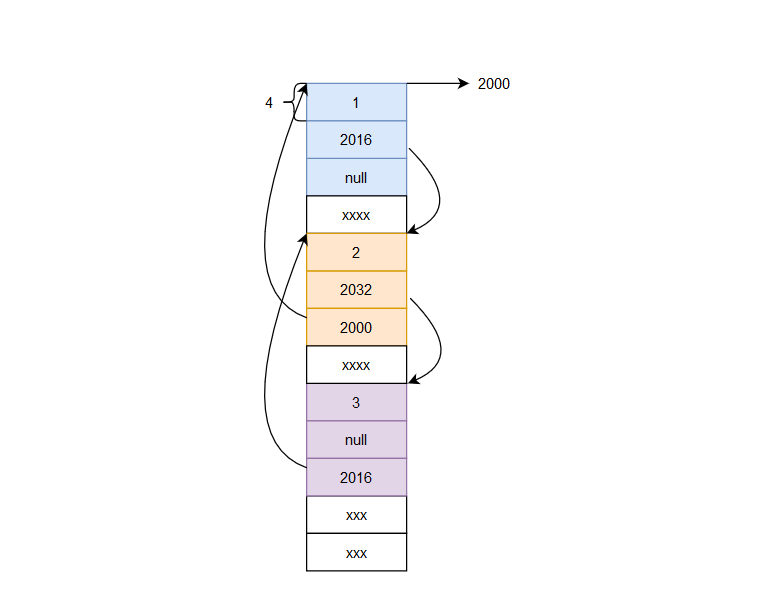
既然都可以雙向訪問了,那我們讓它首尾相接也不算過分吧,這就是循環鏈表
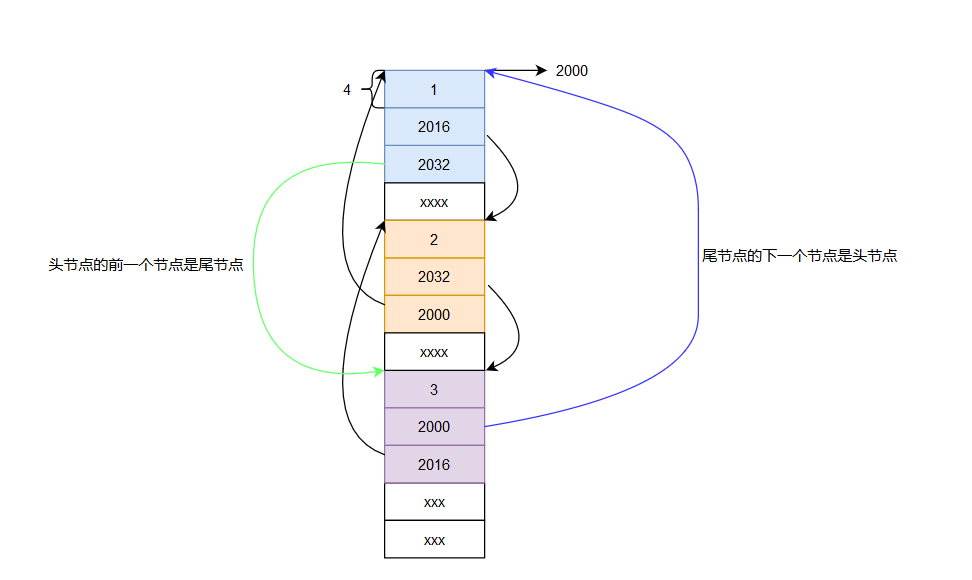
這裡的鏈表都是沒有表頭的,有些時候我們可以把第一個節點設置為表頭,數據部分可以用來存儲鏈表的長度等有意義的數據。
Java實現
下面我們來看看LinkedList是怎麼來實現的,首先是節點的定義
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } item用來存儲數據,next用來存儲下一個節點的Node對象地址,prev用來存儲上一個節點的Node對象地址,操作我也們只看兩個一個是add一個是remove,因為這是基本操作,其餘的複雜操作都是基於這兩個操作的,查與改也就是簡單的遍歷,很容易理解。首先來看add
transient Node<E> first; transient Node<E> last; public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } 類內部定義了兩個變量,first和last,分別用來記錄頭節點和尾節點的

一開始使用一個臨時節點 l 來記錄尾節點的地址,然後把尾節點設置為新加入的節點,之後出現了兩種選擇,第一種是這個鏈表是空的,之前沒有節點,那麼這個鏈表的last就是null,也就是l是null,這樣的話頭尾節點都是這個新加入的節點,第二種是如果這個鏈表不是空的,那麼就是l不是null,這個新的節點要加到之前的節點的後面,也就是把這個節點的地址記錄到尾節點的next上,也就是l.next。add還有一個同名的重載函數,在指定的位置插入元素,根據之前的數組隨筆不難猜測,肯定是先要判斷index範圍,然後再進行插入,這個插入操作是和刪除相反的,所以我們就不看插入了,直接來看刪除
public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } 根據傳入的對象是不是null分別用循環來查找數據值與o相等的節點然後調用unlink
E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { // 該節點的前一個節點是null 那他就是頭節點 first = next; // 直接把first的值設置為下一個節點的地址就刪除了頭節點 } else { // 不是頭節點的話 prev.next = next; // 該節點的前一個節點 的下一個節點 就應該是 這個節點的下一個節點 x.prev = null; // 把存儲該節點前一個節點的變量賦值為null 方便gc } if (next == null) { // 該節點的下一個節點為null 那麼他就是尾節點 last = prev; // last所指向的節點就是該節點的前一個節點 } else { // 不是尾節點的話 next.prev = prev; // 該節點的下一個節點 的前一個節點 就應該是 這個節點的前一個節點 x.next = null; // 把存儲該節點下一個節點的變量賦值為null 方便gc } x.item = null; // 方便gc size--; modCount++; return element; } 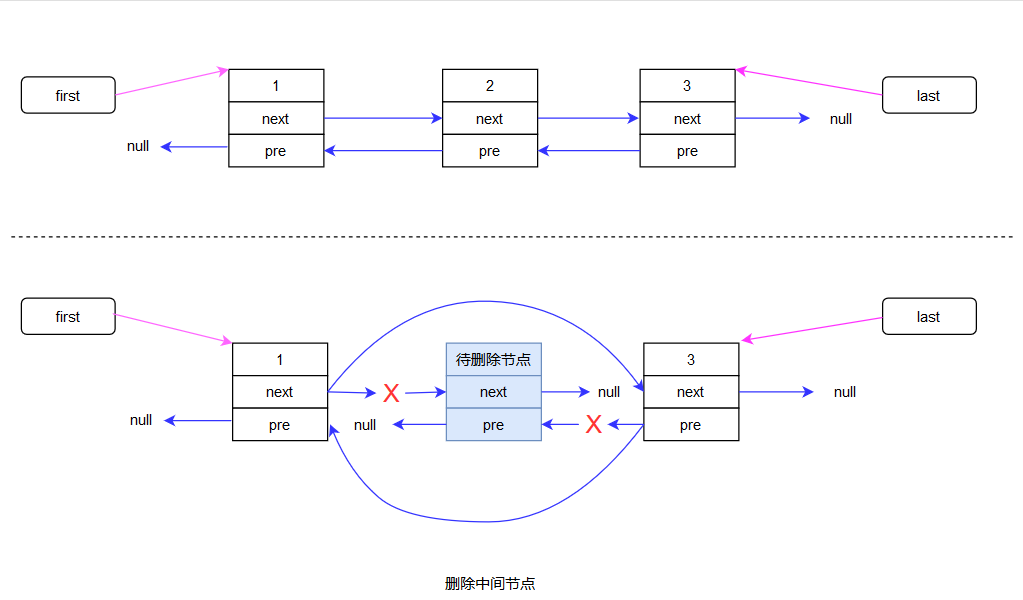
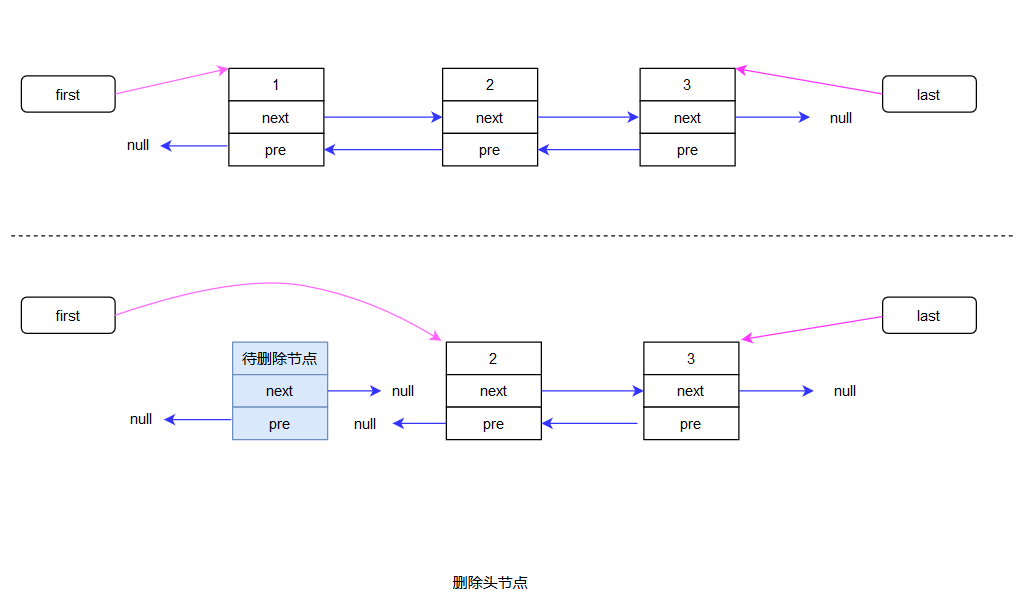
刪除尾節點和刪除頭節點異曲同工我就不畫圖了,還有單個節點的刪除就是fisrt和last都置為null
總結
鏈表通過在節點裏保存前後節點的地址,把一系列的節點連接起來,方便擴容,較為靈活,但是所佔空間也變大,具體使用鏈表還是數組需要根據實際需求來判斷。

