愛奇藝|海量數據實時分析服務技術架構演進
- 2019 年 10 月 6 日
- 筆記
1.現狀與挑戰
愛奇藝目前使用到的大數據相關技術有Druid、Impala、Kudu、Kylin、Presto、ElasticSearch等,並且隨着各技術框架的版本升級而升級。比如:
- Druid是一個分佈式的支持實時分析的數據存儲系統,數據與時間強相關,已由0.10.0版本升級到0.14.2版本;
- Impala是Cloudera受谷歌Dremel啟發開發的實時交互SQL大數據查詢工具;
- Kudu是Cloudera開源的存儲引擎,可以同時提供低延遲的隨機讀寫和高效的數據分析能力;
- Kylin是Apache開源的一個分佈式引擎, 提供了在Hadoop之上的SQL查詢接口及OLAP能力,支持超大規模數據;
- Presto是一個分佈式的SQL查詢引擎,其設計專門用於進行高速、實時的數據分析;
- ElasticSearch是一個高可靠、可擴展、分佈式的全文搜索引擎。
不同的業務場景需要不同的大數據技術架構,對於愛奇藝號而言,因單日數據量達到億級且分固定時間選擇和自由時間選擇(至少查詢近2年數據)查詢數據的業務特點,因此採用的是Druid和ElasticSearch的組合技術架構,其中自由時間選擇查詢Druid,而固定時間選擇查詢ElasticSearch。同時,為了保證數據的高可用,Druid和ElasticSearch都有主備2份數據。
然而,在使用Druid和ElasticSearch的過程中也遇到了一些挑戰,比如:
Druid本身對數據寫入和查詢只提供了基於JSON的API接口,學習接口的使用方法,了解各種字段含義,學習成本很高;另外,數據的安全性,在早期的Druid版本中支持較弱;再有,高qps長時間跨度的聚合查詢也是一個很大的挑戰。
對於ElasticSearch,因不適用於大數據量的聚合計算,要盡量避免此種應用場景,且ElasticSearch提供的RESTful API的查詢接口學習成本也相對較高。另外,因為Druid集群是服務於公司全部業務的,如何做業務隔離也是一個嚴峻的挑戰。
2.技術架構演進
在最初的愛奇藝號數據服務中,主要採用的是Kylin,架構如下圖所示:

服務分集群部署,每個集群部署多台機器,固定時間選擇和自由時間選擇查詢的都是Kylin,並對數據進行緩存。因愛奇藝號作品數據查詢的是視頻明細數據的特點,隨着業務的發展,愛奇藝號用戶以及上傳視頻量快速增長,導致Kylin Cube的構建時長和查詢時長明顯增加,甚至會出現查詢超時的情況。另外,Kylin構建Cube過程很是不穩定,經常會出現構建失敗或超時的情況,需要耗費大量的人力成本去處理上述異常情況。
基於此,我們進行了新的技術選型,對Impala+Kudu、ElasticSearch、Druid等技術架構進行了對比。最後,因Druid具有超大數據規模、毫秒級查詢時延、高並發查詢、高穩定性等的特點,故愛奇藝號選擇Druid平台作為底層架構。而對於固定時間選擇,因其時間固定且視頻量級為億級,故採用ElasticSearch存儲和查詢,重新選型後的架構如下圖所示。

愛奇藝號的作品數據查詢分為兩個部分:固定時間範圍查詢和自由時間範圍查詢,我們對固定時間範圍查詢結果進行預計算且結果存入ElasticSearch,這樣免去了大數據集上的實時聚合和排序,查詢性能得到了很大提升;自由時間範圍選擇查詢Druid,因為是分天查詢視頻數據,所以Druid的Segment粒度是天,但若用戶選擇的數據查詢時間跨度比較大,那麼Druid掃描的Segment數量就會增加,加載進內存的數據會增加,聚合數據速度會變慢,針對此種場景,愛奇藝號導入了按月分Segment數據的DataSource,即把每個視頻1個自然月的數據匯總到一個Segment,這樣減少了掃描的Segment數量,加載進內存的數據減少,數據聚合速度會變快。經過測試,當用戶選擇的時間範圍跨度大於6個月時,將查詢時間範圍拆分成自然月與自然日的兩個時間範圍並行查詢,查詢時間會明顯縮短。
經過上述優化,一個普通的愛奇藝號用戶查詢數據時長由2s+縮減至150ms+,性能提升十分明顯,用戶反饋良好,固定時間選擇具體性能對比如下圖所示:

由上圖可以看出,優化後昨日/近7天/近90天的數據查詢時間明顯縮短,且數據查詢時長並不隨着時間範圍的擴大而明顯增加,固定時間維度查詢優化明顯。自由時間選擇的查詢性能對比如下圖:

由上圖可以看出,優化後自由時間選擇的查詢時長明顯優於優化前,查詢時長是數量級級別的差異。但當用戶的視頻量比較大時,Druid的查詢性能明顯下降,於是我們通過擴容集群機器等方式進一步解決用戶視頻量大而導致查詢變慢的問題。
另外,為了預防Druid集群故障,我們採用主備Druid集群的方式存儲了2份同樣的數據,當主Druid集群出現故障不可用時,採用Hystrix的服務降級,改成查詢備份的Druid集群數據,從而保證服務高可用。因為固定時間維度查詢預計算好的ElasticSearch結果,緩解了Druid查詢壓力,且對查詢過的數據進行Redis緩存,進一步降低ElasticSearch和Druid的查詢壓力,從而保證服務的穩定性,接口成功率提升至99.9%。
3.選擇Druid的原因
Druid是一個用於大數據實時查詢和分析的高容錯、高性能開源分佈式系統,旨在快速處理和查詢,Druid的架構如下圖所示:
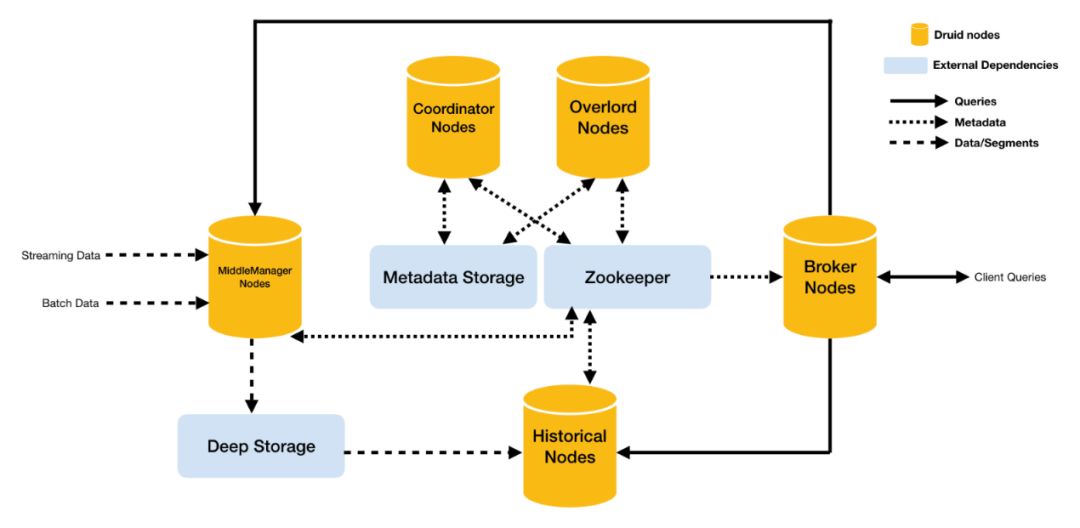
Druid主要包含以下5類節點:
- MiddleManager節點:攝入數據以及生成Segment數據文件
- Historical節點:加載已生成好的數據文件,以供數據查詢
- Coordinator節點:負責歷史節點的數據負載均衡,以及通過規則管理數據的生命周期
- Overload節點:負責數據攝入的負載均衡
- Broker節點:對外提供數據查詢服務,並同時從MiddleManager節點和Historical節點查詢數據,合併後返回給調用方
同時,集群還包括以下三類外部依賴。
- Metadata:存儲Druid集群的元數據信息,比如:Segment的相關信息,一般是MySQL。
- Zookeeper:為Druid集群提供一致性協調服務。
- Deep Storage:存放生成的Segment數據文件,並共Historical節點下載,一般是HDFS。
Druid為何能支持如何快速的查詢呢?下面為你詳細介紹。
在介紹Druid快速查詢原理之前,首先介紹一下Druid的數據查詢過程。
查詢節點接收外部Client的查詢請求,並根據查詢中指定的interval找出相關的Segment,然後找出包含這些Segment的實時節點和歷史節點,再將請求分發給相應的實時節點和歷史節點,最後將來自實時節點和歷史節點的查詢結果合併後返回給調用方。其中,查詢節點通過Zookeeper來發現歷史節點和實時節點的存活狀態。
下圖展示了在系統架構中查詢請求數據如何流動,以及哪些節點涉入其中。

查詢具體過程如下:
- 查詢請求首先進入查詢節點,查詢節點將與已知存在的Segment進行匹配查詢;
- 查詢節點選擇一組可以提供所需要的Segment的歷史節點和實時節點,將查詢請求分發到這些機器上;
- 歷史節點和實時節點都會進行查詢處理,然後返回結果;
- 查詢節點將歷史節點和實時節點返回的結果合併,返回給查詢請求方。
Druid快速查詢主要有以下3個原因:
- 內存式查詢
- 緩存的使用
- Segment特殊存儲格式:列式存儲、Bitmap索引、RoaringBitmap Compression
首先,Druid是一個內存式的數據庫,設計初衷就是數據的查詢落到內存中,如果內存足夠大,可以保證所有的數據都加載到內存中;其次,如果Broker節點上已經緩存本次查詢的結果(即之前查詢過與本次查詢完全相同的查詢),那麼Broker節點直接返回數據給客戶端,而無需再查詢各歷史節點,進一步提高了查詢速度;再次,基於Druid基本存儲單位Segment的特殊存儲格式,列式存儲保證了,每次查詢只查詢其需要的列,而不必查詢出一行中的所有數據列,Bitmap索引的使用,保證了其快速查詢。
下面重點介紹一下其中Bitmap索引:
我們考慮如下場景,一場舉世矚目的籃球名人慈善賽在洛杉磯舉行,所得善款全部用於公益事業,參加籃球賽的有現勇士球星Curry和Durant,著名歌手Beyonce、Biber,還有另外一名Curry女士參加等等。其中每人得分及相應捐款如下:

如果想查詢出籃球運動員Curry的得分情況和捐款情況,如何快速查詢出來呢?
首先,為每個字段中的每個值建立一個Bitmap索引,上述中共有name/gender/profession/score/donation 5個非時間字段,其中name/gender/profession屬於維度列,score/donation屬於度量列。對於name這個字段,因為其有4個值,Curry、Durant、Beyonce、Biber4個值,因此有4個Bitmap,每個Bitmap 0表示無,1表示有,Bitmap大小由數據條數決定,即有多少條數據,這個Bitmap的size就是多大。
Curry對應的Bitmap如下:
|
1 |
0 |
0 |
0 |
1 |
|---|
Profession中basketball player的Bitmap如下:
|
1 |
1 |
0 |
0 |
0 |
|---|
要查詢勇士球星Curry的記錄的話,就直接用上述兩個Bitmap做"與"運算即可,得出:
|
1 |
0 |
0 |
0 |
0 |
|---|
這樣的話,即可得出第一行即為其查詢結果。
另外,對於同一個字段的各個值,其中只有與記錄條數相等的1的個數,其餘全是0(比如:對於name字段,其有4個值,5條記錄,那麼對於這4個值得4個Bitmap中,僅有5個值為1),可以使用壓縮算法對其進行壓縮,Druid使用的是Roaring Bitmap Compression,詳情請見:https://roaringbitmap.org/。
4.展望
Druid在0.10版本之後開始支持SQL,且隨着版本的升級支持的SQL函數也越來越多,但因為Druid SQL本質上是一個語言翻譯層,受限於Druid本身的查詢處理能力,支持的SQL功能有限。 Druid目前並沒有支持JOIN查詢,所有的聚合查詢都被限制在單個DataSource進行,但在實際的使用過程中,往往需要不同DataSource進行關聯查詢才能得到想要結果,這也是目前Druid開發團隊的難題。
現在愛奇藝大部分DataSource的Segment的粒度是天或小時級的,當需要查詢的時間跨度比較大時,會導致查詢變慢,佔用大量Historical節點資源,可以創建一個Batch任務,把幾天前(或幾周前)的數據按照天或月粒度Roll up重新構建Index,當查詢時間跨度較大時,性能會有明顯提升。
此外,因為目前愛奇藝號不同功能使用的是同一個Druid集群,只是在DataSource間做數據隔離,但是數據查詢Broker之間並未做隔離,各功能之間數據查詢會互相影響,也是希望解決的難題。
