HashCode()與equals()深入理解
- 2020 年 4 月 6 日
- 筆記
1、hashCode()和equals()方法都是Object類提供的方法,
hashCode()返回該對象的哈希碼值,該值通常是一個由該對象的內部地址轉換而來的int型整數,
Object的equals()方法等價於==,也就是判斷兩個引用的對象是否是同一對象,所謂同一對象就是指內存中同一塊存儲單元
2、要判斷兩個對象邏輯相等就要覆蓋equals()方法,當覆蓋equals()方法時建議覆蓋hashCode()方法,
官方hashCode的常規協定是如果根據 equals(Object) 方法,兩個對象是相等的,那麼在兩個對象中的每個對象上調用 hashCode 方法都必須生成相同的整數結果。
3、在一些散列存儲結構的集合中(Hashset,HashMap…)判斷兩個對象是否相等是先判斷兩個對象的hashCode是否相等,再判斷兩個對象用equals()運算是否相等
4、hashCode是為了提高在散列結構存儲中查找的效率,在線性表中沒有作用。
5、若兩個對象equals返回true,則hashCode有必要也返回相同的int數。
6、同一對象在執行期間若已經存儲在集合中,則不能修改影響hashCode值的相關信息,否則會導致內存泄露問題。
一、equals()方法
equals是Object類提供的方法之一,眾所周知,每一個java類都繼承自Object類,所以說每一個對象都有equals這個方法。而我們在用這個方法時卻一般都重寫這個方法,why?
Object類中equals()方法的源代碼:
public boolean equals(Object obj) { return (this == obj); }
從這個方法中可以看出,只有當一個實例等於它本身的時候,equals()才會返回true值。通俗地說,此時比較的是兩個引用是否指向內存中的同一個對象,也可以稱做是否實例相等。而我們在使用equals()來比較兩個指向值對象的引用的時候,往往希望知道它們邏輯上是否相等,而不是它們是否指向同一個對象——這就是我們通常重寫這個方法的原因。
重寫equals()方法,必須要遵守通用約定。來自java.lang.Object的規範,equals方法實現了等價關係,以下是要求遵循的5點:
1.自反性:對於任意的引用值x,x.equals(x)一定為true。
2.對稱性:對於任意的引用值x 和 y,當x.equals(y)返回true時,y.equals(x)也一定返回true。
3.傳遞性:對於任意的引用值x、y和z,如果x.equals(y)返回true,並且y.equals(z)也返回true,那麼x.equals(z)也一定返回true。
4. 一致性:對於任意的引用值x 和y,如果用於equals比較的對象信息沒有被修改,多次調用x.equals(y)要麼一致地返回true,要麼一致地返回false。
5.非空性:對於任意的非空引用值x,x.equals(null)一定返回false。
二、hashCode()方法
hashcode()這個方法也是從object類中繼承過來的,在object類中定義如下:
public native int hashCode();
hashCode()返回該對象的哈希碼值,該值通常是一個由該對象的內部地址轉換而來的整數,它的實現主要是為了提高哈希表(例如java.util.Hashtable提供的哈希表)的性能。
官方文檔給出的hashCode()的常規協定:
1、在 Java 應用程序執行期間,在同一對象上多次調用 hashCode 方法時,必須一致地返回相同的整數,前提是對象上 equals 比較中所用的信息沒有被修改。從某一應用程序的一次執行到同一應用程序的另一次執行,該整數無需保持一致。
2、如果根據 equals(Object) 方法,兩個對象是相等的,那麼在兩個對象中的每個對象上調用 hashCode 方法都必須生成相同的整數結果。
3、以下情況不 是必需的:如果根據 equals(java.lang.Object) 方法,兩個對象不相等,那麼在兩個對象中的任一對象上調用 hashCode 方法必定會生成不同的整數結果。但是,程序員應該知道,為不相等的對象生成不同整數結果可以提高哈希表的性能。
4、實際上,由 Object 類定義的 hashCode 方法確實會針對不同的對象返回不同的整數。(這一般是通過將該對象的內部地址轉換成一個整數來實現的,但是 JavaTM 編程語言不需要這種實現技巧。)
總結:
hashCode()的返回值和equals()的關係如下:
如果x.equals(y)返回“true”,那麼x和y的hashCode()必須相等。
如果x.equals(y)返回“false”,那麼x和y的hashCode()有可能相等,也有可能不等。
重寫hashCode時注意事項
(1)返回的hash值是int型的,防止溢出。
(2)不同的對象返回的hash值應該盡量不同。(為了hashMap等集合的效率問題)
(3)《Java編程思想》中提到一種情況
“設計hashCode()時最重要的因素就是:無論何時,對同一個對象調用hashCode()都應該產生同樣的值。如果在講一個對象用put()添加進HashMap時產生一個hashCdoe值,而用get()取出時卻產生了另一個hashCode值,那麼就無法獲取該對象了。所以如果你的hashCode方法依賴於對象中易變的數據,用戶就要當心了,因為此數據發生變化時,hashCode()方法就會生成一個不同的散列碼”。
下面來看一張對象放入散列集合的流程圖:
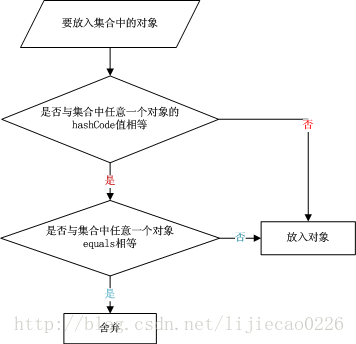
在存儲一個對象時,先進行hashCode值的比較,然後進行equals的比較。來認識一下具體hashCode和equals在代碼中是如何調用的。
測試一:覆蓋equals(Object obj)但不覆蓋hashCode(),導致數據不唯一性
public class HashCodeTest { public static void main(String[] args) { Collection set = new HashSet(); Point p1 = new Point(1, 1); Point p2 = new Point(1, 1); System.out.println(p1.equals(p2)); set.add(p1); // (1) set.add(p2); // (2) set.add(p1); // (3) Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object object = iterator.next(); System.out.println(object); } } } class Point { private int x; private int y; public Point(int x, int y) { super(); this.x = x; this.y = y; } @Override public boolean equals(Object obj) { if (this == obj) { return true; } if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } Point other = (Point) obj; if (x != other.x) { return false; } if (y != other.y) { return false; } return true; } @Override public String toString() { return "x:" + x + ",y:" + y; } }
//結果: true x:1,y:1 x:1,y:1
原因分析:
(1)當執行set.add(p1)時集合為空,直接存入集合;
(2)當執行set.add(p2)時首先判斷該對象(p2)的hashCode值所在的存儲區域是否有相同的hashCode,因為沒有覆蓋hashCode方法,所以jdk使用默認Object的hashCode方法,返回內存地址轉換後的整數,因為不同對象的地址值不同,所以這裡不存在與p2相同hashCode值的對象,因此jdk默認不同hashCode值,equals一定返回false,所以直接存入集合。
(3)當執行set.add(p1)時,時,因為p1已經存入集合,同一對象返回的hashCode值是一樣的,繼續判斷equals是否返回true,因為是同一對象所以返回true。此時jdk認為該對象已經存在於集合中,所以捨棄。
測試二:覆蓋hashCode方法,但不覆蓋equals方法,仍然會導致數據的不唯一性
public class HashCodeTest { public static void main(String[] args) { Collection set = new HashSet(); Point p1 = new Point(1, 1); Point p2 = new Point(1, 1); System.out.println(p1.equals(p2)); set.add(p1); // (1) set.add(p2); // (2) set.add(p1); // (3) Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object object = iterator.next(); System.out.println(object); } } } class Point { private int x; private int y; public Point(int x, int y) { super(); this.x = x; this.y = y; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + x; result = prime * result + y; return result; } @Override public String toString() { return "x:" + x + ",y:" + y; } }
//結果 false x:1,y:1 x:1,y:1
原因分析:
(1)當執行set.add(p1)時(1),集合為空,直接存入集合;
(2)當執行set.add(p2)時(2),首先判斷該對象(p2)的hashCode值所在的存儲區域是否有相同的hashCode,這裡覆蓋了hashCode方法,p1和p2的hashCode相等,所以繼續判斷equals是否相等,因為這裡沒有覆蓋equals,默認使用’==’來判斷,所以這裡equals返回false,jdk認為是不同的對象,所以將p2存入集合。
(3)當執行set.add(p1)時(3),時,因為p1已經存入集合,同一對象返回的hashCode值是一樣的,並且equals返回true。此時jdk認為該對象已經存在於集合中,所以捨棄。
綜合上述兩個測試,要想保證元素的唯一性,必須同時覆蓋hashCode和equals才行。
(注意:在HashSet中插入同一個元素(hashCode和equals均相等)時,會被捨棄,而在HashMap中插入同一個Key(Value 不同)時,原來的元素會被覆蓋。)
測試三:在內存泄露問題
public class HashCodeTest { public static void main(String[] args) { Collection set = new HashSet(); Point p1 = new Point(1, 1); Point p2 = new Point(1, 2); set.add(p1); set.add(p2); p2.setX(10); p2.setY(10); set.remove(p2); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object object = iterator.next(); System.out.println(object); } } } class Point { private int x; private int y; public Point(int x, int y) { super(); this.x = x; this.y = y; } public int getX() { return x; } public void setX(int x) { this.x = x; } public int getY() { return y; } public void setY(int y) { this.y = y; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + x; result = prime * result + y; return result; } @Override public boolean equals(Object obj) { if (this == obj) { return true; } if (obj == null) { return false; } if (getClass() != obj.getClass()) { return false; } Point other = (Point) obj; if (x != other.x) { return false; } if (y != other.y) { return false; } return true; } @Override public String toString() { return "x:" + x + ",y:" + y; } }
x:1,y:1 x:10,y:10
原因分析:
假設p1的hashCode為1,p2的hashCode為2,在存儲時p1被分配在1號桶中,p2被分配在2號筒中。這時修改了p2中與計算hashCode有關的信息(x和y),當調用remove(Object obj)時,首先會查找該hashCode值得對象是否在集合中。假設修改後的hashCode值為10(仍存在2號桶中),這時查找結果空,jdk認為該對象不在集合中,所以不會進行刪除操作。然而用戶以為該對象已經被刪除,導致該對象長時間不能被釋放,造成內存泄露。解決該問題的辦法是不要在執行期間修改與hashCode值有關的對象信息,如果非要修改,則必須先從集合中刪除,更新信息後再加入集合中。
測試4:
public class RectObject { public int x; public int y; public RectObject(int x,int y){ this.x = x; this.y = y; } @Override public int hashCode(){ final int prime = 31; int result = 1; result = prime * result + x; result = prime * result + y; return result; } @Override public boolean equals(Object obj){ return false; } }
public static void main(String[] args){ HashSet<RectObject> set = new HashSet<RectObject>(); RectObject r1 = new RectObject(3,3); RectObject r2 = new RectObject(5,5); RectObject r3 = new RectObject(3,3); set.add(r1); set.add(r2); set.add(r3); set.add(r1); System.out.println("size:"+set.size()); }
運行結果:size:3
原因分析:
首先r1和r2的對象比較hashCode,不相等,所以r2放進set中,
再來看一下r3,比較r1和r3的hashCode方法,是相等的,然後比較他們兩的equals方法,因為equals方法始終返回false,所以r1和r3也是不相等的,r3和r2就不用說了,他們兩的hashCode是不相等的,所以r3放進set中,
再看r4,比較r1和r4發現hashCode是相等的,在比較equals方法,因為equals返回false,所以r1和r4不相等,同一r2和r4也是不相等的,r3和r4也是不相等的,所以r4可以放到set集合中,那麼結果應該是size:4,那為什麼會是3呢?
這時候我們就需要查看HashSet的源碼了,下面是HashSet中的add方法的源碼:
/** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element <tt>e</tt> to this set if * this set contains no element <tt>e2</tt> such that * <tt>(e==null ? e2==null : e.equals(e2))</tt>. * If this set already contains the element, the call leaves the set * unchanged and returns <tt>false</tt>. * * @param e element to be added to this set * @return <tt>true</tt> if this set did not already contain the specified * element */ public boolean add(E e) { return map.put(e, PRESENT)==null; }
這裡我們可以看到其實HashSet是基於HashMap實現的,hashset存放的元素作為hashMap裏面唯一的key變量,value部分用一個PRESENT對象來存儲。
我們在點擊HashMap的put方法,源碼如下:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果存儲元素的table為空,則進行必要字段的初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 獲取長度(16) // 如果根據hash值獲取的結點為空,則新建一個結點
//(先查找對應的索引位置有沒有元素)
if ((p = tab[i = (n - 1) & hash]) == null) // 此處 & 代替了 % (除法散列法進行散列) tab[i] = newNode(hash, key, value, null); // 這裡的p結點是根據hash值算出來對應在數組中的元素 else { Node<K,V> e; K k; // 如果新插入的結點和table中p結點的hash值,key值相同的話
//這裡判斷hashCode是否相等,再判斷兩個對象是否相等或者兩個對象的equals方法,因為r1和r4是同一對象,
//所以其實這裡是r4覆蓋了r1 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果是紅黑樹結點的話,進行紅黑樹插入 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { // 代表這個單鏈表只有一個頭部結點,則直接新建一個結點即可 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 鏈表長度大於8時,將鏈錶轉紅黑樹 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; // 及時更新p p = e; } } // 如果存在這個映射就覆蓋 if (e != null) { // existing mapping for key V oldValue = e.value; // 判斷是否允許覆蓋,並且value是否為空
if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // 回調以允許LinkedHashMap後置操作 return oldValue; } } ++modCount; // 更改操作次數 if (++size > threshold) // 大於臨界值 // 將數組大小設置為原來的2倍,並將原先的數組中的元素放到新數組中 // 因為有鏈表,紅黑樹之類,因此還要調整他們 resize(); // 回調以允許LinkedHashMap後置操作 afterNodeInsertion(evict); return null; }
參考:
https://blog.csdn.net/u012088516/article/details/86495512
https://blog.csdn.net/wonad12/article/details/78958411
https://blog.csdn.net/AJ1101/article/details/79413939


